

Ijraset Journal For Research in Applied Science and Engineering Technology
Databases In The 21’st Century
Authors: Sujay Saundatti
DOI Link: https://doi.org/10.22214/ijraset.2022.43982
Certificate: View Certificate
Abstract
NoSQL databases are the 21’st century databases created to defeat the disadvantages of RDBMS. The objective of NoSQL is to give versatility, accessibility and meet different necessities of distributed computing.The main motivations for NoSQL databases systems are achieving scalability and fail over needs. In the vast majority of the NoSQL data set frameworks, information is parceled and repeated across numerous hubs. Innately, the majority of them utilize either Google\'s MapReduce or Hadoop Distributed File System or Hadoop MapReduce for information assortment. Cassandra, HBase and MongoDB are for the most part utilized and they can be named as the agent of NoSQL world.
Introduction
I. INTRODUCTION
NoSQL, for ?Not Only SQL, alludes to data sets which are not assembled on tables, and by and large don't involve SQL for information control [1]. NoSQL databases are helpful while working with a gigantic amount of information when the information's inclination doesn't need a sql model. NoSQL frameworks are conveyed, non-social data sets intended for huge scope information capacity and for greatly equal information handling across an enormous number of item servers. They additionally use non-SQL dialects and components to interface with information (however some new element APIs that convert SQL inquiries to the framework 's local question language or apparatus). NoSQL data set frameworks have emerged due to needs of significant Internet organizations, like Google, Amazon, and Facebook; which had difficulties in managing enormous amounts of information with ordinary RDBMS arrangements couldn't adapt [2]. They can uphold numerous exercises, including exploratory and prescient examination, ETL-style information change, and non strategic OLTP (for instance, overseeing long-length or between association exchanges). Initially propelled by Web 2.0 applications, these frameworks are intended to scale to thousands or millions of clients doing refreshes as well as peruses, as opposed to customary DBMSs and information distribution centers. NoSQL frameworks are social data sets intended to give ACID (Atomicity, Consistency, Isolation, Durability) - consistent, ongoing OLTP (Online Transaction Processing) and ordinary SQL-based OLAP in Big Data conditions. These frameworks get through customary RDBMS execution limits by utilizing NoSQL-style highlights, for example, segment situated information capacity and dispersed structures, or by utilizing advances like in-memory handling, symmetric multiprocessing (SMP) or Massively equal Processing (MPP)
II. BACKGROUND
Of the various information models, the relational model has been ruling since the 80s, with executions like Oracle data sets, MySQL and Microsoft SQL Servers otherwise called Relational Database Management System (RDBMS). Recently, be that as it may, in a rising number of cases the utilization of relational data sets prompts issues both in light of shortfalls and issues in the demonstrating of information and imperatives of even adaptability north of a few servers and a lot of information. These two are the trends that have been dominating software engineering since the last twenty years:
- With the rise of the internet and social media the rate at which data is being created is enormous and thus massive companies are relying on NoSQL databases for handling these large volumes of data .
- The rising interdependency and intricacy of information advanced quickly by the Internet, Web2.0, interpersonal organizations and open and normalized admittance to information sources from an enormous number of various frameworks
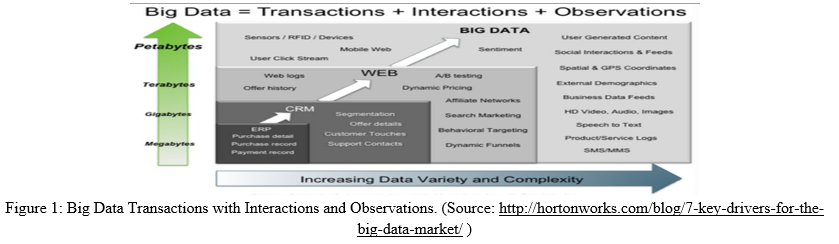
Associations that gather a lot of unstructured information are progressively going to non-relational data sets, presently called NoSQL data sets. NoSQL databases excel around insightful handling of huge scope datasets, which offering expanded adaptability over item equipment Computational and stockpiling necessities of utilizations, for example, for Big Data Analytics, Business Intelligence and person to person communication over peta-byte datasets have pushed SQL-like concentrated data sets as far as possible. This prompted the advancement of on a level plane versatile, circulated non-social information stores, called No-SQL data sets, like Google's Bigtable and its open-source execution HBase and Facebook's Cassandra. The rise of appropriated key-esteem stores, like Cassandra and Voldemort, demonstrates the proficiency and cost viability of their methodologies. The primary restrictions with RDBMS are that it is difficult to scale with Data warehousing, Grid, Web 2.0
III. CHARACTERISTICS OF NOSQL DATABASES
In order to guarantee the integrity of data, most of the classical database systems are based on transactions. This ensures consistency of data in all situations of data management. These transactional characteristics are also known as ACID (Atomicity, Consistency, Isolation, and Durability) . However, scaling out of ACID-compliant systems has shown to be a problem. Conflicts are arising between the different aspects of high availability in distributed systems that are not fully solvable - known as the CAP- theorem :
- Strong Consistency: All clients see the same version of the data, even on updates to the dataset - e. g. by means of the two-phase commit protocol (XA transactions), and ACID,
- High Availability: All clients can always find at least one copy of the requested data, even if some of the machines in a cluster are down,
- Partition-tolerance: The total system keeps its characteristic even when being deployed on different servers, transparent to the client. The CAP-Theorem postulates that only two of the three different aspects of scaling out are can be achieved fully at the same time
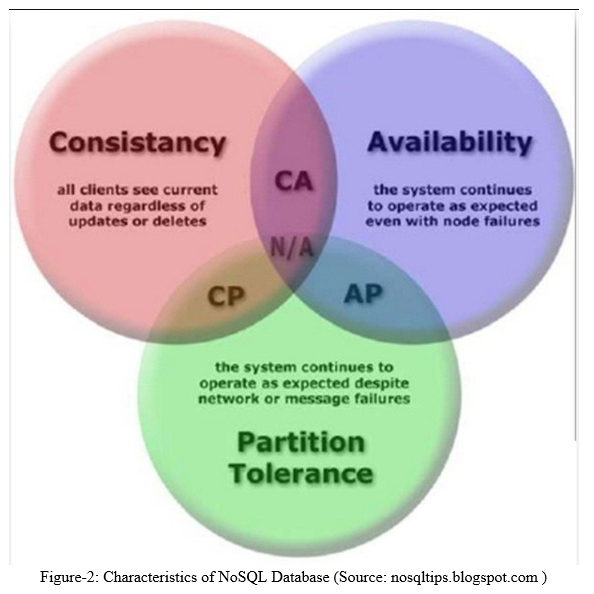
A significant number of the NOSQL data sets most importantly have relaxed the necessities on Consistency to accomplish better Availability and Partitioning. This brought about frameworks know as BASE (Basically Available, Soft-state, Eventually reliable). These have no exchanges in the traditional sense and present limitations on the information model to empower better parcel plans. Han, J., Haihong, E., Le, G., and Du, J. (2011) orders NoSQL information bases as per the CAP hypothesis. Tudorica, B. G., and Bucur, C. (2011), analyzes utilizing numerous standards between a few NoSQL data sets. Essential Uses of NoSQL Database Large-scale information handling (equal handling over appropriated frameworks); Embedded IR (fundamental machine-to-machine data gaze upward and recovery); (3) Exploratory examination on semi-organized information (master level); (4) Large volume information capacity (unstructured, semi-organized, little bundle organized). Appropriately, they give somewhat cheap, exceptionally versatile capacity for high volume, little parcel authentic information like logs, call-information records, meter readings, and ticker
snapshots (i.e., ?big bit bucket? capacity), and for clumsy semi-organized or unstructured information (email chronicles, xml records, reports, and so on.). Their appropriated structure likewise makes them ideal for enormous group information handling (accumulating, sifting, arranging, algorithmic crunching (factual or automatic), and so on.). They are great too for machine-to-machine information recovery and trade, and for handling high-volume exchanges, as long as ACID limitations can be loose, or possibly implemented at the application level as opposed to inside the DMS. At long last, these frameworks are excellent exploratory examination against semi-organized or half breed information, however to coax out knowledge, the scientist generally should be talented analyst working pair with a gifted program
IV. CLASSIFICATION OF NOSQL DATABASES
A. Key-Value stores
Typically, these DMS store items as alpha-numeric identifiers (keys) and associated values in simple, standalone tables (referred to as ?hash tables?). The values may be simple text strings or more complex lists and sets. Data searches can usually only be performed against keys, not values, and are limited to exact matches

Primary Use
The simplicity of Key-Value Stores makes them ideally suited to lightning-fast, highly scalable retrieval of the values needed for application tasks like managing user profiles or sessions or retrieving product names. This is why Amazon makes extensive use of its own KV system, Dynamo, in its shopping cart. Dynamo is a highly available key-value storage system that some of Amazon ‘s core services use to provide highly available and scalable distributed data store.
Examples: Key-Value Stores- Dynamo (Amazon); Voldemort (LinkedIn); Redis;
BerkeleyDB; Riak
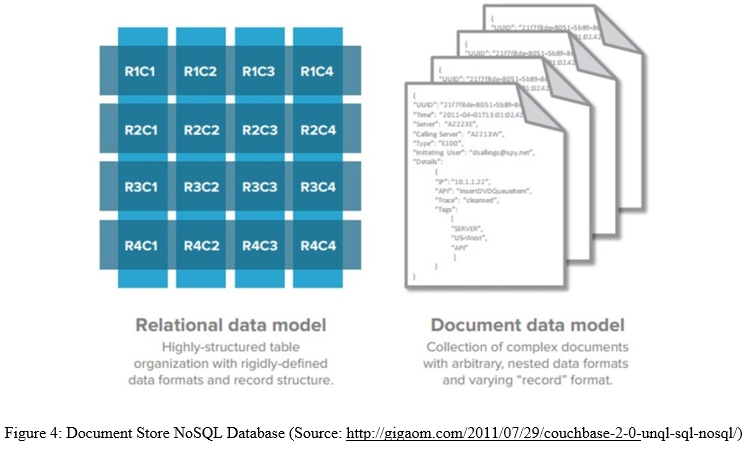
B. Document Databases
Inspired by Lotus Notes, document databases were, as their name implies, designed to manage and store documents. These documents are encoded in a standard data exchange format such as XML, JSON (Javascript Option Notation) or BSON (Binary JSON). Unlike the simple key-value stores described above, the value column in document databases contains semi-structured data – specifically attribute name/value pairs. A single column can house hundreds of such attributes, and the number and type of attributes recorded can vary from row to row. Also, unlike simple key-value stores, both keys and values are fully searchable in document databases
V. ADOPTION OF NOSQL DATABASES
The acronym NoSQL was coined in 1998. Many people think NoSQL is derogatory term created to poke at SQL. In reality, the term means Not Only SQL. The idea is that both technologies can coexist and each has its place. The NoSQL movement has been in the news in the past few years as many of the Web 2.0 leaders have adopted NoSQL technology.
Companies like Facebook, Twitter, Digg, Amazon, LinkedIn and Google all use NoSQL in one way or another. Couchbase Survey was conducted in the year 2012. Key data points from the Couchbase NoSQL survey include:
- Nearly half of the more than 1,300 respondents indicated they have funded NoSQL projects in the first half of this year. In companies with more than 250 developers, nearly 70% will fund NoSQL projects over the course of 2012.
- 49% cited rigid schemas as the primary driver for their migration from relational to NoSQL database technology. Lack of scalability and high latency/low performance also ranked highly among the reasons given for migrating to NoSQL.
- 40% overall say that NoSQL is very important or critical to their daily operations, with another 37% indicating it is becoming more important.
Conclusion
Computational and storage requirements of applications such as for Big Data Analytics, Business Intelligence and social networking over peta-byte datasets have pushed sql-like centralized databases to their limits [8]. This led to the development of horizontally scalable, distributed non-relational No-SQL databases. We speculate some of the major (primarily) uses of NoSQL Databeses: Large-scale data processing (parallel processing over distributed systems); Embedded IR (basic machine-to-machine information look-up & retrieval); Exploratory analytics on semi-structured data (expert level); Large volume data storage (unstructured, semi-structured, small-packet structured) NoSQL is a large and expanding field, for the purposes of this paper - characteristics (features and benefits of NoSQL databases); classification (categories four on their features); comparison and evaluation (with a matrix on basis of few attributes- design, integrity, indexing, distribution, system) of different types of NoSQL databases; and current state of adoption of NoSQL databases. This study reports motivation to provide an independent understanding of the strengths and weaknesses of various NoSQL database approaches to supporting applications that process huge volumes of data; as well as to provide a global overview of this non-relational NoSQL databases
References
[1] https://en.wikipedia.org/wiki/NoSQL [2] Hecht, R., & Jablonski, S. (2011, December). NoSQL evaluation: A use case oriented survey. In Cloud and Service Computing (CSC), 2011 International Conference on (pp. 336-341).IEEE. [3] Use relational DBMS, N. (2009). Saying good-bye to DBMSs, designing effective interfaces. Communications of the ACM, 52(9) [4] Leavitt, N. (2010). Will NoSQL databases live up to their promise?. Computer,43(2), 12-14.
Copyright
Copyright © 2022 Sujay Saundatti. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43982
Publish Date : 2022-06-08
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online