

Ijraset Journal For Research in Applied Science and Engineering Technology
Accident Detection and Alerting System using Deep Learning Techniques
Authors: V. Gopinath, G. Bhavani, G. Uday Sai, G. Chandana
DOI Link: https://doi.org/10.22214/ijraset.2023.50701
Certificate: View Certificate
Abstract
The Aim of Our project is to Focus on Late Responses By Emergency Services During the time of Road Accidents Which Leads to Death of Many lives, Where to Culminate this Apart , Our Project Majorly Focuses On Gathering Images and Informative Selection, Location Tracking and Transferring Notification. Though traditional machine learning approaches Had been outperformed by feature engineering methods which can select an optimal set of features. On contrary, Modernly it is known that deep learning models such as Convolutional Neural Networks (CNN) can extract features and it ables to reduce the computational cost automatically. The proposed implementation increases the survival rate by meager percentage. Efficient computation occurs when the algorithm utilizes the maximum GPU and the right functions.
Introduction
I. INTRODUCTION
As the statistics of accidents are viewed, we can see that the tunnel accidents are increasing day by day. Our main objective is to minimize the accidents’ response time when an accident occurs, and the time emergency responders reach the accident scene in reducing human deaths due to tunnel accidents. Accident detection system is used to recognize the location of the accident and easily reach the location. Every second is valuable for the ambulance.
The notification is immediately sent as soon as the crash takes place. There is no loss of life due to the delay in the arrival of the ambulance. In order to give treatment for injured people, first we need to know where the accident happened through location tracking and sending a message to the emergency services.
According to this project when a vehicle meets with an accident, an immediate notification will be sent to the emergency services. The emergency response to accidents is very crucial. People injured in a crash need to be sent to the nearest hospital in the first place to prevent their health condition from worsening, on the other hand, serious crashes often cause non recurrent congestion, if emergency response or clearance is not carried out on time. In order to mitigate those negative impacts, tunnel crashes need to be quickly detected.
The autonomous vehicle black-box system is simply used as a video recording device for accident identification. The traditional detection methods require manual extraction of features by experts over time. Unlike the traditional detection methods, the Deep Learning-based methods doesn’t require manual extraction of features, with dataset as input it can detect accidents. With the help of the video input the deep learning-based methods does Image Classification and Object Localization. This brings us to the motivation to use Deep Learning Model.
II. PROBLEM STATEMENT
A number of technological and sociological improvements have helped reduce traffic fatalities during the past decade, e.g., each 1% increase in seat belt usage is estimated to save 136 lives.
The road accidents lead to loss of human life. It was noted, with deep concern, that most of these deaths occur as a result of late response by emergency services especially for accidents occurring in remote areas or at night where there is no witness or a means of alerting the responsible authorities such as police, emergency services responders and or relatives; and in some rare cases the identity of victims remain unknown.
Moreover, each minute that an injured crash victim does not receive emergency medical care can make a large difference in their survival rate, i.e., Analysis shows that reducing accident response time by one-minute correlates to a six% difference in the number of lives saved. This project seeks to reduce the time taken between accident time and notifying the emergency responders of the accident occurrence. The proposed implementation increases the survival rate by meager percentage. Efficient computation occurs when the algorithm utilizes the maximum GPU and the right functions.
III. LITERATURE SURVEY
A. Survey Of Major Area Relevant To Project
- Convolution Neural Network (CNN)
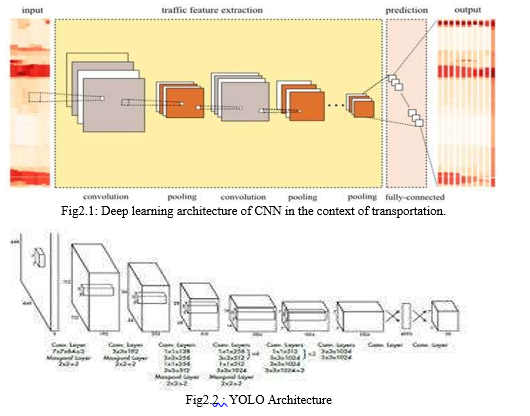
Convolution layers differ from traditional feed forward neural network where each input neuron is connected to each output neuron and network is fully connected. The CNN uses convolution filters over its input layer and obtains local connections where only local input neurons are connected to the output neurons. Hundreds of filters are sometimes applied to input and results are merged in each layer. One filter can extract one traffic feature from the input layer and, thus, hundreds of filters can extract hundreds of traffic features. Those extracted traffic features are combined further to extract a higher level and more abstract traffic features. A Convolutional Neural Network (ConvNet/CNN) is a Deep Learning algorithm which can take in an input image, assign importance (learnable weights and biases) to various aspects/objects in the image and be able to differentiate one from the other. The pre-processing required in a ConvNet is much lower as compared to other classification algorithms. While in primitive methods filters are hand-engineered, with enough training, ConvNets have the ability to learn these filters/characteristics. The architecture of a ConvNet as shown in fig2.1 is analogous to that of the connectivity pattern of Neurons in the Human Brain and was inspired by the organization of the visual cortex.
2. Yolo Algorithm
We re-frame object detection as a single regression problem, straight from image pixels to bounding box coordinates and class of its probabilities. YOLO is refreshingly simple. A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for the boxes. YOLO trains on full images and directly optimizes detection performance. This unified model has several benefits over traditional methods of object detection. YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance. Fast R-CNN, a top detection method, mistakes background patches in an image for objects because it can’t see the larger context. YOLO makes less than half the number of background errors compared to Fast R- CNN.
IV. SYTEM ARCHITECTURE
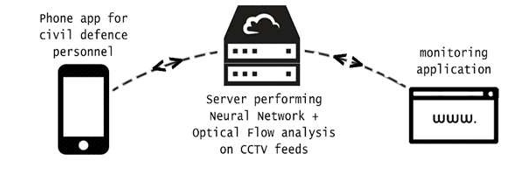
System Architecture is abstract, conceptualization-oriented, global, and focused to achieve the mission and life cycle concepts of the system. Below is the figure of Overall System architecture of our project. We are quite fortunate to have well- prepared emergency services that respond to traffic accidents at a moment’s notice. By using Machine Learning and Computer Vision to detect traffic accidents autonomously in split second. Detecting otherwise unreported accidents will create safer roads and a more efficient system for the civil defense, devoid of human error. Our solution is designed to be as effortless and inexpensive as possible to setup, especially since it will simply run on top of LTA's preexisting, pervasive road CCTV infrastructure. This keeps the costs of this solution very low as it does not require any dramatic paradigm shifts before it can be of use.
A. Sytem Flow
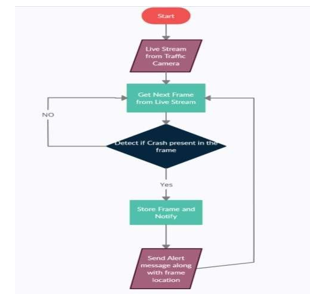
Our project is classified into three modules,
i.e., processing input, Accident Detection Module and Notification System.
We take the input from the CCTV footage for this project and is divided into frames. Comparison between the previous frame and current frame vehicle’s speed is done and if there is a huge difference in speed such that it is greater than the threshold value the frame is detected as crash frame. The crash frames are stored in the crash images folder. When a crash frame is detected the notification system sends an immediate alert along with crash images to the concerned department.
B. System Flow Diagram
V. MODULE DESCRIPTION
A. Processing Input
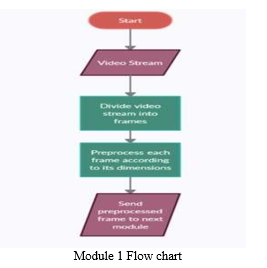
Our project generally takes data from live feed from CCTV Camera, but for feasibility we have worked on pre-recorded traffic videos. This module takes direct feed from video and breaks the video stream into a number of frames then we process each frame as required by the object detection model and then passes the frame to the next module.
B. Accident Detection Module
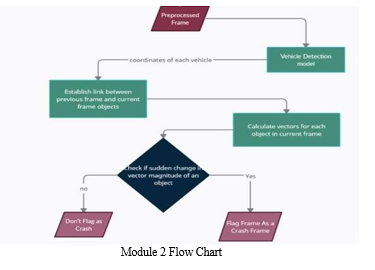
In this module, it takes the input as the pre-processed frames from the above module. We have divided this moduleinto two major parts Object Detection and Crash Detection. In Object Detection we detect all the vehicles present in the current frames and return their location. Now in Accident Detection part marks the current frame as crashed or not. Object detection models can be broadly classified into "single-stage" fast. RetinaNet uses a feature pyramid network to efficiently detect objects at multiple scales and introduces a new loss function, the Focal loss function, to alleviate the problem extreme foreground-background class imbalance.
Bounding boxes can be represented in multiple ways, the most common formats are:
- Storing the coordinates of the corners [x-min, y-min, x-max, y-max]
- Storing the coordinates of the center and the box dimensions [x, y, width, height]
In our project, we used the first way of bounding boxes, i.e., by storing the coordinates of the corners. Now for every frame received from the above module, we pass it to the retinanet object detection model and receive the bounding boxes for each vehicle in the format specified above. We track each vehicle by associating an object to it which contains vehicle information such as its current position, its link to previous frame, its speed.
For every new object detected in the current frame we find an old object from the previous frame such that the distance between this old object and new object is the least among all combinations of old object and new object pairs. The old object in the previous frame with the least distance to the new object in the current frame is most certainly the same object. This is because an object can only move so far between subsequent frames so this distance will almost always be smaller than the distance between 2 different objects. Now establish link between objects having minimum distance. If it's not previously assigned we establish a dual link (from both sides)we check if an old object has already been assigned to a new object. If this is the case then there is a conflict between assigning two new objects to a single old object, we will compare the distances between
- Previous object and its already assigned old cur_frame object and
- Previous object and the new cur_frame object
Then decide which new object the old object actually corresponds to. The incorrect new object is then marked as not found which represents that this object is found first time and will later be assigned completely new index. After the link has been established, we update the new object's number of frames detected. Now, we calculate the vector for each object in the current frame. The vector for every Object is calculated from the object's midpoint at the 1st frame, and the midpoint at the 5th frame. We store these midpoints in a deque inside previous_frame_objects and/or cur_frame_objects. The deque is kept updated every frame by removing the oldest midpoint and adding the latest midpoint. Next, we check the difference in vector magnitude between previous vector magnitude and the current vector magnitude, if the change in magnitude is greater than the threshold value the current frame is detected as Crash frame. The threshold value is calculated manually, and we checked the accurate value where the crash is detected.
C. Notification System
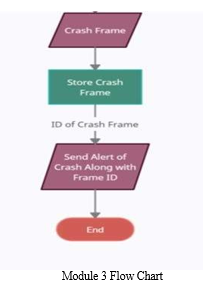
In this module, it takes the input as the crash detected frame. Here, as soon as the crash is detected an immediate notification is sent to the concerned department. The notification is via SMS (Short Message Service). The SMS contains an alert message having crash occurred and link redirecting to the crash images where the crash images are stored. The SMS is sent through an API (Application Programming Interface).
Conclusion
Automatic accident detection became a very important topic in traffic management systems. Traffic surveillance cameras capture the vehicles and is the best way to detect the accidents. Detection of accidents can avoid future accidents by analyzing the accident data like time at which accident occurred, area where frequent accidents take place and thus taking preventive measures at these hot spots. In this Project, we proposed a system that shows the traffic behavior which can be analyzed using vehicle positions, speeds and abnormal activities on the road for accident detection. In this model, when a vehicle meets an accident an immediate notification to the emergency services will be sent. We used RetinaNet for object detection as it is best suited and accurate for vehicle detection. This project can be taken further, we can collect the data of accidents and areas and categorize the frequent accident area and take the required actions. As of now, the proposed system detects the accidents through CCTV traffic surveillance and sends an immediate notification and crash image of the accident to the emergency services. This system can be upgraded to include the location at which accident occurred using gaps systems and also the details of the vehicles involved in crash using enhanced computer vision models and can also be expanded in future with crime/abnormal activity detection and detection of traffic rules violation along with automatic challan generation and can also be implemented in autonomous driving systems to react immediately when an accident occurs in front of vehicle.
References
[1] https://towardsdatascience.com/a-comprehensive-guide-to-convolutional- neural- networks-the-eli5-way-3bd2b1164a53 [2] https://arxiv.org/pdf/1905.05055.pdf#:~:text=Since%20then%2C%20obje ct%20 et ection%20started,%E2%80%9Ccomplete%20in%20one%20step%E2%80%9D [3] https://mega.nz/#!lkFDUaJQ!IpJ00KTEB1LG01XEYfApor9HNvADY3 91g9lE0baP6 ns [4] https://towardsdatascience.com/common-loss-functions-in-machine- learning- 46af0ffc4d23 [5] https://www.kdnuggets.com/2020/08/metrics-evaluate-deep-learning- object- detectors.html [6] https://github.com/Raghav-B/cctv-crash-detector [7] https://keras.io/examples/vision/retinanet/ [8] https://towardsdatascience.com/what-is-map-understanding-the-statistic- of-choice- for-comparing-object-detection-models-1ea4f67a9dbd
Copyright
Copyright © 2023 V. Gopinath, G. Bhavani, G. Uday Sai, G. Chandana. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET50701
Publish Date : 2023-04-20
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online