

Ijraset Journal For Research in Applied Science and Engineering Technology
COPD Patients’ Readmission Using Machine Learning
Authors: B. Sai Venkat, J. Harika, Asst Prof Mrs. Meenakshi Bhrugubanda
DOI Link: https://doi.org/10.22214/ijraset.2023.53486
Certificate: View Certificate
Abstract
Patient reading can be considered an important factor in reducing costs while maintaining quality patient care. Therefore, predicting and managing patients effectively will lead to better outcomes. we are aiming to predict some of the readings of chronic obstructive pulmonary disease patients using some machine learning algorithms. By using Area under curve and accuracy are important features for calculating the predictive power of a model over any time period. Then clearly define the significance of the change for each value and then distinguish the significance of the change. study achieves the highest accuracy in estimating readings, with an ACC of 91%.
Introduction
I. INTRODUCTION
Prescient analysis is foremost utilized (Data Innovation) procedures in health informatics Prescient analytics and information gathering have been used to control the proliferation of persistent maladies.
By and large, amid the later healthcare related investigate has centred on creating, actualizing IT models to aim the basic needs of health frameworks.
Most of the times consider centre on improving huge sums information to get important data and experiences almost the present and further behaviour of the framework beneath thought. Persistent Obstructive Aspiratory Malady. This can be characterized as one of the lungs infections identified by wind current shackling. Around the world, COPD is deemed as one of the main reasons driving to higher rates of passing. The Worldwide Problem of Malady Think about evaluated is spread around 250 million cases.
II. LITERATURE SURVEY
The foremost commonly utilized stipend methods to adjust classes are the distinctive blunder taken a toll negatives procedure, the over-sample technique. There were constrained ponders within some writing which display the issue of unfair readmission information.
Other basic issue which emerges in endeavouring the foresee healing centre readmission is the taken a toll awkwardness misclassification issue.
Finest of information, the readmission prescient writing has occasionally considered the taken a toll lop-sidedness misclassification issue. Machine learning calculations have been broadly utilized for patients. Most widely used calculations are: Naive Bayes, Decision Tree, Support Vector Machines, Artificial Neural Systems, and Random Forest. Diverse ponders compared prescient models based on their anticipated yield. Be that as it may, most of these ponders endure from destitute expectation quality, as the accuracy is extended from 0.57 to 0.74.
III. PROPOSED SYSTEM
- Sign in page the user should be provided with sign in page so that the user can enter details of name and password.
- Entering the data record
- By evaluating for the required algorithms the data which is provided the best possible algorithm is chosen for the accuracy prediction
- The prediction of the patient’s readmission gives the result that whether the patient readmits in the hospital for 30days.
A. Advantages
It identifies accurately for highly risked patients.
Letting healthcare participants to reply appropriately.
IV. PROPOSED ARCHITECTURE
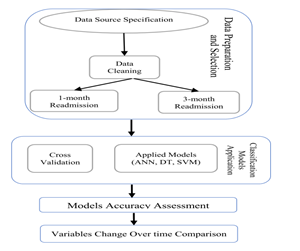
V. PROPOSED ALGORITHM
- Random Forest: This supervised ML algorithm widely utilized in set and regression problems.
- SVM: Support Vector Machines or SVMs are learning techniques for classification problems. The purpose of this algorithm is to find a good boundary that can divide the n-dimensional space into classes.
- Naïve Bayes: This is the easiest and more actual classifications technique that helps to shape better understand of models and make the fastest predictions.
- Decision Trees: A decision tree is an unsupervised learning process for classification and reprocessing.
- ANN: Artificial Neural Networks (ANN) use the brain as a framework to simulate complex models and create algorithms that can be used to predict problems.
- XG Boost: This is the supervised machine learning algorithm which is an open source implementation.
- Logistic Regression: In distribution problems, the objective variable y can only lead to opposite results for a particular process (or input) X.
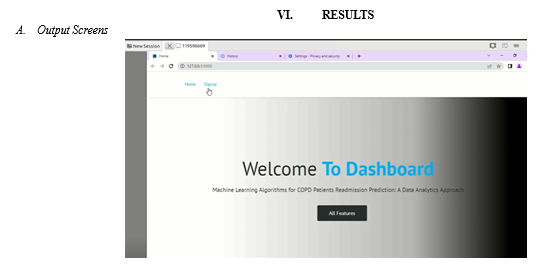
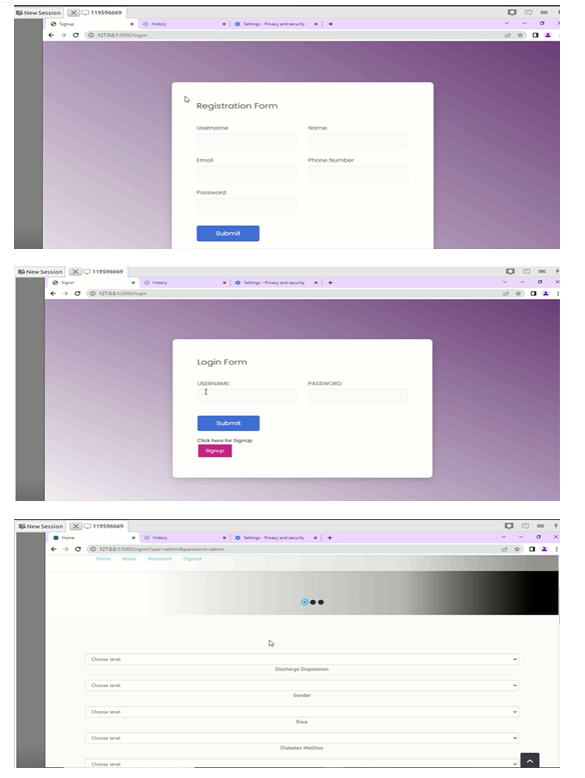
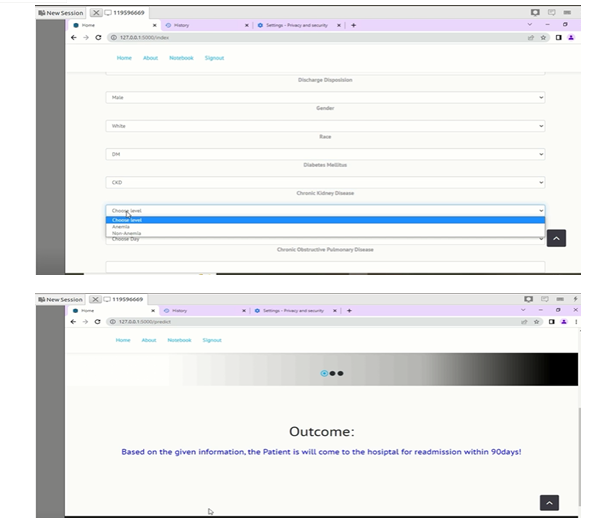
Conclusion
The actual support can be reviewed by using Machine Learning Algorithms to solve problem of inequality, using treatment vector scattering to avoid the limitations of model read estimation and thus improve estimation. This project is the comparison of various learning methods for the prediction of hospital readmission estimates. However, this study has little limitations because of self-payment and limited use. It is likewise very tough to have an expert for researching needs like data collection, maintenance and preparation. The other limitation of this study is the smaller number of patients with COPD (195 cases). Further research direction is to explore alternate methods to develop classification models. We also plan to receive more accurate information of patient admission after discharge, which is more beneficial for designing and building a better and more efficient model.
References
[1] K. Yang, ‘‘TaGiTeD: Predictive brief directed tensor decomposition for representation learning from electronic health records, AAAI Feb. 2021. [2] D. Chen, S. Sohn, E. B. Haberman, C. B. Storlie, J. M. Naessens, Liu, ‘‘Deep learning and alternate learning policies’’ in Dec. 2020 [3] S. Meena and Deepika, ‘‘Predictive analytics to prevent and control chronic diseases, iCATccT 2020.
Copyright
Copyright © 2023 B. Sai Venkat, J. Harika, Asst Prof Mrs. Meenakshi Bhrugubanda. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET53486
Publish Date : 2023-05-31
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online