

Ijraset Journal For Research in Applied Science and Engineering Technology
Detecting Spoofing Attacks in Speaker Verification Systems
Authors: Kathan V Prajapati, Twinkal Christian
DOI Link: https://doi.org/10.22214/ijraset.2022.44162
Certificate: View Certificate
Abstract
The proof of writing tells that they can be powerful, however the issue is as yet present. Because of the chance of parodying assaults at different points the confirmation utilizing biometric has developed astoundingly these years, however they can be helpless against satirizing assaults. In any event, for programmed speaker check, it is difficult to counter the parodying at all focuses. Notwithstanding an extreme climate, the innovation offers great help; more industriousness will be needed in future to set palatable insurance against the assaults. This paper makes accessible a review of work that has been done in the space of ridiculing assaults and its answer for speaker check throughout the long term.
Introduction
I. INTRODUCTION
Programmed Speaker Verification (ASV) framework is to acknowledge or dismiss a guaranteed character dependent on a discourse test. Ridiculing, all in all, is a fraudster or malevolent practice in which correspondence is sent from an obscure source camouflaged as a source known to the collector. Caricaturing is generally pervasive in correspondence instruments that come up short on an undeniable degree of safety in biometric validation. It is proposed to foster a way to deal with recognize replay assaults in ASV frameworks. In discourse signal preparing conventional cepstral handling is joined with steady Q change. Parodying countermeasure has been made viable by the new presentation of the subsequent steady Q cepstral processing(CQCCs).
A. Objective
We propose a replay mocking discovery framework for programmed speaker confirmation utilizing perform multiple tasks learning of commotion classes. We characterize the clamor that is brought about by the replay assault as replay commotion. We investigate the adequacy of preparing a profound neural organization all the while for replay assault mocking recognition and replay commotion grouping.
The perform multiple tasks learning incorporates grouping the commotion of playback gadgets, recording conditions, and recording gadgets just as the satirizing identification. Every one of the three sorts of the commotion classes likewise incorporates a certifiable class. The test results on the adaptation 1.0 of ASVspoof2017 datasets show that the presentation of our proposed framework is improved by 30% moderately on the assessment set.
B. Scope Of Work
It is generally recognized that most biometric frameworks are helpless against parodying, otherwise called imposture. While weaknesses and countermeasures for other biometric modalities have been generally examined, for example face check, speaker confirmation frameworks stay defenseless. This paper portrays some particular weaknesses concentrated in the writing and presents a concise review of late work to create ridiculing countermeasures. The paper finishes up with a conversation on the requirement for standard datasets, measurements and formal assessments which are expected to survey weaknesses to satirizing in practical situations without earlier information.
II. LITERATURE SURVEY
A. Source of System
- Research Papers
- Github
- Reference Materials
B. Proposed
We propose an overall of structure for the speaker confirmation frameworks, where a changed over discourse locator is embraced as a post- handling module for the speaker check framework's acknowledgment choice. The indicator chooses whether the acknowledged case is human discourse or changed over discourse, Voice transformation strategy, which adjusts one speaker's (source) voice to seem like another speaker (target), presents a danger to programmed speaker check. In this paper, we first present new aftereffects of assessing the weakness of present status of-the- craftsmanship speaker check frameworks: Gaussian blend model with joint factor examination (GMM-JFA) and probabilistic straight discriminant investigation (PLDA) frameworks, against caricaturing assaults. The satirizing assaults are reenacted by two voice change procedures: Gaussian combination model based transformation and unit choice based transformation.
???????C. Libraries and Packages
- Pandas
- Numpy
- Librosa
- Pyaudio
III. FEATURE EXTRACTION AND MODEL
A. Feature Extraction
The upgraded sound signs are separated into outlines, to shape portions which are more fixed. Then, a hamming window is applied, with half cover. Countless sound highlights, 11 capabilities altogether, are then removed from each casing. These capabilities incorporate mel- recurrence cepstral coefficients (MFCCs), spectrogram, consistent Q cepstral coefficients (CQCCs), straight prescient cepstral coefficients (LPCCs), altered mel-recurrence cepstral coefficients (IMFCCs), rectangular channel cepstral coefficients (RFCCs), direct channel cepstral coefficients (LFCCs), sub-band centroid recurrence coefficients (SCFCs), sub-band centroid greatness coefficients (SCMCs), and complex cepstral coefficients (CCs).
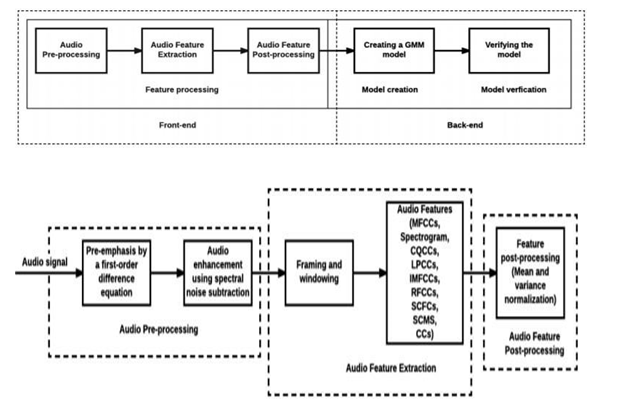
B. ???????Model
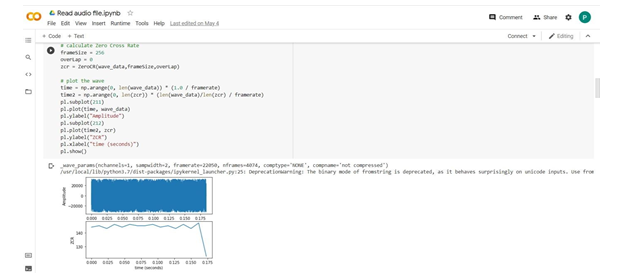
Zero-intersection rate is a proportion of the occasions in a given time span/outline that the sufficiency of the discourse signals goes through a worth of nothing. This component has been utilized vigorously in both discourse acknowledgment and music data recovery, being a vital element to characterize percussive sounds. It is likewise broadly utilized in a wide scope of other sound application spaces, like melodic kind characterization, feature identification, discourse examination, performing voice discovery in music, and natural sound acknowledgment. The easiest strategy to recognize voiced and unvoiced discourse is to break down the zero intersection rate. An enormous number of zero intersections infers that there is no prevailing low-recurrence wavering.
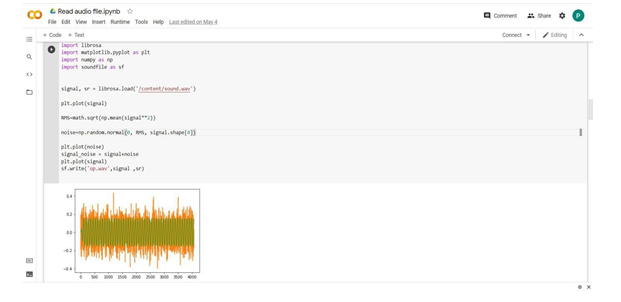
I'm adding commotion to a sign utilizing librosa however subsequent to adding clamor I can't save the sign back as a wav file. Adding commotion to unadulterated discourse is primarily to test the impact of the denoising calculation. As per the meaning of sign to commotion proportion, this little program acquires boisterous discourse with various sign to clamor proportion in bunches.
IV. COUNTER -MEASURES
It is trying to counter mimicry assaults; the standardized score of assailant's voice and target's voice are very close. Studied the control of voice by proficient aggressor, the example of glottal planning to counter ridiculing. The acoustic variety of vowel by vowel was measured utilizing quadratic discriminant over initial two formants. This camouflage location builds the outcome from 95.8 % to 100%. Nonetheless, camouflage recognition isn't strong for a wide range of frameworks. The exhibition of different frameworks has been checked for few speakers.
Programmed speaker confirmation framework is done for the most part in two stages: disconnected preparing and runtime check. In disconnected preparing, an objective voice test is prepared utilizing highlights extricated from the voice test of the speaker. The check at runtime incorporates the coordinating of discourse tests asserted by the speaker with the objective voice tests. The likeness coordinating of various speakers is finished with the assistance of various scoring techniques.
These can be calculations like Euclidean distance, Manhattan distance or Mahalanobis distance. The examination of tests incorporates two models one is guessed and different shows elective theories. With the assistance of a classifier a general likeness is determined and based on the outcome, a choice is made if to acknowledge it.
V. ACKNOWLEDGMENT
This project would not have been possible without the support of many people. Many thanks to my friends, family, faculty member who read my numerous revisions and helped make some sense of the confusion. Also thanks to my co-author, Twinkal Christian, who offered guidance and support.
Thanks to the Gujarat Technological University & my College to give me this opportunity to build this project.
Conclusion
The version of this template is V2. Most of the formatting instructions in this document have been compiled by Causal Productions from the IEEE LaTeX style files. Causal Productions offers both A4 templates and US Letter templates for LaTeX and Microsoft Word. The LaTeX templates depend on the official IEEEtran.cls and IEEEtran.bst files, whereas the Microsoft Word templates are self-contained. Causal Productions has used its best efforts to ensure that the templates have the same appearance. Causal Productions permits the distribution and revision of these templates on the condition that Causal Productions is credited in the revised template as follows: “original version of this template was provided by courtesy of Causal Productions (www.causalproductions.com)”.
Copyright
Copyright © 2022 Kathan V Prajapati, Twinkal Christian. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44162
Publish Date : 2022-06-12
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online