

Ijraset Journal For Research in Applied Science and Engineering Technology
A Design to Predict and Analyze Crime
Authors: Koshe Ahana Hemant, Mankani Neha Haresh , Sayyed Shafiya Majid
DOI Link: https://doi.org/10.22214/ijraset.2022.42898
Certificate: View Certificate
Abstract
Crime is one of the dominant and alarming aspect of our society. Over the past few years, the crime rate across globe has increased exponentially. So, preventing the crime from occurring is a vital task. In the recent time, it is seen that artificial intelligence has shown its importance in almost all the field and crime prediction is one of them. However, it is necessary to maintain a proper database of the crime that has occurred. The ability to predict the crime on the basis of time, location and so on which can occur in future can help the law enforcement agencies in preventing the crime before it occurs from a strategical perspective. However, predicting the crime accurately is a challenging task because crimes are increasing at an alarming rate. Thus, the crime prediction and analysis methods are very important to detect the future crimes and reduce them. In Recent time, many researchers have conducted experiments to predict the crimes using various machine learning methods and particular inputs. For crime prediction, KNN, K-means and Random Forest and some other algorithms are used. Our system can predict regions which have high probability for crime occurrence and can visualize crime prone areas. The main purpose is to highlight the worth and effectiveness of machine learning in predicting violent crimes occurring in a particular region in such a way that it can be used by police to reduce crime rates in the society.
Introduction
I. INTRODUCTION
Crime is increasing considerably day by day. Crime is among the main issues which is growing continuously in intensity and complexity. Crime patterns are changing constantly because of which it is difficult to explain behaviours in crime patterns. Crime is classified into various types like kidnapping, theft murder, rape etc. The law enforcement agencies collects the crime data information with the help of information technologies (IT). But occurrence of any crime is naturally unpredictable and from previous searches it was found that various factors like poverty, employment affects the crime rate . It is neither uniform nor random. With rapid increase in crime number, analysis of crime is also required. Crime analysis basically consists of procedures and methods that aims at reducing crime risk. It is a practical approach to identify and analyse crime patterns. But, major challenge for law enforcement agencies is to analyse escalating number of crime data efficiently and accurately. So it becomes a difficult challenge for crime analysts to analyse such voluminous crime data without any computational support. A powerful system for predicting crimes is required in place of traditional crime analysis because traditional methods cannot be applied when crime data is high dimensional and complex queries are to be processed. Therefore a crime prediction and analysis tool were needed for identifying crime patterns effectively. This paper introduces some methodologies with the help of which it can be predicted that at what place and time which type of crime has a higher probability of occurrence. Ever Since the Coronavirus Pandemic hit the globe like a shockwave, multiple global data prediction systems have shown unexpected amount of fluctuations. Given the circumstances, it is essential to make accurate predictions based on data analysis.
One of the primary advantages of big data analytics software is that it can evaluate huge quantities of data much faster than humans can, plus spot trends they’d likely miss. So, from a crime-solving point of view, data analytics could help catch criminals who are trying to evade arrest.
II. METHODOLOGY
Predictive modeling was used for making predictions since it has the method which is able to build a model and has the capability to make predictions. This method consists of different algorithms of Machine Learning that can study properties from the data used for training which is used for producing predictions. It is split in two major classes one is Regression and other is classification of patterns. Regression models are based upon analysis of the relationship that are present between trends and variable in order to make predictions about the continuous variables. Whereas,the job of classification is to assign a particular class labels to a data value as output of the prediction. Division of pattern classification is in two ways i.e., Supervised and Unsupervised learning. It is already known in supervised learning that which class labels are to be used for building classification models. In unsupervised learning, these class labels are not known.
A. Working Of Project
Predictive modeling was used for making predictions since it has the method which is able to build a model and has the capability to make predictions. This method consists of different algorithms of Machine Learning that can study properties from the data used for training which is used for producing predictions. It is split in two major classes one is Regression and other is classification of patterns. Regression models are based upon analysis of the relationship that are present between trends and variable in order to make predictions about the continuous variables. Whereas, the job of classification is to assign a particular class labels to a data value as output of the prediction. Division of pattern classification is in two ways i.e., Supervised and Unsupervised learning. It is already known in supervised learning that which class labels are to be used for building classification models. In unsupervised learning, these class labels are not known. This paper deals with supervised learning[1].
- Data Collection: Crime dataset from kaggle is used in CSV format.
- Data Preprocessing: Data pre-processing basically involves methods to remove the infinite or null values from data which might affect the performance of the model. In this step the data set is converted into the understandable format which can be fed into machine learning models. The categorical attributes (Location, Block, Crime Type, Community Area) are converted into numeric using Label Encoder. The date attribute is splitted into new attributes like month and hour which can be used as feature for the model.
- Feature Selection: Features selection is done which can be used to build the model. The attributes used for feature selection are Offense ID, District ID, Location, X coordinate , Y coordinate, Latitude , Longitude, Hour and month.
- Building and Training Model: After feature selection location and month attribute are used for training. The dataset is divided into pair of x train, y train and x test, y test. The algorithms model is imported from sklearn. Building model is done using model. Fit (x train, y train).
- Prediction: After the model is build using the above process, prediction is done using model.predict(x test). The accuracy is calculated using accuracy, score imported from metrics.
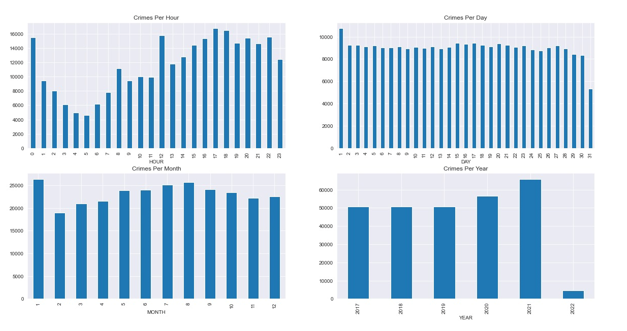
- Visualization: Using matplotlib library from sklearn. Analysis of the crime dataset is done by plotting various graphs.
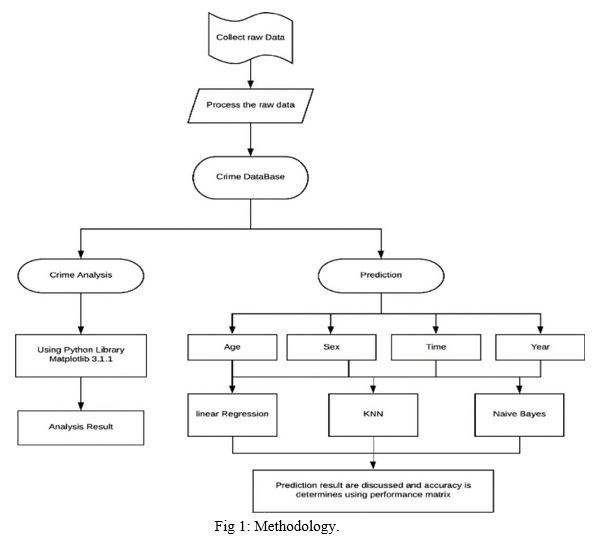
III. DATASET
The dataset that we have used is of 5 Denver City. The different columns or as we refer to them as features are as followed
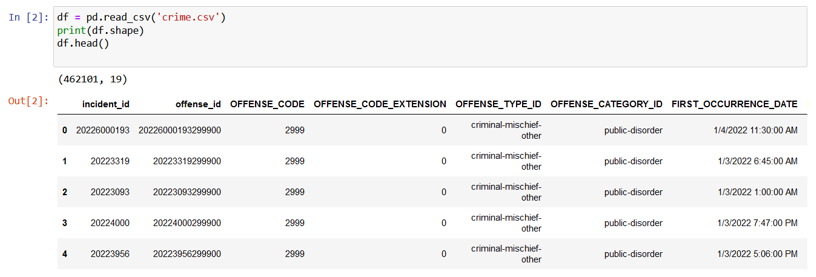
Here the values are as followed :-
- Incident ID - Incident ID is a unique identifier for a specific crime event that happened on a specific date and time.
- Offense ID - It indicates a unique identifier for a crime with respect to incident id and offense code(offense id= incident id + offense code)
- Offense Code - It is a code that uniquely identifies each crime.
- Offense Type ID - It is a superset of offense category id and indicates type of crime.
- Offense Category ID - It is the subset of offense type id and it specifies exact details about the type of crime.
- First Occurence Date - Date on which the particular crime was observed for the first time in the specific address.
- Last Occurence Date - Date on which the particular crime was observed for the last time in the specific address
- Reported Date - Date on which particular crime that took place was reported.
- Incident Address - Address at which the crime took place.
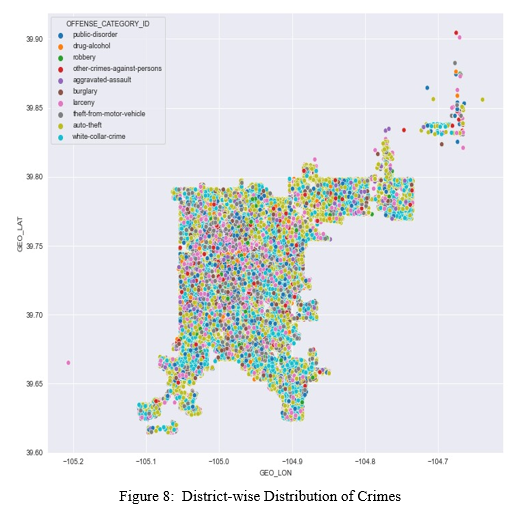
- GEO_LON - Longitudinal co-ordinates of the location.
- GEO_LAT - Latitudinal co-ordinates of the location.
- District ID - Numerical value to identify a district in which the crime took place.
- Precinct ID - It is a numerical value or code for a police station of the area where the crime was reported.
- Neighborhood ID - Province in the city where the crime took place.
IV. PROPOSED SYSTEM
A. System Components
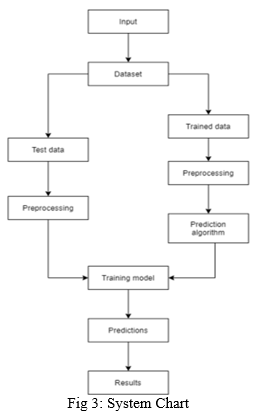
B. System Chart
C. Collaboration Diagram
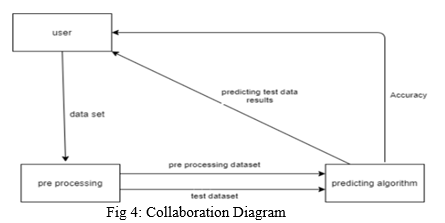
V. EDA AND DATA PRE-PROCESSING
A. Data Cleaning
The dataset is not in the right format to use directly with the model hence data preprocessing is required . In our model we did a few steps as followed :
- Dropping the null rows

2. Changing the data types of the column / features .

3. Sorting the data by offense category id
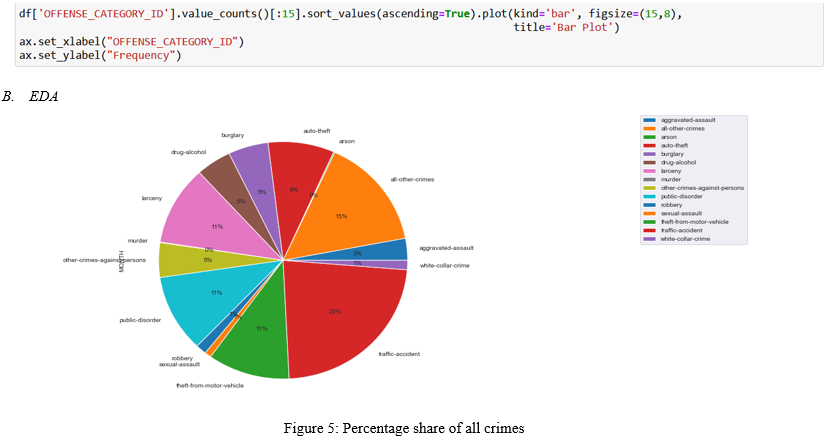
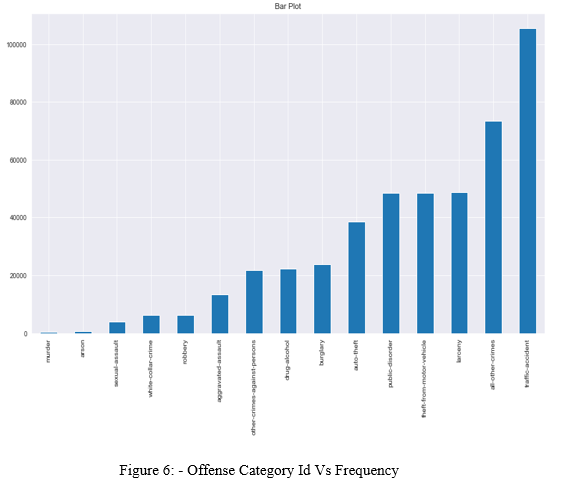
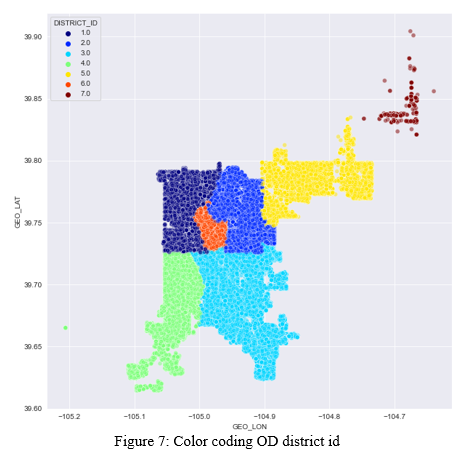
VI. MODEL CREATION
A. Splitting the Dataset
For model creation we split the data for training and testing. We defined a function that splits the dataset . The function divided the dataset in training and testing and further into the training dependent and independent variables.
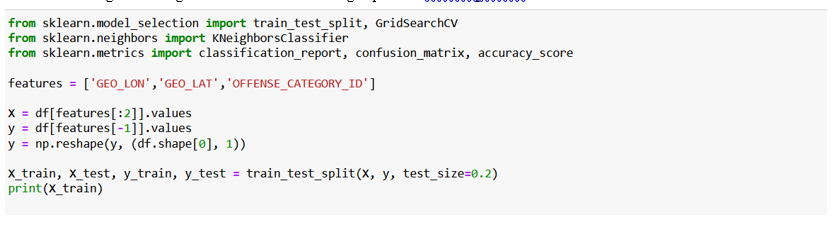
We fit the model using the training split of the dataset by passing the dependent and the independent variables . We passed the testing dataset in the validation dataset.
VII. EXPERIMENTAL ANALYSIS
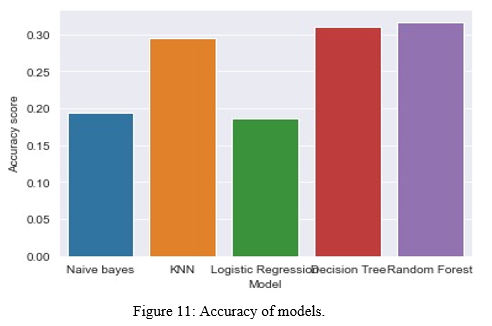
After testing various machine learning models like Logistic Regression, Decision Tree, Random Forest, Support Vector Machine & K-Nearest Neighbor the result are as follows:
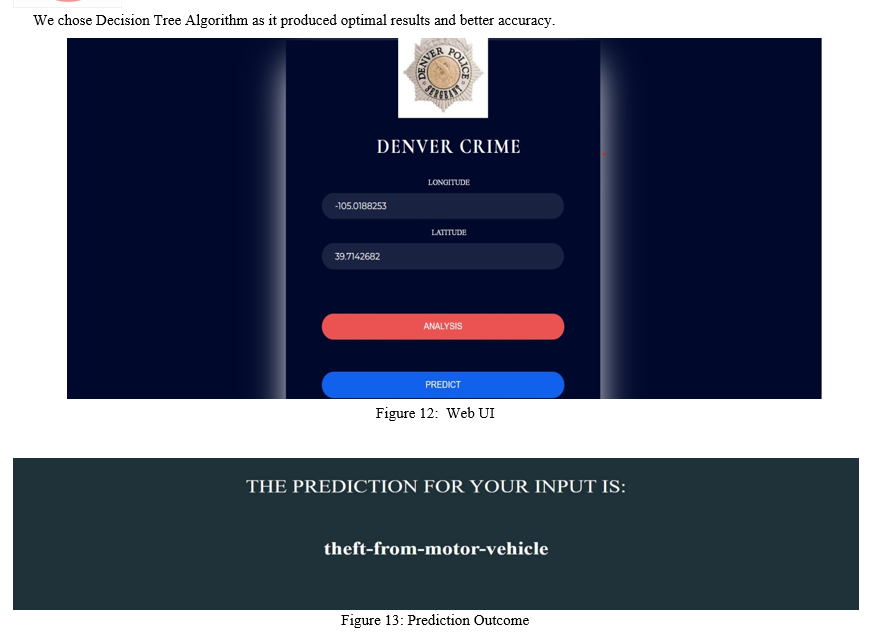
After inserting the Longitude and Latitude as input it predicted which crime is likely to happen in that particular area.
Conclusion
Crime prediction is one the current trends in the society. Crime prediction intends to reduce crime occurrences. It does this by predicting which type of crime may occur in future. Here, analysis of crime and prediction are performed with the help of various approaches some of which are KNN, K means Clustering & Random Forest. However which model will work best is totally dependent on the dataset that is being used. This research work offers a way to foresee and predict crimes and frauds within a city. It focuses on having a crime prediction tool that can be helpful to law enforcement. This paper is aimed at increasing the prediction accuracy as much as possible. As compared to the previous work, this work was successful in achieving the highest accuracy in prediction. The KNN system helps law implementing agencies for improved and exact crime analysis. The result of the optimized k-means algorithm is efficient and provides improved accuracy of the final cluster reduced the number of iterations. We know that the prediction accuracy of random forest model can be improved based on historical crime data and covariates (POI data and demographic information). From the overall prediction results, the prediction model of random forest with covariates has better performance compared with Naive Bayes model and logistic regression model. As a combinatorial classification model, random forest overcomes the limitations of single decision tree classification and can effectively avoid the problem of overfitting. Among the model evaluation indexes selected in this paper, the random forest prediction model with covariates is better than other models.
References
[1] Pratibha, A. Gahalot, Uprant, S. Dhiman and L. Chouhan, \"Crime Prediction and Analysis,\" 2nd International Conference on Data, Engineering and Applications (IDEA), 2020, pp. 1-6, doi: 10.1109/IDEA49133.2020.9170731. [2] S. Yao et al., \"Prediction of Crime Hotspots based on Spatial Factors of Random Forest,\" 2020 15th International Conference on Computer Science & Education (ICCSE), 2020, pp. 811-815, doi: 10.1109/ICCSE49874.2020.9201899. [3] S. G. Krishnendu, P. P. Lakshmi and L. Nitha, \"Crime Analysis and Prediction using Optimized K-Means Algorithm,\" 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC), 2020, pp. 915-918, doi: 10.1109/ICCMC48092.2020.ICCMC-000169. [4] A. Kumar, A. Verma, G. Shinde, Y. Sukhdeve and N. Lal, \"Crime Prediction Using K-Nearest Neighboring Algorithm,\" 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), 2020, pp. 1-4, doi: 10.1109/ic-ETITE47903.2020.155.
Copyright
Copyright © 2022 Koshe Ahana Hemant, Mankani Neha Haresh , Sayyed Shafiya Majid. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET42898
Publish Date : 2022-05-18
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online