

Ijraset Journal For Research in Applied Science and Engineering Technology
Blind Person Assistant: Object Detection
Authors: Aniket Birambole, Pooja Bhagat, Bhavesh Mhatre, Prof. Aarti Abhyankar
DOI Link: https://doi.org/10.22214/ijraset.2022.40850
Certificate: View Certificate
Abstract
It’s a known fact that estimated number of blind persons in the world is about 285 million, approximately equal to the 20% of the Indian Population. They are mostly dependent on someone for even accessing their basic daily needs. In our project, we used TensorFlow, it\'s a new library from Google. TensorFlow model our neural networks. The TensorFlow Object Detection API is used to detect many objects. We have Introduce an algorithm (SSD). SSD uses a similar phase while training, to match the appropriate anchor box with the bounding boxes of each ground truth object within an image. Essentially, the anchor box with the highest degree of flap with an object is responsible for predicting that object\'s class and its location. It has microcontroller which has wi-fi inbuilt module. This guide is convenient and offers data to the client to move around in new condition, regardless of whether indoor or open air, through an ease to use interface. Then again, and so as to lessen route challenges of the visually impaired, a deterrent location framework utilizing ultrasounds is added to this gadget. The proposed framework identifies the closest hindrance through ultrasonic sensors and it gives an alert to illuminate the visually impaired about its confinement.
Introduction
I. INTRODUCTION
For visualising the Visual world to break and elucidate, which explains computer vision in computer technology. In classifying the objects’ accuracy, machines use deep learning models17 and digital images such as cameras and videos. In 1950s, demonstrations have already started in computer vision to identify the edges and align the simpler objects with falling under categories such as circles and squares by the techniques of first neural networks. In 1970s, Optional character recognition came into existence of computer vision, handwritten data on its primary trading tool. The illustrated data mainly used for the blind as a development. Visually impaired people find it hard to recognize the smallest detail with healthy eyes. Those who have the visual acuteness of 6/60 or the horizontal range of the visual field with both eyes open have less than or equal to 20 degrees. These people are regarded as blind. A survey by WHO (World Health Organization) carried out in 2021 estimates that in the world 1billion people includes those with moderate or severe distance vision impairment due to unaddressed refractive error (88.4 million), cataract (94 million), glaucoma (7.7 million), corneal opacities (4.2 million), diabetic retinopathy (3.9 million), and trachoma (2 million), as well as near vision. The main problem with blind people is how to navigate their way to wherever they want to go. Such people need assistance from others with good eyesight. As described by WHO, Blind Assistance System is a vision-based module specifically for the BLIND VICTIMS. The system is designed in such a way in which the blind person can take the help of An Application which in turn sends Real Time Frames to the Laptop-Based Wireless Networked System. It works on REAL-TIME OBJECT DETECTION using SSD algorithm and TENSORFLOW APIs. It has a core feature of approximate distance calculation and Voice - Based wireless Feedback generation w.r.t the Distance Calculation.
It makes the work of Blind easy, efficient and reliable by sending wireless Voice based feedback whether the particular object is either too close to him or is it at a safer distance. The same system can be used from Obstacle Detection SSD has two components: a backbone model and SSD head.
Backbone model usually is a pre-trained image classification network as a feature extractor. This is typically a network like Resnet trained on ImageNet from which the final fully connected classification layer has been removed. We are thus left with a deep neural network that is able to extract semantic meaning from the input image while preserving the spatial structure of the image albeit at a lower.
Therefore, the motivation of this research is given, the fact of building a technological tool supported by computer science (in this case Deep Learning) that allows to overcome some of these barriers, through the creation of a service that recognizes and automatically characterize images taken or provided by a user. The following text presents in the background, a historical tour of the evolution of computer science and, more precisely, the evolution that probabilistic algorithms have had, as well as works that likewise have wanted to identify objects in images using deep learning.
II. LITERATURE REVIEW
Abdul Muhsin M, Farah F. Alkhalid, Bashra Kadhim Oleiwi have proposed their work on “Online Blind Assistive System Using Object Detection” in 2020. In this work, the function of computer vision is to detect indoor objects accurately. The visually impaired people can be assisted by navigating the purposes of the CNN framework.4,5,14 To identify the specific objects first, we need to detect the pixels available in the images. If the lighting conditions are wrong, then it is challenging to capture and identify the objects with high accuracy. To detect the indoor objects, the algorithm needs to extract the image features with a particular class, and it can be done by RetinaNet.25 To enable the network for small object detection by a Region Proposal Int J Cur Res Rev | Vol 12 • Issue 20 • October 2020 160 Mandhala et al.: Object detection using machine learning for visually impaired people Networks (RPN), which involves subsampling to obtain the image information. The Resort with 152 samples achieved an average precision with 83.1%, and Dense Net with 121 samples achieved an average precision with 79.8%.
Pooja Maid, omkar Thorat and Sarita Deshpande have proposed their work on “Object Detection for Blind User’s” in 2018. Based on the relation models, this work assigned an equal quantity of work by considering its features. This removes duplication and attains accuracy at specific standards. Since the objects are aligned in the 2D scale ratio, it uses objects rather than words. Further, the model is categorized into two components that fall under geometric and original weights.15
Venkata Naresh Mandhala, Debnath Bhattacharyya, Vamsi B., Thirupathi Rao N. have proposed their work on “Object Detection Using Machine Learning for Visually Impaired People” in 2005. In this work, the main objective is to focus mainly on time complexities and their accuracies depending upon the various test that has been performed by the greedy approach the module which detects the text in the images which can be improved for visually impaired people. The quality of the model can be measured by F.P. and F.N. rates.
The decision capability of the algorithm can be done by a set of training images and classifiers. The smart telescopic system will be used for vision problem people. On the micro screen visuals, the image represents itself in a emphasize way leaving certain spots of the image behind. this work mainly in the medical field, specific changes have been made in identifying the disease and recoveries by considering its effectiveness and accuracy. Magnetic resonance imaging (MRI) and computed tomography (C.T). are analysed on image processing algorithms that are highly examined rather than DSA. While DSA is referred to the diagnosis of several neurovascular conditions which is used at the time of surgeries, on these considerations, it could be concluded that the framework is designed based upon the patients diagnosed with ischemic stroke.18
Rui (Forest) Jiang have proposed their work on “Let Blind People See: Real-Time Visual Recognition with Results Connected to 3D Audio” in 2015. In this work, a CNN model produces the best performance for image classification with a single label. Due to complexity, multi labelling is an open challenge for training image layouts. A single image object is taken as an input will be given for hypotheses extraction, and this is shared with CNN to get individual scores by max pooling. The image’s hypotheses are identified with different colours that can be indicated by different clusters.10 The extraction method produces predictive results that are utilized by max pooling. By comparing the I-FT and HCP models, the HCP model improves the system performance by 5.7%.
K.S.Manikanta , T.S.S. Phani have proposed their work on “Implementation & Design Of smart Blind Stick For Obstacle Detection And Navigation System” in 2018. In this work, the multi-model is used for visually impaired people to detect the objects with a multi-class strategy in an indoor area. This model takes at a time more than one label. The CVNN and multi-label techniques associate the image with labels that correspond to categories of objects at once.16 The clusters can be made based on multi labelling by ML-CVNN, and the L-CVNN method works by image transformation to classify the problem by ranking solution. The input strategy captures the image by multi-label and multi classes to generate the contexts of realistic and non-realistic of nested and exclusive structures.
Dr. K. Sreenivasulu, P. kiran Rao have proposed their work on “A Comparative Review on Object Detection System for Visually Impaired” in 2016. This model is used for detecting the patterns in urban areas such as public streets, raining, restaurants, etc.13 This method characterizes the audio clips, which yields the patterns. The main limitation of this model is to require a trained data set. 6
J. Dharanidharan, R. Puviarasi have proposed their work on “Object Detection System for Blind People” in 2012. In this work, the Camera wearer’s day is a dense storyboard briefing the recommended methods. On the other hand, in traditional essential chunk selection techniques, the final presentation of these techniques mainly examines the vital objects and people who interact using this camera wearer. A few chucks/data packets required for the storyboard are reflected by the vital object-driven circum- 161 Int J Cur Res Rev | Vol 12 • Issue 20 • October 2020 Mandhala etc al.: Object detection using machine learning for visually impaired people stances in this method. Based on our practices 17 hours of self-centred data depending upon the existing techniques, it shows excellence in saliency and summarisation. This has been done in 4 main steps; they are: (a) the image about a famous person or object could be predicted using a novel self-centric saliencycues which it trains a group independent regression model. (b) Separation of each task/event in dividing the video into subcategories of tasks. (c) Gaining the importance of each event by enabling the regression mechanism. (d)Choosing respective critical data chunks for the storyboard depending upon the required people and objects for.
III. DESIGN
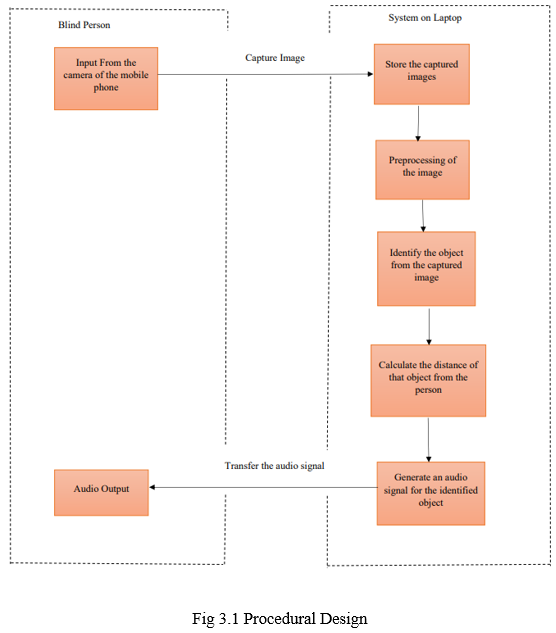
A. Procedural Design
In procedural design, First Blind Person will get the image from camera. By getting the image, means whatever image is captured that will be stored in system. When image is store in system it will go for pre-processing and it will helpful for identifying the objects from captured image. When identification process is done, then it’s necessary to calculate the distance of that object from the blind person. Because not needed in front of blind person these should be one and only object present. There may be more than one objects present, so calculation of distance is necessary. By adding pyttsx3 library we will generate an audio signal for the identified object. After generating audio signal Blind Person will get the audio signal.
B. Architectural Design
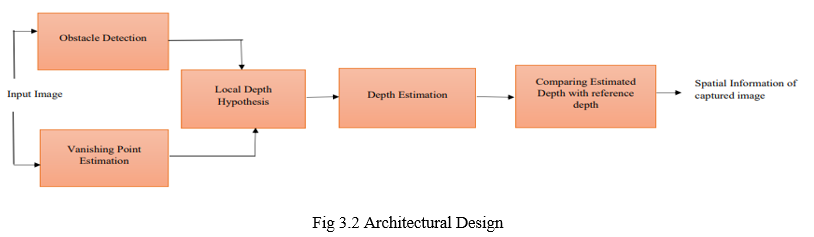
- Vanishing Point Estimation: After removing the noticeable regions from the foreground of the captured image, disappearing points have to be determined for each possible segmented region. Given a set of parallel lines in a three-dimensional space, they will converge at a certain point when projected onto a two-dimensional space which is called as vanishing point. These vanishing points plays important role in assigning the depth values for these noticeable regions which eventually gives the information of the distance of the obstacles from the user. Hence it is very important to determine the disappearing points. Several methods for the estimation of disappearing points have been proposed. In this work, lines corresponding to the edges of each obstacle are determined using Hough transform. After estimating the edges of each segmented obstacle, disappearing points.
- Depth Estimation: Disappearing Point represents the closest point from the user. Starting from the disappearing point, the intensity level of the depth map is increased. These disappearing points determine the type of hypothesis to be used among the four basic hypotheses based on its place and orientation in the image. There can also be obstacles with no disappearing points, for which default hypothesis of bottom to top depth gradient is used. Depending on the position of these disappearing points, a combination of bottom to top depth hypothesis and the depth hypothesis corresponding to the disappearing points is used for assigning depth values for the obstacles of the image. Hence depth is estimated for the separated obstacles regaining the variation of depth values within the same obstacle. The depth map estimated for the obstacles detected. Now the final depth map estimated for the obstacles of the captured image is compared with the reference depth map of the corresponding combination of depth hypotheses used for assignment, which is nothing but a depth map for a flat surface devoid of obstacles. The deviation of the estimated final depth of the obstacles of the image from the corresponding reference depth helps to collect the spatial information of the obstacles, which is to be communicated to the blind user to assist him/her along his navigation path.
IV. RESULTS
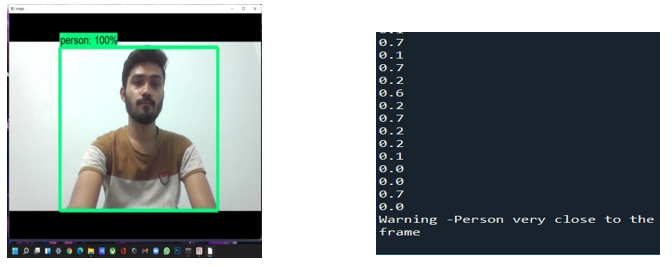
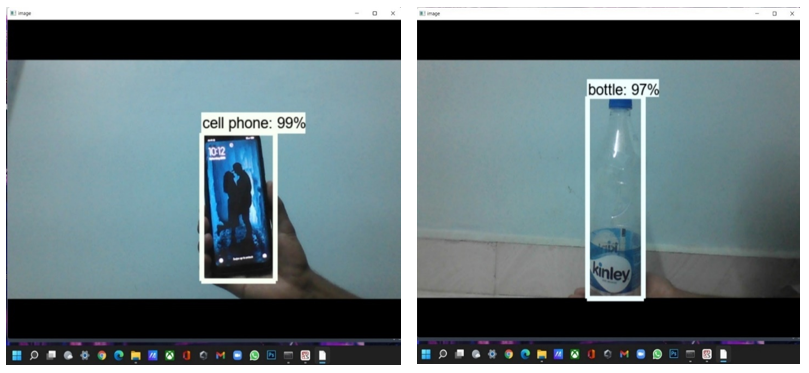
V. ACKNOWLEDGEMENT
We sincerely wish to thank our Project guide Prof. Aarti Abhyankar for her ever encouraging and inspiring guidance helped us to make our project a success. Our project guide made us ensure with her expert guidance, kind advice and timely motivation which helped us to determine about our project.
We also express our deepest thanks to our H.O.D. Dr. Uttara Gogate who’s benevolent helps us making available the computer facilities to us for our project in our laboratory and making it true success. Without his kind and keen co-operation our project would have been stifled to stand still.
Lastly, we would like to thank our college Principal Dr. Pramod R Rodge for providing lab facilities and permitting us to go on with our project. We would also like to thank our colleagues who helped us directly or indirectly during our project.
Conclusion
A. To Train Our Model we have been use TensorFlow is a Computer Vision Technique. B. We would be using SSD algorithm For Blind Person Assistant: Object Detection and a best Performing classification model for object identification. C. We would be using Pyttsx3 for text to speech conversion.
References
[1] Chen X, Yuille AL. A time-efficient cascade for real-time object detection: With applications for the visually impaired. In2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05)-Workshops 2005 Sep 21:28-28. [2] Chi-Sheng, Hsieh. “Electronic talking stick for the blind.” U.S. Patent No. 5,097,856, 24 Mar. 1992. [3] WafaMElmannai, KhaledM.Elleithy. “A Highly Accurate and Reliable Data Fusion Framework for Guiding the Visually Impaired”. IEEE Access 6 (2018) :33029-33054. [1] [4] Ifukube, T., Sasaki, T., Peng, C., 1991. A blind mobility aid modelled after echolocation of bats, IEEE Transactions on Biomedical Engineering 38, pp. 461 - 465. [5] Cantoni, V., Lombardi, L., Porta, M., Sicard, N., 2001. Vanishing Point Detection: Representation Analysis and New Approaches, 11th International Conference on Image Analysis and Processing. [6] Balakrishnan, G. N. R. Y. S., Sainarayanan, G., 2006. A Stereo Image Processing System for Visually Impaired, International Journal of Information and Communication Engineering 2, pp. 136 145. [7] C.S. Kher, Y.A. Dabhade, S. sK Kadam., S.D.Dhamdhere and A.V. Deshpande “An Intelligent Walking Stick for the Blind.” International Journal of Engineering Research and General Science, vol. 3, number 1, pp. 1057-1062 [8] G. Prasanthi and P. Tejaswitha “Sensor Assisted Stick for the Blind People.” Transactions on Engineering and Sciences, vol. 3, number 1, pp. 12-16, 2015
Copyright
Copyright © 2022 Aniket Birambole, Pooja Bhagat, Bhavesh Mhatre, Prof. Aarti Abhyankar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40850
Publish Date : 2022-03-18
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online