

Ijraset Journal For Research in Applied Science and Engineering Technology
Approximative Signed Wallace Tree Multiplier Using Reversible Logic
Authors: Ragoju Raviteja, Mittapelli Kalyan Krishna, Gare Sandhya, N. Srinivasa Reddy
DOI Link: https://doi.org/10.22214/ijraset.2023.50668
Certificate: View Certificate
Abstract
The bulk of high-performance and information systems, including microcomputers and digital signal processors, have multipliers as an essential piece of hardware. Convolutional unit are the computationally demanding and performance-determining operating units in the vast majority of signal conditioning applications. Its length, latency, and power for convolution units, which largely employ adders and multiplyers, are strongly influenced by multipliers. Multimedia and convolution neural networks, which employ processing units, are two examples of real-world applications that place a high demand on high speed multipliers which are optimised both size and power. This project presents an innovative approximation sign Wallace tree multiplication with a approximative 4:2 compressor. Reversible circuitry improves the design for implementation. The basic Wallace tree multiplier utilises half full adder and full adders inside the partial product accumulating stage, resulting in numerous partial product accumulation stages, because the full adder could only add three bits. This project provides an accurate and an approximative 4:2 compressor that really can add four bytes plus one carry. The partial product accumulating approach requires fewer steps and has a lower latency because it only has to add 5bit once. By counting the delay in nanoseconds, one may calculate the Wallace tree multiplier\'s efficiency. By combining the delay the with current Wallace tree multiplier, it is possible to determine when complete adders are being used.
Introduction
I. INTRODUCTION
The bulk of applications for process control use computationally expensive operational units called convolution layer units to regulate performance. In multiple units, whereby optionals and multiplying are often utilised, the size, durability, and power of doubles are quite helpful. Speed multipliers that are designed for power and size are greatly required in real-world applications requiring processing units used in neural net convolution, multimedia, etc. In general, the multiplication operation is composed of three steps. Production of unfinished goods using several AND gates There are three ways to add a product: 1) partially at the at the conclusion of the procedure; 2) completely at the beginning. As the modulo accumulating phase leads to the total delay, studies have been performed to improve this step to offer the smallest delay possible. delay. Stage 3's last two words employ simultaneous and quick accumulation techniques. Dadda and Wallace's methods had a major role in the accumulation step's successful completion employing delay-optimized designs. Use of compressor rather than adder and half adders results in a further reduction of the accumulation phase delay. The 4:2 compression may realise effective completion designs, in contrast to other topology like the 5: 3, 7: 2, and the others, making it the most widely used compressor architecture. As multipliers are so important for creating space and strength designs for error-tolerant applications, they are now being explored in the context of approximation. such as signal processing, neural networks, and multimedia processing.
II. LITERATURE SURVEY
Survey played a very vital role in this project we have analyzed Akbari et al. [4] has switchable exact and approximation modes. When approximation is used, the hardware cost for switching between exact and approximative modes still applies. A 56.25percentage ER, Bitwise architecture was proposed by Esposito at al. [5]. However, because to its large ER, it performs poorly in image processing applications. Multiplexer-based compressors were recommended by Reddy at al. [6] & Edavoor et al. [7]. It is preferable to put these concepts into practise at the regular gate level. The Gorantla and Deepa [8] suggested 4:2 optimised delaying crushers have a high area/gate count. The compressor configuration of Strollo at al4:2 was provided by rearranging such circuits.
The solutions mentioned above are designed for CMOS-based applications. 4:2 compressors with customised ratios shown in [10] for FPGA-based architecture. Chang and other individuals. A approximately 4:1 compressor suggested by [11] is intended to be implemented using pass transistors. As according Zakian and Asli [12], Fin FET-based technology may provide compressing with a ratio of roughly 4:2. Martin's law's [13] physical restrictions are a constraint on all of the aforementioned designs. In irreversible calculations, KTln2 joules of power are lost for every bit lost. In compared to more advanced technologies, it dissipated very little [14]. The designs mentioned before are improved for CMOS-based applications. For FPGA-based architecture, 4:2 compressors are shown in Toan and Lee [10] offer a compact 4:2 compressor for FPGAs with decreased accuracy losses and enhanced electrical performance. around Chang et al4:1 It has been modified for high pass transistors to function with compressor [11]. A Fin FET-based approach was suggested for a compressors with a ratio of around 4:2, as according Zakian by Asli [12]. All of the aforementioned designs comply with Moore's law's physical restrictions [13]. For every bit lost, calculations which can't be undone require KTln2 energy, measured in joules. When employing more current technology, this evaporation wasn't as obvious [14]. Strategies to mitigate this power cut are being looked into. When devices scale fast, it's important to account for around KTln2 joules of energy per bit. thus, is essential. A brand-new area of research dubbed the reversible method in networks and circuit architecture is now being developed as a solution to this issue. Bennett's 1973 study of comparison on conventional irreversible and reversing systems [15] revealed that the power dissipation is decreased to zero or to very low levels if a reversible model is constructed for a circuit or system. Systems and circuits can grow by using reversible logic gates. a new area of research. the combined irreversible logics of QC, GC, GO, and AI The power of reversible logic.
III. AIM AND OBJECTIVES
A. Aim
To design and improve the speed of operation, 4:2 compressors are used instead of full adders
B. Objectives
- To reduce the time and complexity of the circuit
- Reversible logic concept that can crosscheck the results
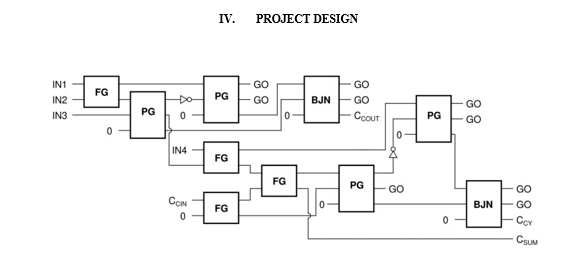
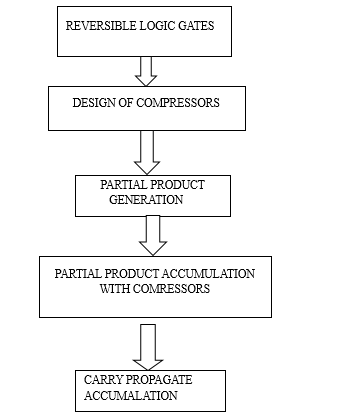
V. METHODOLOGY
Using an approximation adders and reversible logic, this section demonstrates how to create an approximated sign Wallace tree multiplier. The bottom-to-top design methodology entails making all the necessary components first, then using those components to create higher level modules. Compressors such as 12 adders, complete adders, etc. cannot be constructed using any reversible gates until these gates have been created.
VI. SOFTWARE AND HARDWARE REQUIREMENTS
A. Xilinx Vivado
With enhanced system on a chip creation and high-level synthesis capabilities, a software from Xilinx Vivado Design Suite replaces Xilinx ISE. It is utilised in the language of hardware description for design analysis and synthesis (HDL). With the help of Vivado, the architectural flow has been entirely redesigned and rethought (compared to ISE). The logic simulation is incorporated into Vivado like later versions of ISE. Moreover, Vivado provides high synthesis. C code is used to construct the toolset of a programmable circuit.
B. Components
The The Vivado High-Level Synthesis compiler allows programmes composed of C, C++, and SystemC to be targeted specifically at Xilinx hardware without manually writing RTL. It has been demonstrated that Visual studio HLS supports operator overloading, C++ classes, templates, and functions, all of which are known to increase developer productivity. [18] [16] With Vivado 2014.1, support for automatically converting OpenCL kernel to IP on Xilinx hardware was included. OpenCL kernels are programmes that operate on a range of GPU, CPU, and FPGA architectures.
The Vivado Simulator is a component of the a Vivado Design Suite. It's an executable simulation that offers mixed-language scripts along with Tcl scripts, secured IP, and improved verification.
Engineers may use the powerful Xilinx IP library to quickly incorporate and alter intellectual property. IP Integrator by Vivado. The Integrator has also been modified for MathWorks Simulink.
The functionality of Vivado may be added to and changed using the Vivado Tcl Shop, a scripting tool for creating Vivado add-ons. This script Tcl acts as a foundation for Vivado. Tcl script may be used to execute and manage any underlying Vivado function.

Conclusion
From this project we can successfully implement a circuit using baugh wooley algorithm that enhances the speed of operation and reduces the complexity and best optimisation in scales of reversible logic parameters and able to achieve comparable accuracy results.
References
[1] P. J. Edavoor, S. Raveendran, and A. D. Rahulkar, ‘‘Approximate multiplier design using novel dual-stage 4:2 compressors,’’ IEEE Access, vol. 8, pp. 48337–48351, 2020 [2] D. Esposito, A. G.M.Strollo, E. Napoli, D. De Caro, and N. Petra, ‘‘Approximate multipliers based on new approximate compressors,’’ IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 65, no. 12, pp. 4169–4182, Dec. 2018. [3] K. Manikantta Reddy, M. H.Vasantha, Y. B. Nithin Kumar, and D. Dwivedi, ‘‘Design and analysis of multiplier using approximate 4- 2 compressor,’’ AEU Int. J. Electron. Commun., vol. 107, pp. 89–97, Jul. 2019. [4] A. G. M. Strollo, E. Napoli, D. De Caro, N. Petra, and G. D.Meo, ‘‘Comparison and extension of approximate 4-2 compressors for low power approximate multipliers,’’ IEEE Trans. Circuits Syst. I, Reg. Papers, vol. 67, no. 9, pp. 3021–3034, Sep. 2020. [5] A. Gorantla and P. Deepa, ‘‘Design of approximate compressors for multiplication,’’ ACM J. Emerg. Technol. Comput. Syst., vol. 13, no. 3, p. 44, May 2017. [6] N. Van Toan and J.-G. Lee, ‘‘FPGA-based multi-level approximate multipliers for high-performance error-resilient applications,’’ IEEE Access, vol. 8, pp. 25481– 25497, 2020.
Copyright
Copyright © 2023 Ragoju Raviteja, Mittapelli Kalyan Krishna, Gare Sandhya, N. Srinivasa Reddy. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET50668
Publish Date : 2023-04-19
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online