

Ijraset Journal For Research in Applied Science and Engineering Technology
Use of Big Data in the Cloud Computing
Authors: Prof. Nawale Sanchita N, Prof. Vaje Ashwini V
DOI Link: https://doi.org/10.22214/ijraset.2023.55619
Certificate: View Certificate
Abstract
Introduction
I. INTRODUCTION
The successful paradigm for the service oriented programming is the cloud computing. It has revolutionized the way of computing infrastructure’s abstraction and usage. The elasticity, pay per use, low upfront investment, transfer of risks are few of the major enabling characteristics that makes the cloud computing the ubiquitous platform for deploying economically feasible enterprise infrastructure settings. Distributed databases had been the boon of vision for research for few decades. But changes in the data patterns and applications has made way for the new type of storage called key value storage which are now being widely used by various enterprises. In the domain of Map reduce [1] and open source implementation of the same known as the Hadoop [2] has been used by majority of the industry and academics.
Hadoop increases the usability and performance [3, 4].HDFS has become a Very helping tool to maintain and store the complex data. Big data has becoming more available and understandable to computers. What is big data? The question arrives. Big data is the representation of progress of the human cognitive processes, usually includes data sets with sizes that is beyond the current technology’s capability.
The data which is very fast, has various varieties and requires new type of the processing forms to enable decision making, insight discovery and optimization of process. In order for analyzing the data and for identification of patterns it is very important for us to store the data securely, manage and sharing of complex data on cloud. Since cloud involves extensive complexity, we feel its ideal to make enhancements in securing cloud than showing holistic solutions. In this paper we provide a comprehensive background study of state of art systems.
Identification of critical aspects in design of various systems and scope of the systems. We show up some approaches in security provision through a scalable system to handle large number of sites and also has the capability to process large and massive amounts of data. We also provide the status of big data studies and related works, aiming at providing a overview of managing big data and its applications. BIG DATA Big data is a word used for description of massive amounts of data which are either structured, semi structured or unstructured.
The data if it is not able to be handled by the traditional databases and software tech ologies then we categorize such data as big data. The term big data [5] is originated from the web companies who used to handle loosely structured or unstructured data. The big data is defined using three v’s. 1) Volume: many factors contribute for the increase in volume like storage of data, live streaming etc. 2) Variety: various types of data is to be supported. 3) Velocity: the speed at which the files are created and processes are carried out refers to the velocity
Technologies not only supports the collections of large amounts such data effectively. Transactions that are made all over the world in a Bank, Walmart customer transactions, and Facebook users generating social interaction data Are few examples for big data usage. I.
II. HADOOP
This is a freely available java based programming framework supporting for the processing of large sets of data in a distributed computing environment. Using Hadoop, big amount of data sets can be processed over cluster of servers and apps may be run on system with thousands of nodes involving terabyes of information. This lowers the risk of system failure even when a huge number of nodes fail.it enables a scalable, flexible, fault tolerant computing solution. HDFS[6], a file system spanning all nodes in a Hadoop cluster for data storage links the file systems on local nodes to make it onto a very large file system thus improving the reliability
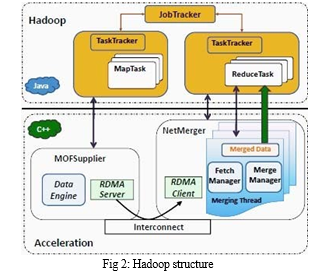
- Task trackers are responsible for running the tasks that the job tracker assigns them
- Job trackers has two primary responsibilities which are managing the cluster resources and scheduling all user jobs
- Data engine consists of all the information about the processing the data
- Fetch manager helps to fetch the data while particular task is running.
III. MAP REDUCE
Map reduce[7] framework is used to write apps that process a large amounts of data in a reliable and fault tolerant way. The application is initially divided into individual chunks which are processed by individual map jobs in parallel. The output of map sorted by a framework and then sent to the reduce tasks. The monitoring is taken care by the framework.
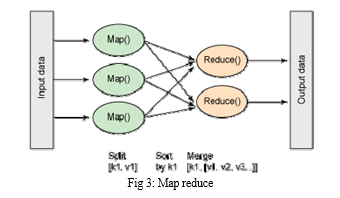
The input data is divided into individual chunks and are provided for processing by the map task. These map task process the data in parallel and the result from the map task is then provided to the reduce task where the results that are generated in parallel by the map task are consolidated and the reduced report is given as output.
A. Big Data Applications
In the current age of data explosion, parallel processing is very much essential for performing a massive volume of data in a timely manner. Parallelization techniques and algorithms are used to achieve better scalability and performance for processing big data. Map reduce is a very popularly used tool or model used in industry and academics. The two major advantages of map reduce are encapsulation of data storage, distribution, replication details. It is very simple for use by the programmers to code for the map reduce task. Since the map reduce is schema free and index free, it requires parsing of each records at the reading point. Map reduce has received a lot of attentiveness in the fields of data mining, information retrieval, image retrieval etc.
The computation becomes difficult to be handled by traditional data processing which triggers the development of big data apps[8]. Big data provides an infrastructure for maintaining transparency in manufacturing industry, which has been having the ability to unreveal uncertainties that exists in the component performance and availability. Another application of the big data is the field of bioinformatics [9] which requires large scale data analysis.
B. Advantages of Big Data
The big data allows an individual to analyze the threats he/she faces internally by naooing onto the entire data landscape over the company using the rich set of tools that the software supporting the big data provides. This is an important advantage of big data since it allows the user to make the data safe and secure. The speed, capacity and scalability of cloud storage provides a mere advantage for the company and organization. Big data even allows the end users to visualize the data and companies can find new business opportunities. Data analytics is one more notable advantage of the big data where in which the individual is allowed to personalize the content or to look and feel the real time websites.
IV. CHALLENGES AND DISCUSSIONS
We live in the period of the big data where we can gather more information from daily life of human being. So far, researchers are unable to unify the features that are more essential to big data, many think that big data is something which we cannot process using existing technology, theory or any methods of such kind. However the world has become helpless since enormous amount of data is being generated by science,business and even society. Big data has posed many challenges to the IT industry.
A. Big Data Management
The needs of the big data are not being satisfied by the current technologies and the speed of increasing storage capacity is much less compared to the data. Thus a revolution reconstruction of information framework is needed very much. For this we need to design a hierarchical architecture for storage. The heterogeneous data are not efficiently handled by the efficient
Algorithms that exist now and thus we need to even design a very efficient algorithm for the effective handling of the heterogeneous data.
B. Necessity of Security in big Data
The big data is used by many of the business but they may not have assets from perspective of the security. If any security threat occurs to big data, it may come out with even more serious issue. Nowadays, companies use this technology to store data of petabyte range regarding to the company, business and customers. This result in severe criticality for classification of information.to secures the data we either need to encrypt, log or use honeypot techniques. The challenge of detecting threats and malicious intruders, must be solved using big data style analysis.
Analysis and computation of big data: Speed is the main thing when we look up for querying in the big data. However the process may be time consuming only because of the reason that it cannot traverse all related data in the whole database in a short time. While the big data is getting complicated, the indices in the big data are aiming at the simple type of the data. The traditional serial algorithm is inefficient for this big data.
C. ??????????????Proposed Approaches For Security Of Big Data In Cloud Computing Environment
Here we present few security measures that can be used to improve the cloud computing environment.
- Encryption: Since the data in any syatem will be present in a cluster, a hacker can easily steal the data from the system. This may become a serious issue for any company or organization to safeguard their data. To avoid this, we may go for encrypting the data. Different encryption mechanisms can be used omn different systems and the keys generated should be stored secretly behind firewalls. By choosing this method the data of the user may be kept securely.
- Nodes Authentication: The node must be authenticated whenever it joins the cluster. If the node turns out to be a malicious cluster then such nodes must not be authenticated.
- Honeypot Nodes: The honeypot nodes appears to be like a regular node but is a trap. It automatically traps the hackers and will not allow any damage to happen to the data.
- Access Control: The differential privacy and access control in the distributed environment will be a good measure of security. To prevent the information from leaking we use a SELinux[17]. The Security Enhanced Linux is a feature that provides the mechanism for supporting access control security policy through the use of linux Security modules in linux kernels.
Conclusion
This paper gave a description of a systematic flow of survey of the big data in the environment of cloud computing. We discussed about the applications, advantages and challenges faced by big data when used over a cloud computing environment. We proposed few solutions to safeguard the data in the cloud computing environment. In future, the challenges are need to be overcome and make way for the even more efficient use of the big data by the user on a cloud computing environment. It is very much needed that the computer scholars and IT professionals to cooperate and make a successful and long term use of cloud computing nd explore new ideas for the usage of the big data over cloud environment.
References
[1] D. Borthakur, “The hadoop distributed file system: Architecture and design,” Hadoop Project Website, vol. 11, 2007. [2] The Apache Hadoop Project. http://hadoop.apache.org/core/, 2009. [3] A. Abouzeid, K. B. Pawlikowski, D. J. Abadi, A. Rasin, and A. Silberschatz. HadoopDB: An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads. PVLDB,2(1):922–933, 2009. [4] A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka, S. Anthony,H. Liu, P. Wyckoff, and R. Murthy. Hive - A Warehousing Solution Over a Map-Reduce Framework. PVLDB, 2(2):1626–1629, 2009. [5] A, Katal, Wazid M, and Goudar R.H. \"Big data: Issues, challenges, tools and Good practices.\". Noida: 2013, pp. 404 – 409, 8-10 Aug. 2013. [6] K, Chitharanjan, and Kala Karun A. \"A review on hadoop — HDFS infrastructure extensions.\". JeJu Island: 2013, pp. 132-137, 11-12 Apr. 2013. [7] Wie, Jiang , Ravi V.T, and Agrawal G. \"A Map-Reduce System with an Alternate API for Multi-core Environments.\". Melbourne, VIC: 2010, pp. 84-93, 17-20 May. 2010. [8] F.C.P, Muhtaroglu, Demir S, Obali M, and Girgin C. \"Busines on big dataapplications.\" Big Data, 2013 IEEE International Conference, Silicon Valley, CA, Oct 6-9, 2013, pp.32 - 37. [9] Xu-bin, LI , JIANG Wen-rui, JIANG Yi, ZOU Quan \"Hadoop Applications in Bioinformatics.\" Open Cirrus Summit (OCS), 2012 Seventh, Beijing, Jun 19-20, 2012, pp. 48 – 52 [10] Venkata Narasimha Inukollu , Sailaja Arsi and Srinivasa Rao Ravuri “Security issues associated with big data in cloud computing “International Journal of Network Security & Its Applications (IJNSA), Vol.6, No.3, May 2014
Copyright
Copyright © 2023 Prof. Nawale Sanchita N, Prof. Vaje Ashwini V. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55619
Publish Date : 2023-09-04
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online