

Ijraset Journal For Research in Applied Science and Engineering Technology
Detection of Cyber bullying on Social Media Using Machine Learning
Authors: Sara Kangane, Priyanka Thorat, Sejal Indalkar, Pratiksha Yewale, Disha Deotale
DOI Link: https://doi.org/10.22214/ijraset.2022.44094
Certificate: View Certificate
Abstract
In the modern era, the usage of the internet has increased tremendously which in turn has led to the evolution of large amounts of data. Cyber world has its own pros and cons. One of the alarming situations in web 4.0 is cyber bullying, a type of cyber-crime. When bullying occurs online with the aid of technology it is known as cyber bullying. This research paper has surveyed the work done by 30 different researchers on cyber bullying, and elaborated on different methodologies adopted by them for the detection of bullying. Three types of features namely textual, behavioral and demographic features are extracted from the dataset as compared to earlier study over the same dataset where only textual features were considered. Textual features include certain bullying words that if exists within the text may lead to a true outcome for cyber bullying. Personality trait features are extracted for the user if it is involved once in bullying may bully in future too. While demographic features extracted from the dataset include age, gender and location. The system is evaluated through different performance measures for both classifiers used and the performance of the Support Vector Machine classifier is found better than the Bernoulli NB with overall 87.14 accuracy.
Introduction
I. INTRODUCTION
Across the globe due to the tremendous increase in the availability of data services, addiction of social media among society has increased proportionally. Just like other countries, India has also witnessed a drastic rise in cyber bullying. In this era of web 4.0 where people live on digital and online platforms, it is very difficult to protect society from the alarming rise in cyber-crime. It has been surveyed that the major victims of cyberbullying are adolescents. Different cyber bullying attacks that are performed by attackers are: (1) Sending or posting hateful or abusive comments with an intention to harm the character of an individual (2) Posting an inappropriate image or video. (3) Creation of a false or improper website. (4) Issuing Online threats that cause a person to kill themselves or injure another person. (5) Triggering online religious, racial, ethnic or political hatred by posting hate comments. Because of the tremendous increase in the availability of data services around the world, social media addiction in society has increased proportionally. It is extremely difficult to protect society from the alarming rise in cyber-crime in this era of web 4.0, where people live on digital and online platforms. According to surveys, adolescents are the most common victims of cyberbullying. The following are examples of cyberbullying attacks carried out by attackers: (1) sending or posting hateful or abusive comments with the intent to harm an individual's character (2) Posting an offensive image or video. (3) Creating a false or inappropriate website. (4) Making online threats that cause someone to kill themselves or injure someone else. (5) Inciting religious, racial, ethnic, or political hatred online through the posting of hateful comments or videos.
II. RELATED WORK
Cyberbullying is a persistent problem in Saudi schools, exacerbated by the advancement of digital technology and its pervasive presence in almost every societal aspect. With such technologies, it is unsurprising that harassment has spread to the virtual world of teenagers, where it is rampant. The intensity and outcome measures of this phenomenon have alarmed interested parties, but researchers who examined the causes and motivating factors behind cyberspace bullying participation are few and far between. 2 The Theory of Planned Behavior, a well-known theory, was used to examine this issue (TPB). This study specifically looked at the effects of attitudes, normative beliefs, subjective norms, and perceived behavioral control/self-efficacy on cyberbullying intentions and expected societal outcomes. 1The study distributed 395 questionnaires to Saudi high school students from the ninth to the twelfth grades. The collected data were subjected to multiple linear regressions, with the results revealing that behavioral attitudes, social norms, perceived behavioral controls, social media use, a lack of parental controls, and a lack of regulations all had a direct effect on intentions to interact in cyberbullying. The findings also revealed that cyberbullying intentions had a direct impact on student academic performance.
This study adds to our understanding of students' intentions toward cyberbullying and the relationship between the Theory of Planned (TPB) variables and the predictive utility model. Finally, the findings of this study can be used to develop prevention and intervention strategies, which have many implications for theory, practice, and policy.
Cybercrime refers to any crime committed using the internet as an access medium and using an electronic device such as a computer or a mobile phone. The main factors limiting previous research in cyberbullying detection have been a lack of datasets, predators' hidden identities, and victims' privacy. Taking these factors into account, an effective text mining approach based on machine learning algorithms is proposed for proactively detecting bullying text. The dataset gathered from myspace.com and Perverted-Justice.com was being used to assess the system's performance. When compared to a previous study on the same dataset that only considered textual features, three types of features are extracted from the dataset: textual, behavioral, and demographic features. Age, gender, and location are among the demographic features extracted from the dataset. The system is evaluated using various performance measures for both classifiers used, and the performance of the Support Vector Machine classifier is found to be better than the Bernoulli NB with an overall accuracy of 87.51.
III. SYSTEM ARCHITECTURE
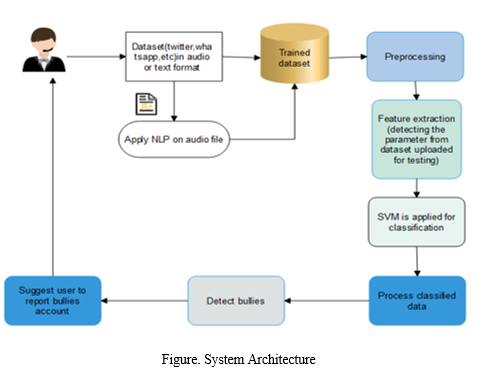
IV. METHODOLOGY
- Dataset: A dataset is a bunch of data. An informational collection is many times the items in a binary data set table or measurable information lattice, where every section of the table addresses a particular variable and each column addresses a particular individual from the informational collection being referred to. For every individual from the informational collection, the informational collection records values for every one of the factors, like an item's level and weight. Each worth is alluded to as a datum. The informational collection might incorporate information for at least one individual, with the number of columns compared to the number of individuals. Every one of our information is kept here as CSV documents. A comma isolated values (CSV) document is a text record that utilizes a comma to isolate values in figuring. A CSV record is a plain text document that contains even information (numbers and text). An information record is addressed by each line in the document. Each record has at least one field, which is isolated by commas. The name for this record design comes from the utilization of the comma as a field separator. Our information is coordinated in a success accounting sheet with values like date, open, high, low, last, low, all-out exchange, and turnover.
- Data Preprocessing: is a significant stage in AI drives. Data gathering approaches are generally uncontrolled, coming about in out-of-range regards, missing properties, and different issues. Taking apart information that hasn't been completely examined for such imperfections can prompt incorrect ends. Thus, preceding running an assessment, the depiction and nature of data are basic. Data readiness is every now and again the most tedious component of an AI project, particularly on account of computational information. In the event that there is a ton of irrelevant and overabundant information present, or on the other hand on the off chance that there is a great deal of boisterous and deceitful data, data disclosure during the readiness stage will be more troublesome. The techniques of data readiness and detachment can consume a large chunk of the day to finish. Cleaning, case choice, normalization, change, incorporating extraction and determination, etc are instances of information planning. The last preparation set is the consequence of information preprocessing.
- Feature Scaling: Include scaling is a methodology for normalizing the scope of free factors or data things. It's otherwise called information normalization in information planning, and it's generally done during the data preprocessing step. Objective abilities won't proceed as arranged without normalization in light of the fact that the extent of potential gains of unrefined information fluctuates broadly. In this vein, the extension ought to be normalized, all the other things being equivalent, to such an extent that every part contributes generally similar to the last distance. One more justification behind part scaling is that slant plunge joins a lot quicker with highlight scaling than it manages without it.
V. EXPERIMENTAL RESULTS
A. Home Page


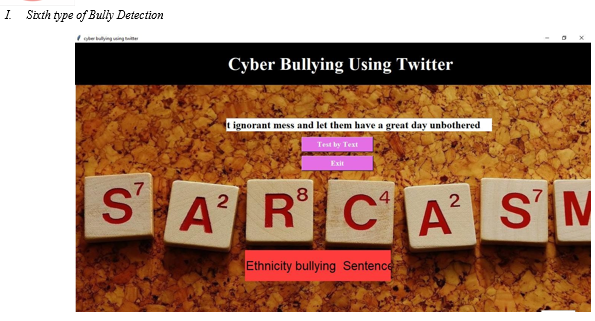
Conclusion
The above paper proposes a system for detecting Hindi and English tweets in Twitter. Because cyberbullying is highly dependent and contextual, sentiment and other contextual clues can help detect it. The system uses sarcastic tweets, not a data source of 9,104 cyberbullying tweets. The system uses LR. The approach has shown good results, with the LR classifier being more accurate than others. The extracted patterns do not cover all sarcastic detection patterns. The survey concluded that traditional machine learning algorithms cannot handle the massive amounts of data generated by Web 4.0, nor can cyber bullying content be accurately detected. Many researchers have recently become interested in Deep Learning, NLP, CNN, and stacked auto-encoders. Future research can use deep learning to detect cyberbullying in social media. Cyberbullying is a hotly debated topic. It is an emerging issue in Web 4.0. After reviewing 30 research papers, it was discovered that there is a lack of proper dataset, and that integrating social, contextual, and sentiment features can improve the monitoring of bullying content. Aside from text, images and video must be recommended for future careers.
References
[1] 1 Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” Pattern Analysis and Machine Intelligence, IEEE Transactions on, vol. 35, no. 8, pp. 1798–1828, 2013 [2] 2 A. M. Kaplan and M. Heinlein, “Users of the world, unite! The challenges and opportunities of social media,” Business horizons, vol. 53, no. 1, pp. 59–68, 2010. [3] 4 B. K. Biggs, J. M. Nelson, and M. L. Sampilo, “Peer relations in the anxiety–depression link: Test of a mediation model,” Anxiety, Stress, Coping, vol. 23, no. 4, pp. 431–447, 2010. [4] 5 K. Dinakar, B. Jones, C. Havasi, H. Lieberman, and R. Picard.” Common sense reasoning for detection, prevention, and mitigation of cyberbullying.” ACM Transactions on Interactive Intelligent Systems (TiiS) 2, no. 3, 2012, p. 18. [5] 6 V. Nahar, S. Unankard, X. Li, and C. Pang.” Sentiment analysis for effective detection of cyberbullying.” In Asia-Pacific Web Conference, Springer, Berlin, Heidelberg, 2012, pp. 767-774. [6] 7 V. Nahar, X. Li, C. Pang, and Y. Zhang.” Cyberbullying detection based on text-stream classification.” In The 11th Aust ralasian Data Mining Conference (AusDM 2013), 2013. [7] 8 M. Dadvar, D. Trieschnigg, R. Ordelman, and F. de Jong.” Improving cyberbullying detection with user context .” In European Conference on Information Retrieval, Springer, Berlin, Heidelberg, 2013, pp. 693-696.
Copyright
Copyright © 2022 Sara Kangane, Priyanka Thorat, Sejal Indalkar, Pratiksha Yewale, Disha Deotale. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44094
Publish Date : 2022-06-11
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online