

Ijraset Journal For Research in Applied Science and Engineering Technology
Deep Neural Network-based Knee Osteoarthritis Grading Using X-Rays
Authors: Zainab Mushtaq Wani, Dr. Satish Saini
DOI Link: https://doi.org/10.22214/ijraset.2022.41757
Certificate: View Certificate
Abstract
Osteoarthritis (OA) of the knee is a common cause of activity restriction and physical impairment in elderly people. Early identification and treatment can help delay the progression of OA. Physicians\' visual examination rating is objective, varies across interpretation, and is heavily reliant on their expertise. We use two machine learning approaches (CNN) in this article to automatically estimate the severity of knee OA as described by the Kallgren- Lawrence (KL) grading system. To begin, we use a customized one-stage YOLOv2 network to recognize kneecap based on the size of knee joints scattered in X-ray pictures with poor contrast. Second, we use a new customizable arbitrary loss to fine-tune its most famous Cnn architectures, spanning ResNet, VGG, and DenseNet versions, as well as InceptionV3, to categorize the collected knee joint pictures. To be more explicit, we provide a stronger penalty to misrepresentation with a greater difference between the predicted and actual KL grade, driven by the ordinal character of the knee KL grading assignment. The Osteoarthritis Institute (OAI) collection is used to evaluate the basic X-ray pictures. Under the Jaccard index criterion of 0.75, we acquire a mean Jaccard index of 0.858 and a recall of 92.2 percent for knee joint identification. The fine-tuned VGG-19 model with the provided linear loss achieves the greatest generalization ability of 96.7 percent and mean standard deviation (MAE) of 0.344 on the knee KL grading task. Both knee joint identification and knee KL assessment are at the cutting edge of technology
Introduction
I. Introduction
Knee osteoarthritis (OA) is the most frequent osteoarthritis ( oa in older persons and the leading cause of activity restriction and medical problem [1]. Radiological confirmation of OA in at least one joint can be seen in more than half of elderly Americans over 65 [2]. By 2030, it is anticipated that more than 20% of US inhabitants would have reached a level of 65 and will be at risk for OA [3]. Knee OA pain and other indications have a significant impact on the elderly's quality of life. Worse still, no therapy can prevent the destructive structural changes that cause knee OA to develop. Early identification and treatment, on the other hand, can assist the elderly delay the course of OA and enhance their quality of life. Joint space narrowing (JSN), subchondral sclerosis, and osteophyte production are all symptoms of knee OA. The 3D architecture of knee joints can be reflected by MRI. However, MRI is only accessible at big medical facilities, and the cost renders it unsuitable for diagnosing knee OA on a routine basis. The gold standard for knee OA screening is X-ray, which offers the advantages of safety, cost-effectiveness, and wide accessibility. The Kellgren and Lawrence (KL) grading system [4] is the most widely used knee OA severity grading system, having been recognised by WHO in 1961. The KL system divides knee OA severity into five grades, ranging from 0 to 4. Figure 1 depicts the sample and criterion for each grade.
Physicians often examine a digitized knee X-ray picture and assign KL ratings to both knee joints in a matter of seconds. The diagnosis correctness is heavily reliant on the experience and prudence of physicians. Furthermore, the KL grading criterion is quite unclear. For KL grade 1, for example, potential osteophytic lipping and questionable JSN are utilised as criteria. When evaluating the same knee joint at various times, the same physician may assign different KL ratings. Culvenor et al. [5] found that the intra-rater reliability of the KL ranged from 0.67 to 0.73. Because of the unclear criterion, we believe that the low reliability of physicians' grading is due to misclassification of the knee joint's KL grade to neighbouring grades. In clinical diagnosis, misclassifying a knee joint's grade to a local grade (e.g., grade 1 to grade 2) is significantly less problematic than reclassifying the grade to a distant grade (e.g., grade 1 to grade 2). (e.g., grade 1 to grade 4). As a result, using grading accuracy as the sole criteria for evaluation is insufficient. To overcome this problem, we adopt mean absolute error (MAE) as a new measure for evaluating knee KL grade categorization, inspired by MAE's usage as an evaluation metric in age estimate [6].
Because of its great incidence, there is a pressing need to reliably diagnose the existence of knee OA and assess its severity. Fully automated knee severity grading can offer objective, repeatable predictions and will not cause weariness after lengthy periods of diagnosis. Knee joint recognition and classification into one of the five KL classes are the two key phases in predicting knee OA severity from a raw screening knee X-ray picture.
Deep learning-based algorithms provide state-of-the-art experience in a range of vision tasks, including picture classifications, object recognition, and segmentation [12], thanks to rapid improvements in computational capabilities and massive accessible datasets. Deep learning has been more popular in medical image analysis in the last five years, such as cell recognition and delineation, mitosis detection, white matter lesion identification, and retinal blood vessel classification. Several research [8,] have used deep learning-based approaches to analyse knee OA. The performance, though, was lacking. For KL grading, detected knee joints (Red) are extended by a certain ratio (1.3 in this case) to encompass a broad knee joint area (Dashed blue). Given the ordinal nature of the KL grading assignment, a better loss function can help in knee KL grading.
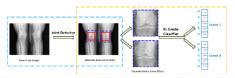
Figure 1 The pipeline of knee joint severity grading, which includes knee joint detection and knee KL grade classification
II. OBJECTIVES
- Modeling a machine learning architecture and conducting comprehensive experiments to illustrate the impact of texture characteristics on diagnostic performance.
- Texture characteristics from the patellar area of lateral view radiographs (X-rays) were investigated to see if they might be utilized to identify knees with definite radiological PFOA from healthy knee radiographs.
- To compare the results of hand-crafted features, deep convolutional neural network features, and machine learning features
- Finally, we present a stacked model that combines predictions of patellar texture and clinical features with a second-level machine learning model -
III. Literature review
One of the most frequently diagnosed musculoskeletal illnesses is osteoarthritis (OA). Nearly 5% of the world's population is affected by this disease [1]. The femoral, tibial, and patella joint capsules are the most often affected by OA, which is defined by irreversible degradation of the articular cartilage at the ends of the bones [2]. Osteoarthritis (OA) is a condition that affects the whole knee joint and progresses over time. Knee OA is a disorder that is caused by both mechanical and metabolic abnormalities. Aging, obesity [3,] and past knee injuries [4] are all known risk factors for OA. OA produces pain, which inhibits one's ability to function and lowers one's quality of life. The harm to the 0e joints in OA is permanent, and the only therapy is total knee replacements (TKR), which is costly and has a limited life expectancy, especially in obese people [5]. As a result, early identification of knee OA is critical for initiating treatment such as weight loss and exercise, which has been shown to be successful in slowing the course of knee OA and postponing TKR [3, 6]. Kellgren–Lawrence grading, which assesses the changes seen on X-ray plain radiography pictures, is the most used radiographic grading scheme for OA. However, since the bony alterations only occur in advanced situations, this strategy creates a delay in OA diagnosis. Other scanners, such as neuroimaging, can use OA soft tissue signs such cartilage and knee degradation, as well as bony and cancellous bone curvature, to detect the development of knee OA [1].
Norman et al. [4] use 2D U-Net to segment six sub compartments of the knee, including articular condyle and the membrane. This study includes both OA patients and non-OA patients. Strong DSC has been observed in this model, particularly on the 3D-DESS image dataset, where all sub compartments had values between 0.753 and 0.878. The 0e automatic cartilage segmentation model has a computational speed of 5 seconds on average. Si et al. [7] opted to utilise 2D U-Net to segment the bones and articular cartilages of the knee from MR images, which are the femur, tibia, kneecap, and each of their associated hyaline cartilage, similar to Norman et al. [14].. The cartilage thickness in 14 anatomical areas is determined by segmenting 0e cartilages. The cartilage compartment 0e DSCs obtained in this investigation vary from 0.76 to 0.87. Wirth et al. [11] employed 2D U-Net to section comes as a great cartilage and achieved high DSC with both axial FLASH and coronal DESS scans, demonstrating cartilage experience and knowledge temporal test-retest repeatability. Only participants without OA would be included in the research by Si et al. [14] and Wirth et al. [13]. To address the lack of computing requirements for 3D CNNs for 3D sector feature extraction, such as memory and practice time,
IV. Methodology
A.. Dataset and Pre-processing
The Rheumatology Initiative 1 (OAI) is a multi-center, longitudinal, prospective observational research of knee osteoarthritis (OA) aimed at identifying biomarkers for OA development and progression [27]. Knee X-ray images were utilized for assessment. This program has 4796 members ranging in age from 45 to 79 years old. To assess our suggested technique, we used knee bilateral PA fixed flexion X-ray images from the baseline group. Because OAI is a multi-centre research, the physical resolution and dimension of these baseline cohort knee X-ray pictures are not constant. Prior to the measurement of OA in the knee, pre-processing is required. To begin, all raw X-ray pictures are scaled to the same physical resolution. The figure of 0.14mm/pixel was chosen to be near to the median of all picture’s physical resolutions. We next crop the centre section from the scaled video with a height of 2048 pixels and a height of 2560 pixels to guarantee that all edited photos are just the same size. We only store X-ray photos with accessible KL classes on both leg joints since we can anticipate KL grades of both left and right leg joints from a single X-ray image.
4130 X-ray pictures with 8260 hips and knees remains after also before the and sorting. With a 7: 1: 2 ratios, we mainly split all knee X-ray pictures into instruction, validity, and testing sets. To maintain generally constant grade distribution throughout training, validate, and testing dataset, this separation is done grade-by-grade based on the KL level of the left knee joint in a knee X-ray picture. After trying to split, the hip and knee validation set comprises 828 X-ray pictures and 1656 joints, including 639 grade 0 knee joints, 296 grade 1 knee joints, 447 grade 2 knee joints, 223 grade 3 knee joints, and 51 grade 4 knee joints.
We use a marking system to explicitly mark knee joints under the supervision of surgeons because there is no ground truth for lower extremity identification. We mark the knees bone area in a stringent manner, which mostly includes the interior part of the knee joint, since we want to use this annotating for joint space segments to estimate joint space width in our future consideration (e.g. the red bounding box in Figure 2). For the knee KL grading, we would extend the labelled knee joint by a particular ratio (1.3 was chosen) (e.g. the dashed blue bounding box in Figure 2). The documented knee joints may be utilized for both knee joint identification and KL grade assessment in this method.
B. Knee Joint Detection
R-CNN series [8, 9, 10], YOLO series [15], SSD [1], and more generic CNN detection designs are accessible. Varying shapes and angles are major issues in natural object identification. Using the Generative Model, a faster R-CNN would create 2000 region proposals with varying aspect ratios (RPN). Default bounding boxes with varied aspect ratios are utilized as object suggestions in SSD at each point of the feature map in distinct activation functions. Due to the general following factors, the size of OA participants' knee joints is significantly less diverse when they are detected. To begin, all X-ray pictures of the knee have been pre-processed to have the identical chemical capabilities. Finally, the registrants are generally senior citizens. As people's physiques differ, the size of their knee joints differs only little.
Setting the starting knee joint size to be near to the real knee joint size is one way to customize YOLOv2 for knee joint detection. Clustering on all available training knee joints will yield the default beginning knee size. Object detection is structured as a regression problem in the YOLOv2 detection architecture, which refines the height, width, centre coordinates, and confidence score for each of the predefined bounding boxes situated in all division grid centres. When the initial bounding box is close to the true bounding box, fitting the model becomes easy. YOLOv2 is a one-stage detector that may be tuned from start to finish and does not need the production of explicit region proposals. In essence, the grid-by-grid method of generating knee joint bounding box suggestions is the same as the sliding window method. To find knee joints, the picture is evaluated in all conceivable areas. The CNN network has the benefit of calculating all of the characteristics of all suggestions in one forward operation.
YOLOv2 enhances YOLO in a number of ways. The following enhancements are used in this knee joint detection: 1) Batch normalization is used to regulate the model and aid in training divergence. 2) To settle the detection, a new direct location prediction is used, which constrains the object center to be within the specified grid cells. 3) K-means clustering is utilized to improve bounding box initialization. To be clear, we only utilize YOLOv2 for detection and do not use it for categorization. When compared to independently training knee detection and KL grade classification models, an integrated knee joint identification and KL grading mediation a more elegant structure. When integrative instruction is used, however, investigations demonstrate that performance and classification accuracy suffer significantly. In medicinal uses, such as this study's knee analysis, we prioritize prediction accuracy over model elegance.
C. Adjustable Ordinal Loss
KL grade prediction is essentially a naive bayesian issue. Because it is more dangerous to confuse two distant grades (e.g., forecasting grade 0 to grade 4) than it is to confuse two close grades (e.g., predicting grade 0 to grade 1). As the default loss in a deep learning-based classification model for object classification, the cross-entropy loss treats all classifications equally. It does not take into account the degree of similarity between distinct groups. In a CNN classifiers, the SoftMax layer would output odds [p0, p1, pn1]T for n subcategories. We anticipate the output confidence interval for a picture with grade m to satisfy the required two features: 1) pm should be just as near to 1.0 as feasible; 2) for k 0,, n 1 m, pk should be even less if k m is bigger. Only the first characteristic is satisfied by the cross-entropy. To achieve these two requirements, we suggest a novel ordinal loss.
To represent the penalty weights between the expected and real grades, we first build an adjustable ordinal matrix W. In the knee KL scoring task, W is a n n complex number, where wi,j W is the penalty cost of guessing grade j to grade I where I j 0, 1,..., n 1 and n = 5. The customizable ordinal matrix may be seen in Figure 3 at the bottom left. The punishment vector of grade m is represented by w:m in this style. We set the penalty weight for each grade to be 1 for itself and greater for the remainder grades if they are far away. The suggested canonical loss is categorized as follows, based on this ordinal array and the softmax layer's output likelihood of occurrence:
qi = pi if I /= m, else qi = 1 pi, where m is the real KL grade of the input picture. To minimize loss in Equation 1, pm must be near to 1.0, and remote grade must have an even lower probability due to its high penalty weight.
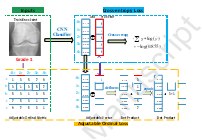
Figure 2 Demo of the proposed ordinal loss calculation process and a comparison with the cross-entropy loss.
The cross-entropy loss optimization is shown in the top right corner, which aims to push the probability of the ground truth category to 1.0 while ignoring the other categories. The suggested ordinal loss computation is shown in the bottom right corner. It uses a bigger penalty weight to try to push the probability of ground truth to 1.0 and the probabilities of distant grades to be even less. Figure 3 displays a demonstration of the suggested ordinal loss computing procedure and a comparison to the cross-entropy loss. W can be changed as a non-diagonal element in the penalty matrix. The penalty matrix is referred to as an adjustable ordinal matrix, and the loss is referred to as an adjustable ordinal loss. Because of its superior performance, the square of the suggested ordinal loss is employed in the actual CNN classifier fine-tuning procedure.
D. CNN Classifiers in KL Grading
Several common CNN classification architectures have emerged during the last five years as deep learning has progressed. ResNet [32] has been shown to be easier to tune and to perform better on recognizing tasks in terms of universality. VGG networks [33] are extremely basic and elegant, consisting of several 3 3 kernel-sized filters that are sequentially applied. Skin cancer [35], diabetic retinopathy detection [36], and other medical classification tasks employ InceptionV3 [34]. DenseNet [37], the most recent version, is intended to improve feature spread and increase feature reuse. On four intense competition object identification benchmark tests, DenseNet outperforms earlier network architectures in classification (CIFAR-10, CIFAR-100, SVHN, and ImageNet).
In this article, we use the knee KL grading assignment to fine-tune all of these prominent CNN classification networks in order to discover the optimal CNN model for the knee KL grading. Furthermore, we would evaluate the actual ordinal loss against the cross-entropy loss on numerous CNN models with varied architectures to see how well the suggested loss generalizes.
V. System architecture
A. Machine Learning
Contact with the environment can lead to the acquisition or modification of knowledge and behavior. This ability exists in even the smallest of organisms and plants [5]. To learn, one must have the necessary knowledge, experience, training, or the capacity to analyze newly obtained information in order to organize it in a more general sense or infer additional knowledge.
Some of the elements associated with learning have been discovered since the advent of psychology, information psychology, and neurobiology in the last century.
This is a terrific example of bend research, as well as one of the most intriguing challenges in computer science since technology was introduced. Machine intelligence and computation neuroscience are examples of new disciplines he pioneered. Machine learning is based on the study of learning computational modelling.
Since the beginning of machine learning and data mining, humans am unable to tackle a number of problems, particularly in the field of optimizations. Contrary to popular belief, computers struggle to tackle many problems that are straightforward for humans to solve, such as categorizing or recognizing objects in a photograph. If you're asking why this happens, it's because none of these concerns are officially addressed. It's quite impossible to design a machine-readable algorithm that can recognize features in an image. This may be accomplished by training a computer to recognize familiar items in the same manner as children learn to recognize them in infancy. In general, this topic aims to provide robots the capacity to learn from data without being training data. "A computer trains from experienced E with respect to a class of tasks T and performances was Therefore if its t, as judged by quality measurement P, improves with experience E" [6]. This model stresses the need of evaluation in addition to providing a formal description of learning algorithms.
B. Machine learning tasks and applications
The training set, during which the model is built from the input, and the test phase, during which the model's success is measured, are the two phases of most learning models. Machine learning, according to the definitions in section 1.1, is heavily reliant on data to work. Data may be organized in a variety of ways, from integers to sequences. Each collection contains three distinct datasets that are commonly grouped together in a single collection. [7]:
- Training set: includes the model's training data.
- Test set: It includes objects that would not be included in training phase and is used to evaluate the model's performance after it has been trained.
- Validation set: By saving the data, it may be utilized to validate and tune hyper-parameters. The steps to implement often has more data than the other two sets. As a rule, 60% of the data is allocated to the training set, while 20% and 20% are allocated to the test and validating sets, correspondingly. However, if the sample size is restricted, relying just on a subset of those samples to verify the model might result in erroneous results. In these instances, cross validation [8] is a popular strategy.
- Tasks
Machine learning tasks have been classified into three broad types based on three factors: the kind of data, the presence of additional input, the style of guidance given to the model, and the nature of the work to be accomplished [7].
a. Supervised Learning: In this method, the function is inferred from graded or labelled data. The training process, for illustration, consists of input-output pairs that must be appropriately matched. In order for a generalised functional and provide the desired output, it must be learned from an unexpected input.
b. Unsupervised Learning: Model learns how to look at data for routines and procedures. If the goal of the model is clustering, an unregulated approach can be utilized as a phase in the process.
c. Reinforcement Learning: Learning models learn from the repercussions while direct estimation only with surrounding. The data is made up entirely of weather and activity data. The RL client uses a credit after completing an action that indicates how effective the activity was. The goal of this entity is to maximize the payout over time.
Between unsupervised learning, there is the concept of mid learning, in which some (typically many) of the items in the training set are not labelled, or some of the labels are incorrect.
Active learning has recently gained popularity as a type of machine learning challenge. In this approach, there is a lot of unlabelled data, and recognizing it is possible, but it takes a long time and a lot of resources. An active learning model might query someone else's tagged subset of data. To infer the widest input-label map, for example, an active learning agent must review data and locate the most appropriate objects that require external labelling with the least amount of labelled data feasible...
2. Applications
Machine learning tasks may also be classified based on the expected outcome [7]:
- Classification: The goal of a learning-objective agent is to create a model that assigns an unknown input to one or more of these classes, with the input being divided into two or more classes. The training data has been labelled with a class in this example.
- Regression: The weight of a person depending on actual height, for, must be continuous rather than discrete. Regression and classifications are both possible with supervised learning.
- Clustering: It is vital to organize the data that has been provided. Because the groups are not known in advance, clustered is a typical example of supervised methods.
- Density estimation: regulates how input data is distributed in a given space. Data can be recorded and analysed using the projected distribution or intentionally manufactured to closely resemble the real thing.
- Dimensionality reduction: One method is to simplify the data by learning a translation in a lower-dimensional space.
- Representation learning: To extract useful features, data must be pre-processed before being input into the deep learning model. The purpose of depiction research is to learn how to extract meaningful these properties from raw data. Many machine learning models presently use representational learning methodologies to solve problems.
VI. Results
A. Experimental setting
Development details for YOLOv2: The size of a knee X-ray picture after pre-processing is 2048 2560, which is too huge for YOLOv2. As the input for knee joint identification, we scale all of these photos to 256 320 pixels in size. The bounding boxes that have been marked are resized proportionately. We first adjust the Gray X-ray picture by removing the mean and dividing by the standard variation, rather than sending it direct into the CNN model. From the training photos, the mean and standard deviation are determined. Then, as the model's input, we convolve three identical normalized Gray knee X-ray images into a three-channel picture. For knee detect introduction, K-means is utilized to cluster knee bounding boxes (also known as anchor box). In the trials, the number of bounding boxes is varied from one to six. We also examine the impact of utilizing weight decay against not using weight decay.
The knee X-ray picture is enlarged, normalized, and then concatenated in the testing step, using the same pre-processing approach as in training. We delete bounding boxes with data set less than 0.12 after the model's first pass upon that input picture, and then prune the remainders using non-maximum suppression (NMS) with an overlap ratio of 0.7. The final detection result is the confining box with the highest confidence score. Finally, the identified bounding box is remapped to a higher resolution (2048 2560) for detection assessment and knee joint cropping for the next knee KL grading.


Details that CNN classifiers fine-tune: Cropped from annotated bounding box for knee joint identification task with an expanding ratio of 1.3, the knee joint pictures utilized in CNN classifier fine-tuning for the KL grading. For normalization, the mean and standard deviation of training knee joint pictures are determined. Cropped pictures are scaled to 299 299 pixels for InceptionV3 and 224 224 pixels for ResNet, VGG, and DenseNet for ResNet, VGG, and DenseNet. They're adjusted before being concatenated into three-channel pictures for CNN classifier training and testing. The demo matrix (shown on the bottom left) is the changeable ordinal matrix that was utilized. The training epochs validation loss and accuracy is shown in figure 6
Conclusion
We use a modified YOLOv2 model to identify the knee joint and fine-tune CNN models with an unique ordinal loss for knee KL grading in this work. Both knee joint identification and knee KL grading yield state-of-the-art results. The one-stage detect YOLOv2 is ideally suited to detection jobs with less variable object size, based on its performance on the knee joint detection. On the knee KL grading problem, the suggested ordinal loss improves classification accuracy and lowers the MAE between prediction and ground truth when compared to using cross-entropy across all common CNN classification models, indicating its use in ordinal classification tasks. The fine-tuned VGG-19 model provides the greatest classification performance when compared to ResNet or DenseNet variations, demonstrating the performance of CNN models that are highly reliant on the recognition task.
References
[1] P. G. Conaghan, M. Porcheret, S. R. Kingsbury, A. Gammon, A. Soni, M. Hurley, M. P. Rayman, J. Barlow, R. G. Hull, J. Cumming, et al., Impact and therapy of osteoarthritis: the arthritis care oa nation 2012 survey, Clinical rheumatology 34 (9) (2015) 1581–1588. [2] T. Neogi, The epidemiology and impact of pain in osteoarthritis, Os- teoarthritis and Cartilage 21 (9) (2013) 1145–1153 [3] J. M. Ortman, V. A. Velkoff, H. Hogan, et al., An aging nation: the older population in the United States, 201 [4] J. Kellgren, J. Lawrence, Radiological assessment of osteo-arthrosis, Annals of the rheumatic diseases 16 (4) (1957) 494. [5] A. G. Culvenor, C. N. Engen, B. E. Øiestad, L. Engebretsen, M. A. Risberg, Defining the presence of radiographic knee osteoarthritis: a comparison between the kellgren and lawrence system and oarsi atlas criteria, Knee Surgery, Sports Traumatology, Arthroscopy 23 (12) (2015) 3532–3539. [6] Z. Niu, M. Zhou, L. Wang, X. Gao, G. Hua, Ordinal regression with mul- tiple output cnn for age estimation, in: CVPR, 2016, pp. 4920–4928. [7] L. Shamir, S. M. Ling, W. W. Scott Jr, A. Bos, N. Orlov, T. J. Macura, D. M. Eckley, L. Ferrucci, I. G. Goldberg, Knee x-ray image analysis method for automated detection of osteoarthritis, TMBE 56 (2) (2009) 407–415. [8] J. Antony, K. McGuinness, N. E. O’Connor, K. Moran, Quantifying ra- diographic knee osteoarthritis severity using deep convolutional neural net- works, in: ICPR, 2016, pp. 1195–1200. [9] A. Tiulpin, J. Thevenot, E. Rahtu, S. Saarakkala, A novel method for automatic localization of joint area on knee plain radiographs, in: SCIA, 2017, pp. 290–301. [10] N. Dalal, B. Triggs, Histograms of oriented gradients for human detection, in: international Conference on computer vision & Pattern Recognition (CVPR’05), Vol. 1, 2005, pp. 886–893. [11] J. Antony, K. McGuinness, K. Moran, N. E. OConnor, Automatic detec- tion of knee joints and quantification of knee osteoarthritis severity using convolutional neural networks, in: MLDM, 2017, pp. 376–390. [12] J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for se- mantic segmentation, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440. [13] A. Tiulpin, J. Thevenot, E. Rahtu, P. Lehenkari, S. Saarakkala, Automatic knee osteoarthritis diagnosis from plain radiographs: A deep learning-based approach, Scientific reports 8 (1) (2018) 1727
Copyright
Copyright © 2022 Zainab Mushtaq Wani, Dr. Satish Saini. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41757
Publish Date : 2022-04-23
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online