

Ijraset Journal For Research in Applied Science and Engineering Technology
Design of a 32-Bit, Dual Pipeline Superscalar RISC-V Processor on FPGA: A Review
Authors: Rohan C, Nidhith B R, Mohammed Maaz, Aman Shariff M A, Mohamed Anees
DOI Link: https://doi.org/10.22214/ijraset.2022.44654
Certificate: View Certificate
Abstract
A 40 MHz with 32-bit and 5-stage dual-pipeline superscalar processor based on RISC-V Instruction Set Architecture is presented. It supports integer, multiply-divide and atomic read-modify-write operations. The proposed system implements in-order issuing of instructions. The design includes a dynamic branch prediction unit, memory subsystem with virtual memory, separate instruction cache and data cache, integer and floating-point execution units, interrupt controller, error control module, and a UART peripheral. Individual interrupts can have up to four levels of primary priority set in the interrupt controller. For the main memory, the error control module provides single error correction and double error detection. For on-chip communication, the Wishbone B.3 bus standard is used. On a Virtex-7 XC7VX485T FFG 1761-2 FPGA-based board, the processor is implemented. The architecture has CoreMark and Dhrystone benchmark ratings of 3.84/MHz and 1.0603 DMIPS/MHz, respectively.
Introduction
I. INTRODUCTION
The speed, performance, and Instruction Set Architecture of processors are the most important factors to consider (ISA). Unlike most commercial ISAs, an open source ISA provides for more innovation with cheaper costs and greater flexibility. To put it another way, a freely available ISA can be efficiently modified for a specific application and workload. Because of its superior advantages over OpenRISC, SPARC, and other ISAs, RISC-V was chosen for the proposed design. The RISC-V ISA is made up of a base integer ISA (RV32I) and optional extensions to the base ISA. Integer (I), Multiply/Divide (M), Atomic (A), Single Precision Floating Point (F), and Double Precision Floating Point (F) are the standard extensions (D) instructions. UC Berkeley has already built RISC-V silicon implementations, and external projects in a variety of nations are also ongoing. One such variant of RISC V is the "Rocket core," which, when implemented in the same process technology, has roughly the same performance as an ARM A5 but is 64-bit instead of 32-bit and has a better form factor and dynamic power consumption than a 32-bit ARM core. More RISC-V ISA implementations have been released in recent years. The ZScale/VScale processor is also based on the RISC-V ISA with RV32IM architecture. A 32-bit single cycle RISC-V processor FPGA prototype is demonstrated. The paper describes a RISC-V processor IP that uses a 32-bit RV32IMA architecture with a 5-stage pipeline. A 32-bit superscalar processor with two 5-stage pipelines is presented in this paper. It implements the RV32IMAFD RISC-V ISA expansion. The goal of this project is to increase throughput by adding new features to the scalar processor. It is implemented as a dynamic branch prediction method. This RISC-V processor can be used in micro embedded processors, IoT applications, machine learning, and other areas. Because it is an open architecture and can be tested for malicious code that could affect its functioning, it can be utilized in military applications, particularly defense.
II. METHODOLOGY
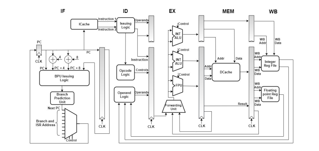
The processor is a 32-bit, five-stage, two-way in-order superscalar pipeline with RV32IMAFD instructions. The processor's dual-pipeline superscalar architecture is shown in Figure 1. Fetch (IF), Decode (ID), Execute (EX), Memory (MEM), and Write-back are the pipeline stages (WB). A programme memory address is generated in the programme counter (PC) during the IF step. This PC value is used to retrieve two consecutive instructions from the Instruction Cache (I-Cache), which are subsequently sent to the ID stage. The Instruction Issuing Unit (IIU) sends one or two instructions to the pipeline, depending on the dependencies between them. The design allows for the simultaneous execution of two integers or one integer and one floating point instruction. The decode stage decodes the instruction and creates select signals for data forwarding in the EX stage's multiplexers. The ID stage is in charge of reading data from the data memory during Atomic Memory Operations (AMO). The EX stage receives operatives from the ID stage. The EX stage has two integer and one floating point units that can only execute two instructions (two integers or one integer and one floating point instruction) every clock cycle.
The forwarding lines toggle the multiplexers, letting the EX stage to use either the forwarded data or the data from register/memory. When multiply/divide or floating-point operations are done, the IF and ID stages become stagnant.
As the execution of instructions takes a variable number of clock cycles, they enter the execution stage. The memory stage uses the EX stage's results to complete data transactions for load/store/atomic instructions. Other times, the results will be sent to the WB stage. If necessary, the register file is modified in the WB stage. For integer and floating-point instructions, separate register files are used. Integer operations use 32 32-bit registers, while floating point operations use 32 64-bit registers. To reduce complications and resource use, a few design rules were adopted. Only if the second instruction has no dependencies on the first is a pair of instructions sent to the pipeline. Only the first instruction is issued in the event of dependencies, and the second instruction is held back at the ID stage. Two load/store or atomic memory access instructions, or two branch instructions, are never issued at the same time. Control status register (CSR) access, load, branch, multiply/divide instructions are issued only through the first pipeline. Wishbone B.3 bus standard by Open Cores is implemented in the system. A dynamic branch prediction technique is used to create a branch prediction unit for superscalar issuing (regarding dependencies).
III. RESULTS AND DISCUSSION
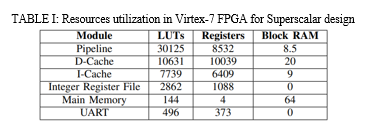
The processor is designed in Verilog using Xilinx Vivado 2018.2 and is implemented on Virtex-7 XC7VX485T FFG 1761-2 FPGA based board. This FPGA can operate at a maximum frequency of 40 MHz. After implementation, the resource use of the Virtex-7 FPGA is confirmed and is shown in Table I.
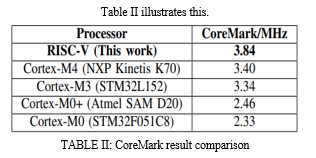
The processor's performance was evaluated using the CoreMark and Dhrystone benchmark programmes. 3.84 DMIPS/MHz and 1.0603 DMIPS/MHz, respectively. The CoreMark score is compared to the scores of some common ARM Cortex-M processors on the market. The performance of our CPU is superior to that of the competitors.
Conclusion
This paper discusses a 32-bit, single-core, dual-pipeline superscalar architecture. The processor runs on a Virtex-7 FPGA, and the results are displayed in terms of resources, frequency, and CoreMark benchmark value.For branch prediction, interrupt management, and all corner cases. Furthermore, the architecture of a dual-issue pipeline can be changed to a multiple-issue pipeline with more execution units. Out of order execution can be used to increase functional unit utilization, reduce stalling, and improve performance. Because virtual memory is already present in the system, Linux may be ported with minimal work by implementing a supervisor privilege level. This single core can be used to construct multi-core systems and can be transformed into a customizable IP with flexible settings.
References
[1] R. Höller, D. Haselberger, D. Ballek, P. Rössler, M. Krapfenbauer and M. Linauer, \"Open-Source RISC-V Processor IP Cores for FPGAs — Overview and Evaluation,\" 2019 8th Mediterranean Conference on Embedded Computing (MECO), 2019, pp. 1-6, doi: 10.1109/MECO.2019.8760205 [2] T. Gokulan, A. Muraleedharan and K. Varghese, \"Design of a 32-bit, dual pipeline superscalar RISC-V processor on FPGA,\" 2020 23rd Euromicro Conference on Digital System Design (DSD), 2020, pp. 340-343, doi: 10.1109/DSD51259.2020.00062. [3] Kumar, GH Shashi, and Gurusiddayya Hiremath. \"Low power implementation of risc-v processor.\" Journal of VLSI and Signal Processing 6.3 (2016): 59. [4] Neri, Michael Joseph, et al. \"Design and Implementation of a Pipelined RV32IMC Processor with Interrupt Support for Large-Scale Wireless Sensor Networks.\" 2020 IEEE REGION 10 CONFERENCE (TENCON). IEEE, 2020 [5] Langen, D., Niemann, J.C., Porrmann, M., Kalte, H. and Rückert, U., 2002. Implementation of a RISC processor core for SoC designs–FPGA prototype vs. ASIC implementation. In Proceedings of the IEEE-Workshop: Heterogeneous reconfigurable Systems on Chip (SoC).
Copyright
Copyright © 2022 Rohan C, Nidhith B R, Mohammed Maaz, Aman Shariff M A, Mohamed Anees. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44654
Publish Date : 2022-06-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online