

Ijraset Journal For Research in Applied Science and Engineering Technology
Analysis of Trends in Stock Market
Authors: Abhinav N Patil, Ananya P Mitra, Karan A Paranjpe, Sanjesh Pawale
DOI Link: https://doi.org/10.22214/ijraset.2021.39599
Certificate: View Certificate
Abstract
In the period of AI applications for each and every fragment of examination, breaking down financial exchange costs and patterns has become more famous than previously. We have gathered information of securities exchange utilizing python back end and have proposed a far reaching customization of element designing and profound learning based model for anticipating the pattern of market, The proposed arrangement incorporates pre-handling of the securities exchange dataset, usage of various element designing strategies, joined with a redid profound learning based framework for pattern forecast, Evaluations have been directed on the models and reason that our proposed arrangement beats because of element designing that we constructed. Framework accomplishes decent exactness without the distant element of information overfitting and because of definite assessment of term lengths and strategies, this adds to the stock examination research local area both in monetary and specialized areas.
Introduction
I. INTRODUCTION
Stock market is one of the significant fields that financial backers are especially drawn to and hence market value expectation is consistently a hotly debated issue for analysts from both monetary and specialized areas. In this exploration, our goal is to assemble a condition of-craftsmanship expectation model for value pattern which centers around transient value pattern forecast.
Stock market expectation has been a functioning space of exploration for quite a while. The Efficient Market Hypothesis (EMH) states that securities exchange costs are to a great extent driven by new data and follow an arbitrary walk design. However this theory is broadly acknowledged by the examination local area as a focal worldview administering the business sectors as a rule, a few group have endeavored to separate examples in the manner securities exchanges act and react to outer upgrades.
In this paper, we test a theory dependent on the reason of conduct financial matters, that the feelings and opinions of people influence their dynamic cycle, hence prompting an immediate relationship between's "public opinion" and "market opinion". We perform feeling investigation on freely accessible Twitter information to track down the public state of mind and the level of participation into 2 classes – Positive, Negative. We utilize these opinions and past United Airlines stock qualities to foresee future stock developments and afterward utilize the anticipated qualities in our portfolio the executives methodology.
The remainder of the paper is coordinated as follows.Second some portion of presentation is the writing review we performed on recently acknowledged papers. The second and third area momentarily examines our overall methodology towards taking care of the issue and the accompanying segments talk about the singular parts more meticulously. In Section 4, we momentarily talk about the dataset that we have utilized for this paper and information preprocessing measures took on. Area 5 fundamentally has the execution part and examines the opinion investigation method created by us with the end goal of this paper. It likewise incorporates, exhaustively, the means we followed to foresee United Airlines stock qualities utilizing our opinion investigation results and presents our discoveries. In Section 6, we examine the future work that can be performed on this venture and casing an end on our exploration.
II. LITERATURE SURVEY
The latest work [reference 1] proposes a similar hybrid neural network architecture, integrating a CNN with a bidirectional long short-term memory to predict the stock market index, while researchers frequently proposed different neural network solution architectures, it bought further discussions about the topic if the high cost of training such models is worth the result or not.
There are three key contributions of our work: (1) a new dataset extracted and cleansed (2) a comprehensive feature engineering and (3) customized machine learning models.
As per the productive market speculation, in the monetary market, stock costs quickly change in accordance with new data once it becomes public, making the expectation of financial exchange's developments unthinkable [2]. This judgment is right for conventional investigations utilizing numerous direct relapse examination. Be that as it may, stock costs will become unsurprising assuming the dynamic and nonlinear connections in financial exchanges are shown. This is the inspiration for applying neural organizations to monetary time series investigation. Up to this point, use of neural organizations to anticipate the developments of monetary business sectors has stood out for some researchers.
White [13] proposed neural organization demonstrating and learning strategies to look for and unravel nonlinear normalities of resource value developments and anticipated IBM day by day stock costs, Chenoweth [4] concentrated on the exchanging framework dependent on the future upsides of every day S&P 500 record. Zhang [15] completed different examinations in four sorts of Stock including Lujiazui, Fuhua Industrial, Changchun Hualian, Shanghai Petrochemical utilizing BP network with unique info information. Wang [12] presented the sliding window method and RBF network into non-straight time series, the outcome was great. A portion of these explores only involved the previous upsides of the stock list as the contribution of neural organizations in order to acquire gauges, while others utilized extra monetary elements as information sources
???????III. XGBOOST
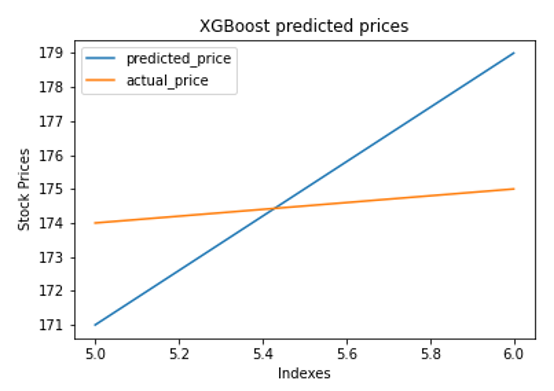
XGBoost is a choice tree-based troupe Machine Learning calculation that utilizes a slope supporting structure. In forecast issues including unstructured information (pictures, text, and so forth) counterfeit neural organizations will generally beat any remaining calculations or systems. Notwithstanding, with regards to little to-medium organized/even information, choice tree based calculations are viewed as top tier at the present time.
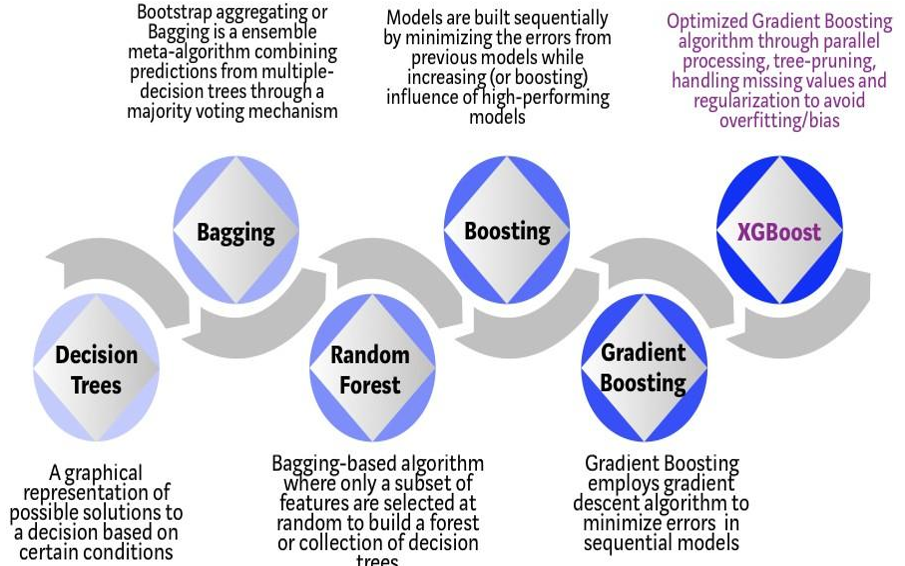
IV .REGRESSION, RANDOM FOREST
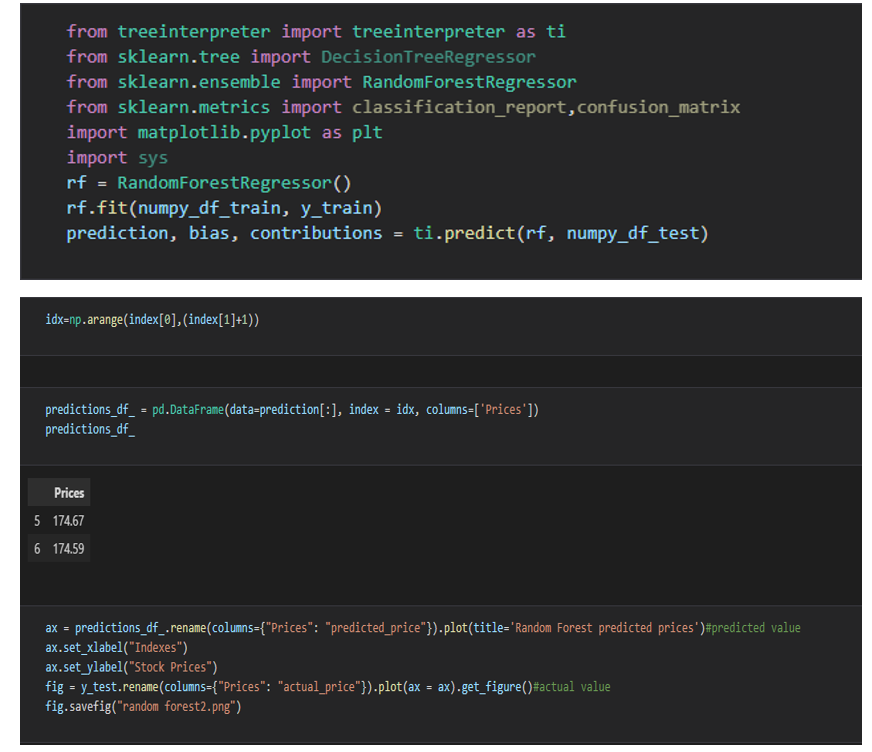
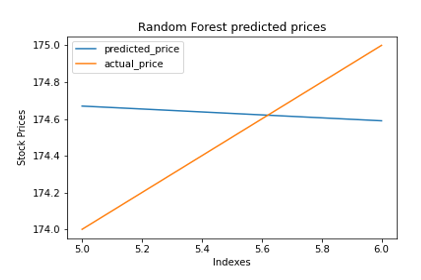
Random forest calculations anticipate the result esteems dependent on input highlights from the information took care of in the framework. The go-to philosophy is the calculation assembles a model on the highlights of preparing information and involving the model to foresee the incentive for new information.
Random Forest is a Supervised Machine Learning Algorithm that is utilized broadly in Classification and Regression issues. It constructs choice trees on various examples and takes their larger part vote in favor of order and normal in the event of relapse.
One of the main elements of the Random Forest Algorithm is that it can deal with the informational collection containing consistent factors as on account of relapse and clear cut factors as on account of characterization. It performs better for characterization issues.
V. DATASET
We are using the yahoo finance datasets for model training. An user interface has been created so that the user can input the company's stock name of his/her choice and get the trends and final prediction price.

VI. IMPLEMENTATION AND RESULTS
A. Data Preprocessing
The dataset obtained from Kaggle initially had a pickle file type which was converted to a csv file for ease of data preprocessing and data training.
The columns necessary for further training and analysis were extracted such as:
- Closing Price
- Adjusted closing price
- Tweets
During the conversion of the pickle file to a csv file, the encoding format used is UTF-8 for ease of translation of any Unicode character to the matching binary string and vice-versa.

B. Sentiment Analysis
Sentiment analysis was a significant piece of our answer since the result of this examination was used as a learning factor in our prescient model. There has been a great deal of examination going on in grouping a piece of text as one or the other positive, negative or unbiased, and we will be taking the advantage of this in our venture. Utilizing feeling investigation, we will break down the tweets as being good or negative and taking their compound outcomes forward.
C. Filtering Punctuations
We shall filter out unnecessary punctuations from each tweet as they do not contribute to the analysis and might also deteriorate the resultant sentiment.

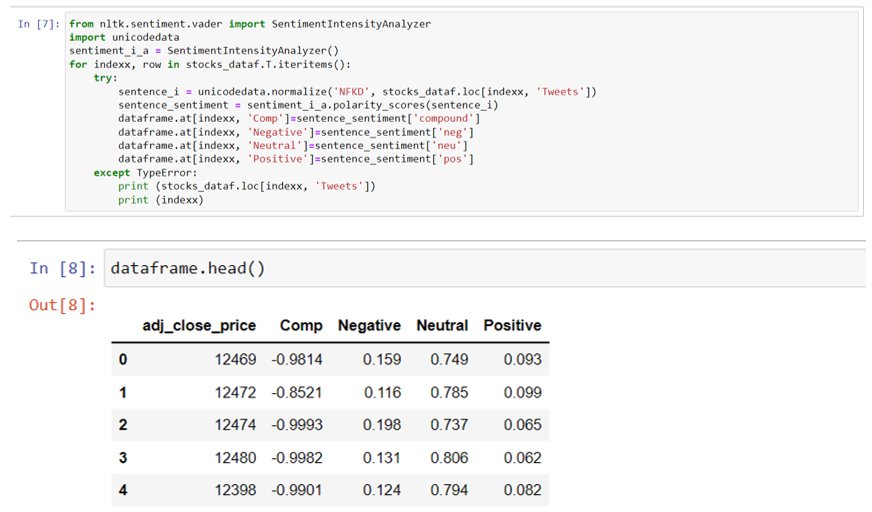
D. Sentiment Analyzer
We shall now apply the SentimentIntensityAnalyzer for the computation of the positivity and negativity of the tweets.
The SentimentIntensityAnalyzer class from VADER, gives a sentiment intensity score to sentences.
VADER (Valence Aware Dictionary and Sentiment Reasoner) is a vocabulary and rule-based sentiment investigation device that is explicitly sensitive to feelings communicated in web-based media. VADER utilizes a mix of feeling dictionary for example a rundown of lexical elements (e.g., words) which are for the most part named by their semantic direction as one or the other positive or negative. VADER not just tells about the Positivity and Negativity score yet additionally enlightens us regarding how positive or negative a feeling is.
If the polarity score is:
- Below 0, it is termed as a Negative Tweet
- Above 0 and approximately greater than 0.5, it is termed as a Positive Tweet
- Otherwise it becomes a Neutral Tweet.
Finally, a compound, i.e. an overall score is calculated to determine the ultimate sentiment of the tweet to be either Positive or Negative.
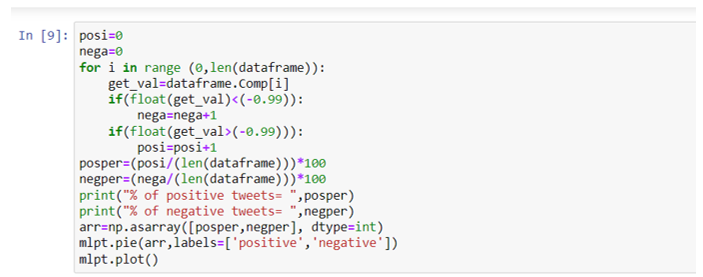
To visualize the sentiment analysis score, the following snippet plots a pie chart displaying the percentage of positive and negative scores.
Random forest improves on bagging because it decorrelates the trees with the introduction of splitting on a random subset of features. This means that at each split of the tree, the model considers only a small subset of features rather than all of the features of the model. That is, from the set of available features n, a subset of m features (m=square root of n) are selected at random.
Think of XGBoost as gradient boosting on ‘steroids’ (well it is called ‘Extreme Gradient Boosting’ for a reason!). It is a perfect combination of software and hardware optimization techniques to yield superior results using less computing resources in the shortest amount of time.
VII. ACKNOWLEDGMENTS
We would like to express our heartfelt appreciation to Prof. Sanjesh Pawale who helped us with the project report. Due to our lack of experience and competence, we ran into a few roadblocks during the project, but he helped us overcome them and integrate our vision in the end. We would like to thank him for his guidance and comments, which helped our entire team understand the project report's finer details. Finally, we would like to express our gratitude to Vishwakarma University's administration for enabling us to participate in these activities.
Conclusion
We conclude our research paper with the facts we reticulated against the comparison of both algorithms we select and on the project as whole. Random forest is expected to always give better result when bagging technique is involved on large scale with in accordance with bootstrapping technique, however, when it comes to minimizing error coefficient for exponential data and gradient boosting, XGBoost is the way to go since it essentially provides more than just gradient tree and using just one algorithm like XGBoost, user can essentially catch out-of-core computing as well as parallel multiple tree nodding together. Trend study in stock has benefitted using these two approaches as the former gives option to bag and bootstrap tree on advance level and the later provides excellent collection of tools to prune and have multiple approaches on how we model the data on every node level. This paper concludes with a starting base for further research on multi-level tree grading algorithms used to analyze stock trends and predict the movement on a bigger and complex scale.
References
[1] McNally S, Roche J, Caton S. Predicting the price of bitcoin using machine learning. In: Proceedings—26th Euromicro international conference on parallel, distributed, and network-based processing, PDP 2018. pp. 339–43. https://doi.org/10.1109/PDP2018.2018.00060. [2] Nagar A, Hahsler M. News sentiment analysis using R to predict stock market trends. 2012. http://past.rinfinance.com/agenda/2012/talk/Nagar+Hahsler.pdf. Accessed 20 July 2019. [3] Ni LP, Ni ZW, Gao YZ. Stock trend prediction based on fractal feature selection and support vector machine. Expert Syst Appl. 2011;38(5):5569–76. https://doi.org/10.1016/j.eswa.2010.10.079. [4] Pang X, Zhou Y, Wang P, Lin W, Chang V. An innovative neural network approach for stock market prediction. J Supercomput. 2018. https://doi.org/10.1007/s11227-017-2228-y. [5] Piramuthu S. Evaluating feature selection methods for learning in data mining applications. Eur J Oper Res. 2004;156(2):483–94. https://doi.org/10.1016/S0377-2217(02)00911-6. [6] Shen J, Shafiq MO. Learning mobile application usage—a deep learning approach. ICMLA. 2019;2019:287–92. [7] Sirignano J, Cont R. Universal features of price formation in financial markets: perspectives from deep learning. Ssrn. 2018. https://doi.org/10.2139/ssrn.3141294. [8] Thakur M, Kumar D. A hybrid financial trading support system using multi-category classifiers and random forest. Appl Soft Comput J. 2018;67:337–49. https://doi.org/10.1016/j.asoc.2018.03.006. [9] Tsai CF, Hsiao YC. Combining multiple feature selection methods for stock prediction: union, intersection, and multi-intersection approaches. Decis Support Syst. 2010;50(1):258–69. https://doi.org/10.1016/j.dss.2010.08.028. [10] Wang X, Lin W. Stock market prediction using neural networks: does trading volume help in short-term prediction?. n.d. [11] Zubair M, Fazal A, Fazal R, Kundi M. Development of stock market trend prediction system using multiple regression. Computational and mathematical organization theory. Berlin: Springer US; 2019. https://doi.org/10.1007/s10588-019-09292-7. [12] Zhang S. Architectural complexity measures of recurrent neural networks, (NIPS). 2016. pp. 1–9. [13] Tushare API. 2018. https://github.com/waditu/tushare. Accessed 1 July 2019. [14] Wang X, Lin W. Stock market prediction using neural networks: does trading volume help in short-term prediction?. n.d. [15] Tsai CF, Hsiao YC. Combining multiple feature selection methods for stock prediction: union, intersection, and multi-intersection approaches. Decis Support Syst. 2010;50(1):258–69. https://doi.org/10.1016/j.dss.2010.08.028. [16] Shih D. A study of early warning system in volume burst risk assessment of stock with Big Data platform. In: 2019 IEEE 4th international conference on cloud computing and big data analysis (ICCCBDA). 2019. pp. 244–8. [17] Qiu M, Song Y. Predicting the direction of stock market index movement using an optimized artificial neural network model. PLoS ONE. 2016;11(5):e0155133. [18] Malkiel BG, Fama EF. Efficient capital markets: a review of theory and empirical work. J Finance. 1970;25(2):383–417. [19] Long W, Lu Z, Cui L. Deep learning-based feature engineering for stock price movement prediction. Knowl Based Syst. 2018;164:163–73. https://doi.org/10.1016/j.knosys.2018.10.034. [20] Lee MC. Using support vector machine with a hybrid feature selection method to the stock trend prediction. Expert Syst Appl. 2009;36(8):10896–904. https://doi.org/10.1016/j.eswa.2009.02.038.
Copyright
Copyright © 2022 Abhinav N Patil, Ananya P Mitra, Karan A Paranjpe, Sanjesh Pawale. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET39599
Publish Date : 2021-12-23
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online