

Ijraset Journal For Research in Applied Science and Engineering Technology
Review on Applications of Object Detection using Deep Learning
Authors: Mohan Kashinath Mali, Vijaya Sayaji Chavan
DOI Link: https://doi.org/10.22214/ijraset.2022.43075
Certificate: View Certificate
Abstract
Human cerebral mantle not requires a second to separate the area of thing inside the image similarly as recall it when it ensures; in spite of that, machine requires a time and large amount of data to perform a similar task. Deep neural network dependent on convolution neural network allows high accuracy and better results in object discovery .To develop deep neural networks, large amount of information such as images, video recordings are required and also it requires large amount of time. As computational cost of PC vision is incredibly high, highly learning methodology, where a model ready on one endeavor is reused on one more associated task, gives improved results. Through the survey and investigation of deep learning-based article recognition techniques recently, this work integrates the going with parts: spine interconnection, setback limits and planning procedures, customary thing distinguishing proof plans, multi-layered issues, the datasets and appraisal aspects, applications, and future headway headings. We belief this overview paper will be helpful for experts in the field of object detection.
Introduction
I. INTRODUCTION
The object Item acknowledgment has a couple of relations with object request, semantic division, and model division. The nuances are displayed in Fig. 1. Article identification is a critical space of PC vision and has huge applications in intelligent assessment and helpful mechanical creation, for example, text location [5], face discovery [6], logo discovery [7], passerby recognition [8], video discovery [9]. Then, gaining from brain associations and related learning structures, the enhancement in these areas will make brain association computations, and will similarly immensely influence object area methodology which can be considered as learning systems. [10]. Anyway, in view of gigantic assortments in viewpoints, stances, hindrances, and lighting conditions, it's difficult to perfectly accomplish object disclosure with an additional a thing restriction task. Such a great deal of thought has been maneuvered into this field actually [11]. The troublesome significance of thing area is to sort out where articles are in each image and which class everything has a spot with. Along these lines, the pipeline of standard thing revelation models can be fundamentally classified into three stages: informative region decision, incorporate extraction and game plan.

Artificial intelligence is getting notable in all ventures with the essential inspiration driving further developing pay and reducing costs; by using Machine learning system they robotize and smooth out their cooperation to handle testing tasks really. Face acknowledgment and walker area are immovably related to traditional thing distinguishing proof and essentially developed with multi-scale adaption and multi-feature mix/supporting forest area, independently. The spotted lines exhibit that the relating spaces are connected with each other under unambiguous circumstances. It should be seen that the covered regions are expanded. Walker and face pictures have common plans, while general things and scene pictures have more awesome assortments in numerical developments and configurations. Along these lines, unprecedented significant models are required by various pictures. Deep learning techniques are additionally used for early suggestion to forestall such clinical sicknesses that emerges with maturing [4].
CNN is the most specialist model of significant learning [12]. A normal CNN designing, which is insinuated as VGG16, can be tracked down in Fig. 1. Each layer of CNN is known as a part map. A Hidden Markov Model is a limited arrangement of states. Changes between these states are administered by a group of probabilities called transition probabilities [13]. The part guide of the information layer is a 3D matrix of pixel powers for different concealing channels (for instance RGB). The part guide of any inside layer is a started multi-channel picture, whose 'pixel' should be visible as a specific component. Every neuron is related with a tad of adjoining neurons from the past layer (responsive field). Different sorts of changes can be coordinated on feature maps [16], for example, sifting and pooling. Separating (convolution) activity tangles a channel lattice (learned loads) with the upsides of an open field of neurons and takes a nonlinear capacity.
II. PROPOSED SYSTEM
A. The goals of Proposed System Are
- To assist with blinding individuals see, not in a real sense yet make life somewhat simpler for them: This gadget will assist with blinding individuals to stroll out and about and do their day to day works all the more without any problem.
- To gather the dataset of the Images: Collection of various sorts of dataset of various article expected for examination and grouping of the pictures. To expand the precision in regards to protest acknowledgment a lot of dataset is required.
- To catch Image utilizing camera: The significant errand is to catch the picture utilizing camera so the acknowledgment of the item should be finished. Camera might be available on the shirt or corner of the shoulder of the client.
- To remove highlights from the Image: Feature Extraction is one of the main assignments in the item acknowledgment and recognition.
- To dissect the elements and examples of the Image: Based on the division of picture various highlights and examples can be examined.
- To perceive the Image
B. Proposed System Design
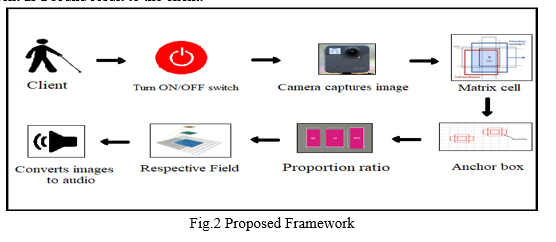
The proposition presents object recognition and recognizable proof gadget for outwardly debilitated individuals. In this venture, we have proposed a gadget for object ID with voice criticism for the outwardly tested. The proposed completely coordinated framework has a camera as an information gadget to take care of the continuous pictures of article encompassed by blind individuals and item discovery and distinguishing proof is finished by Mobile-Net SSD calculation. A system is executed to the acknowledgment of various articles and afterward gives voice criticism. As a feature of the product improvement, the Open CV (Open-source Computer Vision) libraries are used to catch picture of item. Utilizing Mobile-Net SSD calculation object is identified from caught pictures. The proposed framework is prepared with Pascal and COCO datasets to recognize objects from pictures. Once, the item is remembered, it is made accessible as a sound result. Figure 2 shows the framework design of proposed framework.
Client initially needs to turn on the gadget. The gadget will catch the live pictures from encompassing; Then MobileNet SSD calculation will apply on the pictures. SSD separates the picture utilizing matrix cell and have every network cell be liable for distinguishing object around there of picture. Network cells are doled out with different anchor boxes which are answerable for size and shape inside a matrix cell. The proportion boundary can be utilized to determine the different angle proportion of anchor box partners with every lattice cell at each zoom level. The distinguished picture is related to Pascal and COCO datasets. At last, the recognized article is sent as a sound result to the client.
III. EXPECTED RESULTS
- The task means to foster a gadget which will actually want to distinguish the Objects in the encompassing: Using raspberry pi b+ model and camera module the framework will actually want to identify objects in the encompassing.
- Recognition of the recognized Object: The article distinguished by the camera module is then handled by utilizing MobileNetSSD calculation. The development of various anchor boxes is finished. The likelihood of the event of the item in that container is determined. On the off chance that the likelihood is over 20%, that item name is shown on the screen.
- Conversion of text yield into sound structure: Using text-to-discourse libraries, the result in the text structure is changed over into discourse. With the assistance of remote Bluetooth earphones will be heard by the blind person
Conclusion
This Paper present the framework for blind individuals dependent absolutely on object discovery. This framework utilizes SSD (Single Shot Detection) to recognize objects. Article\'s location is utilized to track down objects in reality from a picture of the world. The raspberry-pi camera is utilized to catch continuous pictures from encompassing. To give voice criticism, the recognized picture is changed over into sound configuration utilizing GTTS module. Along these lines, the proposed framework will help the visually impaired individuals to find various items from encompassing and could convey sound as result to the client. This framework is utilized in real time object recognition. The route framework is exceptionally estimated which isn\'t generally reasonable to dazzle individuals. Thus, this undertaking objective is to assist with blinding people groups. Future extension can be recognizing client\'s known individuals when they passed by them. Likewise, to process the hole between the visually impaired individual and each object on the way to effortlessly recognize how lengthy item from them. To make ways of life easy of visually impaired individuals the night vision mode will be accessible in inbuilt camera.
References
[1] Z. Zhao, P. Zheng, S. Xu and X. Wu, \"Object Detection With Deep Learning: A Review,\" in IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 11, pp. 3212-3232, Nov. 2019, doi: 10.1109/TNNLS.2018.2876865. [2] Xiao, Y., Tian, Z., Yu, J. et al. “A review of object detection based on deep learning. Multimedia Tools” Appl 79, 23729–23791 (2020). https://doi.org/10.1007/s11042-020-08976-6 [3] https://towardsdatascience.com/ understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fab [4] Patil V., Ingle D.R. “An association between fingerprint patterns with blood group and lifestyle based diseases”: a review Artif Intell Rev 54, 1803–1839 (2021). https://doi.org/10.1007/s10462-020-09891-w [5] HuangW, Qiao Y, Tang X (2014) “Robust scene text detection with convolution neural network inducedmser trees”. In: European conference on computer vision (ECCV), pp 497–511 [6] Taigman Y, Yang M, Ranzato MA, Wolf L (2014) “Deepface: closing the gap to human-level performance in face verification”. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 1701–1708 [7] Kleban J, Xie X, MaW-Y (2008) “Spatial pyramid mining for logo detection in natural scenes”. In: IEEE international conference on multimedia and expo (ICME), pp 1077–1080 [8] Zhang L, Lin L, Liang X, He K (2016) “Is faster can doing well for pedestrian detection”? In: European conference on computer vision (ECCV), pp 443–457 [9] A. Dundar, J. Jin, B. Martini, and E. Culurciello, “Embedded streaming deep neural networks accelerator with applications,” IEEE Trans. Neural Netw. & Learning Syst., vol. 28, no. 7, pp. 1572–1583, 2017 [10] A. Stuhlsatz, J. Lippel, and T. Zielke, “Feature extraction with deep neural networks by a generalized discriminant analysis.” IEEE Trans. Neural Network & Learning Syst., vol. 23, no. 4, pp. 596–608, 2012. [11] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards realtime object detection with region proposal networks,” in NIPS, 2015, pp. 91–99. [12] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. [13] Swati Warghade, Shubhada Desai, Vijay Patil \"Credit Card Fraud Detection from Imbalanced Dataset Using Machine Learning Algorithm\" International Journal of Computer Trends and Technology 68.3 (2020):22-28. [14] F. M. Wadley, “Probit analysis: a statistical treatment of the sigmoid response curve,” Annals of the Entomological Soc. of America, vol. 67, no. 4, pp. 549–553, 1947. [15] K. Kavukcuoglu, R. Fergus, Y. LeCun et al., “Learning invariant features through topographic filter maps,” in CVPR, 2009. [16] M. Oquab, L. Bottou, I. Laptev, and J. Sivic, “Learning and transferring mid-level image representations using convolutional neural networks,” in CVPR, 2014.
Copyright
Copyright © 2022 Mohan Kashinath Mali, Vijaya Sayaji Chavan. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43075
Publish Date : 2022-05-22
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online