

Ijraset Journal For Research in Applied Science and Engineering Technology
Detection and Analysis of COVID-19 in Chest X-RAY Images
Authors: Sheikh Raheela Gaffar, Ankur Gupta
DOI Link: https://doi.org/10.22214/ijraset.2022.40520
Certificate: View Certificate
Abstract
COVID-19 is the human body\'s most deadly and deadliest illness caused by a single coronavirus. In December 2019, the Coronavirus, which is thought to have originated in Wuhan, China and is responsible for a large number of deaths, spread rapidly around the world. Early detection of COVID-19 by correct diagnosis, especially in cases when there are no obvious symptoms, may help patients live longer. Chest X-rays and CT scans are the most used diagnostic methods for this illness. According to this study, COVID-19 may be recognized using a machine vision approach from chest X-ray images and CT scans. According to current research based on radiological imaging techniques, such images provide crucial information about the COVID-19 virus. . This proposed solution, which employs contemporary artificial intelligence (AI) tools, has been demonstrated to be successful in detecting COVID-19, and when paired with radiological imaging, can help in the accurate diagnosis of this disease. . In binary classification, the proposed technique is meant to provide accurate diagnoses for COVID and non-COVID patients. With 98.87 percent accuracy in network comparisons and 95.91 percent accuracy in patient status classification, the findings show that VGG-16 is the best architecture for the reference dataset. Convolutional layers were used, with each layer having its own filtering. As a consequence, the VGG-16 design was successful in classifying COVID-19 cases. This design, however, may be improved significantly by altering it or adding a preprocessing step on top of it. Our technology may be used to assist radiologists in validating their first screening and can also be utilized to swiftly screen patients through the cloud.
Introduction
I. INTRODUCTION
COVID-19 is the human body's most deadly and deadliest illness caused by a single coronavirus. In December 2019, the Coronavirus, which is thought to have originated in Wuhan, China and is responsible for a large number of deaths, spread rapidly around the world. Early detection of COVID-19 by correct diagnosis, especially in cases when there are no obvious symptoms, may help patients live longer. Chest X-rays and CT scans are the most used diagnostic methods for this illness. According to this study, COVID-19 may be recognized using a machine vision approach from chest X-ray images and CT scans.
The most frequent strategy is deep learning, which may be the only option to work with these medical images. Deep Learning is an emerging field with the potential to revolutionize COVID-19 detection in the future. Machine learning/deep learning models have previously been used to identify COVID-19 using medical imaging such as X-rays and CT scans, with promising results. The major purpose of this work is to analyze prior studies' approach, collect all of the many sources of lung CT and X-Ray image datasets, and describe the most often used strategies for unilaterally assessing COVID-19 using medical images.. The data required to efficiently train a model must take precedence. Using Machine Learning (ML) or Deep Learning (DL) approaches, this information will help in the diagnosis of COVID-19 cases. Because of the limitations of RT-PCR, researchers devised a novel method for identifying COVID-19 that includes applying Artificial Intelligence to chest CT or X-Ray images.
The viral test is the only definite approach for diagnosis, according to the Centers for Disease Control (CDC), even if a chest CT or X-ray shows COVID-19. This assignment is a preliminary inquiry into the development of a tool that validates the viral test result or offers additional information about the current illness. In the classification of patients in the pneumonia class, VGG-16 (visual Geometry Group) achieves a perfect score of 100 percent, the best performance to date. The usual class did well as well, but the COVID-19 class, despite good results, had some minor classification difficulties. To far, this model produces the best and most consistent results in the COVID-19 class.
II. Literture review
Medical X-rays are images used to diagnose some of the most sensitive regions of the human body, including the bones, chest, teeth, and head. This method has been used by medical practitioners for decades to study and discover fractures or malformations in human organs [1]. This is because, in addition to being noninvasive and cost-effective, X-rays are extremely effective diagnostic tools for detecting pathological alterations. As chest diseases, cavitations, consolidations, infiltrates, blunted costophrenic angles, and microscopic widely dispersed nodules can all be detected on CXR pictures. By examining the chest X-ray picture, radiologists can detect pleurisy, effusion, pneumonia, bronchitis, infiltration, nodule, atelectasis, pericarditis, cardiomegaly, pneumothorax, fractures, COVID positive or COVID negative, and a variety of other illnesses and diseases.
Several studies have been conducted since the beginning of the year 2020 in an attempt to develop a technique for recognizing persons who are afflicted with the disease. The majority of these computer science studies employ convolutional neural networks (CNNs) to categorize mages of CT scans or X-Rays of the chest as normal or abnormal in order to identify probable cases of the corona virus [2]. CNNs are frequently employed for image classification applications because they have demonstrated high-accuracy performance in the realms of image recognition and object identification. CNNs have grown in complexity throughout time, from the simplest, LeNet-5, with five layers, to the most complex, ResNet-50, with 152 levels. They can capture secret components of the images thanks to their various hidden layers, which is the key to their success.
III. objectives
We present a unique deep learning model based on the VGG-16 and the attention module, which we believe is one of the most suitable models for CXR picture categorization. Our suggested model can capture more probable deteriorating areas in both local and global levels of CXR pictures because it combines attention and convolution module (4th pooling layer) on VGG-16. Initially, we will use a Convolutional Neural Network (CNN), in which the input pictures are processed through a succession of layers, including convolutional, pooling, flattening, and fully connected layers, before the CNN output is formed, which classifies the images. . Following the construction of CNN models from the ground up, we will attempt to fine-tune the model utilising picture augmentation techniques. As a result, we'll use one of the VGG-16 pre-trained models to categorise images and assess accuracy for both training and validation data.
IV. methodology
A. ANN (Artificial Neural Network)
Artificial neural networks are the most widely used and major way to deep learning (ANN). They are based on a model of the human brain, which is our body's most complicated organ. The human brain is made up of almost 90 billion Neurons, which are small cells. Neurons are linked together via axons and dendrites, which are nerve fibres. The primary function of an axon is to carry information from one neuron to another. Dendrites, on the other hand, serve primarily to receive information supplied by the axons of another neuron to which it is linked.. Each neuron processes a little amount of information before passing it on to another neuron, and so on. This is the main technique through which our human brain processes large amounts of data, such as voice, visual, and other types of data, and extracts meaningful information from it.
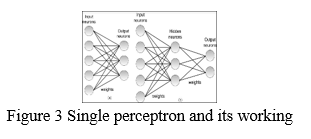
B. Perceptron
In 1958, psychologist Frank Rosenblatt developed the first Artificial Neural Network (ANN) based on this paradigm. ANNs are comparable to neurons in that they are made up of numerous nodes. The nodes are firmly linked and grouped into several hidden levels. The input layer receives the data, which is then passed via one or more hidden layers in a sequential order before being predicted by the output layer. The input may be a picture, and the output could be the object detected in the image, such as a cat. In ANN, a single neuron (called a perceptron) is represented as follows:
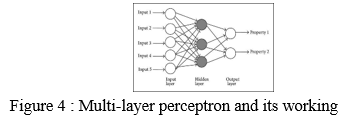
???????C. Multi-Layer Perceptron
The most basic type of ANN is the multi-layer perceptron. It has a single input layer, one or more hidden layers, and an output layer at the end. A layer is made up of a group of perceptrons. One or more aspects of the input data make up the input layer. Every hidden layer has one or more neurons that process a specific component of the feature before sending the processed data to the next hidden layer. The data from the last hidden layer is received by the output layer procedure, which then outputs the result.
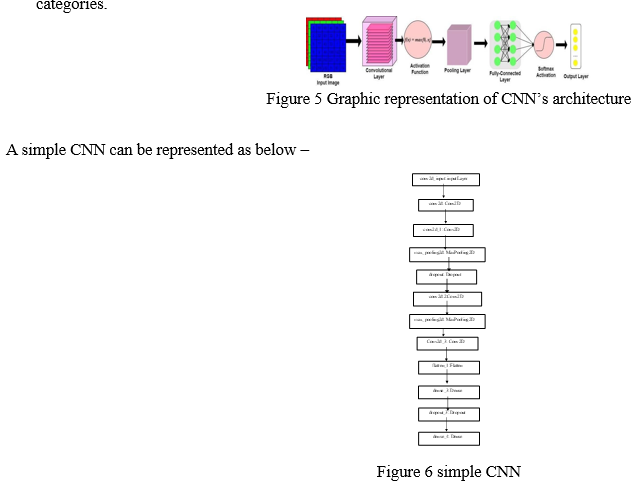
???????D. Convolutional Neural Network
One of the most common ANNs is the convolutional neural network. In the disciplines of image and video recognition, it is commonly employed. It is founded on the mathematical notion of multiplication. It's virtually identical to a multi-layer perceptron, with the exception that it has a sequence of convolution and pooling layers before the fully linked hidden neuron layer. It is made up of three layers.
- Convolution layer − It is the primary building block and perform computational tasks based on convolution function.
- Pooling layer − It is arranged next to convolution layer and is used to reduce the size of inputs by removing unnecessary information so computation can be performed faster.
- Fully connected layer − It is arranged to next to series of convolution and pooling layer and classify input into various categories.
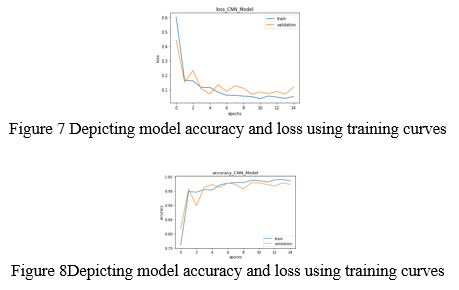
???????E. VGG-16 (Visual Geometry Group)
In their study Very Deep Convolutional Networks for Large-Scale Image Recognition, K. Simonyan and A. Zisserman from the University of Oxford introduced the VGG-16 convolutional neural network model. In ImageNet, a dataset of over 14 million pictures belonging to 1000 classes, the model achieves 92.7 percent top-5 test accuracy. It was a well-known model that was submitted to the ILSVRC-2014. It outperforms AlexNet by sequentially replacing big kernel-size filters (11 and 5 in the first and second convolutional layers, respectively) with numerous 33 kernel-size filters. VGG-16 was trained over a period of weeks using NVIDIA Titan Black GPUs.
The input to the cov1 layer is a 224 by 224 RGB picture with a fixed size. The picture is processed through such a series of convolution, each with an extremely small receptive field: 33 (the smallest size that captures the concepts of left/right, up/down, and centre). It also uses 11 convolution filters in one of the setups, which may be thought of as a linear modification of the input channels (followed by non-linearity). The convolution stride is set to 1 pixel, and the spatial padding of conv. layer input is set to 1 pixel for 33 conv. layers so that the pixel size is kept after combination. Five max-pooling layers, which follow part of the conv. layers, do spatial pooling (not all the conv. layers are followed by max-pooling). Max-pooling is done with stride 2 across a 22 pixel frame..
Following a stack of convolutional layers (of varying depth in various designs), three Fully-Connected(FC) layers are added: the first two have 4096 channels apiece, while the third performs 1000-way ILSVRC classification and hence has 1000 channels (one for each class). The soft-max layer is the last layer. In all networks, the completely linked levels are configured in the same way.
The rectification (ReLU) non-linearity is present in all buried layers. It should also be highlighted that, with the exception of one, none of the networks incorporate Local Response Normalization (LRN), which does not enhance performance on the ILSVRC dataset but increases memory consumption and computation time..
We'll use a VGG-16 pretrained model that's been trained on ImageNet weights to extract features and pass that data to a new classifier to identify photos. To get the VGG-16 model that was trained on the imagenet dataset, we need to provide weights =imagenet'. Include top = False is required to avoid downloading the pretrained model's completely linked layers.. Because the pretrained model classifier contains more than two classes, we need to add our own classifier. Our goal is to categorise the picture into two classes: COVID positive and COVID negative. After the pre - trained deep model's convolutional layers extract low-level picture characteristics like edges, lines, and blobs, the fully connected layer divides them into two groups.
V. system architecture
A. Software Implementation
It includes all of the post-sale steps necessary in getting anything to work successfully in its environment, such as evaluating specifications, installing, testing, and running.
- Python: Python is a popular high-level programming language for general-purpose applications. Guido van Rossum invented it in 1991, and the Python Software Foundation maintained it. Its syntax lets programmers to express concepts in fewer lines of code, and it was primarily built with code readability in mind. Python is a programming language that allows you to operate more quickly and efficiently with systems. We may utilise the Python language to create APIs in Pycharm IDE.
???????B. Libraries Availed
Python libraries are a collection of helpful functions that take the place of having to write code from scratch. Today, there are about 137,000 Python libraries available. Python libraries are used to create machine learning, data science, data visualisation, image and data manipulation, and other applications. The following are some useful Python libraries:
1. Keras and Tensorflow: Keras is a Python-based reinforcement learning API that runs on top of TensorFlow, a computational platform. Francois Chollet, a Google artificial intelligence researcher, came up with the idea. Keras is presently used by Google, Square, Netflix, Huawei, and Uber, among others. It was created with the goal of allowing for quick experimentation. TensorFlow 2.0 and Keras TensorFlow 2.0 is an open-source machine learning platform that runs from start to finish. It brings together four crucial talents.:
a. Executing low-level tensor operations efficiently on the CPU, GPU, or TPU.
b. Tensorflow supports distributed processing, making it possible to handle massive amounts of data, such as big data.
c. Tensorflow uses a computation graph to explain all calculation operations, no matter how basic they are.
d. Keras enables engineers and researchers to fully use TensorFlow 2.0's scalability and cross-platform capabilities; we can run Keras on TPUs or massive clusters of GPUs, and we can export Keras models to run in the web or on mobile devices.
2. NumPY and pandas: The Pandas module primarily handles tabular data, whereas the NumPy module handles numerical data. Pandas provides a collection of sophisticated tools such as DataFrame and Series that are mostly used for data analysis, whereas the NumPy module provides a powerful object known as Array.
3.Matplotlib

It's a popular Python data visualisation package that lets you make 2D graphs and plots using python scripts. Line, histogram, bar-charts, scatter plots, power spectra, error charts, and other graphs and plots are all supported.
???????C. Technology Used
Methods, processes, and equipment that are the outcome of scientific knowledge being applied to practical purposes are referred to as technology.
- Django: Django is a high-level Python web framework for building safe and maintainable websites quickly. Django is a web framework built by experienced developers that takes care of a lot of the heavy lifting so you can focus on developing your app instead of reinventing the wheel. It's free and open source, with a vibrant and active community, excellent documentation, and a variety of free and paid support options.
- Google Colab: Colab is a cloud-based Jupyter notebook environment that is free to use. Most critically, it doesn't require any setup, and the notebooks you create may be modified concurrently by your team members, much like Google Docs projects. Many common machine learning libraries are supported by Colab and can be quickly loaded into your notebook.
- CSS: CSS is a type of communication that specifies how a website markup language like HTML or XHTML is displayed, including fonts, layouts, spacing, and colours, to mention a few. CSS is a language that is used to make existing information seem more appealing; it is a language that is used to promote expressive style and creativity. One of its most popular advantages is the ability to separate document content expressed in markup languages (such as HTML) from document presentation written in CSS.
- JavaScript: Every time this happens page does both just sit there and display info for some of you to look at, such as showing timely content updates, interactive maps, animated 2D/3D graphics, scrolling video record players, and so on, JavaScript is a scripting or programming language that allows you to implement complex features on web pages..

VI. results
In the ILSVRC-2012 and ILSVRC-2013 contests, VGG-16 outperformed the previous generation of models considerably. The VGG-16 performance is also in competition with the classification task winner (GoogleLeNet with 6.7 percent error) and exceeds the ILSVRC-2013 winning entry Clarifai, which obtained 11.2 percent with external dataset and 11.7 percent without it. VGG-16 architecture delivers the greatest single-net performance (7.0 percent test error), exceeding a single Google Net by 0.9 percent..
The interface was designed with a visual notion in mind for freedom of usage, and we utilised Tkinter to construct graphical user interfaces. We picked Tkinter because Python and Tkinter together provide a quick and straightforward approach to construct graphical user interfaces. Tkinter also gives the Tk GUI toolkit a robust object-oriented interface.
A. Confusion Matrix
An N x N matrix is used to evaluate the classification results, where Denotes the number of target classes. The matrix compares the actual goal values to the machine learning model's predictions. This provides us with a comprehensive picture of how well our classification model is working and the types of errors it makes.
- The target variable has two values: Positive or Negative
- The columns represent the actual values of the target variable
- The rows represent the predicted values of the target variable

B. VGG-16 Comparison
It was shown that representation depth improves classification accuracy, and that state-of-the-art performance on the ImageNet challenge dataset can be reached using a standard ConvNet architecture with significantly enhanced depth.
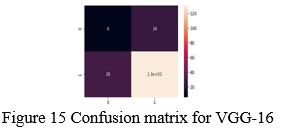
C. Results
It can be categorized into two forms:
- Confusion Matric without normalization
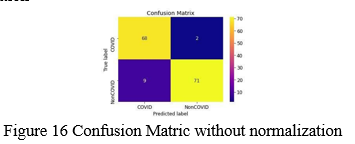
2. Confusion Matric with normalization
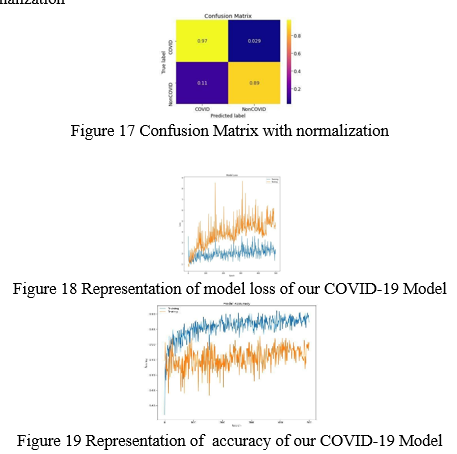
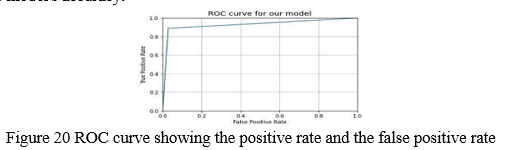 ???????
???????
Conclusion
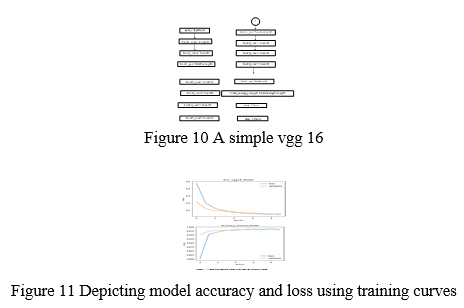
We present a deep learning-based algorithm to detect and classify COVID-19 instances from X-Ray pictures in this work. Our model has an end-to-end structure that eliminates the need for manual feature extraction. Our built system can execute binary classification tasks with a 98.40 percent accuracy. The generated model\'s performance is evaluated, and it is ready to be tested on a bigger database. Other chest-related disorders, such as TB and pneumonia, can also be diagnosed using similar models. The study\'s utilisation of a restricted number of COVID-19 X-Ray pictures is a restriction. We plan to use additional similar photos from our local hospitals to make our model more robust and accurate. Our proposed method\'s performance, on the other hand, may be enhanced further. This also helps to increase the quantity of CXR pictures, which improves our model\'s accuracy. This study backs up a viable method for enhancing health-care quality and diagnostic procedure outcomes. Although deep learning is one of the most powerful computational techniques for diagnosing COVID-19 and non-COVID patients, it is still a work in progress.
References
[1] Sitaula C, Xiang Y, Basnet A, Aryal S, Lu X (2020) Hdf: hybrid deep features for scene image representation. In: To appear in international joint conference on neural networks (IJCNN). [2] Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L (2009) ImageNet: a large-scale hierarchical image database. Proceedings of the IEEE conference on computer vision and pattern 067 recognition (CVPR). [3] Loey M, Smarandache F, M Khalifa NE (2020) Within the lack of chest COVID-19 X-Ray dataset: a novel detection model based on gan and deep transfer learning. Symmetry 12(4):651. [4] Singhal T (2020) A review of coronavirus disease-2019 (COVID- 19). Indian J Pediatr 87:1-6. [5] J. Vilar, M.L. Domingo, C. Soto, J. Cogollos Radiology of bacterial pneumonia Eur J Radiol, 51 (2) (2004),pp. 102-113. [6] Cohen JP “COVID-19 image data collection,” https://github.com/ieee 8023/covid-chestxray-dataset 2020. [7] Wu, F.; Zhao, S.; Yu, B.; Chen, Y.M.; Wang, W.; Song, Z.G.; Hu, Y.; Tao, Z.W.; Tian, J.H.; Pei, Y.Y.; et al. A new coronavirus associated with human respiratory disease in China. Nature 2020, 579, 265–269. [8] Chowdhury, N.K.; Rahman, M.M.; Kabir, M.A. PDCOVIDNet: A parallel-dilated convolutional neural network architecture for detecting COVID-19 from chest X-Ray images. Health Inf. Sci. Syst. 2020, 8, 1–14. [9] Martinez, F.; Martínez, F.; Jacinto, E. Performance evaluation of the NASNet convolutional network in the automatic identification of COVID-19. Int. J. Adv. Sci. Eng. Inform. Technol. 2020, 10, 662. [10] S. A, et al. Duration of infectiousness and correlation with RT-PCR cycle threshold values in cases of COVID-19, England, January to May 2020 Euro Surveill, 25 (32) (2020). [11] D. Ezzat, H. A. Ella et al., “Gsa-densenet121-COVID-19: a hybrid deep learning architecture for the diagnosis of COVID-19 disease based on gravitational search optimization algorithm,” arXiv preprint arXiv:2004.05084, 2020. [12] U. Özkaya, ?. Öztürk, M. Barstugan Coronavirus (COVID-19) classific- ation using deep features fusion and ranking technique (2020), pp. 281- 295. [13] A. Khan, J.A. Doucette, R. Cohen, D.J. Lizotte Integrating machine learning into a medical decision support system to address the problem of missing patient data Proc. - 2012 11th int. Conf. Mach. Learn. Appl, 1, ICMLA (2012), pp. 454-457. [14] S.M. Sasubilli, A. Kumar, V. Dutt Machine learning implementation on medical domain to identify disease insights using TMS Proc. 2020 Int. Conf. Adv. Comput. Commun. Eng. ICACCE (2020).
Copyright
Copyright © 2022 Sheikh Raheela Gaffar, Ankur Gupta. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40520
Publish Date : 2022-02-25
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online