

Ijraset Journal For Research in Applied Science and Engineering Technology
Detecting the Best Route to Destination with Minimum Covid19 Infection Chances
Authors: Parth Aranke, Ajinkya Ghuge, Shivam Garje
DOI Link: https://doi.org/10.22214/ijraset.2022.43053
Certificate: View Certificate
Abstract
Hazard of covid 19 is increasing by day-by-day. Many organizations have tried to address this issue in this own way. More than 20,000 articles about covid-19 has been published.[4] Some have tried to track the covid-19 patients while some systems tried to keep a track of occurrences of patients. While travelling in public the next person standing to you, Or the next person standing to you might be infected. Masks and other measures can be used to avoid the spread but as long as we are in the vicinity of other patients the chances of getting infected are very high. There arises the need of a System which will decide an alternative route to the destination, based on the chances of the getting infected by covid-19. The mobile application will generate all the possible routes to the destination and then calculate the density of covid-19 patients across each of them and then it will decide the best route to the destination.
Introduction
I. INTRODUCTION
In today’s world the amount of transport is drastically increased. Even if pandemic is forcing everyone to stay at home, people are ordering food and groceries at home.
This puts people who deliver these goods in a grave danger of getting infected by covid-19. There arises the need of a safer transportation system.
Due to covid-19, The way people transport have drastically changed.[5]
The idea is to collect data from the user such as its status: whether he/she has been affected by any pandemic disease and also her/his location. Then using this data to optimize the transportation in such a way that it will minimize the covid-19 infection chances.
II. PROPOSED METHODOLOGY
A. Obstacle Avoidance using A* algorithm
This method requires preexisting knowledge of obstacles. In this case, these obstacles are clusters of patients. To form these clusters, we need the information of locations of patients which can be gathered using an android application. Then, clusters of these patients can be formed using DB-scan algorithm.
The DB-scan algorithm works in the following way:
There are two main parameters to consider:
- radius(r): the minimum distance of other points from the current point, in order to consider them.
- min. Number of neighbors required to consider a core point(n): if a point has this number of neighbors, then it will be considered a core point.
The algorithm starts by picking any random core point. Then if the neighbors of this point are also core points, then they are added to the cluster. This step is carried out for every core point. After that, the non-core points which are at-most ‘r’ distance away from any of the core points, are also added to the cluster.( C. Nagesh ,2020)
After formation of these clusters, The A* algorithm will be used to find a way around these clusters. Starting point and ending point for the A* algorithm will be same as the given starting point and ending point. After the output is received from A* algorithm, it needs to be fitted along the existing paths in the real world.(S. Nedkov and S. Zlatanova,2011)
Thus, computation overhead of this method is very large, but still, it’s very efficient for the regions where size of clusters of patients are noticeable.
B. Calculating Density of Patients Across the Path and Selecting the Path with the Minimum Density
- Storing Location Based Data: Hilbert’s curve is used to map 2-d space to 1-d line in order to optimize search queries.[3]
- Google Directions api: This api generates every possible path to the destination. For each of these paths the density of patients can be calculated. Then the path which has the minimum density will be considered as the best path.
- Calculating Density for a Single Path
a. When a user is registered, his location and status will be stored in database. Location is stored in the form of longitude and latitude.
b. The ‘x’ number of points will be selected on the route.
c. ‘x’ will depend on the displacement between two points.
d. For each of these points, the users which lie in 100-meter radius will be counted.
e. Then the sum of count for each point is divided to get the average density.
f. This new average will be our final density factor for a given route.
4. Selection of factor ‘x’: This factor will depend on the continuity of the distribution of patients in that region.
III. RESULT
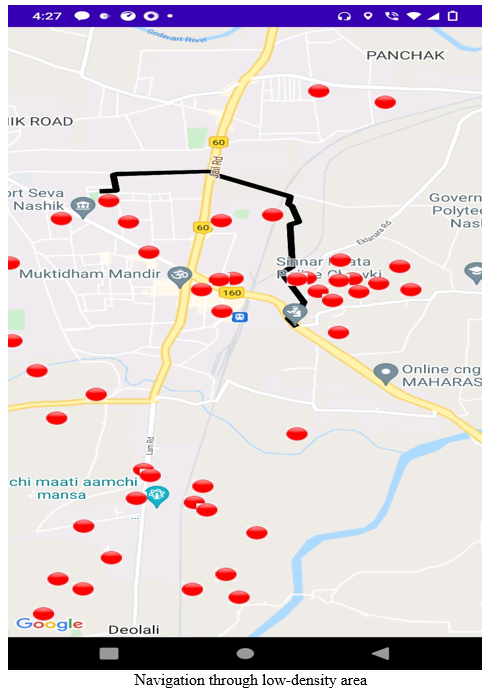
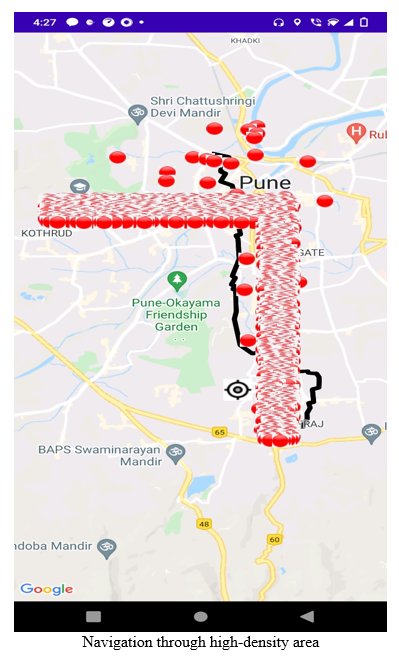
Conclusion
The safer transportation system can be built using one of the two proposed methodologies. The first method is more suited for areas which have well-defined and sufficiently large clusters of patients The second methos is more suited for areas where clusters are not well defined and not very large. The first method also has higher computational overhead than the second method, thus it is only useful if the clusters are static and not dynamic. The second method uses an api which tells users the number of patients in the 100-meter radius of a particular point. This api can also be used by other applications.
References
[1] Nagesh, C.(2020,April 24).DBSCAN Clustering Algorithm in Machine Learning.retrieved from:https://www.kdnuggets.com/2020/04/dbscan-clustering-algorithm-machine-learning.html [2] S. Nedkov and S. Zlatanova, \"Enabling obstacle avoidance for google maps\' navigation service\", Proceedings Gi4DM, 2011. [3] Tarver, Tim. (2014). HILBERT\'S SPACE-FILLING CURVE. Asian Journal of Mathematics and Applications. 2014. 2307-7743. [4] P. Chaturvedi, A. Chaturvedi and A. Singh, \"Covid-19 pandemic: A story of helpless humans confused clinicians rudderless researchers and a victorious virus!\", Cancer Research Statistics and Treatment, vol. 4, no. 1, 2021. [5] A. Shamshiripour, E. Rahimi et al., \"How is covid-19 reshaping activity-travel behavior? evidence from a comprehensive survey in chicago\", Transportation Research Interdisciplinary Perspectives, vol. 7, pp. 100216, 2020.
Copyright
Copyright © 2022 Parth Aranke, Ajinkya Ghuge, Shivam Garje. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43053
Publish Date : 2022-05-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online