

Ijraset Journal For Research in Applied Science and Engineering Technology
Building Crack Detection Using Deep Learning Techniques
Authors: Mr. V. Maheskumar, S. Sangeetha, S. Shripriya, S. Tharani
DOI Link: https://doi.org/10.22214/ijraset.2022.44303
Certificate: View Certificate
Abstract
Reliability, performance, and life cycle costs are real concerns for almost all in-service massive structures, such as buildings, bridges, nuclear facilities, hydroelectric structures, and dams. Cracks on these structures are a common phenomenon associated with various internal and external forces, including the corrosion of embedded reinforcement, chemical deterioration of concrete, and the application of adverse loading to the structure. In comparison to the traditional manual inspection-based crack detection system, computer vision and machine learning-based approaches are quickly becoming an integral part of the modern segmentation of civil infrastructures to automate crack detection and identification systems. The project is about the construction and application of a device that uses image processing to detect cracks. The system has a graphical user interface for initializing the device, viewing real time image, taking pictures of a crack, measuring its width, and evaluating if safe or unsafe.
Introduction
I. INTRODUCTION
Deep learning is a machine learning technique thatteaches computers to do what comes naturally to humans: learn by example. Deep learning is a key technology behind driverless cars, enabling them to recognize a stop sign, or to distinguish a pedestrian from a lamppost. It is the key to voice control in consumer devices like phones, tablets, TVs, and hands-free speakers. Deep learning is getting lots of attention lately and for good reason. It’s achieving results that were not possible before. In deep learning, a computer model learns to perform classification tasks directly from images, text, or sound. Deep learning models can achieve state-of-the-art accuracy, sometimes exceeding human-level performance. Models are trained by using a large set of labeled data and neural network architectures that contain many layers. Deep learning achieves recognition accuracy at higher levels than ever before. This helps consumer electronics meet user expectations, and it is crucial for safety-critical applications like driverless cars. Recent advances in deep learning have improved to the point where deep learning outperforms humans in some tasks like classifying objects in images. While deep learning was first theorized in the 1980s, there are two main reasons it has only recently become useful: Deep learning requires large amounts of labeled data. For example, driverless car development requires millions of images and thousands of hours of video. Deep learning requires substantial computing power. High-performance GPUs have a parallel architecture that is efficient for deep learning. When combined with clusters or cloud computing, this enables development teams to reduce training time for a deep learning network from weeks to hours or less.
II. OBJECTIVE
Cracks are of major concern for ensuring the safety, durability, and serviceability of structures. The reason is that when cracks are developed and propagate, they tend to cause the reduction in the effective loading area which brings about the increase of stress and subsequently failure of the concrete or other structures. In the present work, an deep learning model that automatically detects and analyzes cracks on the surfaces of building elements.
III. EXISTING SYSTEM
Automatic crack detection is a very challenging image classification task with the goal of accurately marking crack areas. To improve the continuity of crack detection, researchers have attempted to detect cracks by introducing Minimal Path Selection (MPS) , Minimal Spanning Trees (MSTs), and Crack Fundamental Elements (CFEs). These methods can partially eliminate noise and improve crack detection continuity. However, only the low-level features can be roughly obtained, some complex high-level crack features may not be presented, and utilized correctly. A randomly structured forest-based method is presented to detect cracks automatically is method can effectively suppress noise by manually selecting crack features and learning internal structures. Although it improves the recognition speed and accuracy but does not perform well when dealing with complex pavement crack situations. Therefore, traditional machine learning methods simulate cracks by manually setting color or texture features. In these methods, the features cover only some specific real-world situations. The set of crack features is simplified and idealized, which cannot achieve the robust detection requirements for pavement diseases. To process a large volume of concrete structure image data regarding cracks, the machine learning-based classification approach has recently received significant attention. The Support Vector Machine (SVM) was applied to detect “crack” and “no-crack” conditions from concrete image data through extracting handcrafted manual features. The feature extraction process acts as a vital bridge between the raw image and rich feature vectors regarding cracks, which are used for classification
A. Drawbacks
- Accuracy is less
- Provide high number of false positive rate
- Complexity is high
IV. PROPOSED SYSTEM
In building monitoring concrete floor inspection, generating a crack map enables assessing important information about the surface health. In addition, detecting cracks early minimizes maintenance-renovation efforts and costs. Currently, crack detection is mainly performed by human experts. It is a tiring, time consuming, costly and above all subjective task. An improvement is to use scanning vision systems and possible basic image processing algorithms highlighting at least some cracks. In this case, experts just have to visualize the image sequences. However, it is still suggestive. In order to overcome these problems, many efforts are currently done to automatize the inspection. Cracks generally present radiometric and geometric features such as darker than the background and elongated. These are the reasons why scanning vision systems based on a monochrome camera; image processing and recognition are natural tools for this task. These tools are used in this work. However, it is still a current challenge to detect automatically (and fast) a wide variety of cracks in a wide variety of concrete floors. In proposed system we can implement the framework to segment the images to identify the crack with improved accuracy rate. It may be possible to classify cracked and non-cracked images directly from the original images by using Artificial Neural Network (ANN). However, the method using only ANN without image processing will require more computation time, since the training images have so many information. Thus it is required to include the image processing before applying ANN step in order to develop an effective process. It is required to distinguish cracks from normal concrete surface automatically to reduce the effort of the human inspectors. In this project, ANN are adopted to replace the human intelligence, that is to say, to replace the human classification though visual inspection. The proposed algorithm, the multi-layer ANN is basically used and back propagation algorithm is used for training the NN.
A. Advantages
- Improved accuracy rate
- Less number of false positive rate
- Complexity is less
- Handle large number of image pixels
IV. OVERVIEW OF PROPOSED SYSTEM
A. Problem Definition
Over the past few decades, image processing (IP)-based crack inspection techniques have been widely studied. This processing refers to the entire computational process of the photograph of a concrete structure; image input/output, digitization, segmentation, defect management, and defect detection. Thus, it not only detects cracks but also measures the width and orientation of the recognized cracks. IP-based methods generally determine whether or not an image pixel is part of a crack region by using predefined gradient filters and a binary classifier. Oliveira and Correia showed that it is possible to detect crack by distinguishing darker areas. Many researchers proposed effective crack detection that enhances cracks using noise filtering on the images. Moreover, various image processing techniques for crack inspection have also been studied based on morphology, fuzzy, and percolation techniques. However, the accuracy of these rule-based image processing is variant to the focal length of the image, the influence of the shooting environment (illuminance, intensity, etc.), shooting quality, and the resolution. This weakness requires new filter modeling every time depending on the input image for accurate detection.
???????B. Overview of Proposed System
The rule-based crack inspection methods, machine learning (ML) has attracted attention from researchers. Machine Learning refers to computer algorithms learning important patterns or rules by itself based on given data without being explicitly programmed. ML-based crack inspection methods are categorized into two main groups as Artificial Neural Networks (ANN) use or without (ANN) use. Conventional ML-based crack inspection methods first extract crack features using image processing, then evaluate whether or not the extracted features indicate cracks without ANN use. Many researchers have used various ML algorithms for crack detection, including Support Vector Machine, Bayesian, genetic algorithm, and decision trees. However, conventional ML-based methods have limitations as their accuracy inevitably relies on the extracted crack features by image processing.
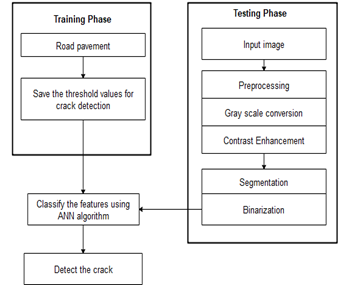
VI. MODULES DESCRIPTION
A. Image Acquisition
Image-based systems have several benefits for monitoring the crack propagation in different structural material. Initially, when these systems were used to measurement of cracks, more attention was paid to features of objects and repeatability. Also, the use of remote sensing techniques allows the measurement of cracks without the need for access to the validated elements, and also provides stable image storage for each observation in any period. These systems are helpful for those who are involved in the design of structures or those who are responsible for maintaining the infrastructure systems when analyzing the relationship between loading and damage locations. In this module, we can input the image with any type and any size.
???????B. Preprocessing
Pre-processing is a common name for operations with images at the lowest level of abstraction both input and output are intensity images. These iconic images are of the same kind as the original data captured by the sensor, with an intensity image usually represented by a matrix of image function values (brightnesses). Image pre-processing methods are classified into four categories according to the size of the pixel neighborhood that is used for the calculation of new pixel brightness. The aim of pre-processing is an improvement of the image data that suppresses unwilling distortions or enhances some image features important for further processing, although geometric transformations of images (e.g. rotation, scaling, translation) are classified among pre-processing methods here since similar techniques are used. The user has to select the required lung frame image for further processing. In this module convert the RGB image into gray scale image. The colors of leaves are always green shades and the variety of changes in atmosphere cause the color feature having low reliability. Therefore, to recognize various plants using their leaves, the obtained leaf image in RGB format will be converted to gray scale before pre-processing. The formula used for converting the RGB pixel value to its grey scale counterpart is given in Equation.
Gray = 0.2989 * R + 0.5870 * G + 0.1140 * B
where R, G, B correspond to the color of the pixel, respectively.
???????C. Contrast Enhancement
In this module, we can implement contrast enhancement to improve the contrast pixels. Linear contrast enhancement, also referred to as a contrast stretching, linearly expands the original digital values of the remotely sensed data into a new distribution. By expanding the original input values of the image, the total range of sensitivity of the display device can be utilized. Linear contrast enhancement also makes subtle variations within the data more obvious. These types of enhancements are best applied to remotely sensed images with Gaussian or near-Gaussian histograms, meaning, all the brightness values fall within a narrow range of the histogram and only one mode is apparent. Training and learning functions are mathematical procedures used to automatically adjust the network's weights and biases.
???????D. Binarization
Image binarization is the process of taking a gray scale image and converting it to black-and-white, essentially reducing the information contained within the image from 256 shades of gray to 2: black and white, a binary image. This is sometimes known as image thresholding, although thresholding may produce images with more than 2 levels of gray. The process of binarization works by finding a threshold value in the histogram – a value that effectively divides the histogram into two parts, each representing one of two objects (or the object and the background). In this context it is known as global thresholding. Based on this step, binary image is created.
???????E. Segmentation
ANN has significant application in crack detection. The purpose of ANN is to generate a network system with little errors but also yield good result from the testing data set. In this module implement artificial neural network algorithm to classify image as normal or cracked. The neural network itself isn't an algorithm, but rather a framework for many different machine learning algorithms to work together and process complex data inputs. Such systems "learn" to perform tasks by considering examples, generally without being programmed with any task-specific rules. An ANN is based on a collection of connected units or nodes called artificial neurons, which loosely model the neurons in a biological brain. Each connection, like the synapses in a biological brain, can transmit a signal from one artificial neuron to another. An artificial neuron that receives a signal can process it and then signal additional artificial neurons connected to it. In common ANN implementations, the signal at a connection between artificial neurons are a real number, and the output of each artificial neuron is computed by some non-linear function of the sum of its inputs. The weight increases or decreases the strength of the signal at a connection. Artificial neurons may have a threshold such that the signal is only sent if the aggregate signal crosses that threshold.
Step 1: Randomly initialize the weights and biases.
Step 2: feed the training sample.
Step 3: Propagate the inputs forward; compute the net input and output of each unit in the hidden and output layers.
Step 4: back propagate the error to the hidden layer.
Step 5: update weights and biases to reflect the propagated errors.
Step 6: terminating condition
Based on these steps leaves and fruits are classified with disease names with improved accuracy rate.
VII. FEATURE EXTRACTION
A. Data flow diagram
A two-dimensional diagram explains how data is processed and transferred in a system. The graphical depiction identifies each source of data and how it interacts with other data sources to reach a common output. Individuals seeking to draft a data flow diagram must identify external inputs and outputs, determine how the inputs and outputs relate to each other, and explain with graphics how these connections relate and what they result in. This type of diagram helps business development and design teams visualize how data is processed and identify or improve certain aspects.
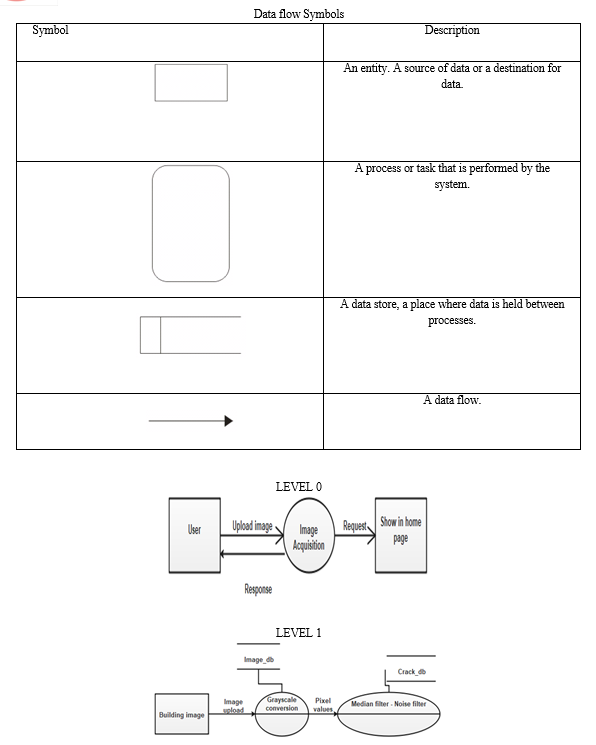
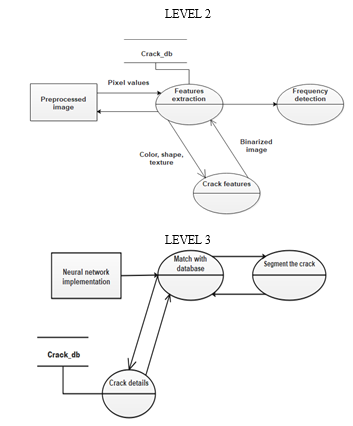
???????B. Input Design
In an information system, input is the raw data that is processed to produce output. During the input design, the developers must consider the input devices such as PC, MICR, OMR, etc.
Therefore, the quality of system input determines the quality of system output. Welldesigned input forms and screens have following properties −
- It should serve specific purpose effectively such as storing, recording, and retrieving the information.
- It ensures proper completion with accuracy.
- It should be easy to fill and straightforward.
- It should focus on user’s attention, consistency, and simplicity.
- All these objectives are obtained using the knowledge of basic design principles regarding −
- What are the inputs needed for the system?
- How end users respond to different elements of forms and screens.
- Objectives for Input Design
The objectives of input design are −
- To design data entry and input procedures
- To reduce input volume
- To design source documents for data capture or devise other data capture methods
- To design input data records, data entry screens, user interface screens, etc.
- To use validation checks and develop effective input controls.
2. Data Input Methods
It is important to design appropriate data input methods to prevent errors while entering data. These methods depend on whether the data is entered by customers in forms manually and later entered by data entry operators, or data is directly entered by users on the PCs.
A system should prevent user from making mistakes by −
- Clear form design by leaving enough space for writing legibly.
- Clear instructions to fill form.
- Clear form design.
- Reducing key strokes.
- Immediate error feedback.
Some of the popular data input methods are −
- Batch input method (Offline data input method)
- Online data input method
- Computer readable forms
- Interactive data input
3. Input Integrity Controls
Input integrity controls include a number of methods to eliminate common input errors by end-users. They also include checks on the value of individual fields; both for format and the completeness of all inputs.
Audit trails for data entry and other system operations are created using transaction logs which gives a record of all changes introduced in the database to provide security and means of recovery in case of any failure.
4. Output design
The design of output is the most important task of any system. During output design, developers identify the type of outputs needed, and consider the necessary output controls and prototype report layouts.
Objectives of Output Design
The objectives of input design are −
- To develop output design that serves the intended purpose and eliminates the production of unwanted output.
- To develop the output design that meets the end users requirements.
- To deliver the appropriate quantity of output.
- To form the output in appropriate format and direct it to the right person.
- To make the output available on time for making good decisions.
Let us now go through various types of outputs –
5. External Outputs
Manufacturers create and design external outputs for printers. External outputs enable the system to leave the trigger actions on the part of their recipients or confirm actions to their recipients.
Some of the external outputs are designed as turnaround outputs, which are implemented as a form and re-enter the system as an input.
6. Internal outputs
Internal outputs are present inside the system, and used by end-users and managers. They support the management in decision making and reporting. There are three types of reports produced by management information −
- Detailed Reports − They contain present information which has almost no filtering or restriction generated to assist management planning and control.
- Summary Reports − They contain trends and potential problems which are categorized and summarized that are generated for managers who do not want details.
- Exception Reports − They contain exceptions, filtered data to some condition or standard before presenting it to the manager, as information.
7. Output Integrity Controls
Output integrity controls include routing codes to identify the receiving system, and verification messages to confirm successful receipt of messages that are handled by network protocol.
Printed or screen-format reports should include a date/time for report printing and the data. Multipage reports contain report title or description, and pagination. Pre-printed forms usually include a version number and effective date.
Forms Design
Both forms and reports are the product of input and output design and are business document consisting of specified data. The main difference is that forms provide fields for data input but reports are purely used for reading. For example, order forms, employment and credit application, etc.
A good form design is necessary to ensure the following −
- To keep the screen simple by giving proper sequence, information, and clear captions.
- To meet the intended purpose by using appropriate forms.
- To ensure the completion of form with accuracy.
- To keep the forms attractive by using icons, inverse video, or blinking cursors etc.
VIII. RESULT AND DISCUSSION
A. Datasets
A data set (or dataset) is a collection of data. In the case of tabular data, a data set corresponds to one or more database tables, where every column of a table represents a particular variable, and each row corresponds to a given record of the data set in question. The data set lists values for each of the variables, such as height and weight of an object, for each member of the data set. Data sets can also consist of a collection of documents or files. In this project we can input the real time object datasets for analyze the object. This datasets have various crack images.
B. Result
A new framework that can inspect cracks objectively and efficiently in concrete ground structures through crack detection and measurement is proposed.
The framework detects crack using artificial neural networks that classify crack patches in the input image and segment cracks in the classified patches. Subsequently, it analyzes crack characteristics using image processing techniques. Verification using test data demonstrated that this proposed framework can reliably provide crack characteristics through the consecutive processes.
The proposed crack measurement method is able to calculate the physical length and width of the crack when the physical length of a pixel is given. Although the proposed measurement method was successfully verified using ideal data including the physical length of a pixel, images that are taken in the practical field do not contain physical length data. One possible solution is to shoot a crack together with a certain reference mark that has a predetermined shape and length. The reference mark can help estimate the physical length of a pixel. Lastly, although this study aims to propose a novel concrete crack inspection method, the effects of hyper-parameter changes in the proposed neural network should be further analyzed with a larger training data set prior to practical use to suggest appropriate parameter values more rigorously
Conclusion
In order to evaluate the safety of a concrete structure, a method to detect cracks from camera image was proposed. First, it was possible to visualize the concrete crack easily through the image processing techniques such as improved preprocessing, contrast enhancement, binarization and segmentation method. Second, the existence of cracks in many images could be automatically identified using the trained ANN. The proposed algorithm was verified with the real concrete surface image of a bridge and the result shows high accuracy in image classification. However, the test had the limitation that it was performed at the similar environmental conditions such as similar weather, existence of fog, hue of the concrete surface, the shape of structures. It means that construction environment is very diverse and the proposed algorithm needs to be evaluated in various fields of application. The algorithm also needs to be improved for the better accuracy. In addition, the various optimization methods can be applied to determine optimal parameters required in the image processing. It is important in the visualization of crack and the acquisition of the exact crack information.In future, we can extend the framework to implement various algorithms to improve the accuracy in crack detection and also extended with embedded framework.
References
[1] Subirats, Peggy, et al. \\\"Automation of pavement surface crack detection using the continuous wavelet transform.\\\" 2021 International Conference on Image Processing.IEEE, 2021. [2] Lange, J., W. Benning, and K. Siering. \\\"Crack detection at concrete construction units from photogrammetric data using image processing procedures.\\\" ISPRS commission VII mid-term symposium remote sensing: from pixels to processes, Enschede, Netherlands. 2021. [3] Yamaguchi, Tomoyuki, et al. \\\"Image?based crack detection for real concrete surfaces.\\\" IEEJ Transactions on Electrical and Electronic Engineering 3.1 (2021): 128-135. [4] Valença, J., et al. \\\"Assessment of cracks on concrete bridges using image processing supported by laser scanning survey.\\\" Construction and Building Materials 146 (2021): 668-678. [5] Zhang, Lei, et al. \\\"Road crack detection using deep convolutional neural network.\\\" 2021 IEEE international conference on image processing (ICIP).IEEE, 2021. [6] S. Mathavan, K. Kamal, and M. Rahman, “A review of three-dimensional imaging technologies for pavement distress detection and measurements,” IEEE Transactions on Intelligent Transportation Systems, vol. 16, no. 5, pp. 2353–2362, 2021. [7] R. Medina, J. Llamas, E. Zalama, and J. Gomez-GarciaBermejo, “Enhanced automatic detection of road surface cracks by combining 2d/3d image processing techniques,” in Proceedings of IEEE International Conference on Image Processing, 2020, pp. 778–782. [8] Y. Hu and C. Zhao, “A local binary pattern based methods for pavement crack detection,” Journal of Pattern Recognition Research, vol. 5, no. 1, pp. 140–147, 2020. [9] H. Oliveira and P. L. Correia, “Automatic road crack detection and characterization,” IEEE Transactions on Intelligent Transportation Systems, vol. 14, no. 1, pp. 155–168, 2020. [10] S. Varadharajan, S. Jose, K. Sharma, L. Wander, and C. Mertz, “Vision for road inspection,” in Proceedings of 2020 IEEE Winter Conference on Applications of Computer Vision, 2020, pp. 115–122.
Copyright
Copyright © 2022 Mr. V. Maheskumar, S. Sangeetha, S. Shripriya, S. Tharani. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44303
Publish Date : 2022-06-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online