

Ijraset Journal For Research in Applied Science and Engineering Technology
Ad Demand Forecasting Prediction using Machine Learning
Authors: Dr. P. Sujatha, Bora Mounika, Dukka Raju, Gokavarapu Rahul, Mulli Gangaraju
DOI Link: https://doi.org/10.22214/ijraset.2023.51330
Certificate: View Certificate
Abstract
Introduction
I. INTRODUCTION
In this period of mechanical headway, business knowledge assumes an urgent part in choice parts of the organization connected with future undertakings. Business knowledge (BI) named as the strategies procedure and ideas having a positive effect on the choice for business by excursing the help of truth-based frameworks. It is the design and innovation that changes crude and dissimilar information into significant full instructive information. This instructive information helps with laying out new procedures, empowers functionally greatness, strategic bits of knowledge, and firm decision-production for future parts of the organization.
Business Insight (BI) is positioned to assume an unequivocal part in practically a wide range of businesses in the cutting-edge period and in the not-so-distant future. Business Knowledge (BI) is inescapable for investigation and solid decision-production for a wide range of organizations running up to all areas. It isn't as it was working on the proficiency and viability of big business associations, however, it additionally diminishes the expense and misfortunes. It helps in holding and drawing in clients, moving along deals, and numerous other huge advantages. Business Insight (BI) predicts what's to come in patterns of the market. AI is utilized as one apparatus and innovation as one more device to carry out business knowledge (BI) the idea of utilizing request gauging for a specific business. Request determining is the part of the prescient investigation and become popular over the long run. There are customarily two essential appraisal techniques utilized in popular determining. One is a Subjective assessment and the other one is Quantitative assessment. With time as examination builds, these techniques are expanded into additional kinds and a few different strategies for determining thoughts and blends were presented.
A. Overview of Project
Machine learning is a technology which allows a software program to became more accurate at pretending more accurate results without being explicitly programmed and also ML algorithms uses historic data to predicts the new outputs The main objective of this project is to Predictive Analysis for ad demand prediction. Applications are
1.online Advertisement creation 2.Product demand in ad.
B. Machine Learning
Machine Learning is a category of algorithms that allow software applications to predict much better results without being specifically programmed. The basic premise of machine learning is to build algorithms that receive input data and use statistical analysis to predict output data while output data is updated like many input data become valid. The processes involved in machine learning are similar to the processes of datamining and predictive modelling.
Both require searching for certain patterns by date, and adjusting program actions accordingly. Many people are also familiar with machine learning from internet shopping and the advertisements that are shown to them depending on what they are buying. This is because referral engines use machine learning to customize ads that are delivered online in near real time. In addition to personalized marketing, other well-known cases in which machine learning is used are fraud detection, spam filtering, threat detection of countries in the network, maintenance, predictability, and building the flow of news.
Machine learning is an important component of the growing field of data science. Through the use of statistical methods, algorithms are trained to make classifications or predictions, and to uncover key insights in data mining projects. These insights subsequently drive decision making within applications and businesses, ideally impacting key growth metrics. As big data continues to expand and grow, the market demand for data scientists will increase. They will be required to help identify the most relevant business questions and the data to answer them.
C. Types Of Machine Learning
Machine learning algorithms are categorized as both supervised and unsupervised.
- Supervised Learning
They require a data researcher, or data analyst, who has the knowledge of machine learning to supply the desired input and output data, in addition to delivering feedback on the accuracy of the predictions; acute during algorithm training. Data researchers determine which variables, or characteristics, should be analysed by the model and used to develop predictions. Once the training is complete, the algorithm will apply what it has learned to new data. Supervised learning problems can be further grouped into regression and classification problems.
a. Classification: A classification problem is when the output variable is a category, such as “red” or “blue” or “disease” and “no disease”.
b. Regression: A regression problem is when the output variable is a real value, such as “dollars” or “weight”. Some common types of problems built on top of classification and regression include recommendation and time series prediction respectively.
Some popular examples of supervised machine learning algorithms are: Linear regression for regression problems. Random forest for classification and regression problems, Support vector machines for classification problems.
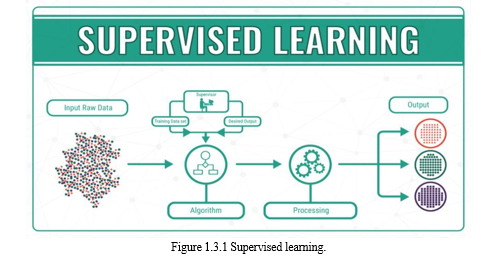
2. Unsupervised Learning
They do not need training with output data. Instead, they use a method called deep learning to review the date and come to conclusions. Unsupervised and learned algorithms, also known as neural networks, are used for more complex processes than supervised algorithms, which include image recognition, speech-to-text, and natural language generation. These neural networks work by first combining millions of training examples with data and automatically identifying subtle correlations between multiple variables. Once trained, the algorithm can be used by associates to interpret new data.
These algorithms become feasible only in the information age, because they require massive amounts of data to train. These are called unsupervised learning because unlike supervised learning above there is no correct answers and there is no teacher. Algorithms are left to their own devises to discover and present the interesting structure in the data. Unsupervised learning problems can be further grouped into clustering and association problems.
a. Clustering: A clustering problem is where you want to discover the inherent groupings in the data, such as grouping customers by purchasing behaviour.
b. Association: An association rule learning problem is where you want to discover rules that describe large portions of your data, such as people that buy X also tend to buy Y. Some popular examples of unsupervised learning algorithms are: k-means for clustering problems., Apriori algorithm for association rule learning problems.
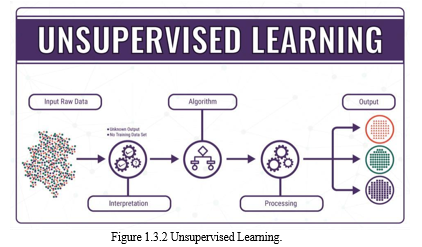
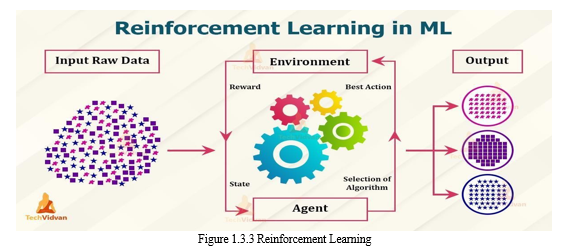
3. Reinforcement Learning
Reinforcement learning is an area of Machine Learning. It is about taking suitable action to maximize reward in a particular situation. It is employed by various software and machines to find the best possible behaviour or path it should take in a specific situation. Reinforcement learning differs from supervised learning in a way that in supervised learning the training data has the answer key with it so the model is trained with the correct answer itself whereas in reinforcement learning, there is no answer but the reinforcement agent decides what to do to perform the given task. In the absence of a training dataset, it is bound to learn from its experience.
???????D. How Does Machine Learning Work?
Machine learning is the brain where all the learning takes place. The way the machine learns is similar to the human being. Humans learn from experience. The more we know, the more easily we can predict. By analogy, when we face an unknown situation, the likelihood of success is lower than the known situation. Machines are trained the same. To make an accurate prediction, the machine sees an example. When we give the machine a similar example, it can figure out the outcome. However, like a human, if its feed a previously unseen example, the machine has difficulties to predict.
The core objective of machine learning is the learning and inference. First of all, the machine learns through the discovery of patterns. This discovery is made thanks to the data. One crucial part of the data scientist is to choose carefully which data to provide to the machine. The list of attributes used to solve a problem is called a feature vector. You can think of a feature vector as a subset of data that is used to tackle a problem.
The machine uses some fancy algorithms to simplify the reality and transform this discovery into a model. Therefore, the learning stage is used to describe the data and summarize it into a model.

Fig: working of Machine learning
II. SYSTEM ANALYSIS
A. Feasibility Study
The feasibility of the project is analyzed in this phase and business proposal is put forth with a very general plan for the project and some cost estimates. During system analysis the feasibility study of the proposed system is to be carried out. This is to ensure that the proposed system is not a burden to the company. For feasibility analysis, some understanding of the major requirements for the system is essential.
Three key considerations involved in the feasibility analysis are,
- Economical Feasibility: This study is carried out to check the economic impact that the system will have on the organization. The amount of fund that the company can pour into the research and development of the system is limited. The expenditures must be justified. Thus the developed system as well within the budget and this was achieved because most of the technologies used are freely available. Only the customized products had to be purchased.
- Technical Feasibility: This study is carried out to check the technical feasibility, that is, the technical requirements of the system. Any system developed must not have a high demand on the available technical resources. This will lead to high demands on the available technical resources. This will lead to high demands being placed on the client. The developed system must have a modest requirement, as only minimal or null changes are required for implementing this system.
- Social Feasibility: The aspect of study is to check the level of acceptance of the system by the user. This includes the process of training the user to use the system efficiently. The user must not feel threatened by the system, instead must accept it as a necessity. The level of acceptance by the users solely depends on the methods that are employed to educate the user about the system and to make him familiar with it. His level of confidence must be raised so that he is also able to make some constructive criticism, which is welcomed, as he is the final user of the system.
III. LITERATURE REVIEW
V. A Thakor Proposed the advantages of Effective Demand Forecasting (2001) is a commonly used process to help predict what both future and current customers are wanting in the future. This will not only tell a company or production facility what customers are buying, but also the products that the company should manufacture. Along with manufacturing, this also pertains to the setting of the price of the good and what markets should be best suited for the company. With proper and accurate demand forecasting, it allows for insight into what customers need, which can be forecasted through a variety of means and methods
Leanne luce proposed Demand forecasting (2020) is a branch of predictive analytics that focuses on gaining an understanding of consumer demand for goods and services . If demand can be understood, brands can control their inventory to avoid overstocking and understocking products. While there is no perfect forecasting model, using demand forecasting as a tool can help fashion businesses better prepare for upcoming seasons.
Herman Stekler proposed Benchmarking of Regression Algorithms and Time Series Analysis Techniques for Sales Forecasting. Predicting the sales amount as close as to the actual sales amount can provide many benefits to companies. Since the fashion industry is not easily predictable, it is not straightforward to make an accurate prediction of sales. In this study, we applied not only regression methods in machine learning, but also time series analysis techniques to forecast the sales amount based on several features.
A paper from M. Ahsan Akter Hasin, Shuvo Ghosh and Mahmud A. Shareef describe an ANN approach to demand forecasting in retail trade in Bangladesh. [12]. Traditional Holt-Winters model for establishing basic forecasting function and ANN is comparing in this paper. Using different product data, they calculate the demand factor, seasonal factor, and marginal cost factor. Holt-Winters model got 29.1% MAPE where Fuzzy Neural Network got only 10.1% MAPE. Their research finds out that a fuzzy artificial neural network can give a better solution [12].
A paper from Z Kilimci, A.Okay Akyuz, Mitat Uysal describes An Improved Demand Forecasting Model Using Deep Learning Approach and Proposed Decision Integration Strategy for Supply Chain [5]. They compared three models where model one had 42.4% MAPE on average, model two had 25.8% MAPE on average and the last model had 24.7% MAPE on average. They use the timeseries method, three different regression methods, and the SVM method.
Another paper from Majed Kharfan and Vicky Wing Kei Chan describes forecasting seasonal footwear demand using machine learning. They used both supervised learning and unsupervised learning. They use regression, classification trees, random forest, neural network, K- nearest neighbor, K mean clustering. That paper measures performance by mean absolute percentage error and mean percentage error. Forecast accuracyand bias helped them tochoose the best method for predicting demand.
The fuzzy-neural network [6] implemented for sales forecasting and demonstrated that this model’s performance is better than traditional neural networks. An approach named Gray extreme machine learning with the Taguchi method [7] which demonstrates better systemperformance than the performance of artificial neural networks. Forecasting for month electricity sales purposedin china uses clustering, regression, and time series analysis techniques. Time series analysis auto sales [9] also carried out in China.
A forecasting engine based on genetic algorithm also embedded [13].
A customer model [14] created a which uses customer- browsing behavior and verified the model on an e- commerce website. Another technique the merger of the SARIMA and wavelet transform method for forecasting. A hybrid model is demonstrated that delivers better performance than the single methods[15].
A hybrid model is designed as a hybrid model, which combines k-means clustering and fuzzy neural network forthe prediction of circuit boards[16]. A model purposed which uses extreme learning machine and harmony search algorithm for prediction of retail supply chains and displayed that the new model provides better performance than the ARIMA models[17]. A fuzzy logic and Naïve Bayes classifier also used for forecasting[18]. Recurrent Neural Networks also implemented to forecast sales [19]. An extreme Machine Learning (ML) algorithm is used for prediction [20].
A. Existing System
The paper aims at analyzing the demand of the ad by the predicting the demand of the ad at the correct scenario. Television markets by the knowledge of market demand ad of over 15 local television. The demand is predicted using the well-known algorithms such as the Partial Least Square (PLS), Autoregressive Integrated Moving Average (ARIMA) and the Artificial Neural Network (ANN). The ad considered for analyzing are advertisement.
The research aims over choosing an appropriate ad for an area selected by the user thus helping the customer to take better and wise decisions. It also suggests the rank of the ad based the suitability to that television.
The prediction which predicts the output is done by analyzing the dataset using supervised machine learning technique such as K nearest neighbor regression algorithm and decision tree learning(ID3).
Disadvantages
- Less amount of accuracy score
- Small level dataset.
- Applicable on small level prediction work.
B. Proposed System
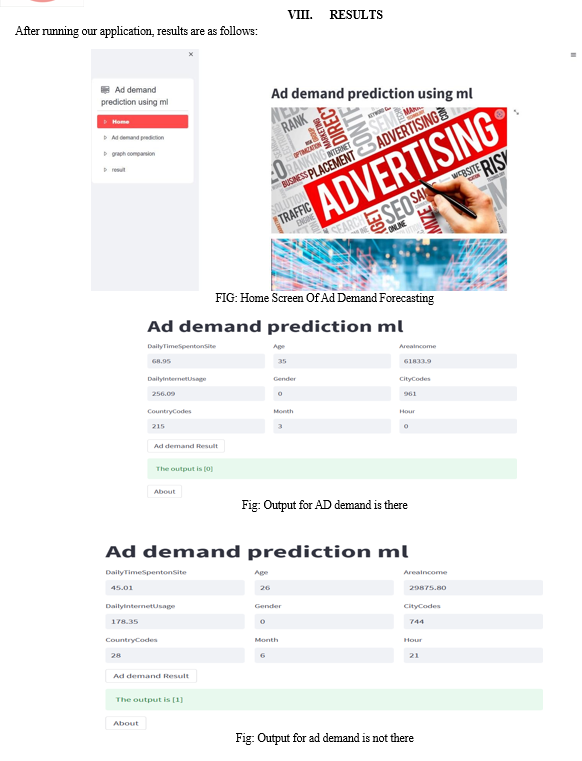
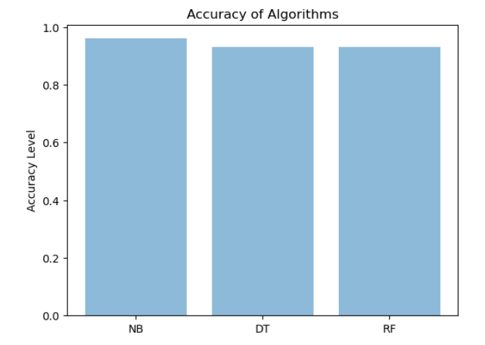
The prediction method will employ 3 machine learning algorithms which are Compare the accuracy of various time series forecasting algorithms such as Naïve bayes, Decision tree and Random forest in machine learning.
- Initialize the dataset containing training data ad demand index
- Select all the rows and column 1from dataset to “x” Which is independent variable
- Select all of the rows and column 2 from dataset to “y” Which is dependent variable
- Fit NB/RF/DT to the dataset 5.Predict the new value
- Visualize the result and check the accuracy
Advantages
- Increasing the accuracy score
- Time complexity was less
- Large amount of feature we are taking for the training and testing.
C. System Requirements
- Software Requirements
- Operating system : Windows 11 Ultimate/8/10/11.
- Coding Language : Python 3.7.0
- Front-End : Html , Css
- Designing : Streamlit Framework
- IDE Tool : Anaconda Navigator and Jupyter Notebook
- Dataset : Advertisement Dataset
2. Hardware Requirements
- System : Pentium IV 2.4 GHz.
- Hard Disk : 40 GB.
- Floppy Drive : 1.44 Mb.
- Monitor : 14’ Colour Monitor.
- Mouse : Optical Mouse.
- Ram : 512 Mb.
IV. SYSTEM DESIGN
A. Architecture
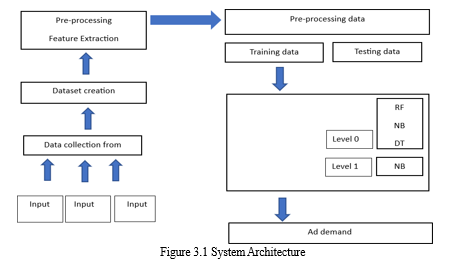
- Input Design
The input design is the link between the information system and the user. It comprises the developing specification and procedures for data preparation and those steps are necessary to put transaction data in to a usable form for processing can be achieved by inspecting the computer to read data from a written or printed document or it can occur by having people keying the data directly into the system. The design of input focuses on controlling the amount of input required, controlling the errors, avoiding delay, avoiding extra steps and keeping the process simple. The input is designed in such a way so that it provides security and ease of use with retaining the privacy. Input Design considered the following things:
a. What data should be given as input?
b. How the data should be arranged or coded?
c. The dialog to guide the operating personnel in providing input.
d. Methods for preparing input validations and steps to follow when error occur.
2. Output Design
A quality output is one, which meets the requirements of the end user and presents the information clearly. In any system results of processing are communicated to the users and to other system through outputs. In output design it is determined how the information is to be displaced for immediate need and also the hard copy output. It is the most important and direct source information to the user. Efficient and intelligent output design improves the system’s relationship to help user decision-making.
a. Designing computer output should proceed in an organized, well thought out manner; the right output must be developed while ensuring that each output element is designed so that people will find the system can use easily and effectively. When analysis design computer output, they should Identify the specific output that is needed to meet the requirements.
b. Select methods for presenting information.
c. Create document, report, or other formats that contain information produced by the system.
The output form of an information system should accomplish one or more of the following objectives.
- Convey information about past activities, current status or projections of the
- Future.
- Signal important events, opportunities, problems, or warnings.
- Trigger an action.
- Confirm an action.
3. Objectives
a. Input Design is the process of converting a user-oriented description of the input into a computer-based system. This design is important to avoid errors in the data input process and show the correct direction to the management for getting correct information from the computerized system.
b. It is achieved by creating user-friendly screens for the data entry to handle large volume of data. The goal of designing input is to make data entry easier and to be free from errors. The data entry screen is designed in such a way that all the data manipulates can be performed. It also provides record viewing facilities.
c. When the data is entered it will check for its validity. Data can be entered with the help of screens. Appropriate messages are provided as when needed so that the user will not be in maize of instant. Thus, the objective of input design is to create an input layout that is easy to follow.
B. UML Diagrams
UML stands for Unified Modeling Language. UML is a standardized general-purpose modeling language in the field of object-oriented software engineering. The standard is managed, and was created by, the Object Management Group.
The goal is for UML to become a common language for creating models of object-oriented computer software. In its current form UML is comprised of two major components: a Meta-model and a notation. In the future, some form of method or process may also be added to; or associated with, UML.
The Unified Modeling Language is a standard language for specifying, Visualization, Constructing and documenting the artifacts of software system, as well as for business modeling and other non-software systems.
The UML represents a collection of best engineering practices that have proven successful in the modeling of large and complex systems.
The UML is a very important part of developing objects-oriented software and the software development process. The UML uses mostly graphical notations to express the design of software projects.
Goals
The Primary goals in the design of the UML are as follows:
Provide users a ready-to-use, expressive visual modeling Language so that they can develop and exchange meaningful models.
- Provide extendibility and specialization mechanisms to extend the core concepts.
- Be independent of particular programming languages and development process.
- Provide a formal basis for understanding the modeling language.
- Encourage the growth of OO tools market.
- Support higher level development concepts such as collaborations, frameworks, patterns and components.
- Integrate best practices.
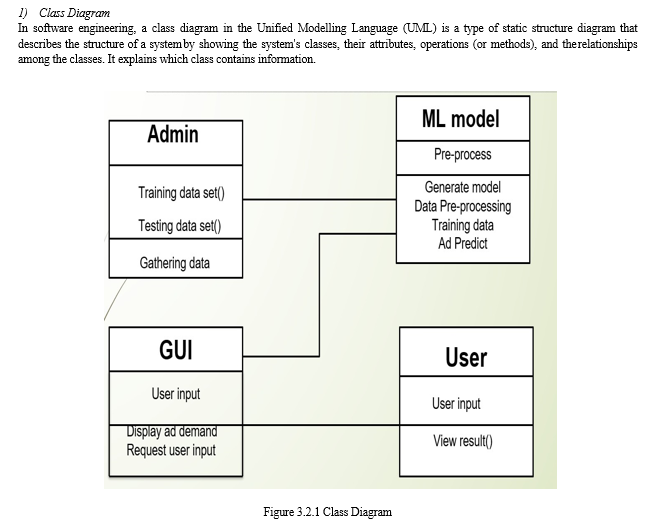
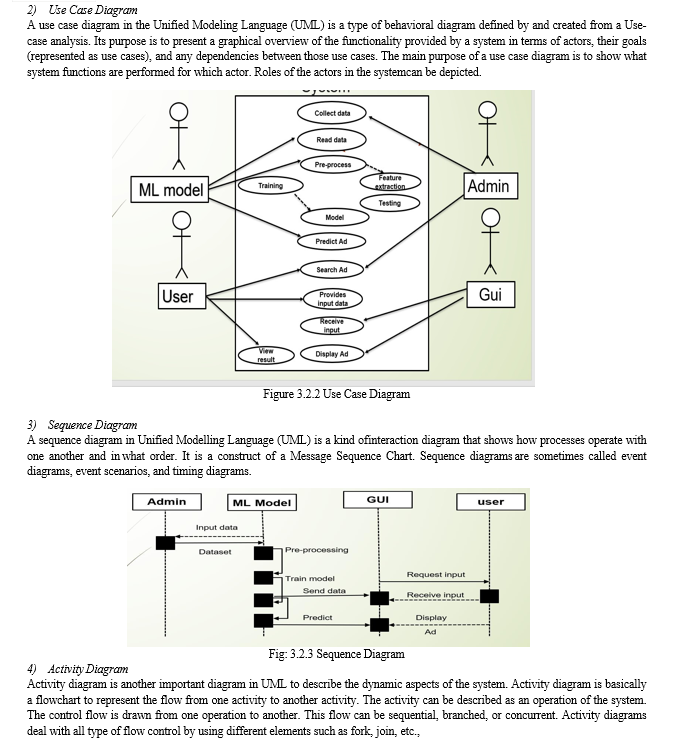
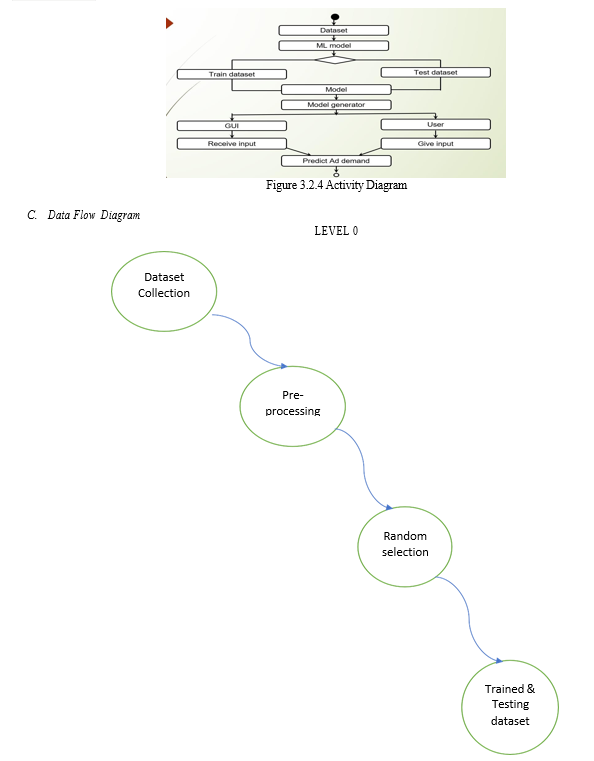
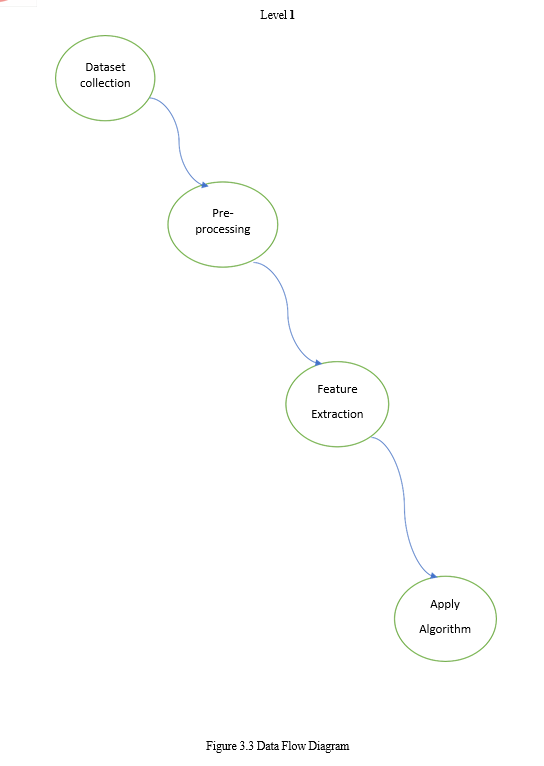
Modules
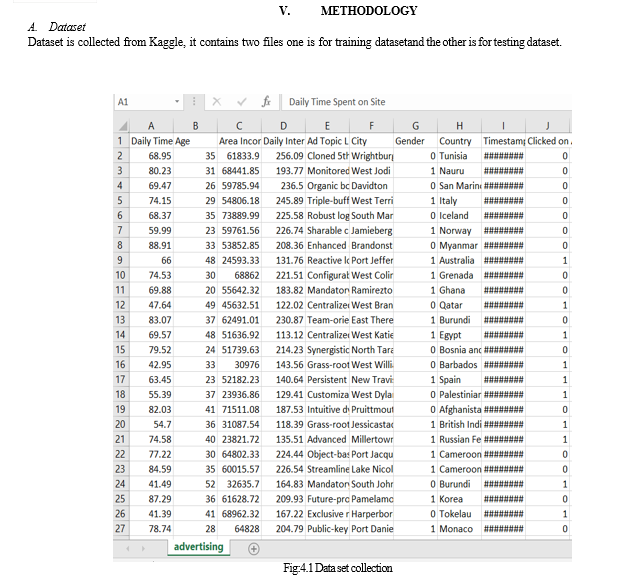
- Dataset Collection
The database design of this research mainly involves historical information database, real-time monitoring database and web crawling database. The historical database is mainly used for historical data query and display, and it also provides data support for subsequent data analysis. Take the information data in the rice planting process. Data collection is a process in which information is gathered from many sources which is later used to develop the machine learning models. The data should be stored in a way that makes sense for problem. In this step the data set is converted into the understandable format which can be fed into machine learning models. Data used in this paper is a set of cervical cancer data with 15 features . This step is concerned with selecting the subset of all available data that you will be working with. ML problems start with data preferably, lots of data (examples or observations) for which you already know the target answer. Data for which you already know the target answer is called labelled data
2. Data Preprocessing
Data pre-processing steps are:
Formatting: The data you have selected may not be in a format that is suitable for you to work with. The data may be in a relational database and you would like it in a flat file, or the data may be in a proprietary file format and you would like it in a relational database or a text file.
Cleaning: Cleaning data is the removal or fixing of missing data. There may be data instances that are incomplete and do not carry the data you believe you need to address the problem. These instances may need to be removed. Additionally, there may be sensitive information in some of the attributes and these attributes may need to be anonymized or removed from the data entirely.
Sampling: There may be far more selected data available than you need to work with. More data can result in much longer running times for algorithms and larger computational and memory requirements. You can take a smaller representative sample of the selected data that may be much faster for exploring and prototyping solutions before considering the whole dataset.
3. Feature Extration
Next thing is to do Feature extraction is an attribute reduction process. Unlike feature selection, which ranks the existing attributes according to their predictive significance, feature extraction actually transforms the attributes. The transformed attributes, or features, are linear combinations of the original attributes.
Finally, our models are trained using Classifier algorithm. We use classify module on Natural Language Toolkit library on Python. We use the labelled dataset gathered. The rest of our labelled data will be used to evaluate the models. Some machine learning algorithms were used to classify pre-processed data. The chosen classifiers were Random forest . These algorithms are very popular in text classification tasks.
4. Evaluation Model
Model Evaluation is an integral part of the model development process. It helps to find the best model that represents our data and how well the chosen model will work in the future. Evaluating model performance with the data used for training is not acceptable in data science because it can easily generate overoptimistic and over fitted models. There are two methods of evaluating models in data science, Hold-Out and Cross-Validation. To avoid over fitting, both methods use a test set (not seen by the model) to evaluate model performance.
Performance of each classification model is estimated base on its averaged. The result will be in the visualized form. Representation of classified data in the form of graphs.
Accuracy is defined as the percentage of correct predictions for the test data. It can be calculated easily by dividing the number of correct predictions by the number of total predictions.
B. Random Forest
An effective alternative is to use trees with fixed structures and random features. Tree collections are called forests, and classifiers built in so-called random forests. The random water formation algorithm requires three arguments: the data, a desired depth of the decision trees, and a number K of the total decision trees to be built.
The algorithm generates each of the K trees. independent, which makes it very easy to parallelize. For each tree, build a complete binary tree. The characteristics used for the branches of this tree are selected randomly, usually with replacement, which means that the same characteristic can occur more than 20 times, even in a single branch. and the leaves of this tree, where predictions are made, are completed based on training data.
The last step is the only point at which the training data is used. The resulting classifier is just a K-lot vote, and random trees. The most amazing thing about this approach is that it actually works remarkably well. They tend to work best when all the features are at least, well, relevant, because the number of features selected for a particular tree is small. One intuitive reason that it works well is the following. Some trees will query unnecessary features.
These trees will essentially make random predictions. But some of the trees will happen to question good characteristics and make good predictions (because the leaves are estimated based on training data).
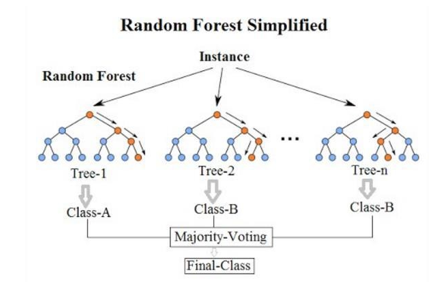
- How the Random Forest Algorithm Works
The following are the basic steps involved in performing the random forest algorithm:
- Pick N random records from the dataset. 2.Build a decision tree based on these N records.
- Choose the number of trees you want in your algorithm and repeat steps 1 and 2.
- In case of a regression problem, for a new record, each tree in the forest predicts a value for Y (output). The final value can be calculated by taking the average of all the values predicted by all the trees in forest.
2. Advantages of using Random Forest
- The random forest algorithm is not biased, since, there are multiple trees and each tree is trained on a subset of data.
- Basically, the random forest algorithm relies on the power of "the crowd", therefore, the overall biasedness of the algorithm is reduced.
- This algorithm is very stable. Even if a new data point is introduced in the dataset the overall algorithm is not affected much since new data may impact one tree, but it is very hard for it to impact all the trees.
- The random forest algorithm works well when you have both categorical and numerical features. The random forest algorithm also works well when data has missing values or it has not been scaled well (although we have performed feature scaling in this article just for the purpose of demonstration).
C. NAÏVE Bayes
The Naïve Bayes classifier is a supervised machine learning algorithm, which is used for classification tasks, like text classification. It is also part of a family of generative learning algorithms, meaning that it seeks to model the distribution of inputs of a given class or category. Unlike discriminative classifiers, like logistic regression, it does not learn which features are most important to differentiate between classes.
???????3. Bayes' Theorem
- Bayes' theorem is also known as Bayes' Rule or Bayes' law, which is used to determine the probability of a hypothesis with prior knowledge. It depends on the conditional probability.
- The formula for Bayes' theorem is given as:
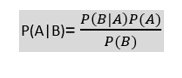
Where,
P(A|B) is Posterior probability: Probability of hypothesis A on the observed event B.
P(B|A) is Likelihood probability: Probability of the evidence given that the probability of a hypothesis is true.
P(A) is Prior Probability: Probability of hypothesis before observing the evidence. P(B) is Marginal Probability: Probability of Evidence.
Working of Naïve Bayes' Classifier can be understood with the help of the below example:
Suppose we have a dataset “Advertisement” and corresponding target variable "ad demand”. So using this dataset we need to decide that whether it had demand or not on a particular ad according to the advertisement. So to solve this problem, we need to follow the below steps:
- Convert the given dataset into frequency tables.
- Generate Likelihood table by finding the probabilities of given features.
- Now, use Bayes theorem to calculate the posterior probability
4. Advantages and disadvantages of the Naïve Bayes classifier Advantages
- Less complex: Compared to other classifiers, Naïve Bayes is considered a simpler classifier since the parameters are easier to estimate. As a result, it’s one of the first algorithms learned within data science and machine learning courses.
- Scales well: Compared to logistic regression, Naïve Bayes is considered a fast and efficient classifier that is fairly accurate when the conditional independence assumption holds. It also has low storage requirements.
- Can handle high-dimensional data: Use cases, such document classification, can have a high number of dimensions, which can be difficult for other classifiers to manage.
5. Disadvantages
- Subject to Zero frequency: Zero frequency occurs when a categorical variable does not exist within the training set. For example, imagine that we’re trying to find the maximum likelihood estimator for the word, “sir” given class “spam”, but the word, “sir” doesn’t exist in the training data. The probability in this case would zero, and since this classifier multiplies all the conditional probabilities together, this also means that posterior probability will be zero. To avoid this issue, laplace smoothing can be leveraged.
- Unrealistic core assumption: While the conditional independence assumption overall performs well, the assumption does not always hold, leading to incorrect classifications.
D. Decision Tree
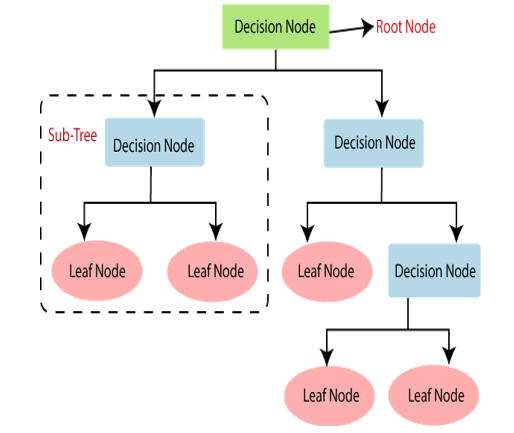
Decision Tree is a Supervised learning technique that can be used for both classification and Regression problems, but mostly it is preferred for solving Classification problems. It is a tree-structured classifier, where internal nodes represent the features of a dataset, branches represent the decision rules and each leaf node represents the outcome.
In a Decision tree, there are two nodes, which are the Decision Node and Leaf Node. Decision nodes are used to make any decision and have multiple branches, whereas Leaf nodes are the output of those decisions and do not contain any further branches. The decisions or the test are performed on the basis of features of the given dataset.
It is called a decision tree because, similar to a tree, it starts with the root node, which expands on further branches and constructs a tree-like structure
Below diagram explains the general structure of a decision tree
- How do Decision Trees Work?
The decision of making strategic splits heavily affects a tree’s accuracy. The decision criteria are different for classification and regression trees. Decision trees use multiple algorithms to decide to split a node into two or more sub- nodes. The creation of sub-nodes increases the homogeneity of resultant sub- nodes. In other words, we can say that the purity of the node increases with respect to the target variable. The decision tree splits the nodes on all available variables and then selects the split which results in most homogeneous sub- nodes.
In a decision tree, for predicting the class of the given dataset, the algorithm starts from the root node of the tree. This algorithm compares the values of root attribute with the record (real dataset) attribute and, based on the comparison, follows the branch and jumps to the next node.
For the next node, the algorithm again compares the attribute value with the other sub-nodes and move further. It continues the process until it reaches the leaf node of the tree. The complete process can be better understood using the below algorithm:
- Step-1: Begin the tree with the root node, says S, which contains the complete dataset.
- Step-2: Find the best attribute in the dataset using Attribute Selection Measure.
- Step-3: Divide the S into subsets that contains possible values for the best attributes.
- Step-4: Generate the decision tree node, which contains the best attribute.
- Step-5: Recursively make new decision trees using the subsets of the dataset created in step -3. Continue this process until a stage is reached where you cannot further classify the nodes and called the final node as a leaf node.


VII. TESTING
A. Testing
The purpose of testing is to discover errors. Testing is the process of trying to discover every conceivable fault or weakness in a work product. It provides a way to check the functionality of components, sub- assemblies, assemblies and/or a finished product It is the process of exercising software with the intent of ensuring that the Software system meets its requirements and user expectations and does not fail in an unacceptable manner. There are various types of tests. Each test type addresses a specific testing requirement.
B. Types Of Tests
1.Unit testing 2.Integration testing 3.Acceptance testing 4.Functional testing 5.Sytem testing 6.2.1UNIT TESTING:
Unit testing involves the design of test cases that validate that the internal program logic is functioning properly, and that program inputs produce valid outputs. All decision branches and internal code flow should be validated. It is the testing of individual software units of the application .it is done after the completion of an individual unit before integration. This is a structural testing, that relies on knowledge of its construction and is invasive. Unit tests perform basic tests at component level and test a specific business process, application, and/or system configuration. Unit tests ensure that each unique path of a business process performs accurately to the documented specifications and contains clearly defined inputs and expected results.
Unit testing is usually conducted as part of a combined code and unit test phase of the software lifecycle, although it is not uncommon for coding and unit testing to be conducted as two distinct phases.
- Test Strategy and Approach
Field testing will be performed manually and functional tests will be written in detail.
2. Test objectives
- All field entries must work properly.
- Pages must be activated from the identified link.
- The entry screen, messages and responses must not be delayed.
3. Features to be Tested
- Verify that the entries are of the correct format
- No duplicate entries should be allowed
- All links should take the user to the correct page.
C. Integration Testing
Integration tests are designed to test integrated software components to determine if they actually run as one program. Testing is event driven and is more concerned with the basic outcome of screens or fields. Integration tests demonstrate that although the components were individually satisfaction, as shown by successfully unit testing, the combination of components is correct and consistent. Integration testing is specifically aimed at exposing the problems that arise from the combination of components.
Software integration testing is the incremental integration testing of two or more integrated software components on a single platform to produce failures caused by interface defects.
The task of the integration test is to check that components or software applications, e.g. components in a software system or – one step up – software applications at the company level – interact without error.
Test Results: All the test cases mentioned above passed successfully. No defects encountered.
D. Acceptance Testing
User Acceptance Testing is a critical phase of any project and requires significant participation by the end user. It also ensures that the system meets the functional requirements.
Test Results: All the test cases mentioned above passed successfully. No defects encountered
E. Functional Test
Functional tests provide systematic demonstrations that functions tested are available as specified by the business and technical requirements, system documentation, and user manuals.
Functional testing is centered on the following items:
Valid Input: identified classes of valid input must be accepted.
Invalid Inpu: identified classes of invalid input must be rejected.
Functions: Identified functions must be exercised.
Output: identified classes of application outputs must be exercise.
Systems/Procedures : interfacing systems or procedures must be invoked.
Organization and preparation of functional tests is focused on requirements, key functions, or special test cases. In addition, systematic coverage pertaining to identify Business process flows; data fields, predefined processes, and successive processes must be considered for testing. Before functional testing is complete, additional tests are identified and the effective value of current tests is determined.
F. System Test
System testing ensures that the entire integrated software system meets requirements. It tests a configuration to ensure known and predictable results. An example of system testing is the configuration-oriented system integration test. System testing is based on process descriptions and flows, emphasizing pre-driven process links and integration points.
- White Box Testing
White Box Testing is a testing in which in which the software tester has knowledge of the inner workings, structure and language of the software, or at least its purpose. It is purpose. It is used to test areas that cannot be reached from a black box level.
2. Black Box Testing
Black Box Testing is testing the software without any knowledge of the inner workings, structure or language of the module being tested. Black box tests, as most other kinds of tests, must be written from a definitive source document, such as specification or requirements document, such as specification or requirements document. It is a testing in which the software under test is treated, as a black box. you cannot “see” into it. The test provides inputs and responds to outputs without considering how the software works.

IX. ACKNOWLEDGEMENT
We sincerely thank the following distinguished personalities who have given their advice and support for the successful completion of the work.
We are deeply indebted to our most respected guide Dr. P. SUJATHA, Associate Professor, Department of CSE, for her valuable and inspiring guidance, comments, suggestions, and encouragement.
We extend our sincere thanks to Mr. G RAJASEKHARAM Associate Prof. & Head of the Dept. of CSE for extending his cooperation and providing the required resources.
We are also thankful to Mr. PRASAD V LOKAM, CEO of Miracle Software Systems Inc. and Dr. A. ARJUNA RAO, Principal of Miracle Educational Society Group of Institutions and Dr. SRINIVASA RAO BEHARA, for their extreme support, cooperation and providing us with excellent state-of-the-art infrastructure without which we could never achieve our goals and targets.
I sincerely thank all the staff members of the department for giving us their support in all stages of the Project work. In all humility and reverence, we express our profound sense of gratitude to our Parents who have given their complete support in this regard.
Conclusion
A. Conclusion Advertising can increase awareness of a product or service, producing an increase in sales. This does not necessarily reflect an increase in its price elasticity of demand because price elasticity represents a change in demand with an increase in price. Customers today expect effective products and hassle free on-time services. These expectations could not be met without a strong supply-chain that involves strategic planning that includes demand forecasting. Business intelligence (BI) practices are also the need of the hour. As business intelligence (BI) practices are applied throughout the enterprise, these practices lead to accurate and effective decision support. BI helps in stabilizing the business, make it more sustainable, and increase productivity. For enterprises, the importance of demand forecast doubles as the day passes. Previously organizations do these calculations manually or some irrational techniques were there. As the market is becoming more dynamic and robust the forecasting has not only changed the organizational philosophy of the business and culture of an organization, it also increases executive support, cooperation, and transparency significantly. In this system, the demand forecasting enhances the operational productivity reduces the losses and wastages, as the company doesn’t have the production Units they purchased items based on forecasting. High forecast accuracy helps in formulating established market strategy, stock turn over increase, decrease in supply chain cost, and an increase in customer satisfaction. B. Future Work In this application, we proposed a system which exactly shows you how . The scope of demand forecasting depends upon the operated area of the firm, present as well as what is proposed in the future. Forecasting can be at an international level if the area of operation is international.
References
[1] Ahn, S. J., and J. N. Bailenson. 2011. Self-endorsing versus other-endorsing in virtual environments. Journal of Advertising 40, no. 2: 93–106. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] [2] Ahn, S. J., J. Kim, and J. Kim. 2022. The bifold triadic relationships framework: A theoretical primer for advertising research in the metaverse. Journal of Advertising 51, no. 5: 592–607. [Taylor & Francis Online], [Google Scholar] [3] Ahn, S. J., L. Levy, A. Eden, A. S. Won, B. MacIntyre, and K. Johnsen. 2021. IEEEVR2020: Exploring the first steps toward standalone virtual conferences. Frontiers in Virtual Reality 2, no. 648575: 1–15. [Google Scholar] [4] Ball, C., E. Novotny, S. J. Ahn, L. Hahn, M. D. Schmidt, S. L Rathbun, K. Johnsen, and M. Potel. 2022. Scaling the virtual fitness buddy ecosystem as a school-based physical activity intervention for children. IEEE Computer Graphics and Applications 42, no. 1: 105–15. [Crossref], [PubMed], [Web of Science ®], [Google Scholar] [5] Belk, R. W. 2013. Extended self in a digital world. Journal of Consumer Research 40, no. 3: 477–500. [Crossref], [Web of Science ®], [Google Scholar] [6] Blascovich, J., J. Loomis, A. C. Beall, K. R. Swinth, C. L. Hoyt, and J. N. Bailenson. 2002. Immersive virtual environment technology as a methodological tool for social psychology. Psychological Inquiry 13, no. 2: 103–24. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] [7] Boerman, S. C., E. A. van Reijmersdal, and P. C. Neijens. 2015. How audience and disclosure characteristics influence memory of sponsorship disclosures. International Journal of Advertising 34, no. 4: 576–92. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] [8] Breves, P., and H. Schramm. 2019. Good for the feelings, bad for the memory: The impact of 3D versus 2D movies on persuasion knowledge and brand placement effectiveness. International Journal of [9] Advertising 38, no. 8: 1264–85. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] Cauberghe, V., M. Geuens, and P. De Pelsmacker. 2011. Context effects of TV programme-induced interactivity and telepresence on advertising responses. International Journal of Advertising 30, no. 4: 641–63. [Taylor & Francis Online], [Web of Science ®], [Google Scholar]. [10] De Pelsmacker, P. 2021. What is wrong with advertising research and how can we fix it? International Journal of Advertising 40, no. 5: 835–48. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] [11] De Pelsmacker, P., M. Geuens, and P. Anckaert. 2002. Media context and advertising effectiveness: The role of context appreciation and context/ad similarity. Journal of Advertising 31, no. 2: 49–61. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] Griffith, D. A., and Q. Chen. 2004. The influence of virtual direct experience (VDE) on on-line ad message effectiveness. Journal of Advertising 33, no. 1: 55–68. [Taylor & Francis Online], [Web of Science ®], [Google Scholar]. [12] Kamins, M. A., L. J. Marks, and D. Skinner. 1991. Television commercial evaluation in the context of program induced mood: Congruency versus consistency effects. Journal of Advertising 20, no. 2: 1–14. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] [13] Kim, J., T. Shinaprayoon, and S. J. Ahn. 2022. Virtual tours encourage tntentions to travel and willingness to pay via spatial presence, enjoyment, and destination image. Journal of Current Issues & Research in Advertising 43, no. 1: 90–105. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] [14] Kumaravel, B.T., C. Nguyen, S. DiVerdi, and B. Hartmann. 2020. Transcei VR: Bridging asymmetrical communication between VR users and external collaborators. In Proceedings of the 33rd Annual ACM Symposium on User Interface Software and Technology, 182–95. Virtual Event USA: ACM. [Crossref], [Google Scholar] [15] Leckenby, J. D., and H. Li. 2000. From the editors: Why we need the journal of interactive advertising. Journal of Interactive Advertising 1, no. 1: 1–3. [Taylor & Francis Online], [Google Scholar] [16] Lee, K.-Y., H. Li, and S. M. Edwards. 2012. The effect of 3-D product visualisation on the strength of brand attitude. International Journal of Advertising 31, no. 2: 377–96. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] [17] Levy, S., and I. D. Nebenzahl. 2006. Programme involvement and interactive behavior in interactive television. International Journal of Advertising 25, no. 3: 309–32. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] Li, H., T. Daugherty, and F. Biocca. 2002. Impact of 3-D advertising on product knowledge, brand attitude, and purchase intention: The mediating role of presence. Journal of Advertising 31, no. 3: 43–57. [Taylor & Francis Online], [Web of Science ®], [Google Scholar] [18] Lou, C., H. Kang, and C. H. Tse. 2021. Bots vs. Humans: How schema congruity, contingency-based interactivity, and sympathy influence consumer perceptions and patronage intentions. International Journal of Advertising 41, no. 4: 655–84. [Google Scholar] [19] Maister, L., F. Cardini, G. Zamariola, A. Serino, and M. Tsakiris. 2015. Your place or mine: Shared sensory experiences elicit a remapping of peripersonal space. Neuropsychologia 70: 455–61. [Crossref], [PubMed], [Web of Science ®], [Google Scholar] [20] McGuinness, D., P. Gendall, and S. Mathew. 1992. The effect of product sampling on product trial, purchase and conversion. International Journal of Advertising 11, no. 1: 83–92. [Taylor & Francis Online], [Google Scholar]
Copyright
Copyright © 2023 Dr. P. Sujatha, Bora Mounika, Dukka Raju, Gokavarapu Rahul, Mulli Gangaraju. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET51330
Publish Date : 2023-04-30
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online