

Ijraset Journal For Research in Applied Science and Engineering Technology
Advancing Autonomous Navigation: Deep Learning Techniques for Self-Driving Cars
Authors: Riya Kapadia, Kush Mehta
DOI Link: https://doi.org/10.22214/ijraset.2023.55491
Certificate: View Certificate
Abstract
The fast development of self-driving car technology has brought forth radical breakthroughs in the world of transportation and movement. This study paper looks into the paradigm shift allowed by deep learning methods in getting stable and reliable autonomous steering for self-driving cars. Leveraging the power of artificial intelligence, particularly deep learning models, this study presents a comprehensive exploration of the multifaceted aspects involved in developing a self-driving car system that can adeptly perceive its environment, make intelligent decisions, and ensure passenger and pedestrian safety. The paper first reviews the basic concepts of self-driving cars, getting into the challenges associated with real-time awareness, scene understanding, and decision-making in complex and dynamic settings. It then shows the important role that deep learning plays in handling these challenges by studying various neural network designs designed for different tasks, including picture recognition, object detection, semantic segmentation, and path planning. The study encompasses convolutional neural networks (CNNs) for picture analysis.
Introduction
I. INTRODUCTION
Going by means of automotive is at present one of the most harmful methods of transportation with over a million passing every year around the world. As basically all automotive incidents (especially fatal ones) are produced by driver error, autonomous vehicles would viably dispose of all hazards related to driving simply as driver deaths, road safety, mobility for everyone, and injuries. In the late 1990s, it became possible to process a massive volume of data at high speed with the rise of general-purpose computers. The predominant technique was to extract a feature vector (called the image local features) from the picture and apply a machine learning algorithm to perform image recognition. Supervised machine learning requires a considerable number of class-label training examples, but it does not need researchers to design precise rules as in the case of rule-based approaches. So, flexible image recognition may be produced. In the 2000 period, handcrafted features such as scale-invariant feature transform (SIFT) and histogram of oriented gradients (HOG) as image local features, constructed based on the experience of researchers, have been actively researched. By blending the picture of local features with machine learning, practical applications of image recognition technology have evolved, as evidenced by face detection. The self-driving vehicle is the latent beast that can make a huge difference. The self-driving automobile is a vehicle furnished with an autopilot framework and is designed for driving without the help of human administrator. This invention was made first employing autonomous strategy but with the development in the field of PC vision and AI we may apply the deep learning technique. There are a number of concerns that need to have been met before introducing self-driving vehicle. One of the most critical characteristics of a self-driving car is autonomous lateral control. Autonomous lateral movements mainly rely on visual processing. The procedure is split into identifying byways, locating by way centre track design, track following, and a control logic.
The precision of such frameworks depends mainly on how well-tuned the picture processing filters are. These techniques are astoundingly sensitive to assortments of illumination and are prone to erroneous identification. An algorithm configured to recognize lane markings in a location where it is bright and sunny may not perform effectively in a place where it is dark and dreary. This technique employs a convolutional neural system to offer controlling points reliant on street pictures. Basically, the model is built up to emulate human driving behaviour. Since an end-to-end model doesn't take a shot at properly specified requirements, it is less affected by variances in lighting settings. Deep learning is a technology that can automate the feature extraction process and is ideal for photo recognition. Deep learning has produced exceptional results in the general object identification contests, and the employment of image recognition essential for autonomous driving (such as object detection and semantic segmentation) is in development. This article explains how deep learning is applied to each task in picture recognition and how it is addressed, and analyse the trend of deep learning-based autonomous driving and accompanying issues.
At the end of this paper, you will attempt to go in detail on how to control an autonomous car, we will develop a model of a car motion and will test our control design in our stimulator.
II. LITERATURE SURVEY
Convolutional neural networks (CNNs) have painted a whole new picture of pattern recognition; moving forward to large scale adoption of CNNs, many of the pattern recognition projects were finished with an initial stage of self-created components which were extracted and further followed by classifiers. The self-driving car is one of the largest and the most intriguing issues these days. The industry will continue to need excellent engineers to give inventive solutions for driving. In this paper, our objective is to train and test the manual functioning of the car which will be done with the help of image processing and will make a model which we will run in our stimulator, after successfully training the model will make our car run on the different track and will try to decrease the error rate as much as possible and make our vehicle run productively in the various track. The features we applied, got information by employing training instances of growth of CNNs. This method is usually applied in picture identification as the convolution activity captures the 2d character of the particular image. Likewise, the convolution kernel peruses the whole image by including a few parameters that contrast with the complete amounts of processes. In recent times and light centre on the attributes and discoveries of CNN they are employed for commercial purposes more often than they were used 20 years from now. There are a few factors to it: 1) big data sets such as ImageNet big Scale Visual Recognition Challenge (ILSVRC) have become increasingly available and may be examined.
2) CNN’s learning algorithm had been put in parallel graphics processing units which enabled fast-track learning DARPA Autonomous Vehicle (DAVE) established the potential of end-to-end learning and was used to validate the DARPA Learning Applied to Ground Robots (LAGR) program. However, DAVE’s success was not stable enough to provide a full alternative to more modular ways to off-road driving: its average spacing between collisions was around 20 m. Recently, a new program has been initiated at NVIDIA, which wants to expand on DAVE and develop a strong system that is capable of learning the whole task of line and path monitoring, without the need for manual decomposition, marking, semantic abstraction, path planning, and control. The purpose for this project is to prevent the necessity to recognize certain features, such as lane lines, guardrails, or other autos.
Pomerleau performed a wonderful challenge by creating DAVE-2 which was done when he bought together an autonomous land vehicle in neural network dated in 1989. It showcased how a trained neural network may drive an automobile on streets. The self-driving car is one of the largest and the most intriguing issues these days. The industry will continue to need excellent engineers to give inventive solutions for driving. In this paper, our objective is to train and test the manual functioning of the car which will be done with the help of image processing and will make a model which we will run in our stimulator, after successfully training the model will make our car run on the different track and will try to decrease the error rate as much as possible and make our vehicle run productively in the various track.
III. BEHAVIOURAL CLONING AND USE OF CNN
CNN every picture is represented in the form of pixel values and it compares photos piece by piece. It is frequently used to study visual pictures by handling information with a grid-like layout. If any of the layers fail to perform their job then the process will never be performed. In the convolutional layer we first line up the feature along with the picture and then increase the pixel value with the matching value of filter and then add them up and drive them with the absolute value of pixels[1]. Re-Lu layer represents the corrected layer unit made by this layer to expel all the bad qualities from the filter picture and afterward change it with zero. The node is triggered if the picture is above a given quality and it is linearly based on the variable considering the input is above benchmark value. Image received from Re-L is shrunk in the shared layer.
CNN has following different layers:
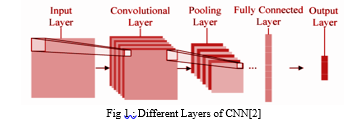
The real sorting is done in a fully linked layer. We take the shouting picture and up that in a single list. And then we match that picture with our previously-stored list and rate the image. The last is the output layer which gives the result of the identified picture. Behavioural cloning is a way by which sub psychological aptitudes like - perceiving things, understanding while simultaneously making an action can be stored and copied in a computer program. The skills performed by human artists are recorded alongside the situation that offered rise to the activity. The learning tool gives a lot of rules that repeat skilled behaviour.
This method is used to build automated control structures for complicated jobs where the classical control view is lacking. In simple words, the work of behavioural cloning is to gather the information and teach the model to impersonate the behaviour with the data that has been gathered.
In summary, these include Deep Neural Network(DNN) we are essentially going to download a self-driving car simulator which is open source by Udacity, we will then use this stimulator to create our very own training data for our model for driving a car through the training track inside the stimulator, as we drive the car through the stimulator we are going to take images at each instance of the drive, these images are going to represent our training dataset and the label of each specific image is the angle on which the car will turn at that given point. After that we will show all the pictures on our CNN and let her learn how to drive independently by studying our behaviour as a manual driver, this key difference that our model will learn to adjust is the car's steering ability at any time, it will learn to effectively turn the steering angle to the right level based on the stimulation it finds itself in. After making the model we test its performance on a unique test track where the car will be driven easily. This behavioural copy method is very helpful and plays a big role in a real-life self-driving car as well. After learning this behavioural copying method, you will successfully be able to understand and even apply the science of self-driving cars.
IV. DEEP LEARNING-BASED IMAGE RECOGNITION
Image recognition prior to deep learning is not always ideal because picture features are extracted and expressed using an algorithm designed based on the knowledge of researchers, which is called a handcrafted feature. Convolutional neural network (CNN) [7]), which is one type of deep learning, is a method for learning classification and feature extraction from training examples. This section describes CNN, focuses on object identification and scene understanding (semantic segmentation), and describes its application to picture recognition and its trends.
A. Convolutional Neural Network (CNN)
As shown in Fig. 2, CNN computes the feature map corresponding to the kernel by convoluting the kernel (weight filter) on the input picture. Feature maps relating to the kernel types can be computed as there are various kernels. Next, the size of the feature map is reduced by the pooled feature map. As a result, it is possible to absorb geometrical changes such as small translation and rotation of the original picture. The convolution process and the pooling process are performed repeatedly to extract the feature map. The extracted feature map is input to fully linked layers, and the chance of each class is finally output. In this case, the input layer and the output layer have a network structure that has units for the picture and the number of classes.
Training of CNN is achieved by changing the values of the network by the backpropagation method. The values in CNN refer to the centre of the convolutional layer and the weights of all coupled layers. The process flow of the backpropagation method is shown in Fig. 2. First, training data is input to the network using the current settings to receive the forecasts (forward propagation). The error is calculated from the guesses and the training label; the update amount of each parameter is received from the error, and each parameter in the network is updated from the output layer toward the input layer (back propagation). Training of CNN refers to repeating these processes to gain good parameters that can recognize the images correctly.
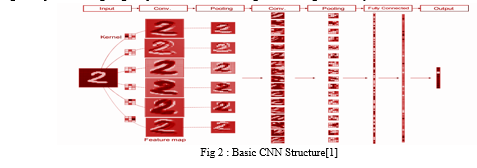
Some visualization examples of kernels at the first convolution layer of the Alex-Net, which is intended for 1000 object class classification jobs at IL-SV-RC (ImageNet Large Scale Visual Recognition Challenge) 2012. Alex-Net consists of five convolution layers and three fully-connected layers, whose output layer has 10,000 units equal to the number of classes. We see that the Alex-Net has automatically gained different filters that extract edge, texture, and colour information with directional components. We examined the effectiveness of the CNN filter as a local image feature by comparing the HOG in the human recognition task. The recognition miss rate for CNN filters is 3%, while the HOG is 8%. Although the CNN kernels of the Alex-Net were not trained for the human detection task, the detection accuracy improved over the HOG feature that is the standard handmade feature. CNN can perform not only image classification but also object identification and semantic segmentation by designing the output layer according to each job of image recognition. For example, if the output layer is intended to produce class chance and detection region for each grid, it will become a network structure that can perform object detection. In semantic segmentation, the output layer should be designed to give the class a chance for each pixel. Convolution and pooling layers can be used as shared modules for these jobs. On the other hand, in the conventional machine learning method, it was necessary to create image local features for each job and mix it with machine learning. CNN has the flexibility to be applied to different tasks by changing the network structure, and this trait is a great advantage in getting image recognition.
B. Application of CNN to object detection task
Conventional machine learning-based object recognition is a method that raster scans two class classifiers. In this case, because the aspect ratio of the object to be recognized is constant, it will be object detection of only a certain group learned as a good example. On the other hand, in object detection using CNN, object proposal regions with different features are detected by CNN, and multiclass object detection is possible using the Region Proposal method that performs multiclass classification with CNN for each found region. Faster RCNN [8] adds Region Proposal Network (RPN) and simultaneously finds object potential areas and recognizes object classes in those regions. First, convolution processing is performed on the full raw picture to build a feature map. In RPN, an item is identified by raster scanning the detection box on the resulting feature map. In raster scanning, recognition windows in the form of k number of shapes are put centre on selected areas known as anchors. The area marked by the anchor is input to RPN, and the score of object likeness and the noted coordinates on the input picture are output. In addition, the area marked by the anchor is also input to another all-connected network, and object detection is performed when it is found to be an object by RPN. Therefore, the unit of the output layer is the number obtained by adding the number of classes and ((x, y, w, h) × number of classes) to one rectangle. These Region Proposal methods have made it possible to find multiple types of things with different aspect ratios. [1][2] In 2016, the single-shot method was suggested as a new multiclass object recognition approach. This is a way to identify multiple items only by giving the whole picture to CNN without raster scanning the image. YOLO (You Only Look Once) is a representative method [9] in which an object rectangle and an object group is given for each local region split by a 7 × 7 grid. First, feature maps are formed through convolution and pooling of raw photos.
The point (I , j) of each channel of the obtained feature map (7 × 7 × 1024) is a structure that becomes an area feature corresponding to the grid (I , j) of the input image, and this feature map is fed to fully connected layers. The output values achieved through fully linked layers are the score (20 categories) of the object category at each grid point and the position, size, and reliability of the two object rectangles. Therefore, the unit of the output layer is the number (1470) in which the position, size, and reliability ((x, y, w, h, reliability) × 2) of two object squares is added to the number of categories (20 categories) and multiplied with the number of grids (7 × 7). In YOLO, it is not necessary to find object area candidates such as Faster R-CNN; therefore, object identification can be performed in real time.
C. CNN for ADAS application
Semantic segmentation is a difficult job and has been studied for many years in the area of computer vision. However, as with other tasks, deep learning-based methods have been suggested and achieved much better success than conventional machine learning methods. Fully convolutional network (FCN) [10] is a method that enables end-to-end learning and can achieve segmentation results using only CNN. The organization of FCN is shown in Fig. 3. The FCN has a network structure that does not have a fully-connected layer. The size of the generated feature map is reduced by frequently running the convolutional layer and the pooling layer on the input picture. To make it the same size as the original picture, the feature map is increased 32 times in the final layer, and convolution processing is performed. This is called deconvolution. The final layer gives the chance map of each class. The probability map is taught so that the probability of the class in each pixel is achieved, and the unit of output of the end-to-end segmentation model is (w × h × number of classes).
Generally, the feature map of the middle layer of CNN gets more detailed information as it is closer to the input layer, and the pooling process integrates these pieces of information, resulting in the loss of detailed information. When this feature map is broadened, coarse segmentation results are achieved. Therefore, high precision is achieved by integrating and using the feature map of the middle layer.
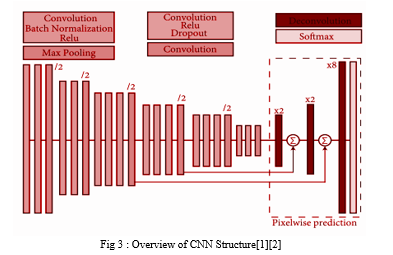
Additionally, FCN performs processing to combine feature maps in the middle of the network. Convolution process is performed by connecting mid-feature maps in the channel direction, and segmentation results of the same size as the original picture are produced. When expanding the feature map received on the encoder side, PSP-Net [1] can record information of different scales by using the Pyramid Pooling Module, which grows at multiple scales. The Pyramid Pooling Module is used to pool feature maps with 1 × 1, 2 × 2, 3 × 3, 3 × 6 × 6 in which the vertical and horizontal sizes of the original image are reduced to 1/8, respectively, on the encoder side. Then, the convolution process is run on each feature map. Next, the convolution process is performed and probability maps of each class are output after growing and linking feature maps to the same size. PSP-Net is the method that won in the “Scene parsing” area of ILSVRC held in 2016. Also, high precision has been achieved with the Cityscapes Dataset [12] shot with a dashboard camera.
V. DEEP LEARNING BASED AUTONOMOUS DRIVING
This section presents end-to-end learning that can determine the control value of the car directly from the input picture as the use of deep learning for autonomous driving, and describes visual explanation of judgment grounds that is the problem of deep learning models and future challenges. This chapter shows end-to-end learning that can determine the control value of the car directly from the input picture as the use of deep learning for autonomous driving, and describes visual description of judgment grounds that is the problem of deep learning models and future challenges.
A. End-to-end learning-based autonomous driving
In most of the research on autonomous driving, the environment around the vehicle is known using a dashboard camera and Light Detection and Ranging (LiDAR), proper traveling position is determined by motion planning, and the control value of the vehicle is determined [1]. Autonomous driving based on these three processes is widespread, and deep learning-based object detection and semantic segmentation described before are starting to be used to understand the surrounding world. On the other hand, with the progress in CNN research, an end-to-end learning-based method has been suggested that can identify the control value of the vehicle straight from the input picture [1][2]. In these methods, the network is taught by using the pictures of the dashboard camera when driven by a person, and the car control value matching to each frame as learning data. End-to-end learning-based autonomous driving control has the advantage that the system setup is simpler because CNN learns naturally and consistently without clear understanding of the surrounding world and motion planning.
To this end, Bojarski et al. offered an end-to-end learning method for autonomous driving, which fed dash-board camera images into a CNN and gave steering angle directory [2]. Started by this work, several works have been conducted: a method considering time structure of a dash-board camera video or a method to train CNN by using a driving simulator and use the trained network to control vehicles under real environment [6]. These methods usually handle only steering angle and throttle (that is accelerator and stop) is managed by humans. According to the autonomous driving model in Reference [1], it infers not only the direction but also the speed as the control value of the car. The network structure is made of five convolutional layers through the pooling process and three layers of fully connected layers. In addition, the inference is made in view of one's own state by giving the vehicle speed to the fully-connected layer in addition to the panel pictures, since it is necessary to infer the change of speed in one's own vehicle for throttle control. In this way, high-precision control of steering and throttle can be achieved in different drive settings.
B. Visual explanation of end-to-end learning
CNN-based end-to-end learning has a problem where the source of output control value is not known. To solve this problem, research is being performed on a method on the judging grounds (such as turning the steering wheel to the left or right and putting on brakes) that can be understood by people. The usual method to clarify the reason for the network decision making is a visual explanation. Visual explanation method outputs an attention map that visualizes the area in which the network focused as a heat map. Based on the received attention map, we can examine and understand the reason for the decision-making. To obtain a more explainable and better attention map for efficient visual explanation, a number of methods have been suggested in the computer vision field. Class activation mapping (CAM) [2] creates attention maps by weighting the feature maps received from the last convolutional layer in a network. A gradient-weighted class activation mapping (Grad-CAM) [1][2] is another popular method, which generates an attention map by using gradient values calculated at the backpropagation process. This method is widely used for a broad analysis of CNNs because it can be applied to any network.
Visual explanation methods have been created for general image recognition tasks while visual explanation for autonomous driving has been also suggested. Visual backprop is developed for visualizing the intermediate values in a CNN, which combines feature maps for each neural layer to a single map. This allows us to understand where the network highly reacts to the input image. A Regression-type Attention Branch Network in which a CNN is split into a feature extractor and a regression branch. By providing vehicle speed in fully connected layers and through end-to-end learning of each branch of Regression-type Attention Branch Network, control values for steering and throttle for various scenes can be output, and also output the attention map that describes the location in which the control value was output on the input image. An example of representation of attention maps is during Regression-type Attention Branch Network-based autonomous driving. S and T in the picture are the turning value and throttle value, respectively. If the road turns to the right where there is a strong response to the centre-line of the road, then steering output value is a positive value showing the right direction. On the other hand, wherever the road curves to the left, the steering output value is a negative value showing the left direction, and the attention map reacts strongly to the white line on the right. By visualizing the attention map in this way, it can be said that the centre-line of the road and the position of the lane are noted for an estimate of the steering value. Also, in the scene where the car stops, the attention map strongly reacts to the brake lamp of the vehicle ahead. The power output is 0, which means that the accelerator and the brake are not pressed. Therefore, it is understood that the state of the car ahead is closely watched in the determination of the throttle. In addition, the night travel scenario shows a scene of following a car ahead, and it can be seen that the attention map strongly reacts to the car ahead because the road shape ahead is unknown. It is possible to visually explain the judgment grounds through the result of an attention map in this way.
C. Future challenges
The visual descriptions help us to study and understand the internal state of deep neural networks, which is efficient for engineers and academics. One of the future problems is explanation for end users, i.e., riders on a self-driving car. In case of fully automatic driving, for instance, when lanes are quickly changed even when there are no vehicles ahead or on the side, the person in the car may be worried as to why the lanes were changed. In such cases, the attention map display technology allows people to understand the reason for changing lines. However, showing the focus map in a fully automatic car does not make sense unless a person on the driverless vehicle always sees it. A person in a driverless car, that is, a person who gets the full advantage of AI, needs to be told of the decision grounds in the form of text or voice saying, “Changing to the left lane as a vehicle from the rear is approaching with speed.” Transitioning from recognition results and visual explanation to vocal explanation will be the challenges to face in the future. In spite of the fact that several tries have been made for this purpose, it does not still achieve sufficient accuracy and flexible speech explanations. Also, in the more distant future, such voice explanation features will soon not be used.
At first, people who receive the full benefit of autonomous driving find it difficult to accept, but a sense of trust will be gradually made by repeating the verbal explanations. Thus, if trust is formed between autonomous driving AI and the person, the voice explanation functions will not be needed, and it can be expected that AI-based autonomous driving will be widely and generally accepted. Deficient generalizability happens as a result of a little database in which controls its application to a natural scenario. These future challenges can be worked upon by getting more insights about deep-learning techniques like image recognition used for self-driving cars.
Conclusion
This study gives one approach under the simulated situation for self-governing driving: the methods use deep learning strategies and end-to-end figure out how to accomplish copying of vehicles. The Nvidia neural network is the main frame of the driver cloning method. It is made of five convolutional layers, one leveling layer and four fully linked layers. The result we receive is the turning angle. The result of its use of autonomous mode is successful autonomous driving along a defined stimulated path through which the model was taught using smaller data sets. It ought to be stressed that all the data needed to train the system are separately made in manual mode, thus building their own databases. We can improve our method by using a better trigger generalization. Deficient generalizability happens as a result of little database in which limits its application to a natural situation. As though now the car in automatic mode is running really well along a set stimulator route.
References
[1] Chirag Sharma, S. Bharathiraja and G. Anusooya, “Self Driving Car Using Deep Learning Technique,\'\' International Journal of Engineering Research & Technology (IJERT), Jun. 2020. [2] Kritika Rana, Dr Parampreet Kaur, “Comparative Study of Automotive Sensor Technologies used for Unmanned Driving [3] ,” 2021 2nd International Conference on Computation, Automation and Knowledge Management (ICCAKM), 2021. [4] Hironobu Fujiyoshi, Tsubasa Hirakawa and Takayoshi Yamashita, “Deep learning-based image recognition for autonomous driving,” IATSS Research, 2019. [5] Jin Gao and Yuwen Hu, “Direct Self-Control for BLDC Motor Drives Based on Three-Dimensional Coordinate System,” IEEE Transactions on Industrial Electronics, Vol..57, No.8, August 2010. [6] Jianqiang Wang, Lei Zhang, Dezhao Zhang, and Keqiang Li, “An Adaptive Longitudinal Driving Assistance System Based on Driver Characteristics,” IEEE Transactions on Intelligent Transport Systems, Vol. 14, No. 1, March 2013. [7] Thomas Herrann, Alexander Wischnewski, Leonhard Hermansdorfer, Johannes Betz, and Markus Lienkamp, “Real-Time Adaptive Velocity Optimization for Autonomous Electric Cars at the Limits of Handling,” IEEE Transactions on Intelligent Vehicles, Vol. 6, No. 4, December 2021. [8] Mattia Laurini, Luca Consolini, and Marco Locatelli, “A Graph-Based Algorithm for Optimal Control of Switched Systems: An Application to Car Parking,” IEEE Transactions on Intelligent Control, Vol. 66, No. 12, December 2021. [9] Christopher B. Kuhn, Markus Hofbauer, Goran Petrovic, and Eckehard Steinbach, “ Introspective Failure Prediction for Autonomous Driving Using Late Fusion of State and Camera Information,” IEEE Transactions on Intelligent Transport Systems,, Vol. 23, No. 5, May 2022. [10] Shaheena Noor, Maria Waqas, Muhammad Imran Saleem, and Humera Noor Minhas, “Automatic Object Tracking and Segmentation Using Unsupervised SiamMask,” IEEE Access, July 2021. [11] Alessio Gambi, Marc Muller, and Gordon Fraser, “AsFault: Testing Self-Driving Car Software Using Search-based Procedural Content Generation,” 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion). [12] Zihan Cao, Yang Liu, Longfei Zhou, Yajun Fang, and Berthold K. P. Horn, “A Macroscopic Traffic Simulation Model to Mingle Manually Operated and Self-driving Cars,” IEEE 4th International Conference on Universal Village · UV2018 · Session 9b-9. [13] Liu Zhaohua, and Gao Bochao, “Radar Sensors “In Automatic Driving Cars,” 2020 5th International Conference on Electromechanical Control Technology and Transportation (ICECTT),2020. [14] Cheng WANG, Chuansheng SI, and Lanchun ZHAG, “Study on Stepless Speed Regulation Actuation Concept and Simulation of the Mini-Car Power Split Automatic,” 2010 Third International Conference on Information and Computing,2010. [15] N. Takahashi, S.Shimizu, Y.Hirata, H.Nara, F.Miwakeichi, N.Hirai, S.Kikuchi, E.Watanabe and S.Kato, “Fundamental study for new assistive system based on brain activity during car driving,” Proceedings of the 2010 IEEE International Conference on Robotics and Biomimetics, December 2010. [16] Yota Hahiba, Ryojun Ikeura, Yota Hasebe, Soichiro Hayakawa and Shigeyoshi Tsutsumi, “Analysis of Cooperative driving characteristics of vehicles by two humans for the application to automatic driving system,” Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics, December 2018. [17] Wen Yao,Yubin Lin, Chao Wang, Huijing Zhao and Hongbin Zha, “Automatic lane change data extraction from car data sequence,” 2014 IEEE 17th International Conference on Intelligent Transportation Systems (ITSC) October 8-11, 2014. Qingdao, China. [18] Dan-Ioan Gota, Alexandra Fanca, Adela Puscasiu, Honoriu Valean, Liviu Miclea, “Driving Evaluation Based on Acceleration, Speed and Road Signs” 2019 23rd International Conference on System Theory, Control and Computing (ICSTCC). [19] Hailiang Zhao, “Motion planning for intelligent cars following roads based on feasible neighborhoods” 2014 IEEE International conference on Control Science and Systems Engineering, 2014. [20] Sandip Roy, and Zhiyang Zhang, “Route Planning for Automatic Indoor Driving of Smart Cars,” 2020 IEEE 7th International conference on Industrial Engineering and Applications, July, 2020. [21] Jie Wen, Jianghua Liu, and Fu Xu, “Intelligent tracking car system based on single chip microcomputer,” 2022 International Seminar on Computer Science and Engineering Technology (SCSET).
Copyright
Copyright © 2023 Riya Kapadia, Kush Mehta. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55491
Publish Date : 2023-08-25
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online