

Ijraset Journal For Research in Applied Science and Engineering Technology
Automatic Synthesis of Realistic Human Faces from Text using GANs
Authors: Kushal Jivarajani, Eeshan Chanpura, Anurag Pande, Mayur Pokharkar, Sarita D. Deshpande
DOI Link: https://doi.org/10.22214/ijraset.2023.53433
Certificate: View Certificate
Abstract
The field of image generation has witnessed significant advancements in recent years, particularly through the application of Generative Adversarial Networks (GANs). Many capable generative adversarial networks (GANs) models have emerged in recent times which help in synthesizing, generating real-like images and playing around with images using text. However, most existing tasks are limited to generating simple images such as flowers from captions.This project aims to create a deep learning based model and a system that tries to generate realistic human facial images from a given textual description. The project explores the utilization and applications of GANs, and uses a particular type like VQGAN. In this work, we extend this problem to the domain of face generation from fine-grained textual descriptions of the human face, e.g. “A person has curly hair, an oval face, and a mustache”. To expedite this process, the project uses VQGAN that is conditioned on the given text using a language conditioning model called CLIP (Contrastive Language-Image Pretraining). The model is trained on the CelebA image dataset. Overall, the project seeks to improve the speed and accuracy of mapping faces to text by leveraging advances in deep learning and image generation. We broaden this objective in our study to the less-explored area of face generation using precise textual descriptions of faces.
Introduction
I. INTRODUCTION
With the emergence of different communication methods, the creation of images from narratives using digital technologies has become a noteworthy area for research. Due to availability of computing power and hugh amount of data in the form of images and visual content, the rise in Deep Learning based models is arisen. Particularly Generative Adversarial Networks (GANs) have revolutionized this field by enabling the generation of realistic and high-quality images from different scenarios that were previously challenging to produce due to its remarkable capabilities in understanding complex patterns and structures in image data and have demonstrated their ability to generate visually appealing and diverse images across various domains, including natural scenes, faces, objects, and artwork. They have been used for tasks such as image synthesis, style transfer, image inpainting, and data augmentation. The popularity of these deep learning-based image generation methods, particularly GANs, is leading itself in finding different applications and use cases.
Through our project we aim to explore one such use case application. The main goal of our project is to create realistic facial images based on textual description. thai involves use of Text-to-face rendering (T2F), a subfield of text-to-image rendering (T2I), where we extend the problem from a good face description to generating a relevant matching face, for example "A man with black beard, an oval face, and curly hair." textual description should generate facial images that have attributes mentioned like a mans face, black beard, and curly hair also.This application also enhances other use cases like public safety, theft recognition, etc.
Starting from this project, we propose a solution to try and create better iterations of images that best fit the description. Our framework leverages high resolution face generators, GAN-based techniques such as VQGAN and DCGAN, and explores the possibility of using it in T2F. Here we use the annotation to trace the written text and facial features in the input field of the GAN. We train our framework on behavior-based annotation to create better images. The presence of finer-grained content and variable-length subtitles makes the problem easier for users, but more challenging compared to other text-based tasks. The images created for the different explanations show good effect.
A. Problem Statement
“Develop an artificial intelligence based model that can generate realistic images of human faces from textual descriptions, using a Generative Adversarial Network (GAN) trained on a large dataset of human faces and corresponding text descriptions. The goal is to create a system that can generate high-quality and diverse images that accurately represent the input text descriptions. ”
B. Objective
- To implement GAN's for generating images from the given text descriptions for the purpose of identifying criminal faces.
- To convert natural language text descriptions into images using Deep Learning.
- Publish research papers and contribute to the academic community's understanding of image generation using GANs.
C. Scope
The automatic synthesis of realistic images from text using GANs is based on disciplines, including computer vision, image generation, natural language processing, and GANs. This cutting-edge technology has a plethora of possible uses, including assisting sketch artists, image editing, video game development, e-commerce design, advertising, and entertainment. GANs technology holds the potential to alter user experiences and build immersive and interactive environments across a variety of sectors thanks to its capacity to generate highly accurate and lifelike images from textual descriptions.
II. EXISTING SYSTEMS
Text-to-facial image synthesis is a relatively new research area that has gained significant attention in recent years. The goal of this research is to generate facial images from textual descriptions, which has a range of applications, including creating realistic avatars for video games and virtual reality, generating personalized emojis, and aiding in criminal investigations by producing images of suspects based on witness descriptions. One of the earlier approaches to text-to-facial image synthesis involved using hand-crafted features and a decision tree to generate images. These early models were limited by their ability to generate images that lacked fine-grained details and could not capture complex features such as facial expressions and lighting. More recent approaches have utilized deep learning models, particularly Generative Adversarial Networks (GANs), to generate more realistic and detailed facial images. For example, researchers have used a Conditional GAN (CGAN) to generate facial images from text descriptions by conditioning the generator network on both the textual input and a latent code. Another approach involves using Variational Autoencoder (VAE) to generate images based on a combination of textual input and an image prior, which helps to improve the realism of the generated images. In addition to these approaches, recent work has also explored the use of attention mechanisms to improve the quality of the generated images. These models use an attention mechanism to focus on specific parts of the text input when generating different parts of the facial image. This helps to ensure that the generated images are more coherent and realistic. Overall, previous work in text-to-facial image synthesis has made significant strides in generating realistic and detailed facial images from textual input. However, there is still room for improvement, particularly in capturing fine-grained details and generating more diverse and expressive facial images.
III. TECHNOLOGY
A. Python
Python is a high-level, interpreted programming language that is widely used in many different domains, including machine learning.Python is a versatile language that is known for its ease of use and readability, as well as its powerful libraries and frameworks. In machine learning, Python is commonly used to build and train machine learning models, as well as to process and analyze large datasets.Python's popularity in machine learning is due mostly because of its adaptability and simplicity of use.. With its vast ecosystem of libraries and frameworks, it has become a go-to language for data scientists and machine learning engineers alike.
B. Google Colab
Google Colab is a product from Google Research. Colab is particularly useful for machine learning, data analysis, and education because it enables anyone to write and run arbitrary Python code through the browser.
C. Pytorch
PyTorch is an open-source machine learning library for Python that allows efficient computation of multi-dimensional arrays using a tensor-based data structure. It offers automatic differentiation and modular design, enabling developers to create complex neural network architectures. PyTorch also supports distributed training across multiple GPUs and CPUs, making it ideal for research and experimentation in deep learning.
IV. GENERATIVE ADVERSARIAL NETWORKS
Generative Adversarial Networks (GANs) are a type of deep learning model that consists of two neural networks, a generator and a, that work together to generate new data that is similar to a training set of real data. The discriminator learns to discriminate between the actual and fake data, while the generator learns to create synthetic data that resembles the training data. The two networks are trained together in a process where the generator aims to produce more realistic synthetic data that can fool the discriminator, and the discriminator aims to correctly identify the real data from the synthetic data.
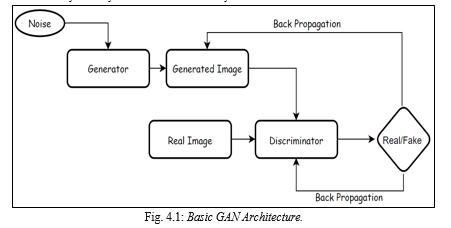
GANs have been successfully applied in various domains, including image, video, and text generation, and have shown promising results in generating high-quality, realistic data that can be used in a range of applications.
Here, GANs form an important part of our Project as our Model is based on GANs architecture, There are different types of GANs architecture that vary based on. One of them is VQGAN (Vector Quantized Generative Adversarial Network).
V. VQGAN
VQGAN (Vector Quantized Generative Adversarial Network) is a deep learning model that combines the power of generative adversarial network (GAN) and Vector Quantization layer to generate high-quality, diverse images from textual prompts. The VQGAN architecture was first introduced in a research paper titled "Making the World a Little More Representable, At Least for a Neural Network" by Patrick Esser, Robin Rombach, and Björn Ommer in 2021.
In this architecture, the generator network produces an initial low-resolution image, which is then refined by a series of residual blocks. The vector quantization layer then maps the continuous latent space to a discrete space, where each latent vector is replaced with the closest vector from a learned codebook of discrete vectors.
This allows the VQGAN to generate high-quality images with a greater degree of control over the features of the generated images. The VQGAN has been used in various applications, including image synthesis, style transfer, and image editing.
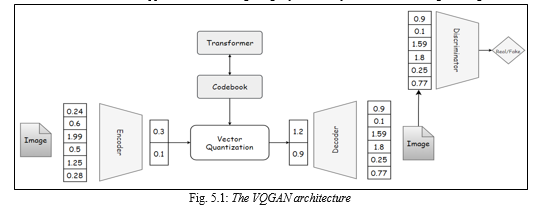
VQGAN uses a pre-trained encoder network to convert textual descriptions into a compressed vector representation, which is then used by the generator network to produce images. The Vector Quantization technique used in VQGAN helps to generate diverse images that match the textual description by clustering similar image patches in the generator output space. The reason for choosing VQGAN is it has shown impressive results in generating realistic images that match textual descriptions and is an active area of research.
The VQGAN is an extension of VQVAE model which is then simply integrated with usual GAN architecture.
Generally when we see an image we seem to see them through discrete representations. Eg. If we see a man. We see the discrete representations: man, white, tall/short, hairs etc. This tells us that our visual reasoning is symbolic. This approach assists us to understand relationships between different words and symbols. This is usually referred to as the ability to model long-range dependencies in machine learning.. VQGAN can learn not only the visual parts of an image, but also the relationship between these parts (long range dependencies).
The VQGAN architecture consists of :
- A convolutional neural network which helps in learning the visual parts of the image. We can learn high level features
- A transformer network to learn long range interactions.
- A codebook which helps in training the transformer.
A two-stage method that learns a representation from the image and encodes it to a different form before feeding it into a transformer is a common feature of most approaches. However, transformers have a limitation: they scale quadratically. As a result we have to reduce the pixel dimensions of the image. Instead of downsampling the image, VQGAN represents the visual components using a codebook. Instead of modelling the image directly from the pixel level, it instead uses the learnt codebook's codewords. By using a codebook as an intermediate representation and feeding it to a transformer network, VQGAN was able to resolve the scale issue with Transformers. Vector quantization (VQ) is then used to learn the codebook.
A signal processing method for encoding vectors is vector quantization. Once delivered to a transformer, it depicts all visual components in a quantized form, which reduces the computational cost. What happens during vector quantization is that we divide vectors into groups with each group having a centroid (codeword). So on a high level we can consider these codewords as discrete symbols. So by training them with a transformer we can under or discover their relationships. The codebook consists of discrete vectors consisting of the same dimensions as of latent vectors generated from encoders. So after encoding our image to a latent space we replace the vector with its nearest vector from the codebook. This process is a complex process because our encoder outputs multiple vectors for each image and each of these will be replaced with corresponding nearest neighbor, this just increases the number of possible latent vectors .

So, what happens in a VQGAN is we give an image as an input to our encoder which then converts this image to a latent space. Then these latent vectors are replaced by the vectors from the codebook and the decoder decodes this to a reconstructed image. Additionally, we also have a discriminator in our training loop which takes in the reconstructed image and the original image and tries to distinguish between real and fake ones. This provides additional information to our encoder and decoder as to how and what to improve to fool the discriminator which leads to mimicking the original data distribution better. With this setup right here we are successfully able to reconstruct our image.
But the question arises how do we generate new images?
To answer the above question we introduce a second stage of VQGAN which are the transformers. Transformers are on the rise now-a-days and are taking over as the de-facto state-of-the-art architecture in all language-related tasks and other domains such as audio and vision. Transformers are free to comprehend and pick up on the intricate connections between the inputs. Creating a model that blends transformer and convolutional architectures in a powerful and expressive way is one of the main objectives.As we know codebook would learn the pattern of the latent vectors and would assign specific codebook vectors to each property. For example we would have a vector which represents green eyes and a vector which represents black hairs. So if we want to construct a face of a boy with brown hairs and blue eyes and long chin we can just take these vectors from code and fuse them together to the decoder to generate the image.
So the transformer here learns which codebook vector would make sense together and which does not. And after learning this it generates new possible combinations of codebook vectors which it thinks would go along together. The reason we are using a transformer is because a codebook vector representing an image is just a sequence and transformers are really good sequences.
We are able to generate images which are way bigger then the training images because the encoder and decoder are fully convolutional architectures and as a result are invariant to image sizes.
VI. CLIP
A neural network model called CLIP (Contrastive Language-Image Pre-Training) was created by OpenAI and is trained to comprehend the link between natural language descriptions and images. It can identify and categorize different visual concepts since it has been pre-trained on a sizable dataset of photos and the descriptions that go with them. by defining textual prompts, CLIP provides a powerful way to control the production of graphics when combined with VQGAN. You can feed a prompt into CLIP to get an embedding that explains the prompt's purpose.
The development of a picture can then be guided by the VQGAN model using this embedding. Essentially, CLIP acts as a bridge between the textual and visual worlds, allowing users to modify the features of the produced image using straightforward natural language instructions. For example, a user could enter a prompt like "a young man with brown beard and white skin with straight black hair" into CLIP, and the resulting embedding could be used to guide the VQGAN in generating an image that matches that description. The VQGAN can also be fine-tuned on specific datasets to generate images that match specific styles or characteristics. The combination of CLIP and VQGAN has shown impressive results in generating high-quality images that match specific prompts, making it a useful tool for various creative and practical applications, such as generating artwork, product designs, or even realistic simulations. For a comprehensive explanation you can refer [6].

In VQGAN, CLIP is used to guide the image generation process by providing a score for how well the generated image matches the input text prompt. This score is computed by comparing the embedding of the generated image with the embedding of the input text using a similarity measure, such as cosine similarity. By incorporating CLIP into VQGAN, the model can generate more accurate and diverse images that better match the input text descriptions.
This model is based on zero-shot transfer, natural language supervision, and multimodal learning.
VII. WORKING
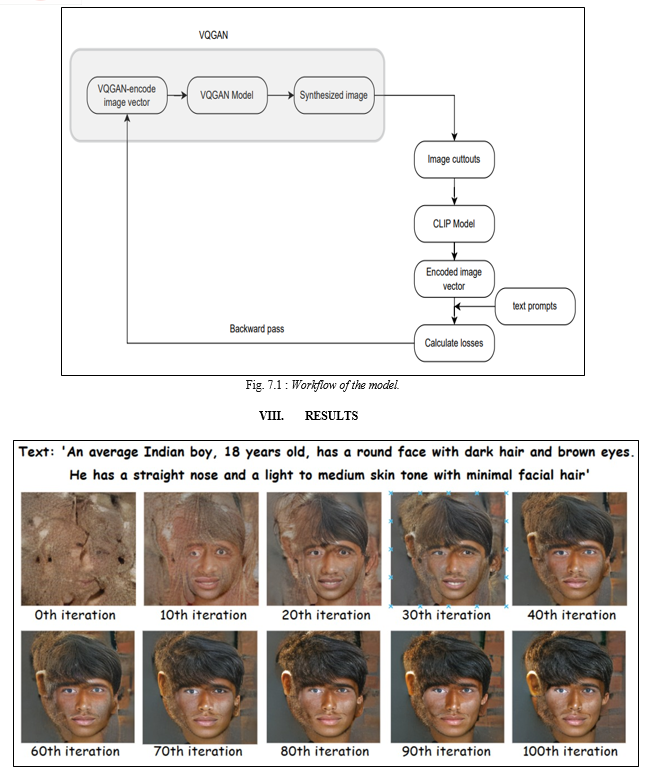
We refer to the interaction between these two networks as VQGAN-CLIP.. They are separate models that work in collaboration. In short, the way they work is that VQGAN generates the images, while CLIP evaluates how well an image matches our input text. This helps our generator to produce more errorless images.
In the case of VQGAN+CLIP we deal with 2 models: VQGAN is trained on a mostly canonical dataset like CelebA or COCO. On the other hand, CLIP was trained using a sizable (unknown) dataset of arbitrary online content.
A. Procedure
- Initially the user gives a text description as an input.
- The generator of VQGAN generates an image and this image is then used by the CLIP model.
- The CLIP model is an evaluation model which takes in the input prompts and generated image and then evaluates the image to find the similarities between them.
- Now as we are familiar with the loss in the image, the GAN generates a new improvised image.
- The above steps are repeated from multiple iterations unless we get a required image which fits the text description.

IX. CHALLENGES
- Training the model on low end devices may result in slow computation and heating up the device.
- Generation and accuracy of the generated face is limited to the significant features of the facial features.
- Generating realistic images from text requires even more data than traditional image synthesis tasks. Additionally GANs need large datasets to train on. Therefore, techniques for scaling up the training process and handling large amounts of data must be developed.
X. FUTURE WORK
Text-to-face generation using GANs has a lot of potential for future development and applications. Here are a few possible areas of future scope:
- Future research on the automatic synthesis of realistic images from text using GANs may concentrate on improving the quality and variety of the generated images, improving the model's handling of complicated and multi-sentence descriptions.
- Using High-end Devices and Infrastructure for faster computation power. Thus increasing scalability of model.
- Adding Speech Navigation for describing the prompt and directly adding the prompt to the model instead of typing it.
- Forensic investigations: Law enforcement agencies could use text-to-face generation to generate images of suspects based on eyewitness accounts. This could potentially help solve cases where traditional composite sketches fall short.
- Medical applications: Text-to-face generation could be used in various medical applications, such as reconstructive surgery planning or facial prosthetics. Doctors could input specific facial feature descriptions to create personalized models for their patients.
- Advertising and marketing: Marketers could use text-to-face generation to create targeted advertisements that feature models with specific facial features that appeal to their target audience.
Conclusion
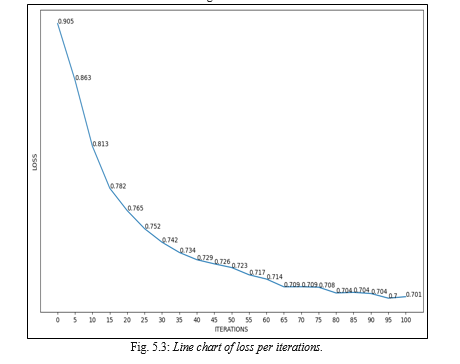
In conclusion, our research has shown that VQGANs can produce decent realistic images from dependable text descriptions. Our tests demonstrated that the model could generate a wide range of graphics that tried to match the input text cues. Although the more and better the prompt of input texts, the better the chances of the model mapping the relevant features and generating clearer noiseless images. VQGANs are computationally demanding and need a lot of training data, thus there is still opportunity for development in terms of scalability and effectiveness. Overall, our findings imply that VQGANs have enormous potential for use in different image and visual content based domains including image editing and style synthesis , game development, entertainment, where realistic facial images can improve the user experience of potential consumers.
References
[1] P. Esser, R. Rombach and B. Ommer from Heidelberg Collaboratory for Image Processing, IWR, Heidelberg University, Germany, \"Taming Transformers for High-Resolution Image Synthesis,\" 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, [2] Ayanthi, Akila & Munasinghe, Sarasi. (2022). Text-to-Face Generation with StyleGAN2. 49-64. 10.5121/csit.2022.120805. [3] T. Xu et al ., \"AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks,\" 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2018, pp. 1316-1324, doi: 10.1109/CVPR.2018.00143. [4] H. Zhang et al., \"StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks,\" in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 8, pp. 1947-1962, 1 Aug. 2019, doi: 10.1109/TPAMI.2018.2856256. [5] H. Zhang et al ., \"StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks,\" 2017 IEEE International Conference on Computer Vision (ICCV) , 2017, pp. 5908-5916, doi: 10.1109/ICCV.2017. [6] Alec Radford, Aditya Ramesh, Jong Wook Kim, Chris Hallacy ., “Learning Transferable Visual Models From Natural Language Supervision” arXiv:2103.00020v1 [cs.CV] 26 Feb 2021. [7] Lj Miranda “The Illustrated VQGAN” 08 Aug 2021. [8] Ryan Moulton Generating panorama images 23 Aug 2021. [9] Hao Hao Tan “Image Generation Based on Abstract Concepts Using CLIP + BigGAN”, Weights and biases, April 2021. [10] Alexa Steinbrück “VQGAN+CLIP — How does it work?” Medium, Aug. 2021. [11] Nagesh Singh Chauhan, ”Generate Realistic Human Face using GAN”, Oct 2020 [12] \"DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis\" by Jing Yu Koh et al. [13] Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran ., “Generative Adversarial Text to Image Synthesis” arXiv:1605.05396v2 [cs.NE] 5 Jun 2016 [14] Katherine Crowson, Stella Biderman, Daniel Kornis ., VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance arXiv:2204.08583v2 [cs.CV] 4 Sep 2022
Copyright
Copyright © 2023 Kushal Jivarajani, Eeshan Chanpura, Anurag Pande, Mayur Pokharkar, Sarita D. Deshpande. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET53433
Publish Date : 2023-05-31
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online