

Ijraset Journal For Research in Applied Science and Engineering Technology
Bone Tumor Detection and Classification Using Deep Learning
Authors: Vishnuvardhan R, Balakrishnan G, Nithishkumar M, Logeshwaran S
DOI Link: https://doi.org/10.22214/ijraset.2023.50655
Certificate: View Certificate
Abstract
Bone tumor is a rare type of tumor that refers to an abnormal growth of tissue inside and outside of the bone, with a high chance to spread to other parts of the body. A bone tumour is a mass growth of tumour cells that causes the disease and is difficult to diagnose. Children, teenagers, and young adults who have received a lot of radiation are the most affected. There are no known causes of bone cancer, unlike other cancers such those of the breast, lungs, prostate, stomach, and brain. Our project uses techniques like green plane extraction, arithmetic operations, linear contrast stretching, histogram equalization, and global thresholding to do segmentation, and GLCM is utilised for classification.
Introduction
I. INTRODUCTION
White blood cells (WBCs), together with red blood cells and platelets, are the blood's corpuscles. The human immune system is protected by WBCs, which also help to heal wounds and eradicate microbial invasion. WBC levels that are abnormally high or low are symptoms of a pathological illness and should not be disregarded. An increase in WBCs typically indicates inflammation, bacterial damage, or acute or chronic infection of an organ or tissue. A substantial rise in WBC can also result from a variety of trauma, post-operative injury, acute bleeding, poisoning, malignant tumours, and other eventsA decrease in WBCs.On the other hand, is typically caused by prolonged chemotherapy and radiotherapy or a symptom of hypersplenism, autoimmune disorders, aplastic anaemia, and haematological malfunction. Thus, in clinical practise, it is crucial to determine the amount, morphology, and percentage of WBCs.
Because deep learning is better at extracting information from high-dimensional input, techniques based on deep convolutional neural networks (CNN) have recently advanced quickly in the field of computer vision. The fields of image categorization, object recognition, and picture segmentation have all seen its use.Despite the widespread use of machine vision technologies by researchers, there is still a need to create sorting machine software that is more accurate, dependable, and automated. Examples of such software include artificial intelligence, deep learning algorithms, convolution neural networks, and recurrent neural networks. To check the quality of the tomatoes, we utilised a Python software with the CNN and RNN algorithms. The colour of the tomatoes was tested to distinguish between green, ripe, and unripe tomatoes.An artificial neural network called a convolution neural network is made primarily to process image data and is used for picture recognition and processing. Using the Python keras package, the data set image is collected for testing and training. One of the deep learning algorithms, RNN, uses picture recognition while maintaining accuracy. The photos from the dataset were tested and trained using the same approach.
II. MODULE DESCRIPTION
A. Image Acquisition
An artificial neural network called a convolution neural network is made primarily to process image data and is used for picture recognition and processing. Using the Python keras package, the data set image is collected for testing and training. One of the deep learning algorithms, RNN, uses picture recognition while maintaining accuracy. The photos from the dataset were tested and trained using the same approach.
- 2D Image Input: A digitised monochrome (greyscale) image serves as the foundation for two-dimensional images. The brightness or grey value of the image at any position (x, y) is proportional to the value of the two-dimensional light intensity function f(x,y), where x and y are spatial coordinates. When spatial and greyscale values are made discrete, an image is said to be digitised. Measurements of intensity in the x and y directions, with intensities sampled to 8 bits (256 values).
B. Gray Image
A grayscale or greyscale image is one in which the value of each pixel is a single sample that represents only a quantity of light, that is, that it conveys only intensity information, in digital images, computer-generated imagery, and colorimetry. Black-and-white or grey monochrome images are a type of grayscale image that only contains shades of grey. Black with low intensity and white with high contrast (strong intensityGrayscale images are distinct from one-bit bi-tonal black-and-white images, which are used in computer imaging. Black and white images, also known as binary and bilevel images, have only two colours. Images in grayscale feature a wide range of grey tones.
When only one frequency (in practise, a restricted band of frequencies) is acquired, grayscale images can be produced by measuring the intensity of light at each pixel in accordance with a specific weighted combination of frequencies (or wavelengths). In such circumstances, the images are monochromatic proper. The electromagnetic spectrum is open to theoretically any location for the frequencies (e.g. infrared, visible light, ultraviolet, etc.).
An picture with a defined grayscale colorspace that maps the sample values to the achromatic channel of a standard colorspace, which is based on the observed characteristics of human vision, is said to be colorimetric (or, more precisely, photometric).There is no specific mapping from such a colour image to a grayscale image if the original colour image has no defined colorspace or if the grayscale image is not meant to have the same human-perceived achromatic intensity as the colour image.
C. Grayscale As Single Channels Of Multichannel Color Images
Many stacked colour channels, each of which represents a different channel's value levels, are frequently used to create colour images. For instance, CMYK images have four channels for cyan, magenta, yellow, and black ink plates, while RGB images are made up of three distinct channels for the red, green, and blue main colour components.
Here is a full RGB colour image that has had its colour channels divided. The isolated colour channels are displayed in natural hues in the left column, while their grayscale equivalents are shown in the right column:

It is also possible to create a full colour image from each channel's individual grayscale data in the other direction. Instead of faithfully replicating the original image, artistic effects can be produced by manipulating channels, employing offsets, rotating, and other techniques.
III. HISTOGRAM EQUALIZATION:
Because the image's useable data is represented by close contrast values, this strategy typically raises the overall contrast of numerous photos. The histogram intensities can be more evenly spread by making this adjustment. This makes it possible for regions with less local contrast to acquire more contrast. The most frequent intensity values are efficiently dispersed via histogram equalisation to achieve this.
A. Otsu Thershold
With the process of thresholding, we change a colour or grayscale image into a binary image, or one that is only black and white. Most typically, thresholding is used to pick out specific portions of an image that are of interest while ignoring the rest.
The Otsu method is a picture thresholding based on clustering.When the histogram is bimodal, it functions. The strategy essentially aims to maximise the between class variation while simultaneously minimising the within class variance. Total variance is the sum of the within-class and between-class variances.Automatic picture thresholding is done with it. The algorithm returns a single intensity threshold in its most basic form, dividing pixels into the foreground and background classes.
B. IM2BW (Black and White Image):
It converts an image to a binary image, based on threshold.
- Im2bw converts RGB, intensity, or indexed pictures into binary images. In order to accomplish this, the input image is first converted to grayscale format (assuming it is not already an intensity image), and then this grayscale image is thresholded into binary. All input picture pixels with brightness less than level have values of 0 (black) in the output binary image BW, whereas all other pixels have values of 1 (white). (Notice that regardless of the class of the input image, you must specify level in the range [0,1].)
- BW = im2bw(I,level) creates a black-and-white version of the intensity picture I.
- BW = im2bw(X,map,level) creates a black-and-white version of the indexed picture X with colormap map.
- BW = im2bw(RGB,level) turns an RGB image into a black-and-white version.

IV. MORPHOLOGICAL OPERATION:
A shape-based method of image processing is called morphology. Each pixel in the output image has its value determined by comparing it to its neighbours in the input image. A morphological operation that is sensitive to particular shapes in the input image can be built by selecting the neighborhood's size and shape.
A. Dilation & Erosion
The two main morphological processes are dilation and erosion. In an image, dilation involves adding pixels to object boundaries, and erosion involves taking pixels away from object boundaries. The size and shape of the structuring element used to process the image determines how many pixels are added to or subtracted from the objects in the image.
- Morphological Reconstruction: Another important component of morphological image processing is morphological reconstruction. Morphological reconstruction based on dilation offers the following special characteristics: Instead of using one image and one structuring element, processing is based on two images: a marker and a mask. Processing is repeated until stability, or when the image no longer changes.The idea of connectedness serves as the foundation for processing rather than a structural factor.
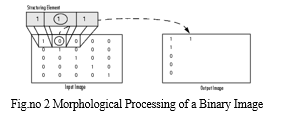
- Understanding Dilation and Erosion: By applying a rule to the corresponding pixel and its neighbours in the input image, the morphological dilation and erosion processes define the state of any given pixel in the output image. The operation is classified as a dilation or an erosion by the rule that was employed to process the pixels. The guidelines for both erosion and dilation are listed in this table. The dilatation of a binary picture is seen in the following figure. See how the structuring element in the picture defines the area around the circled pixel of interest. (Further details can be found under Structuring Elements.) The dilation function assigns a value to the relevant pixel in the output image after applying the appropriate rule to the pixels in the vicinity. Because one of the elements in the neighbourhood described by the structuring element is on in the illustration, the morphological dilation function sets the value of the output pixel to 1 in the figure.
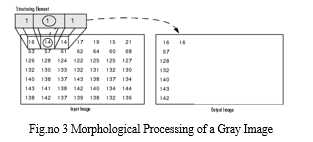
This processing for a grayscale image is shown in the accompanying graphic. The processing of a specific input image pixel is depicted in the figure. See how the function applies the rule to the neighbourhood of the input pixel and selects the pixel in the output image that has the greatest value out of all those in the neighbourhood.
B. Processing Pixels at Image Borders
The origin of the structuring element, or its centre element, is placed above the input image pixel of interest via morphological functions. Parts of the neighbourhood formed by the structuring element for pixels near an image's edge may extend beyond the boundary of the image. These undefinable pixels are given a value by the morphological functions to be processed as border pixels, giving the illusion that more rows and columns have been added to the image. These "padding" pixels have different values for dilation and erosion processes. The padding guidelines for erosion and dilation for binary and grayscale pictures are shown in the following table.
- Dilating an Image
Use the imdilate function to enlarge an image. Two basic arguments are accepted by the imdilate function. A structuring element object returned by the strel function or a binary matrix specifying a structuring element's neighbourhood in the input image to be processed (grayscale, binary, or packed binary image).The two optional arguments PADOPT and PACKOPT are likewise accepted by imdilate. The output image's size is impacted by the PADOPT parameter. The input picture is recognised as packed binary by the PACKOPT parameter. (For details on binary image packing, visit the bwpack reference page.)The example makes use of a 3-by-3 square structuring element object to increase every edge of the foreground component. SE = str("square",3)Provide the structuring element, SE, and the image, BW, to the imdilate function to enlarge the image.
2. Eroding an Image
Use the imerode function to erode an image. Two main arguments are accepted by the imerode function. A structuring element object returned by the strel function or a binary matrix specifying a structuring element's neighbourhood in the input image to be processed (grayscale, binary, or packed binary image).
The three optional arguments PADOPT, PACKOPT, and M are also accepted by imerode.
The output image's size is impacted by the PADOPT parameter. The input picture is recognised as packed binary by the PACKOPT parameter. M identifies the number of rows in the original image if the image is packed binary.
The binary image circbw.tif degrades as seen in the sample below:
a. Read the image into the workspace of MATLAB.
b. Add a structural component.
c. Invoke the imerode function, passing the inputs BW for the picture and SE for the structuring element.
d. Take note of the diagonal streaks on the output image's right side. They are owing to the shape of the structural element.
3. Combining Dilation and Erosion
The implementation of image processing procedures frequently combines erosion and dilation. For instance, an erosion followed by a dilation, utilising the same structuring element for both operations, is the definition of a morphological opening of an image. The opposite process, known as morphological closing of a picture, involves dilation followed by erosion using the same structuring element. Imdilate and Imerode are used in the next section to demonstrate how to employ a morphological opening. But keep in mind that the imopen function, which carries out this processing, is already present in the toolbox. The toolbox has several morphological procedures that are frequently performed by functions.
C. Bag of Features (BoF)
In computer vision and image processing, the Bag of Features (BoF) technique is used to extract and represent features from images in a condensed and useful fashion. In order to create a collection of visual words, BoF's primary premise is to extract local features from an image, such as SIFT, SURF, or ORB, and then use clustering algorithms to organise the features into a set. The bag of features is a histogram of these visual terms that represents each image. Several computer vision and image processing tasks, including image retrieval, object recognition, and semantic segmentation, use the Bag of Features model. BoF is used in image retrieval to represent images effectively and compactly, enabling quick and precise retrieval of related images. In order to distinguish objects in new photos, BoF extracts features from images and trains a classifier. In semantic segmentation, features are extracted from images using BoF, and a model is trained to forecast the semantic labels of the image's pixels. Due to its capacity to extract and represent features in a concise and meaningful manner, BoF has proven to be a potent tool in computer vision and image processing. Moreover, BoF's histogram representation enables quick and effective image comparison. Yet, it costs a lot to compute and needs a lot of practise data. Recent methodologies, such deep learning-based approaches, which are more effective and accurate, have taken its place.
- Steps Involved in The BoF Process
The Bag of Features (BoF) method's fundamental steps are feature extraction, clustering, and histogram representation.
a. Feature Extraction: Extraction of local features from the photos is the first stage in the BoF approach. Feature detection and description techniques like SIFT, SURF, or ORB are used to do this. These techniques extract from the image a set of key points and related descriptor vectors.
b. Clustering: The next step is to compile a collection of visual words from the extracted data. This is accomplished by using descriptor vectors with clustering methods like k-means or hierarchical clustering. The outcome is a collection of clusters, each of which stands for a visual word.
c. Histogram Representation: Lastly, a histogram of the visual words is used to depict the image. In order to accomplish this, each visual word's features are counted and a histogram of these counts is created. The image is represented as a histogram of the image's features.We may use the images' bag of feature representation to carry out various tasks, including image retrieval, object recognition, and semantic segmentation, after the feature extraction, clustering, and histogram representation processes are finished. It is crucial to remember that the representation of the images will vary depending on how many clusters, or visual words, are employed in the BoF approach. A more detailed representation will be produced by employing more clusters, but the computational cost and memory use will also rise. Therefore, while utilising fewer clusters may produce a coarser representation, it will also be more effective.
D. Comparing BoF to Other Feature Extraction Methods
A method for extracting and representing features from photos is called "bag of features" (BoF). Nevertheless, additional feature extraction techniques like SURF (Speeded-Up Robust Feature), SIFT (Scale-Invariant Feature Transform), and ORB (Oriented FAST and Rotated BRIEF) can also be used.
- SIFT: It is among the most widely used feature extraction techniques. In 1999, David Lowe made it popular. SIFT extracts important areas and descriptor vectors from a picture and is resistant to affine and scale rotation. While being computationally expensive and potentially noise-sensitive, SIFT is resilient to changes in viewpoint and illumination.
- SURF: The SIFT algorithm is the foundation of the feature extraction technique SURF. In 2006, Herbert Bay, Tinne Tuytelaars, and Luc Van Gool first proposed it. It is quicker than SIFT but less resistant to changes in perspective and lighting.
- ORB: The ORB feature extraction technique is based on the BRIEF descriptor and the FAST corner detector. It was first presented in 2011 by Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary R. Bradski. Compared to SIFT and SURF, ORB is quicker and less noise-sensitive. It is less resistant to changes in perspective and lighting, though.
- BoF: It is a method that extracts features from the image and groups them into visual words using feature extraction techniques like SIFT, SURF, and ORB. BoF is a potent method for extracting features and displaying them in a concise and comprehensible manner. However, it costs a lot to compute and needs a lot of practise data.In conclusion, each feature extraction technique has pros and cons. Although SIFT is computationally expensive, it is resilient to changes in viewpoint and illumination. Although SURF is quicker than SIFT, it is less resistant to changes in lighting and perspective. Compared to SIFT and SURF, ORB is quicker, less sensitive to noise, but less resistant to changes in viewpoint and lighting. Although BoF is effective, it is computationally expensive and necessitates a substantial training set. The specific needs of the application and the trade-off between robustness and computing cost will determine the feature extraction approach to be used.
E. System Implementation
With the use of MATLAB's data acquisition, analysis, and visualisation features, you may quickly obtain understanding of your data compared to when utilising spreadsheets or conventional programming languages. Also, you can present and distribute your findings via plots, reports, or published MATLAB code.
- Acquiring Data: You can access data from files, other programmes, databases, and external devices using MATLAB. You can read data from common file types like text files, binary files, image, music, and video files, as well as scientific file types like net CDF and HDF. You may work with data files in any format thanks to file I/O functions.By using MATLAB with add-on products, you can stream real-time measured data into MATLAB for analysis and visualisation as well as obtain data from hardware devices like your computer's sound card or serial port. Moreover, you may converse with devices like oscilloscopes, function generators, and signal analyzers.
- Analyzing Data: You may organise, filter, and preprocess your data using MATLAB. Exploratory data analysis can be used to find patterns, verify theories, and create descriptive models. Fast Fourier transformations, interpolation, convolution, and filtering and smoothing are all functions available in MATLAB (FFTs). Curve and surface fitting, multivariate statistics, spectral analysis, image analysis, system identification, and other analysis activities are all capabilities offered by add-on products.
- Visualizing Data: 2-D and 3-D charting functions, as well as functions for visualising volumes, are incorporated into MATLAB. These features can be used to communicate results and visualise and comprehend data. Plots can be altered programmatically or interactively. There are numerous examples of graphical data displays in MATLAB in the MATLAB plot gallery. You can browse and download the source code for each example to use it in your MATLAB programme
F. Programming and Algorithm Development
With the aid of MATLAB's high-level language and development tools, you may easily create and test algorithms and software.
- The MATLAB Language: Fast development and execution are made possible by the native support for vector and matrix operations that the MATLAB language offers. These operations are essential for solving engineering and scientific problems. The MATLAB language eliminates the need for low-level administrative duties like declaring variables, defining data types, and allocating memory, allowing you to build programmes and create algorithms more quickly than with traditional languages. For-loops are often unnecessary thanks to the support for vector and matrix operations. As a result, numerous lines of C or C++ code can frequently be replaced by a single line of MATLAB code. Traditional programming language features like flow control, error management, and object-oriented programming are all available in MATLAB (OOP). You can create own data types, employ basic data types or sophisticated data structures. By interactively performing commands one at a time, you can get quick results. This method enables you to rapidly explore a variety of choices and iterate to the best answer. To reuse and automate your work, you can save interactive stages as scripts and functions. Built-in algorithms for signal processing and communications, image and video processing, control systems, and many other disciplines are available in MATLAB add-on products. You can create intricate programmes and applications by fusing these algorithms with your own.
V. SYSTEM TESTING
A. Testing Objectives
A series of operations known as testing can be organised in advance and carried out in a methodical manner. For this reason, the development process should specify a template for software testing, or a collection of stages into which we may insert particular test case creation approaches and testing methods. More work than any other software engineering task is frequently put into testing. When it is done carelessly, time is lost, additional work is added, and even worse, mistakes are made covertly. So, developing a methodical testing plan for software would appear sensible.
1. Type of Testing
There are two type of testing according their behaviors
a. Unconventional Testing
A process of verification called unconventional testing is carried out by the SQA (Software Quality Assurance) team. It is a preventative strategy that is used throughout the course of a project's development. The SQA team checks project development activities during this process to determine whether or not the project is meeting the client's requirements.
In this testing the SQA team follows these methods:
- Peer review
- Code walk and throw
- Inspection
- Document Verification
b. Conventional Testing
The process of conventional testing involves identifying the bugs and validating the project. This testing process involves the testing team, which verifies whether or not the generated project complies with client requirements. In this procedure, the testing team identifies bugs and informs the development team so that the produced project can be corrected.
VI. TEST CASE DESIGN
A. Unit Testing
Unit testing's basic objective is to take the smallest tested component of the application, isolate it from the rest of the code, and check to see if it functions as expected. Prior to being integrated into modules, each unit is evaluated independently to check how well the modules communicate with one another. The significance of unit testing has been demonstrated by the fact that a significant portion of flaws are found when it is used.
The zero length username and password are provided and verified in both the firm registration form and the seeker registration form. Also provided and validated is the duplicate username. When entering a job or a question, the button will only send data to the server after client-side validations have been performed. Dates are incorrectly entered and double-checked. The provided and checked URLs for the website and email address are incorrect.
B. Integration Testing
Each module undergoes testing. After each module has been thoroughly tested, the modules are linked, and the final system is then tested using test data that has been specifically created to demonstrate that the system will function properly under all of its conceivable circumstances. So, system testing is a chance to demonstrate to the user that the system functions and to validate that everything is in order.
C. Validation Testing
Validation testing, which is the last step, ascertains whether the software performs as the user anticipated. Most software engineers do this test through a procedure called "Alpha and Beta Testing" that involves the end user rather than the system developer in order to detect issues that only the end user appears to be able to notice. The completion of the entire project depends on the users' complete contentment.
Validation testing is done in the project in a number of ways. Only the right response will be allowed in the answer box on the question entry form. Other than the four options provided, further answers will not be accepted.

Conclusion
The suggested approach combines feature extraction with a classification model to identify and classify the liveliness of cancerous and healthy bones. The noise is eliminated using a median filter with a 3x3 pixel size. The canny algorithm is used to extract the object of interest. In the malignant location, the healthy and cancerous bone have different textures. The malignant region has more distributed cancerous bone pixels than healthy bone pixels. It is crucial to choose a textural feature that can distinguish a malignant spot. The GLCM-based texture feature is the one that researchers employ most appropriately. However, the experiment revealed that a GLCM-based texture feature alone is insufficient. Entropy and skewness are important factors in the prediction of malignant regions.
References
[1] K. Sujatha et al., \"Screening and Identify the Bone Cancer/Tumor using Image Processing,\" 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 2018, pp. 1-5, doi: 10.1109/ICCTCT.2018.8550917. [2] B. Jabber, M. Shankar, P. V. Rao, A. Krishna and C. Z. Basha, \"SVM Model based Computerized Bone Cancer Detection,\" 2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 2020, pp. 407-411, doi: 10.1109/ICECA49313.2020.9297624. [3] H. Boulehmi, H. Mahersia and K. Hamrouni, \"Bone Cancer Diagnosis Using GGD Analysis,\" 2018 15th International Multi-Conference on Systems, Signals & Devices (SSD), Yasmine Hammamet, Tunisia, 2018, pp. 246-251, doi: 10.1109/SSD.2018.8570658. [4] R. M M, T. N. L, A. C. N and C. K. Subbaraya, \"Bone Cancer Detection Using K-Means Segmentation and Knn Classification,\" 2019 1st International Conference on Advances in Information Technology (ICAIT), Chikmagalur, India, 2019, pp. 76-80, doi: 10.1109/ICAIT47043.2019.8987328. [5] R. S. Upadhyay and P. Tanwar, \"A Review on Bone Fracture Detection Techniques using Image Processing,\" 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 2019, pp. 287-292, doi: 10.1109/ICCS45141.2019.9065874. [6] B. Jabber, M. Shankar, P. V. Rao, A. Krishna and C. Z. Basha, \"SVM Model based Computerized Bone Cancer Detection,\" 2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 2020, pp. 407-411, doi: 10.1109/ICECA49313.2020.9297624. [7] C. Z. Basha, G. Rohini, A. V. Jayasri and S. Anuradha, \"Enhanced and Effective Computerized Classification of X-Ray Images,\" 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2020, pp. 86-91, doi: 10.1109/ICESC48915.2020.9155788. [8] C. Z. Basha, B. Lakshmi Pravallika, D. Vineela and S. L. Prathyusha, \"An Effective and Robust Cancer Detection in the Lungs with BPNN and Watershed Segmentation,\" 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 2020, pp. 1-6, doi: 10.1109/INCET49848.2020.9154186. [9] C. Z. Basha, M. R. K. Reddy, K. H. S. Nikhil, P. S. M. Venkatesh and A. V. Asish, \"Enhanced Computer Aided Bone Fracture Detection Employing X-Ray Images by Harris Corner Technique,\" 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 2020, pp. 991-995 [10] C. Saha and M. F. Hossain, \"MRI brain tumor images classification using K-means clustering, NSCT and SVM,\" 2017 4th IEEE Uttar Pradesh Section International Conference on Electrical, Computer and Electronics (UPCON), Mathura, 2017, pp. 329-333.
Copyright
Copyright © 2023 Vishnuvardhan R, Balakrishnan G, Nithishkumar M, Logeshwaran S. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET50655
Publish Date : 2023-04-19
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online