

Ijraset Journal For Research in Applied Science and Engineering Technology
Character Segmentation and Recognition of Marathi Language
Authors: Saurabh Ravindra Nikam, Dr. D. L. Bhuyar, Mr. B. R. Guru
DOI Link: https://doi.org/10.22214/ijraset.2021.39566
Certificate: View Certificate
Abstract
: In this paper Segmentation is one the most important process which decides the success of character recognition fashion. Segmentation is used to putrefy an image of a sequence of characters into sub images of individual symbols by segmenting lines and words. In segmentation image is partitioned into multiple corridor. With respect to the segmentation of handwritten words into characters it\'s a critical task because of complexity of structural features and kinds in writing styles. Due to this without segmentation these touching characters, it\'s delicate to fete the individual characters, hence arises the need for segmentation of touching characters in a word. Then we consider Marathi words and Marathi Numbers for segmentation. The algorithm is use for Segmentation of lines and also characters. The segmented characters are also stores in result variable. First it Separate the lines and also it Separate the characters from the input image. This procedure is repeated till end of train.
Introduction
I. INTRODUCTION
The Indian Devanagari character segmentation and recognition system, which de fines the ability of a machine to analyze and identify the script characters is implemented here. Over the last few decades, machine reading has grown day by day. Recognition Optical character recognition in image processing and artificial intelligence has become one of the most successful applications of technology. Its classification based on two major factors: acquisition of data process and the type of text type (Noise reduced). The goal state is to fetch the character of Marathi language into digital form after identification. The basic Character set of Marathi language is called as Aksharas. Samyuktaksharas is the joint character word of Marathi language. The Samyuktaksharas consists of vowels, consonants and joint characters. The character set of Marathi language contains of 34 consonants and 12 vowels in addition of 14 vowel modifiers. Besides consonants and vowels, it also contains modifiers called Kana, a slating line placed at the top of character and Matra's which are placed at left or right part of the character. The half character increases complexity of script and lower modifier too. The Marathi language writing style is from left to right. The segmentation of character is an operation of decomposing image into sub image. There after several operations like preprocessing feature extraction, and its respective classification is done. Technology of Marathi language character recognition had been led to more transform development.
The various researches had been implemented on Marathi language character recognition. Image of written document in Marathi language fed as an input image and the editable file taken as output has been implemented. The structure of the script was used in the proposed scheme for segmentation with a homogenous set of features for recognition, which are computationally simple for extracting. Final recognition performed by Support Vector Machine (SVM) classifiers [1]. Patterns orientate segmentation technique for optical character recognition that contributes to document structure analysis. An extended form of pattern oriented segmentation is considered. An efficient and computationally focused method for segmenting character and graphics part of scanned images based on textural cues is used. It segmented 530 M. S. Khanderão and S. Ruikar using vertical and horizontal projection whereas convex hull technique for feature extraction used [2].
The data set is maintained for preparation and character classification. Data base created by performing standard operations like preprocessing, feature extraction, and distribution of Training set and Testing set. The Deep Convolution Neural Network trains the training set and accuracy evaluated from Testing set [3].
To perform high accuracy for recognition neural network is implemented in the system. The hidden layer and output layer each consist of 33 neurons [4, 5]. The combination classifier used for classification to solve classification problem. The combination of various networks is having more advantage as compare to individual one [6].
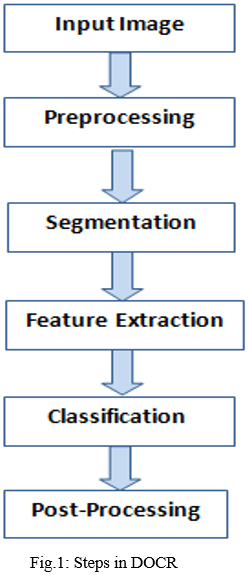
II. SYSTEM DESIGN OF DEVANAGARI OPTICAL CHARACTER RECOGNITION (DOCR)
Devanagari optical character recognition converts image of text into digital text. It has various applications such as postal address automation, historical document preservation, etc. Character recognition is an interested area in developing systems that works in documents analysis and recognition. Input can be taken from sources such as mobile, PDA, digitizer, etc. OCR converts input text to digital text as it is present in the input image. Device used for input text can be a mobile, PDA or any special digitizer. Documents are scanned using a scanner and converted into digital image so that computer understands and processes that text. DOCR is used to digitize image documents. Designing and developing DOCR is more complicated and challenging task.
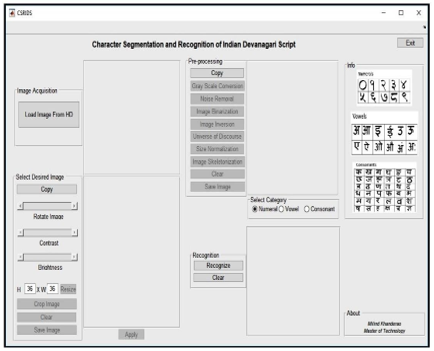
A. Image Pre-processing
It is the processes in which some morphological operations are performed on image, in order to extra useful information from it into digital form are called as Image pre-processing. Initially the digital images contain various objects with noise and have to remove it without distortion. To enhance the properties of the image, the series of operations performed in pre-processing. To get better results, it is essential for image enhancement. In proposed system two dimensional images are utilizes for all the sets of operations.
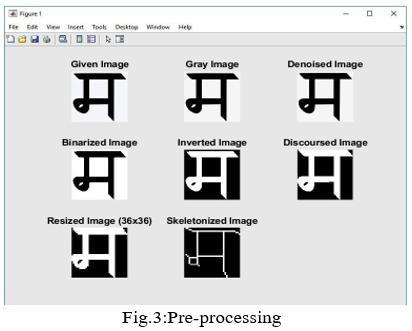
- RGB Image to GRAY Image: An RGB image is mainly considered as a true image. Three colors red, green, and blue combined form any color visible spectrum. Initially raw input image taken is referred RGB image. Further that is converted into Gray perform necessary operations on it. In scale images, only shades are present, the input all further process. . The reason for differentiating such images from any other sort of color image is that less information needs to be provided for each pixel. In fact a `gray' color is one in which the red, green and blue components all have equal intensity in RGB space, and so it is only necessary to specify a single intensity value for each pixel, as opposed to the three intensities needed to specify each pixel in a full color image. Gray scale images are very common, in part because much of today's display and image capture hardware can only support gray scale images. In addition, gray scale images are entirely sufficient for many tasks.
- Noise Removal: Digital images contain various types of noise. In the image acquisition process, it is added in the image. To nullify noise various filters used like high-pass, low pass, band pass, average filters etc. The median filter is used in proposed system to reduce blurring of character and improve the feature. The median filter avoids edges degradation. We cannot remove it completely but we can reduce it up to certain extent. By applying various filters we can reduce the noise present in the digital image. The filter removes the noise after filtering it through filter. The median filter considers each pixel in the image in turn and looks at its nearby neighbors to decide whether or not it is representative of its surroundings. Instead of simply replacing the pixel value with the mean of neighboring pixel values, it replaces it with the median of those values.
- Binary Image: An image having only two values for each pixel is nothing but the binary image. Precisely, two, white and black are accustomed for binary. These are also called bi-level or two-level images. Here, each pixel is stored as single bit either 0 or 1. As binary image having only two values (0&1), it reduces the storage requirements as compared with RGB or Gray. Binary images often utilized in image processing as masks or as the result of certain operations such as segmentation and thresholding. Most of morphological operations binary image is essential. Gray level has different gray intensity values but binary image have only either 0 or 1. It reduces the storage requirement and increases the rate of processing by converting the gray scale image in to binary image.
- Inversion of Image: Image inversion is a process where dark areas are mapped as light and light areas are mapped as dark. In simple word, black is converted to white and white is converted to black. The resultant black and white image is the replication of original image in white to black and vice versa. The binary image is used as input image for this operation. The inverted image is very helpful for various operations. The objects present in the inverted image more highlighted as compare to binary image. Background of an inverted image is mostly black colored whereas the foreground or the objects are in white colored.
- Universe of Discourse: The smallest matrix where entire character skeleton gets fitted is universe of discourse. Features extracted from scanned image of character have positions of different line segments, so universe of discourse has to be selected. After applying it gives the image fitted to required image size and the unwanted background suppressed resulting in enlarging objects of input image.
- Image Normalization: It is a process in which range of pixel intensity values is changed. Sometimes, nor malization is referred as histogram stretching or contrast stretching. Input image his to gram and the processed image histogram show the difference properly. The image normalization enhances the input image, which results in sharpen output image.
- Image Skeletonization: It is a process where foreground pixels in a binary image are reduced to a skeletal remnant. For doing the image skelesization, input image has to undergo some morphological operations such as thinning. It successively erodes away the boundary pixels without affecting the end points of object segment. The morphological thinning process results into skeleton of input image. The alternative method is to first compute distance transform of image. Skeleton then lies along the distinctiveness in distance transform.
B. Segmentation
For character segmentation, the scheme has been proposed, where at the beginning; pre- processing is performed on Input images Document. Subsequently, one pixel width image, i.e. thinning operation is applied on words and projection profile is used to find primary segmentation paths. Later, distance related criteria are utilized to get fine segmentation paths. Image segmentation is the process segmenting an image into multiple parts of image segments with characteristics and extracting regions of interest, and it is the basics of image analysis. The quality of image segmentation directly affects the results of the concern image processing operation. In the segmentation process, the pre-processed input image undergoes partitioning an image into multiple parts by extracting the region of interest. It is the basis of image analysis. The quality of image segmentation directly affects the results of the concerned image processing operation. Segmentation methods include thresholding, edge detection, graph cut method, and machine learning-based method. In thresholding objects of interest are separated from their background by some grey-level threshold value.
The g(i. j) is obtained by applying threshold function to f(i, j), then
G (i. j) = 1 if f (i. j) > T
= 0 Otherwise
Threshold is obtained using: T, = M (i.j.p(i.j).f(i.j).
In the above expression, T is the threshold. F (i. j) is the gray value of (i. j) & p (i. j) is some local property of point such as the average gray value of neighborhood centered on the point(i. j).
C. Feature Extraction
Feature extraction is the process where relevant information about different shapes present in the pattern is detected and put in a vector to use further for classification. Depending on the feature vectors system classifies the inputs with significant accuracy. So, the features extracted should be highly discriminative with reduced dimensions in order to reduce the computation requirements in classification. Feature extraction is done properly, and then it can also reduce the errors such as mean square error or inter-distance differences, etc.
Each character has some features, which play an important role in pattern recognition. Indian Marathi language characters have many particular features. Feature extraction describes the relevant shape information contained in characters so that the task of classifying the character is made easy by a formal procedure. Feature extraction stage in Marathi language characters Character system analyses these Marathi language characters Character segment and selects a set of features that can be used to uniquely identify. Mainly, this stage is main part of system because output depends on these features.
- Zoning: In the process of zoning, a binary image having Marathi language characters which are pre-processed and normalized to a size of 36 x 36 is partitioned into n number of equal-sized zones. Then features are extracted from the individual zone. The advantage of finding features from individual zone over that from the whole images is that it provides more detailed information regarding small and finer details in the skeleton of the character image. After calculating feature vectors from each zone, they are put in an array to make one feature vector representing the features for a given input image.
- Directional Features: These features are extracted from the image skeleton, based on the line types forming the character skeleton. To do this, the image is zoned or partitioned into 3 x 3 sub-images and features are extracted from each of the zones.
Moment Invariant Features
These features are extracted from image skeleton, based on the line types forming the character skeleton. To do this, image is zoned or partitioned into 3 × 5 sub images and features are extracted from each of the zones.
Moment Invariant Features
These are the statistical features. In object recognition, moments play a significant role. This method measures the intensity function. It gives global character information.
III. CLASSIFICATIONS AND RECOGNITION
After features are extracted, inputs are classified and recognized depending upon the feature values. For this, in this system two classifiers, namely, SVM (Support Vector Machine) and MLP (Multi-Layer Perceptron).
A. Support Vector Machines
The concept of SVM is based on linear separation using hyper plane which is fitted to two classes within multi-dimensional space. SVM is the supervised method of classification in which both target and input data sets are given.
Styles
- Classification Tasks with Hyper Planes: SVM uses hyper plane to divide the data into some groups of similar elements. Here we consider hyper planes that are linear in nature. In 2-Dimensional space, this would be a straight line and in 3-Dimensional space, it would be a plane.
- Maximum Margin: A maximum margin hyper plane, in simple words, is just a line/surface that creates separation between the class’s data. In the given figure, any of the three lines could do the job of separating the data. But the one with the ability to create the greatest separation would take care of some variations in positions of data points near boundary. These variations may lead to miss-classifications.
- Support Vectors: Support vectors are those points in each of the classes that are closest to maximum margin hyper plane. Every class should have at least one support vector, but maybe having more than one (see Fig. 2).
In n-dimensional space, the hyper plane is defined as W X+B=0 where W is a vector of i.e. [wl, w2.....wn]. B is a single number called the bias. Using the formula, aim of the algorithm is to find out a set of weights that specify two hyper planes as follows.
W. X – B >= 1 W .X + B
IV. RESULTS
The results produced for the recognition of Indian Marathi language character becomes difficult due to presence of odd characters or similarity in shapes for multiple characters. Scanned image is pre-processed to get a cleaned image and the characters are isolated into individual characters. Preprocessing work is done in which normalization, filtration is per formed using processing steps which produce noise free and clean output. Managing our evolution algorithm with proper training, evaluation other step wise process will lead to successful output of system with better efficiency. Use of some statistical features and geometric features through neural network will provided better recognition result of Indian Marathi language characters.
Devanagari Character Recognition using neural network performed with hybrid features extraction method. It is the combination of geometric and statistical feature extraction technique. The geometric feature extraction techniques use directional features. The statistical feature technique uses distribution of pixel density and Euclid features of the skeletonized character image. SVM and MLP classifier used for classification of Marathi language character. The Support vector machine has more accuracy as compare to MLP. The SVM is slower than the MLP.


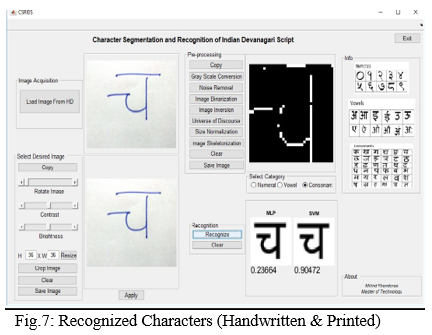
Conclusion
V. CONCLUSION Many regional languages throughout the world have different writing styles which can be recognized with this system using proper algorithms and strategies. We have learned to recognition of Indian Marathi language characters. It has been found that recognition of Indian Marathi language characters becomes difficult due to the presence of odd characters or similarity in shapes for multiple characters. A scanned image is pre-processed to get a cleaned image and the characters are isolated into individual characters. Preprocessing work is done in which normalization; filtration is performed using processing steps that produce noise-free and clean output. Managing our evolution algorithm with proper training, evaluation another step-wise process will lead to the successful output of the system with better efficiency. The use of some statistical features and geometric features through a neural network will provide better recognition results of Indian Marathi language characters. This work will be helpful to the researchers for the work towards another script. A. Application 1) Aid for blind 2) Automatic number-plate readers 3) Form readers 4) Signature verification and identification.
References
[1] Y. Ren, X. Chen, J. Jia, W. Gao, and J. Zhu, ‘‘Environment monitoring and temperature prediction in greenhouse based on wechat platform,’’ Nongye Jixie Xuebao., vol. 48, no. s1, pp. 302–307, Dec. 2017. doi: 10.6041/j.issn.1000-1298.2017.S0.046. [2] X. Zheng, ‘‘Expert control systems for modern greenhouse climate,’’ Jidian Gongcheng., vol. 20, no. 3, pp. 42–45, 2003. doi: 10.3969/j.issn.1001- 4551.2003.03.014. [3] F. G. Montoya, J. Gómez, A. Cama-Pinto, A. Zapata-Sierra, F. Martínez, J. de la cruz, and F. Manzano-Agugliaro, ‘‘A monitoring system for intensive agriculture based on mesh networks and the Android system,’’ Comput. Electron. Agricult., vol. 99, pp. 14–20, Nov. 2013. doi: 10.1016/j.compag.2013.08.028. [4] R. Pahuja, H. K. Verma, and M. Uddin, ‘‘A wireless sensor network for greenhouse climate control,’’ IEEE Pervasive Comput., vol. 12, no. 2, pp. 49–58, Apr. 2013. doi: 10.1109/MPRV.2013.26. [5] W. S. Lee, V. Alchanatis, C. Yang, M. Hirafuji, D. Moshou, and C. Li, ‘‘Sensing technologies for precision specialty crop production,’’ Comput. Electron. Agricult., vol. 74, no. 1, pp. 2–33, Oct. 2010. doi: 10.1016/j.compag.2010.08.005. [6] N. K. D. N, ‘‘ARM based remote monitoring and control system for environmental parameters in greenhouse,’’ in Proc. IEEE ICECCT, Coimbatore, India, Mar. 2015, pp. 1–6. doi: 10.1109/icecct.2015.7226117. [7] Y. He, M. Liang, L. Chen, D. Xu, and S. Du, ‘‘Greenhouse environment control system based on IOT,’’ Zhengzhou Daxue Xuebao Lixueban, vol. 50, no. 1, pp. 90–94, Mar. 2018. doi: 10.13705/j.issn.1671- 6841.2017263. [8] S. Du, Y. He, M. Liang, L. Chen, J. Li, and D. Xu, ‘‘Greenhouse environment network control system,’’ Nongye Jixie Xuebao, vol. 48, no. s1, pp. 296–301, Dec. 2017. doi: 10.6041/j.issn.1000-1298.2017.S0.045. [9] U. Pal, P. P. Roy, N. Tripathy and J. Llados, ?Multi-oriented Bangla and Devnagari text recognition\", Pattern Recognition., Volume 43, Issue 12, pp. 4124–4136, 2010. [10] Sandhya Arora, Debotosh Bhattacharjee, Mita Nasipuri, \"Combining Multiple Feature Extraction Techniques for Handwritten Devnagari Character Recognition\", 3rd IEEE International conference on Industrial and Information Systems, pp. 1-6, 2008. [11] M. Vaidya and Y. Joshi, \"Marathi Numeral Recognition using statistical distribution features\", In: Proc. IEEE conference on Information processing, pp. 586-591, 2015. [12] M. Vaidya and Y. Joshi, \"Handwritten Numeral Identification System Using Pixel Level Distribution Features\", In: Proc. 2nd International Conference on Information and Communication Technology for Intelligent Systems, Vol. 2, pp. 307-315, Springer, Cham, 2017. [13] J. Memon et al.: Handwritten OCR: A Comprehensive SLR are all based on different deep learning architectures,e.g. CNN, RNN or LSTM. [14] C. C. Tappert, C. Y. Suen, and T. Wakahara, ‘‘The state of the art in online handwriting recognition,’’ IEEE Trans. Pattern Anal. Mach.Intell., vol. 12, no. 8, pp. 787–808, Aug. 1990, doi: 10.1109/34.57669. [15] M. Kumar, S. R. Jindal, M. K. Jindal, and G. S. Lehal, ‘‘Improved recognition results of medieval handwritten Gurmukhi manuscripts using boosting and bagging methodologies,’’ Neural Process. Lett., vol. 50,pp. 43–56, Sep. 2018. [16] M. A. Radwan, M. I. Khalil, and H. M. Abbas, ‘‘Neural networks pipeline for of?ine machine printed Arabic OCR,’’ Neural Process. Lett., vol. 48,no. 2, pp. 769–787, Oct. 2018. [17] P. Thompson, R. T. Batista-Navarro, G. Kontonatsios, J. Carter, E. Toon, J. McNaught, C. Timmermann, M. Worboys, and S. Ananiadou, ‘‘Text mining the history of medicine,’’ PLoS ONE, vol. 11, no. 1, pp. 1–33, Jan. 2016. [18] K. D. Ashley and W. Bridewell, ‘‘Emerging AI & Law approaches to automating analysis and retrieval of electronically stored information in discovery proceedings,’’ Artif. Intell. Law, vol. 18, no. 4, pp. 311–320,
Copyright
Copyright © 2022 Saurabh Ravindra Nikam, Dr. D. L. Bhuyar, Mr. B. R. Guru. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET39566
Publish Date : 2021-12-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online