

Ijraset Journal For Research in Applied Science and Engineering Technology
Creating Face Transition using Deep Fake Technology with its Architecture
Authors: Prajakta Malgunde, Kunal Kulkarni, Kundan Chaudhari, Rohit Gavit, Prof. Varsha Gosavi
DOI Link: https://doi.org/10.22214/ijraset.2023.56455
Certificate: View Certificate
Abstract
Deep fake videos are videos where the features and expressions of a person are replaced with the features and expressions of another person. Videos can be converted or manipulated using powerful Deep Learning techniques. This technology may be used in wrong way or maliciously as a means of spreading misinformation of any activity, manipulation, and persuasion. Currently there are not many solutions to identify products of Deep fake technology, although there is significant research being conducted to tackle or handle with this problem. Generative Adversarial Network (GAN) is the one often researched deep learning technology. These networks preferred to develop or generate the non-existing patterns or creations. In this work, we’re working on the development of first order motion model for image animation using Dense motion network. Using key point detectors as a baseline, we train a GAN and extract the facial landmarks from the driving video and building the embedding model to create the synthesized video using the dedicated module to prepare the Deep fakes. At the end, we shows a model to get the efficacy of a group of GAN generators using dense motion networks. Our results generate the augmented animation video using the sequel driving combination of driving video with source image. This project can be used in many areas like multiplying the dataset counts with minimum number source, CG platforms where gaming industry animation industry using to create real-time backgrounds characters, Cloth translations, 3D object generation, etc.
Introduction
I. INTRODUCTION
Deep Fake technology using GANs (Generative Adversarial Networks) is a powerful tool for creating realistic face transitions in real-time. GANs are a neural network architecture which contains two model or networks: a generator and a discriminator. The generator takes an image and creates a new image based on it. The discriminator is then used to evaluate the generated image and determine whether image is real or fake. By training the GANs on a large dataset of images, the GANs can learn to generate realistic face transitions. This technology has been used to create realistic deepfake videos, which can be used for entertainment, research, and other applications. Generative Adversarial Network(GAN) is a type of deep learning(DL) algorithm. GAN is used to create synthetic data which is artificial or nonnatural that is man-made. GAN consist of two neural networks which work together that are generator and discriminator network. The generator model takes random noisy as input and generate similar data that is intended to resemble a particular type of real data. The discriminator model takes both real data and synthetic data as input and tries to seperate between them. The aim of generator is to generate artificial data which looks like real and makes discriminator fool to think that it is real. Both networks play a game during training in which generator try to produce better artificial data on the other hand discriminator try to distinguish between real and artificial data. At the end the result is generator network can generate artificial data which is indistinguishable from real data by discriminator. Image and video synthesis, text generation these includes in variety of applications of GAN. They are particularly useful in situations where there is limited or expensive real data, or where the generation of synthetic data can help augment existing datasets. A deep learning architecture which consists of two neural networks doing competition against each other called Generative Adversarial Network. To generate new and artificial data which resembles some known data distribution is the goal of GAN. Generative Adversarial Networks(GANs) has three main parts they are as follows: Generative: It is a model which describes how data is generated same to real data. Adversarial: in this setting training of model is done. Networks: for training purpose it uses neural networks as artificial intelligence algorithm.
II. EXISTING SYSTEM
- DeepFaceLab: DeepFaceLab is a popular open-source deep fake software that allows users to create and manipulate deep fake videos. It provides both high-quality and high-speed models for deep fake generation.
- Faceswap: Similar to DeepFaceLab, Faceswap is an open-source deep fake software that enables users to swap faces in videos. It offers a user-friendly interface and various customization options.
- ReFace: ReFace is a deep fake app that allows users to create fun and entertaining deep fake videos with just a few clicks. It is designed for the consumer market and is available on mobile devices.
- Deepware Scanner: Deepware Scanner is an app designed for detecting deep fake content. It uses AI-based technology to identify manipulated media, helping users spot deep fake videos and images.
- Microsoft Video Authenticator: Microsoft has developed a tool called Video Authenticator, which can be integrated into video platforms and content management systems. It analyzes videos for signs of manipulation, including deep fakes, and provides a confidence score.
- Deepware Scanner: This mobile app is designed to identify deep fake videos. It uses artificial intelligence to analyze videos for signs of manipulation and provide users with information about the authenticity of the content.
- Deepware Scanner: Deepware Scanner is a mobile app designed to detect deep fake videos. It uses AI technology to analyze videos and determine the likelihood of manipulation.
- Amber Video: Amber Video is an AI-powered platform that helps organizations identify deep fake content in real-time. It is aimed at businesses and government agencies concerned about the potential impact of manipulated media.
- Deepware Scanner: This mobile app is designed to detect deep fake videos. It uses AI technology to analyze videos for signs of manipulation and provide users with information about the authenticity of the content.
- Media Forensics Toolkits: Several media forensics toolkits and software solutions are available for researchers and professionals to detect deep fake content. These often involve the use of digital forensics techniques to uncover inconsistencies in the media.
III. PROPOSED SYSTEM
The face transition systems face the problem of large dataset size. the reading, processing and interpretations of massive image dataset take more processing latency. The graphical processing unit utilized for processing the high density images are more and developed with complex structures. the dimensionality reduction through feature mapping is adopted to overcome the problem. the proposed algorithm keenly focus on deriving the unique features and analysis of feature mapping for reduced usage of GPU.
IV. ALGORITHM
Deep fake technology relies on various algorithms, often based on deep learning, to create and detect manipulated media. Here are some key algorithms and techniques commonly used in deep fake technology:
A. Deep Fake Creation Algorithms
- Generative Adversarial Networks (GANs): GANs consist of a generator and a discriminator. The generator creates synthetic content (e.g., faces), while the discriminator tries to distinguish between real and fake content. Through adversarial training, GANs can generate realistic deep fake images and videos.
- Variational Autoencoders (VAEs): VAEs are used for face swapping and generation. They work by encoding the input face into a latent space and then decoding it into a new face. VAEs can produce smoother transitions and are often used for face synthesis.
- Autoencoders: Autoencoders are used for dimensionality reduction and data compression. They can be applied to face swapping by encoding the source face, transforming it, and decoding it as the target face.
- Deep Neural Networks (DNNs): Deep neural networks, particularly convolutional neural networks (CNNs), are used in various parts of the deep fake creation process, such as face alignment, feature extraction, and the generation of deep fake content.
- Neural Style Transfer: This technique applies the artistic style of one image to another, allowing for artistic deep fake transformations that mimic famous artists' styles.
- CycleGAN: CycleGAN is a specialized GAN architecture used for unpaired image-to-image translation. It can be applied to style transfer, face swapping, and other creative transformations.
B. Deep Fake Detection Algorithms
- Machine Learning Classifiers: These classifiers are trained on features extracted from images or videos to distinguish between real and manipulated content. Features may include texture analysis, inconsistencies in lighting, and compression artifacts.
- Liveness Detection: Liveness detection algorithms are used to assess whether a face in a video is a live person or a manipulated image. They analyze facial movement, blinking, and other dynamic features.
- Context Analysis: Deep fake detection algorithms consider the context and metadata of the content. Metadata analysis can reveal anomalies or inconsistencies, such as unusual editing timestamps or source information.
- Face Morphing Detection: These algorithms aim to detect manipulated images created by morphing two different faces. They analyze geometric and texture inconsistencies introduced during the manipulation process.
- Neural Network-Based Detection: Deep learning models can be trained to detect deep fake content by learning patterns and artifacts specific to manipulated media. These models often use convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
- Deep Fake Datasets: Large datasets of known deep fake and authentic media are used to train detection models. These datasets help the algorithms learn to differentiate between real and fake content.
- Media Forensics Techniques: Digital forensics methods, such as error level analysis (ELA) and noise analysis, can be applied to identify anomalies in deep fake content.
It's important to note that both deep fake creation and detection are active areas of research, and the algorithms are continually evolving. Researchers are developing more advanced techniques to create better deep fakes and improve detection accuracy. Moreover, the use of these technologies comes with ethical and legal responsibilities, and many organizations are working on guidelines and regulations to address these concerns.
V. LITERATURE SURVEY & EXISTING SYSTEM:
[1]
|
Title |
Tidal-traffic-aware routing and spectrum allocation in elastic optical networks
|
|
Name of Author |
Boyuan Yan; Yongli Zhao; Xiaosong Yu; Wei Wang; Yu Wu; Ying Wang; Jie Zhang |
|
Year of Publishing |
2018 |
|
Details |
With the growing popularity of 5G mobile communications, cloud and fog computing, 4K video streaming, etc., population distribution and migration have increasing influence on traffic distribution in metro elastic optical networks (EONs). Traffic distribution is further diversified according to people's tendency to use network services in different places at different times. |
[2]
|
Title |
GAN for Load Estimation and Traffic-Aware Network Selection for 5G Terminals
|
|
Name of Author |
Changfa Leng; Chungang Yang; Sifan Chen; Qing Wu; Yao Peng
|
|
Year of Publishing |
2022 |
|
Details |
In the face of the user-centric access network architecture adopted by the fifth-generation (5G) mobile communication network terminals, the communication capability of terminals faces significant challenges. In this case, the combination of 5G and artificial intelligence (AI) has become a significant trend to meet the various communication needs of terminal devices. |
[3]
|
Title |
Availability- and Traffic-Aware Placement of Parallelized SFC in Data Center Networks |
|
Name of Author |
Meng Wang; Bo Cheng; Shangguang Wang; Junliang Chen |
|
Year of Publishing |
2021 |
|
Details |
Network Function Virtualization (NFV) brings flexible provisioning and great convenience for enterprises outsource their network functions to the Data Center Networks (DCNs). Network service in NFV is deployed as a Service Function Chain (SFC), which includes an ordered set of Virtual Network Functions (VNFs). However, in one SFC, the SFC delay increases linearly as the length of SFC increases. SFC parallelism can achieve high performance of SFC. |
[4]
|
Title |
An Enhanced Hybrid Glowworm Swarm Optimization Algorithm for Traffic-Aware Vehicular Networks |
|
Name of Author |
Pratima Upadhyay; Venkatadri Marriboina; Shiv Kumar; Sunil Kumar; Mohd Asif Shah |
|
Year of Publishing |
2022 |
|
Details |
The vehicular network has some permanent devices called roadside units and moving devices called On Board Units (OBU). Every vehicle traveling on the network must possess the OBU. Safety and non-safety tidings are broadcasted in vehicular networks. Even vehicular network is derived from MANET and its characters are discriminated against the MANET. |
VI. PROBLEM STATEMENT
Deepfakes, a type of fake video that uses deep learning algorithms to create realistic manipulations of real people’s faces and voices, pose a significant challenge to detection systems. The face transition systems face the problem of large dataset size. The reading, processing and interpretations of massive image dataset take more processing latency.
VII. OBJECTIVES
- The dimensionality reduction through feature mapping is adopted to overcome the problem.
- The proposed algorithm keenly focus on deriving the unique features and analysis of feature mapping for reduced usage of GPU.
VIII. ADVANTAGES
- Synthetic Data Generation: GANs can generate new, synthetic data that resembles some known data distribution, which can be useful for data augmentation, anomaly detection, or creative applications.
- High-quality Results: GANs can produce high-quality, photorealistic results in image synthesis, video synthesis, music synthesis, and other tasks.
- Unsupervised Learning: GANs can be trained without labeled data, making them suitable for unsupervised learning tasks, where labeled data is scarce or difficult to obtain.
- Versatility: GANs can be applied to a wide range of tasks, including image synthesis, text-to-image synthesis, image-to-image translation, anomaly detection, data augmentation, and others.
IX. DISADVANTAGES
- Training Instability: GANs can be difficult to train, with the risk of instability, mode collapse, or failure to converge.
- Computational Cost: GANs can require a lot of computational resources and can be slow to train, especially for high-resolution images or large datasets.
- Overfitting: GANs can overfit to the training data, producing synthetic data that is too similar to the training data and lacking diversity.
- Bias and Fairness: GANs can reflect the biases and unfairness present in the training data, leading to discriminatory or biased synthetic data.
- Interpretability and Accountability: GANs can be opaque and difficult to interpret or explain, making it challenging to ensure accountability, transparency, or fairness in their applications
X. APPLICATIONS
- Entertainment and Film Industry: Deep fake technology is widely used in the entertainment industry for creating special effects, altering actors' appearances, and seamlessly replacing faces in movies and TV shows. It can be used to bring deceased actors back to the screen or transform actors into different characters.
- Video Game Development: In video games, deep fake technology can enhance character customization by allowing players to create realistic avatars that closely resemble themselves.
- Marketing and Advertising: Marketers can use deep fake technology to create personalized ads and promotions, making products more relatable to the target audience by incorporating their own faces into the content.
- Training and Simulation: Military and law enforcement agencies use deep fake technology for training exercises, creating realistic scenarios with lifelike avatars and adversaries.
- Dubbing and Localization: Deep fakes can be used to seamlessly replace the faces and voices of actors to adapt movies and shows to different languages and cultures while preserving the original lip-syncing.
- Education: Deep fake technology can be applied in educational content creation to generate realistic, interactive simulations for medical training, language learning, or history lessons.
XI. SYSTEM OVERVIEW
Deepfake videos are videos where the features of a person are replaced with the features of another person. Videos can be manipulated using powerful Deep Learning techniques. This technology may be used maliciously as a means of misinformation, manipulation, and persuasion. There are currently not many solutions to identify products of Deepfake technology, although there is significant research being conducted to tackle this problem. One often researched deep learning technology is the Generative Adversarial Network (GAN). These networks preferred to develop or generate the non-existing patterns or creations. In this work, we're working on the development of first order motion model for image animation using Dense motion network. Using key point detectors as a baseline, we train a GAN and extract the facial landmarks from the driving video and building the embedding model to create the synthesized video using the dedicated module to prepare the Deepfakes.
Finally, we propose a model to boost the efficacy of a group of GAN generators using dense motion networks. Our results generate the augmented animation video using the sequel driving combination of driving video with source image. This project can be used in many area's like multiplying the dataset counts with minimum number source, CG platforms where gaming industry & animation industry using to create real-time backgrounds & characters, Cloth translations, video prediction, 3D object generation, etc.,
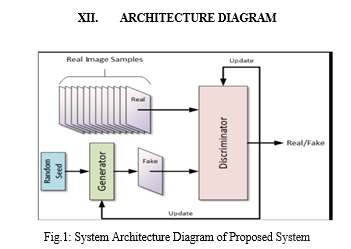
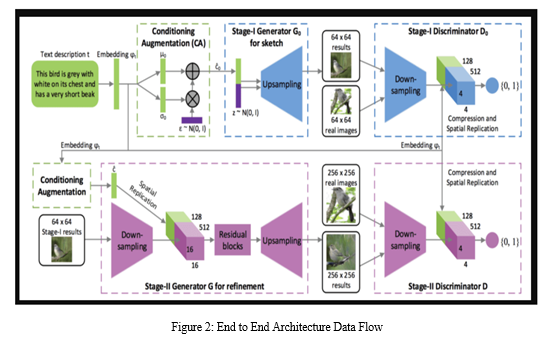
A. Development Flow
- Collecting the driving videos source image datasets.
- Setting up the image animation part to display the comparisons.
- Creating the generator model .
- Creating key point detector model.
- Performing image animation.
- Testing real-time image animation using Deep GAN.
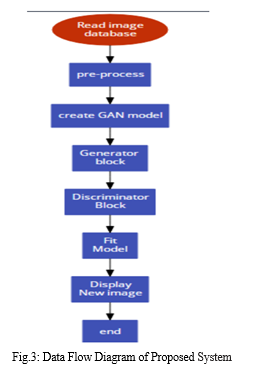
XIII. DATA FLOW DIAGRAM
It appears that you have provided a list of tasks related to creating a Deepfake technology for image animation. Here is a brief overview of what each step involves:
- Collecting the Driving Videos Source Image Datasets: This involves gathering a set of driving videos that will be used to train the Deepfake technology. The source image dataset will consist of images that will be used to generate the fake videos.
- Setting up the Image Animation part to Display the Comparisons: This step involves setting up the infrastructure to display the original and generated videos side by side to enable comparison and evaluation.
- Creating the Generator Model: The generator model is the heart of a Deepfake technology. It is responsible for generating the fake videos using the source image dataset and driving videos.
- Creating Key Point Detector Model: This is another critical component of the Deepfake technology. The key point detector model identifies the facial landmarks and other critical features in the source images and driving videos that will be used to generate the fake videos.
- Performing Image Animation: Once the generator and key point detector models are trained, the image animation process can be performed. This involves generating a fake video by using the source image dataset and driving videos.
- Testing real-time Image Animation using Deepfake Technology: This step involves testing the Deepfake technology in real-time scenarios to evaluate its accuracy and effectiveness.
It is essential to note that the creation and use of Deepfake technology can be highly controversial and can lead to serious ethical and legal concerns. It is crucial to use this technology responsibly and ethically to avoid causing harm or damage to individuals or society.
A. Software
We are using “PYTHON “coding for our implementation. This language gave high accuracy on face detection. Thus, we have two main functions on that. First one for detecting the eye blinking and the second one is for reading the blinking. This calculation invoked into the complete set of 1programs. The camera system continuously monitors and sends the video file to the programming. The function which is for getting the data to observe it and the blinking detection function reads the file if it detects then it completely makes reading with that corresponding function and the signals are send to the alerting mechanism.
B. Google Collab
Google Colaboratory, or Google Colab for short, is a free online platform for running Jupyter Notebook-style Python code. It allows users to write, run, and share Python code using a web browser. Google Colab provides a virtual machine that includes many of the same libraries and tools that are commonly used in data science, such as TensorFlow, PyTorch, and scikit-learn, so that users do not need to install these tools on their local machines.
Conclusion
Face progress utilizing Generative Ill-disposed Organizations (GANs) is a technique where a model is prepared to become familiar with the planning between two particular pictures of a face. The model is able to produce a series of intermediate images that gradually change one face into the other because of this. In this work, we are developing a first-order motion model for image animation using a dense motion network for the proposed model. We train a GAN, extract facial landmarks from the driving video, and build the embedding model to create the synthesized video with the dedicated module for preparing the Deepfakes using key point detectors as a baseline. Last but not least, we offer a model that makes use of dense motion networks to improve the efficiency of a group of GAN generators. Our outcomes produce the increased activity video utilizing the continuation driving mix of driving video with source picture. The development of deepfake GAN models with GAN architecture has shown promising results in the creation of realistic face transitions. Future research should explore the potential applications of this technology while also addressing the ethical concerns associated with its use.
References
[1] C. Leng, C. Yang, S. Chen, Q. Wu and Y. Peng, ”GAN for Load Estimation and Traffic-Aware Network Selection for 5G Terminals,” in IEEE Internet of Things Journal, vol. 9, no. 17, pp. 16353-16362, 1 Sept.1, 2022, doi: 10.1109/JIOT.2022.3152729. [2] M. Wang, B. Cheng, S. Wang and J. Chen, ”Availability- and Traffic Aware Placement of Parallelized SFC in Data Center Networks,” in IEEE Transactions on Network and Service Management, vol. 18, no. 1, pp. 182-194, March 2021, doi: 10.1109/TNSM.2021.3051903. [3] Y.-I. Tian, T. Kanade, and J. F. Cohn, “Recognizing action units for facial expression analysis,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 23, no. 2, pp. 97–115, Feb. 2001 [4] G. Zen, L. Porzi, E. Sangineto, E. Ricci, and N. Sebe, “Learning personalized models for facial expression analysis and gesture recognition,” IEEETrans. Multimedia, vol. 18, no. 4, pp. 775–788, Apr. 2016. [5] M. Aboelwafa, G. Alsuhli, K. Banawan, and K. G. Seddik, “Selfoptimization of cellular networks using deep reinforcement learning with hybrid action space,” in Proc. IEEE 19th Annu. Consum. Commun. Netw. Conf. (CCNC), 2022, pp. 223–229. [6] C. Zhang, Y. Ueng, C. Studer, and A. Burg, “Artificial intelligence for 5G and beyond 5G: Implementations, algorithms, and optimizations,” IEEE J. Emerg. Sel. Topics Circuits Syst., vol. 10, no. 2, pp. 149–163, Jun. 2020. [7] Y. Dai, D. Xu, K. Zhang, Y. Lu, S. Maharjan, and Y. Zhang, “Deep reinforcement learning for edge computing and resource allocation in 5G beyond,” in Proc. IEEE 19th Int. Conf. Commun. Technol. (ICCT), 2019, pp. 866–870. [8] B. Yan et al., ”Tidal-traffic-aware routing and spectrum allocation in elastic optical networks,” in Journal of Optical Communications and Networking, vol. 10, no. 11, pp. 832-842, Nov. 2018, doi: 10.1364/JOCN.10.000832. [9] Q. Liu, G. Chuai, W. Gao, and K. Zhang, “Load-aware user-centric virtual cell design in ultra-dense network,” in Proc. IEEE Conf. Comput. Commun. Workshops (INFOCOM WKSHPS), 2017, pp. 619–624. [10] J. Qiu, L. Du, Y. Chen, Z. Tian, X. Du, and M. Guizani, “Artificial intelligence security in 5G networks: Adversarial examples for estimating a travel time task,” IEEE Veh. Technol. Mag., vol. 15, no. 3, pp. 95–100, Sep. 2020. [11] I. Makki, R. Younes, C. Francis, T. Bianchi and M. Zucchetti, ”A survey of landmine detection using hyperspectral imaging”, ISPRS J. Photogramm. Remote Sens., vol. 124, pp. 40-53, Feb. 2017 [12] H. Fu et al., ”Evaluation of retinal image quality assessment networks in different color-spaces”, Proc. MICCAI, pp. 48-56, 2019. [13] S. C. Wong, A. Gatt, V. Stamatescu and M. D. McDonnell, ”Understanding data augmentation for classification: When to warp?”, Pro Int. Conf. Digit. Image Comput. Techn. Appl. (DICTA), pp. 1-6, Nov. 2016. [14] V. Rengarajan, A. N. Rajagopalan, R. Aravind and G. Seetharaman, ”Image registration and change detection under rolling shutter motion blur”, IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 10, pp. 1959-1972, Oct. 2017. [15] Armato, S.G., et al.: The lung image database consortium (LIDC) and imagedatabase resource initiative (IDRI): a completed reference database of lung noduleson CT scans. Med. Phys. 38(2), 915–931 (2018)
Copyright
Copyright © 2023 Prajakta Malgunde, Kunal Kulkarni, Kundan Chaudhari, Rohit Gavit, Prof. Varsha Gosavi. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET56455
Publish Date : 2023-11-02
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online