

Ijraset Journal For Research in Applied Science and Engineering Technology
Captioning Image Using Deep Learning: A Novel Approach
Authors: Sunanda Chakraborty, Shibam Chakraborty, Moloy Dhar, Nirupam Saha, Bidyutmala Saha, Pallabi Das, Rafiqul Islam, Sutapa Sarkar
DOI Link: https://doi.org/10.22214/ijraset.2023.54297
Certificate: View Certificate
Abstract
Captioning image using deep learning is a technology that aims to generate descriptive and accurate textual descriptions for images. By using the power of deep neural networks, this approach enables computers to understand and interpret visual content bridging the gap between the visual and textual domains. This paper focuses on developing an image captioning system using deep learning techniques. The paper aims to generate descriptive textual captions for images, enabling machines to understand and communicate the content of visual data. The methodology involves leveraging convolutional neural networks (CNNs) for image feature extraction and recurrent neural networks (RNNs) for sequential language generation. Captioning images is a challenging task in computer vision that involves describing the content of an image in natural language. In recent years, deep learning techniques have shown remarkable success in various computer vision tasks, including image captioning.
Introduction
I. INTRODUCTION
Captioning image using deep learning is an innovative procedure which combines computer vision and natural language processing to automatically generate descriptive captions for images. It addresses the challenging task of overcoming the gap between visual perception and language understanding. VGG-19 has been pre trained on more than a million images from ImageNet database so the output comes out quite accurate. Image captioning is an exciting field at the intersection of computer vision and natural language processing (NLP). It involves generating descriptive textual captions for images, enabling machines to understand and communicate the content of visual data. Deep learning techniques, such as (CNNs) and recurrent neural networks (RNNs), have shown remarkable success in image captioning tasks.
The paper will leverage a pre-trained CNN to extract meaningful features from the images. These extracted features will serve as input to the RNN-based captioning model. The RNN, equipped with recurrent cells such as LSTM or GRU, will learn to generate descriptive captions based on the extracted image features. Training the model will involve optimizing the parameters to minimize the captioning loss. In this paper, we are using MS-COCO dataset which is used for large-scale object detection, segmentation and captioning and are used in various computer vision papers. It contains 328,000 images of everyday objects and humans. It contains feature-rich annotations including object detection, captioning, person-keypoints and more. Accurate image captioning has numerous practical applications, including assisting visually impaired individuals in understanding images, enhancing image search engines, and enabling better image indexing and retrieval. Our approach consists of two main components: an image encoder and a language decoder. The image encoder employs a pre-trained CNN, such as VGG or ResNet, to extract high-level visual features from the input image. These features capture the semantic information present in the image and serve as the input to the language decoder. The language decoder is implemented using an RNN, specifically a long short-term memory (LSTM) network, which generates captions based on the visual features obtained from the image encoder.

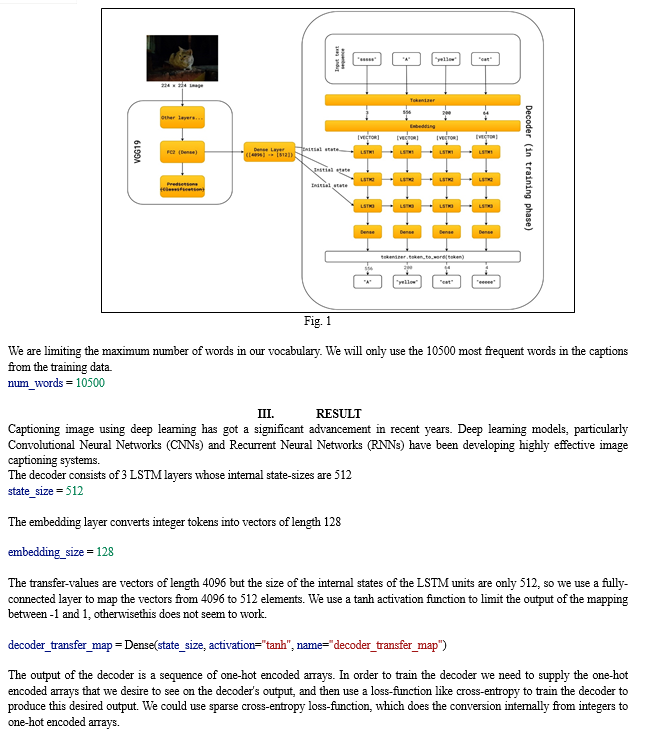

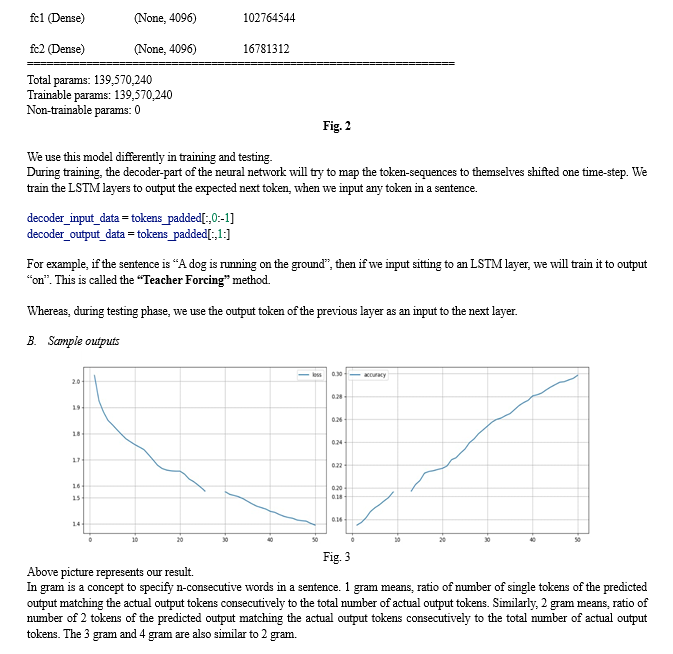
Conclusion
Captioning image using deep learning has emerged as a highly promising and effective approach for generating textual descriptions for images using CNN, RNN and LSTM model along with advancements such as attention mechanisms and transfer learning, has led to significant improvements in the quality and accuracy of generated captions.This paper successfully implemented and trained the models on a suitable dataset, evaluated their performance using quantitative metrics, and discussed the obtained results. We compare our model against state-of-the-art methods and demonstrate its superiority in terms of caption quality, fluency, and relevance. This paper showcased the potential of deep learning in addressing the challenging task of generating accurate and contextually relevant captions for images and videos. By leveraging the power of CNNs for visual feature extraction and RNNs for language modeling, the developed system demonstrated the ability to understand the visual content and generate descriptive captions.
References
[1] Yang, L., & Hu, H. (2019). Adaptive syncretic attention for constrained image captioning. Neural Processing Letters [2] Fu, K., Jin, J., Cui, R., Sha, F., & Zhang, C. (2016). Aligning where to see and what to tell: Image captioning with region-based attention and scene-specific contexts. IEEE transactions on pattern analysis and machine intelligence [3] Li, J., Yao, P., Guo, L., & Zhang, W. (2019). Boosted Transformer for Image Captioning. Applied Sciences(19) [4] Oluwasanmi, A., Aftab, M. U., Alabdulkreem, E., Kumeda, B., Baagyere, E. Y., & Qin, Z. (2019). CaptionNet: Automatic end-to-end siamese difference captioning model with attention. [5] Farhadi, M. Hejrati, M. A. Sadeghi, P. Young,C.Rashtchian, J. Hockenmaier, and D. Forsyth. Every picture tells a story: ?Generating sentences from images.?7. Peter Anderson, Xiaodong He, Chris Buehler, DamienTeney, Mark Johnson, Stephen Gould, and LeiZhang. 2017.? Bottom-up and top-down attention for image captioning and vqa?. [6] J. Donahue,L. Anne Hendricks,S. Guadarrama,M. Rohrbach, S. Venugopalan, K. Saenko, and T.Darrel?Long-term recurrent convolutional networks for and description?. InCVPR, 2015. [7] Oriol Vinyals, Alexander Toshev, Samy Bengio, andDumitru Erhan. 2014. Show and tell: A neural im-age caption generator. [8] YonghuiWu,MikeSchuster,ZhifengChen,QuocVLe,MohammdNorouzi,WolfgangMacherey,MaximKrikun,YuanCao,Qin Ga0,KlausMacherrey,et at.2016.Google’sneural machine translation system:“Bridging the gap between human and machine translation”. [9] Fang, F., Wang, H., Chen, Y., & Tang, P. (2018). Looking deeper and transferring attention for image captioning. Multimedia Tools and Applications, 77(23). [10] Oriol Vinyals, Alexander Toshev, Samy Bengio, andDumitru Erhan. 2014. Show and tell: A neural image captiongenerator.
Copyright
Copyright © 2023 Sunanda Chakraborty, Shibam Chakraborty, Moloy Dhar, Nirupam Saha, Bidyutmala Saha, Pallabi Das, Rafiqul Islam, Sutapa Sarkar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET54297
Publish Date : 2023-06-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online