

Ijraset Journal For Research in Applied Science and Engineering Technology
Detailed Classification of Customer Reviews Using Sentiment Analysis
Authors: Mr. Sarvesh Iyer, Mr. Tarun Kalkar, Mr. Shivam Pandey, Mr. Ved Ghuikhedkar, Prof. Nirmal Mungale
DOI Link: https://doi.org/10.22214/ijraset.2023.49028
Certificate: View Certificate
Abstract
With the rapid of Growth of E-Commerce websites, there is no doubt that people are drawn to online shopping more nowadays. As people are drawn to it, so are the sellers. But sellers can differentiate in quality as well as quantity. To adjust to the needs of the consumer, some sellers provide luxury items and some focus on fulfilling the needs of the consumer at normal rates. To make it easier for consumers to decide which product suits for their demands and needs, customer review on E-Commerce Websites is a proficient way for consumers to get what they are looking for. In today’s world, customer’s reviews can have big impacts on the sales of a product. It can also let the seller and manufacturer know if their product is lacking in quality or not. Favorable reviews can attract New Customers while bad reviews can result in less sales of a product. This can also maintain the reputation of Brand or a manufacturer as the people who have previously bought a product from them, will buy their products again and this will promote Customer-Brand loyalty. Studying the reviews has become an essential part of the E- Commerce field and Sentiment Analysis is a process that greatly helps in determining the Statistics of Customer Reviews. Sentiment analysis, also known as opinion mining, is the computational study of people\'s written opinions, feelings, attitudes, and emotions. It is one of the most active research areas in natural language processing and text mining in recent years. Sentiment analysis can assist you in determining the ratio of positive to negative engagements on a particular topic. You can gain insights from your audience by analysing text bodies such as comments, tweets, and product reviews.
Introduction
I. RELATED LITERATURE
A natural language processing (NLP) method known as sentiment analysis or opinion mining is used to determine whether data is positive, negative, or neutral. Text data is frequently subjected to sentiment analysis, which enables businesses to monitor brand and product sentiment in customer feedback and comprehend customer requirements.
There are three methods for sentiment analysis:
Rule-based: Based on a set of rules that have been manually created, these systems carry out sentiment analysis automatically.
Typically, rule-based systems make use of a set of artificial rules that assist in determining subjects of subjectivity, polarity, or opinion. Because it doesn't take into account how words are arranged, the rule-based system is very simple. Obviously, you can support new expressions and vocabularies by employing more advanced processing methods or adding new rules. However, introducing new rules can have a significant impact on the system as a whole and alter previous outcomes. Rule-based systems frequently necessitate fine- tuning and upkeep, necessitating ongoing investment Automatic Systems: To learn from data, these systems use machine learning techniques.Automated methods, in contrast to rule-based systems, do not rely on rules that are created by hand but rather on machine learning techniques. Typically, tasks involving sentiment analysis are modeled after classification problems in which text is entered into a classifier and categories are returned. B. Either positive or negative
Based on the test patterns used for training, the model learns to associate particular inputs (text) with corresponding outputs (tags) in the training process (a). A text input is transformed into a feature vector by a feature extractor. pairs of positive, negative, or neutral feature vectors and tags are fed into an algorithm for machine learning in order to create a model.
A feature extractor is used in prediction process (b) to turn the unseen text input into feature vectors. The model is then fed these feature vectors to generate predicted tags (once more positive, negative, or neutral).
Algorithms for Classification: A statistical model like Naive Bayes, Logistic Regression, Support Vector Machines, or Neural Networks are typically used in the classification step:
- Naïve Bayes: A group of probabilistic algorithms that predict a text's category using Bayes's Theorem.
- Linear Regression: A well-known algorithm in statistics that uses a set of features (X) to predict a value (Y).
- Support Vector Machines: A non-probabilistic model that uses text examples as points in a multidimensional space as its representation. In that space, distinct regions are mapped to examples of various categories (sentiments). Then, new texts are put into a category based on how similar they are to other texts and where they are mapped.
- Deep Learning: A diverse set of algorithms that use artificial neural networks to process data to imitate the human brain
- Hybrid Systems: It combines automatic and rule-based approaches. One major advantage of these systems is that they frequently yield more accurate results.
II. FUTURE SCOPE
Implementation of Sentiment analysis is an interestingly useful asset for organizations that are hoping to gauge mentalities, sentimentsand feelings in regards to their image. Until now, most of opinion examination projects have been led only by organizations and brands using virtual entertainment information, study reactions and different centres of client created content. By exploring and examining client opinions, these brands can get an inside take a gander at purchaser waysof behaving and, at last, better serve their crowds with the items, administrations and encounters they offer. It is getting better since online entertainment is progressively more emotive and expressive. A brief time prior, Facebook presented "Responses," which permits its clients to 'Like' content, however connect an emoji, whether it be a heart, a stunned face, furious face, and so forth. To the typical virtual entertainment client, this is a tomfoolery, apparently senseless component that gives the person in question somewhat more opportunity with their reactions. In any case, to anybody seeking influence online entertainment information for feeling examination, this gives a completely new layer of information that wasn't accessible previously. Each time the significant web-based entertainment stages update themselves and add more elements, the information behind those collaborations gets more extensive and more profound. In order to properly comprehend the value of social media interactions and what they reveal about the people who use the platforms, the future of sentiment analysis will involve digging even deeper beneath the surface of likes, comments, and shares. Additionally, this forecast predicts that sentiment analysis will be utilized in additional settings; This technology will be used by public figures, NGOs, government agencies, schools, and many other institutions in addition to brands.
III. PROPOSED METHODOLOGY
A. Software Specifications
- Language Used: Python
- Platform Used: Google Collab
- Libraries Used: NLTK, Seaborn, Tokenizers.
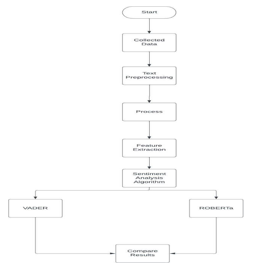
The above figure shows the work flow of the proposed system and how the things will occur. We will be gathering the data and then implementing two different models that are
- VADER Model
- ROBERTa
Both of them are totally different from one another.
a. VADER Model
Vader is model that is based on lexicon and rule based matching , sentiment analysis tool that is specifically aware to sentiments expressed in social platform. VADER makes use of a variety of A sentiment lexicon is a collection of lexical elements (such as words) that are often classified as either positive or negative depending on their semantic orientation. VADER not only informs us of the positivity and negativity scores, but also of the sentimentality of each score. This model for text sentiment is sensitive to both the polarity (positive/negative) and intensity (strong) of emotion. It may be used right away on unlabeled text data and is included in the NLTK package. The VADER sentimental analysis uses a dictionary that converts lexical data into sentiment scores, which measure the intensity of an emotion. By adding the intensity of each word in a text, one can determine the sentiment score of that text.
- Working Of Vader
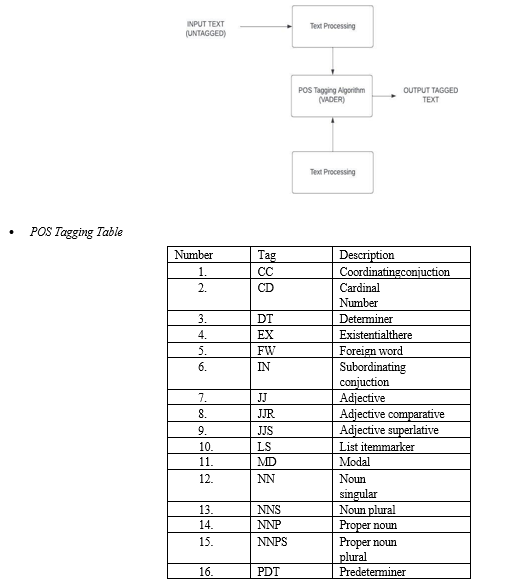
Part-of-speech (POS) (POS) In natural language processing, tagging is the process of classifying words in a text (corpus) according to a specific part of speech, based on the word's definition and context.
Part-of-speech tags can be used to infer semantics because they describe the typical structure of lexical phrases in a sentence or text.
One of the earliest forms of tagging was rule-based POS tagging. Rule-based taggers search a dictionary or lexicon for potential tags for each word. When a word has multiple possible tags, rule-based taggers use handwritten rules to select the appropriate tag. Rule-based tagging also makes it possible to disambiguate by looking at the linguistic characteristics of a word as well as those of its related words.
???????b. Roberta Model
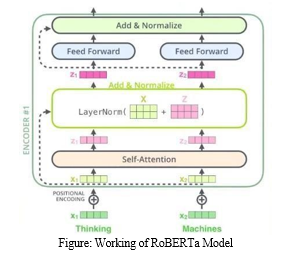
RoBERTa utilizes a different pretraining strategy and a byte- level BPE as a tokenizer (similar to GPT-2) despite sharing the same architecture as BERT.
You are not required to specify which token corresponds to which segment because RoBERTa does not have token type ids. Simply make use of the separation token tokenizer.sep token to Improve BERT's outcomes, the authors made a few minor adjustments to the training process and architecture, despite the fact that RoBERTa's architecture is virtually identical to BERT's.
Some of the modifications are
- Removal of the Next Sentence Prediction (NSP) Objectives: In the next sentence prediction task, the model is trained to determine, through the use of an auxiliary Next Sentence Prediction (NSP) loss, whether the observed document segments come from the same documents or from other documents. The researchers conducted tests on a variety of versions, both with and without NSP loss, and came to the conclusion that using NSP loss matches or slightly improves performance on subsequent tasks.
- Training with Bigger Corpus: BERT is initially trained for 1M steps and 256 sequence batches. The model was trained in this study with 31K steps of batch-sized 8K sequences and 125 steps of 2K sequences. This has two advantages: On the masked language modeling target, the large batches raise both the difficulty and accuracy of the final task. Additionally, parallelizing large batches is made simpler by distributed parallel training.
- Working Flowchart of RoBERTa Model
IV. IMPLEMENTATION
A. Data collection
The dataset we used here is the collection of all the reviews related to food products from Amazon. The dataset here has multiple parameters like score, time of the review, profile name, productid, User ID, Text, Summary of the review, helpfulness numerator, helpfulness denominator.
Id
Produc tId is the item's distinctive identifier. Unique identification number for the user ProfileName
Helpfulness Numerator of people who thought the review was useful in the numerator
Number of users who indicated whether or not they considered the review useful (helpfullnessDenominator)
Ratings range from 1 to 5. Time — the review's timestamp
Summary: A succinct synopsis of the evaluation Text — the review's text.
???????B. Libraries and Modules used
- NLTK
The NLTK is the most widely used platform for developing Python programs that make use of human language data. It provides straightforward interfaces to more than fifty corpora and lexical resources, including WordNet, as well as a collection of text processing libraries for categorization, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.
A hands-on guide that covers programming foundations in addition to topics in computational linguistics and extensive API documentation make NLTK suitable for linguists, engineers, students, educators, academics, and industry users alike. NLTK can be used on Linux, Windows, and Mac OS X. The fact that NLTK is a free, open-source, community-driven project is the best part.
2. Seaborn
A Seaborn is a Python data visualization library based on matplotlib. It provides a sophisticated drawing tool for creating statistical visualizations that are engaging and instructive.
For a quick overview of the library's concepts, you can read the paper or the introductory notes. Go to the installation page to learn how to download and use the package. To get an idea of what Seaborn can do, you can look through the sample galleries and then look at the tutorials or API.
3. Tokenizers
The raw input text for the transformers must be preprocessed into a form that the model can understand because, like any other neural network, they are unable to interpret it directly. Tokenization is the process of converting text input into integers. We utilise a tokenizer to accomplish this, and it does the following
a. Dividing the incoming text into tokens, which are single letters, words, or subwords.
b. Putting a distinct number on each token's map.
c. Arranging and including model-useful inputs that are necessary
C. Implemented Model

 ???????
???????
Conclusion
Despite all of the challenges and potential issues facing the industry, sentiment analysis\'s value cannot be ignored. Because it bases its findings on factors that are fundamentally compassionate, sentiment analysis is destined to become one of the key determinants of many future business decisions. There are now a number of problems with sentiment analysis that can be fixed by using text mining techniques that are more accurate and consistent. A genuine social democracy that relies on the collective wisdom of the people rather than a select group of \"experts\" will be built using sentiment analysis. a democracy in which all points of view and emotions are taken into consideration when making decisions. The findings of sentiment analysis are useful as a preventative measure. It cannot be used to predict a business\'s success or any other measurement. Sometimes, sentiment analysis is unnecessary and only serves as a reporting metric after the harm has already occurred. Uneven outcomes in light of the sources: Separating data can present a significant obstacle in sentiment analysis. Situational analysis based on incomplete data can produce biased outcomes. To obtain complete data, sources like Twitter and Facebook can be mined.
References
[1] Abdul-Mageed, M., M.T. Diab, and M. Korayem. Subjectivity and sentiment analysis of modern standard Arabic. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:shortpapers, 2011 [2] Akkaya, C., J. Wiebe, and R. Mihalcea. Subjectivity word sense disambiguation. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (EMNLP- 2009), 2009. 3. Alm, C.O. Subjective natural language problems: motivations, applications, characterizations, and implications. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:shortpapers (ACL-2011), 2011. [3] Alm, C.O. Subjective natural language problems: motivations, applications, characterizations, and implications. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:shortpapers (ACL-2011), 2011. [4] Andreevskaia, A. and S. Bergler. Mining WordNet for fuzzy sentiment: Sentiment tag extraction from WordNet glosses. In Proceedings of Conference of the European Chapter of the Association for Computational Linguistics (EACL-06), 2006. [5] P. Prakrankamanant and E. Chuangsuwanich, \"Tokenization- based data augmentation for text classification,\" 2022 19th International Joint Conference on Computer Science and Software Engineering (JCSSE), 2022, pp. 1-6, doi: 10.1109/JCSSE54890.2022.9836268. [6] Abdul-Mageed, M., M.T. Diab, and M. Korayem. Subjectivity and sentiment analysis of modern standard Arabic. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:shortpapers, 2011. [7] Akkaya, C., J. Wiebe, and R. Mihalcea. Subjectivity word sense disambiguation. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (EMNLP-2009), 2009 [8] Alm, C.O. Subjective natural language problems: motivations, applications, characterizations, and implications. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:shortpapers (ACL-2011), 2011. [9] Li, F., C. Han, M. Huang, X. Zhu, Y.J. Xia, S. Zhang, and H. Yu. Structure-aware review mining and summarization. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling-2010), 2010. [10] Li, S., C.-R. Huang, G. Zhou, and S.Y.M. Lee. Employing Personal/Impersonal Views in Supervised and Semi-Supervised Sentiment Classification. In Proceedings of Annual Meeting of the Association for Computational Linguistics (ACL-2010), 2010. [11] Twitter as a Corpus for Sentiment Analysis and Opinion MiningAlexander Pak, Patrick Paroubek [12] Kushal Dave, Steve Lawrence, and David M. Pennock.2003. Mining the peanut gallery: opinion extraction and semantic classification of product reviews [13] B. Aisha, \"A Letter Tagging Approach to Uyghur Tokenization,\" 2010 International Conference on Asian Language Processing, 2010, pp. 11-14, doi:10.1109/IALP.2010.72.
Copyright
Copyright © 2023 Mr. Sarvesh Iyer, Mr. Tarun Kalkar, Mr. Shivam Pandey, Mr. Ved Ghuikhedkar, Prof. Nirmal Mungale. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET49028
Publish Date : 2023-02-07
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online