

Ijraset Journal For Research in Applied Science and Engineering Technology
Detection of Fake Product Review using Machine Learning Techniques
Authors: Menaka. S, Gowthami. S, Sakthi. V, Saranya. G, Valarmathi. S, Vijayalakshmi. V
DOI Link: https://doi.org/10.22214/ijraset.2023.51761
Certificate: View Certificate
Abstract
Online reviews play a crucial role in determining whether a product will be sold on e-commerce websites or applications. Because so many people rely on online reviews, unethical actors may create reviews in order to artificially boost or devalue goods and services. This study presents a semi-supervised machine learning strategy to identify fake product reviews. In addition, this work extracts several reviewer behaviours using feature engineering techniques. In this work, we investigate the findings of several experiments on a genuine food review dataset of restaurant evaluations with features gathered from user behaviour. The results show that Random Forest, with the best f-score of 98%, outperforms another classifier in terms of off-score. The data also shows that accounting for the reviewers\' behavioural traits boosts the f-score, and the final accuracy came out at 97.7%. The behaviour of different types of reviewers has not been taken into account in the existing methodology. The effectiveness of the proposed fake review detecting algorithm will be further enhanced by the addition of other low-level data, such as frequent time or date dependency, the timing of the reviewer\'s delivery of a review, and how typical it is to supply favourable or unfavourable reviews.
Introduction
I. INTRODUCTION
Reviews are progressively used by individuals and groups for making decision with respect to purchase and for scalable marketing and design of the online product. Appreciative opinions often mean better income, sale and fame for the specific business or individual selling that product and hence this gives a reason for individuals and/or group spammers to post phony reviews for the purpose of promotion or demotion of specific products. Such individuals that do such malpractice are called opinion spammers and their activities are called opinion spamming. In the past few years, several techniques have been used to detect such opinion spammers. Most approaches that have been proposed rely on supervised machine learning techniques and on distinct characteristics. In this paper, there is a survey of almost 20 research papers and 5 survey papers and a comparison of the various techniques used by the different authors for detection of spam reviews based on different parameters & we then propose our method to detect such opinion spammers by using machine learning algorithms such as SVM, Naïve-Bayes and maximum entropy and also using some neural networks such as recurrent neural network, RNN-long short term learning etc. The data-set that is to be used will be pre-processed to convert it into the suitable format so as to provide it as input for the different algorithms. The results obtained from this will show the effectiveness of each of the methods and will Also provide us with the most efficient, reliable and accurate model.
II. RELATED WORKS
A. Collective Opinion Spam Detection: Bridging Review Networks and Metadata
S. Rayana and L. Akoglu [1] Online reviews capture the testimonials of “real” people and help shape the decisions of other consumers. Due to the financial gains associated with positive reviews, however, opinion spam has become a widespread problem, with often paid spam reviewers writing fake reviews to unjustly promote or demote certain products (or businesses). Current approaches have successfully but separately utilized linguistic clues associated with deception, behavioural footprints, or relational ties between agents in a review system, to unearth suspicious reviews, users, or user groups. In this work, we propose a new holistic approach called SpEagle that utilizes clues from all of metadata (text, timestamp, rating) as well as relational data (network), and harness them collectively under a unified framework to spot suspicious users and reviews, as well as targeted products of spam. Moreover, our method can efficiently and seamlessly integrate semi-supervision, i.e., a (small) set of labels if available, without requiring any training or changes in its underlying algorithm.
We demonstrate the effectiveness and scalability of SpEagle on three real-world review datasets from Yelp.com with filtered (spam) and recommended (no spam) reviews, where it significantly outperforms several baselines and state-of-the-art methods. To the best of our knowledge, this is the largest scale quantitative evaluation performed to date for the opinion spam problem.
B. Spotting Collective Behaviour of online Frauds in Customer Reviews
S. Dhawan, S. C. R. Gangireddy, S. Kumar, and T. Chakraborty [2] Online reviews play a crucial role in deciding the quality before purchasing any product. Unfortunately, spammers often take advantage of online review forums by writing fraud reviews to promote/demote certain products. It may turn out to be more detrimental when such spammers collude and collectively inject spam reviews as they can take complete control of users' sentiment due to the volume of fraud reviews they inject. Group spam detection is thus more challenging than individual-level fraud detection due to unclear definition of a group, variation of inter-group dynamics, scarcity of labelled group-level spam data, etc.Here, we propose defrauder, an unsupervised method to detect online fraud reviewer groups. It first detects candidate fraud groups by leveraging the underlying product review graph and incorporating several behavioural signals which model multi-faceted collaboration among reviewers. It then maps reviewers into an embedding space and assigns a spam score to each group such that groups comprising spammers with highly similar behavioural traits achieve high spam score. While comparing with five baselines on four real-world datasets (two of them were curated by us), Defrauder shows superior performance by outperforming the best baseline with 17.11% higher NDCG@50 (on average) across datasets.
C. Simultaneously detecting fake reviews and review spammers using factor graph model
Y. Lu, L. Zhang, Y. Xiao, and Y. Li [3]
Review spamming is quite common on many online shopping platforms like Amazon. Previous attempts for fake review and spammer detection use features of reviewer behaviour, rating, and review content. However, to the best of our knowledge, there is no work capable of detecting fake reviews and review spammers at the same time. In this paper, we propose an algorithm to achieve the two goals simultaneously. By defining features to describe each review and reviewer, a Review Factor Graph model is proposed to incorporate all the features and to leverage belief propagation between reviews and reviewers. Experimental results show that our algorithm outperforms all of the other baseline methods significantly with respect to both efficiency and accuracy.
D. Spotting Fake Reviewer Groups in Consumer Reviews
A. Mukherjee, B. Liu, and N. Glance [4] Opinionated social media such as product reviews are now widely used by individuals and organizations for their decision making. However, due to the reason of profit or fame, people try to game the system by opinion spamming (e.g., writing fake reviews) to promote or demote some target products. For reviews to reflect genuine user experiences and opinions, such spam reviews should be detected. Prior works on opinion spam focused on detecting fake reviews and individual fake reviewers. However, a fake reviewer group (a group of reviewers who work collaboratively to write fake reviews) is even more damaging as they can take total control of the sentiment on the target product due to its size. This paper studies spam detection in the collaborative setting, i.e., to discover fake reviewer groups. The proposed method first uses a frequent itemset mining method to find a set of candidate groups. It then uses several behavioural models derived from the collusion phenomenon among fake reviewers and relation models based on the relationships among groups, individual reviewers, and products they reviewed to detect fake reviewer groups. Additionally, we also built a labelled dataset of fake reviewer groups. Although labelling individual fake reviews and reviewers is very hard, to our surprise labelling fake reviewer groups is much easier. We also note that the proposed technique departs from the traditional supervised learning approach for spam detection because of the inherent nature of our problem which makes the classic supervised learning approach less effective. Experimental results show that the proposed method outperforms multiple strong baselines including the state-of-the-art supervised classification, regression, and learning to rank algorithms.
E. Understanding Deja reviewers
Gilbert and K. Karahalios [5] People who review products on the web invest considerable time and energy in what they write. So why would someone write a review that restates earlier reviews? Our work looks to answer this question. In this paper, we present a mixed-method study of Deja reviewers, latecomers who echo what other people said. We analyze nearly 100,000 Amazon.com reviews for signs of repetition and find that roughly 10-15% of reviews substantially resemble previous ones. Using these algorithmically-identified reviews as centerpieces for discussion, we interviewed reviewers to understand their motives.
An overwhelming number of reviews partially explains Deja reviews, but deeper factors revolving around an individual's status in the community are also at work. The paper concludes by introducing a new idea inspired by our findings: a self-aware community that nudges members toward community-wide goals. Gilbert and Karahalios analysed the one million reviews available on Amazon's website and found that nearly 15% of reviews were similar to earlier product reviews. Rule-based fake review detection means to manually make corresponding feature rules and conduct fake review detection based on professional knowledge and experience. Gilbert found similar reviews and repeated users through comprehensive evaluation of content and user characteristics.
A. Advantages
- The system is very fast and effective due to semi-supervised and supervised learning.
- Accuracy result
- Time consumption.
- Easy to identify the reviews fake or original
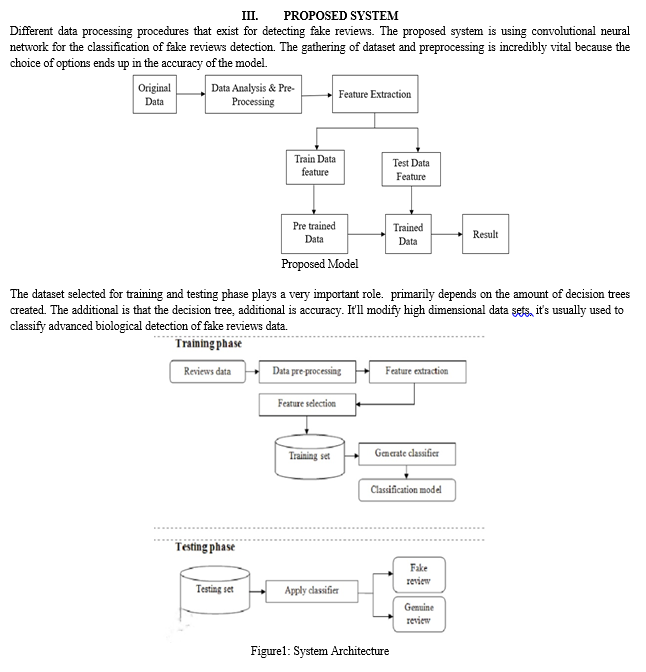
IV. MODULE DESCRIPTION
A. List Of Modules
- Data Preprocessing
- Dataset splitting
- Model training
- Implementation Methodology
- Processing
- Text Preprocessing
- Result Analysis
B. Module Descriptions
Detecting fake product reviews can be a challenging task since they often appear genuine and are written to deceive readers. However, there are several methods that can be used to identify fake product reviews. Here are some approaches:
- Data Preprocessing
Preprocessing is used to transform unstructured data into a structured data that is suitable for machine learning. A data analyst can use an applied machine learning model to obtain more precise results by using structured and clean data. The method involves data formatting, cleaning, and sampling.
2. Dataset Preprocessing
Three subsets—training, test, and validation sets should be developed from a dataset used for machine learning. A training set is to train a model and provide the best parameters that it should learn from data, a data scientist utilizes a training set. Test set is to assess the trained model's generalization capabilities, a test set is required. The latter refers to a model's capacity, following training over training data, to identify patterns in fresh, previously unobserved data. To prevent model overfitting, which causes the lack of generalizations as discussed above, so it is essential to employ separate subsets for training and testing.
3. Model Training
The goal of model training is to develop a model, which can be achieved by "feeding" the algorithm with training data. An algorithm will process data and output a model that is able to find a target value (attribute) in new data and an answer you want to analyse with predictive analysis.
4.. Implementation Methodology
The proposal for work is implemented in Python 3.6.4 with the required libraries scikit-learn, pandas, matplotlib, and others as well. We downloaded the data set from yelp.com. The data package includes very different train and test sets with four kinds of labels, false and real. The train dataset is referred to as the train set, and the test dataset is referred to as the test set. Machine learning algorithms including Naive Bayes, SVM, logistic regression, and random forest are implemented.
5. Processing
Many real-world databases contain inconsistent and disruptive information. The reasons for this is that data is frequently gathered from various and diverse sources. Inaccurate results are produced by data mining because of data inconsistency. Before completing the data mining process, Preprocessing the data is a crucial step. Preprocessing techniques include cleaning, attribute reduction, tokenization, stop words removal, lemmatization, and stemming (Y. Sun, Kamel, Wong, & Wang, 2007). The research of the project uses both text Preprocessing and data Preprocessing techniques.
6. Text Preprocessing
Data mining techniques are utilized in text Preprocessing to transform unstructured
information. On this particular dataset, a few text Preprocessing techniques are defined as follows:
Tokenization: Tokenization is the process of dividing the review content into tokens of words. To put it another way, review content is tokenized. Tokenization is a crucial step to segregate each word in review for the purposes of calculating RCS and capital diversity.
Lemmatization: The process of lemmatizing involves changing a word as it related to its morphological root, for example, "bought" is lemmatized into "buy."
7. Result Analysis
Considering the significance of particular features for training a model to detect fake reviews, experiments were undertaken with a variety of behavioural and contextual feature sets. In addition to these three alternative term evaluating techniques, we compared the outcomes of several feature sets on Naive and RF. As a result of initial studies examining the interaction between "Review Deviation" and other behavioural and contextual factors, it has been determined that adding a new feature increases accuracy. While the conclusion based on our experimental findings indicates that scalability of the dataset can improve classification accuracy.
Combining these approaches can help to improve the accuracy of fake product review detection. It's worth noting that no method is fool proof, and fake reviewers are constantly evolving their tactics to avoid detection.
V. RESULT & EVOLUTION METRICS
The evolution of metrics for fake product review detection using machine learning techniques has improved over time due to the availability of larger and more diverse datasets, the development of more sophisticated machine learning algorithms, and the use of more advanced evaluation techniques such as cross-validation and ensemble methods.

VI. FUTURE ENHANCEMENTS
For future developments, a web application can be designed which makes the process of finding out fake reviews easier. Every user will be given an account through which they can write reviews for various products. The app would automatically filter out fake reviews based on the proposed deep Learning algorithm. Eventually, customer will get rid of fake reviews present in online shopping websites.
Conclusion
This project presented an extensive survey of the most notable works to date on machine learning-based fake review detection. Firstly, we have reviewed the feature extraction approaches used by many researchers. Then, we detailed the existing datasets with their construction methods. Then, we outlined some traditional machine learning models and neural network models applied for fake review detection with summary tables. Traditional statistical machine learning enhances text classification model performance by improving the feature extraction and classifier design.
References
[1] S. Rayana and L. Akoglu “Collective opinion spam detection: Bridging review networks and metadata”. [2] S. Dhawan, S. C. R. Gangireddy, S. Kumar, and T. Chakraborty “Spotting collective behaviour of online frauds in customer reviews”. [3] Y. Lu, L. Zhang, Y. Xiao, and Y. Li “Simultaneously detecting fake reviews and review spammers using factor graph model”. [4] A. Mukherjee, B. Liu, and N. Glance “Spotting fake reviewer groups in consumer reviews”. [5] Elshrif Elmurngi, Abdelouahed Gherbi , \"Detecting Fake Reviews through Sentiment Analysis Using Machine Learning Techniques” [6] Rakibul Hassan , Md. Rabiul Islam, \"Detection of Fake Online Reviews Using Semi-supervised and supervised learning\" (IEEE-2019) [7] Satuluri Vanaja, Meena Belwal, \"Aspect – Level Sentiment Analysis on E-Commerce Data\" (IEEE – 2018) [8] Kamal Nigam, John Lafferty, Andrew McCallum, \"Using Maximum Entropy for Text Classification\" [9] Seema Sharma, Jitendra Agarwal, Shikha Agarwal, Sanjeev Sharma, “Machine Learning Techniques for Data Mining : ASurvey” [10] Zhuo Wang,Tingting Hou,Zhun Li,Dawei Song, \"Fake Reviewers using Product Review Graph\" (Research Gate-2015) [11] Bing Liu,Junhui Wang,Natalie Glance,N.Jindal, \"Detecting Group Review Spams\"(20th conference of WWW-2011) [12] Chetna Pujari, Aiswarya and Nisha P.Shetty, \"Comparison of Classification Techniques for Sentiment Analysis of Product Review Data\" (Springer – 2018) [13] Yuming Lin, Tao Zhu, Hao Wu, Jingwei Zhang, Xiaoling Wang,Aoying Zhou, \"Towards Online Anti-Opinion Spam: Spotting Fake Reviews from the Review sequence\" [14] Alex Gravesa, Jurgen Schmidhuber, \"Framewise phoneme classification with bidirectional LSTM and other neural network architectures\" [15] Yafeng Ren, Donghong Ji, \"Neural Networks for deceptive opinion spam detection\" ELSEVIER (2017) [16] Chih-Chien Wang, Min-Yuh Day, Chien-Chang Chen, Jia-Wei Liou,\"Detecting Spamming Reviews Using Long Short-term Memory Recurrent Neural Network Framework\" [17] Minlie Huang, Yujie Cao, Chao Dong, \"Modeling Rich Contexts for Sentiment Classification with LTSM\" (ResearchGate – 2016) [18] Y. Wang, J. Zhang, \"Keyword extraction from online product reviews based on bi-directional LSTM recurrent neural network\" [19] Sherry Girgis, Eslam Amer, Mahmoud Gadallah, \"Deep Learning Algorithms for Detecting Fake News in Online Text\" (IEEE-2018) [20] Chengai Sun, Qiaolin Du,and Gang Tian, \"Exploiting Product Review Features for Fake Review Detection\". [21] Huayi Li,Bing Liu,Jidong Shao, \"Spotting Fake Reviews using positive-unlabelled learning\" (Scielo 2014) [22] Hasim Sak,Andrew Senior,Francoise Beaufays, \"Long Short term memory recurrent neural network architectures for large scale aucoustic modelling\" (Conference of annual speech communication associaition-2014) [23] Wenpeng Yiny, Katharina Kanny, Mo Yuz and Hinrich Sch ? utzey,\"Comparative Study of CNN and RNN for Natural Language Processing\". [24] J. C. S. Reis, A. Correia, F. Murai, A. Veloso, and F. Benevenuto, “Supervised Learning for Fake News Detection,” IEEE Intelligent Systems, vol. 34, no. 2, pp. 76-81, May 2019. [25] N. O’Brien, “Machine Learning for Detection of Fake News,” [Online]. [Accessed: November 2018]. [26] B. Wagh, J. V. Shinde and P. A. Kale, “A Twitter Sentiment Analysis Using NLTK and Machine Learning Techniques,” International Journal of Emerging Research in Management and Technology, vol. 6, no. 12, pp. 37- 44, December 2017. [27] Duyu Tang,Bing Qin, Ting Liu, \"Document Modelling with Gated Recurrent Neural Network for sentiment Classification\" (Conference on Emperical Methods-2015). [28] J. Li, M. Ott, C. Cardie and E. Hovy, “Towards a General Rule for Identifying Deceptive Opinion Spam,” in Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, vol. 1, no. 11, pp. 1566-1576, November 2014.
Copyright
Copyright © 2023 Menaka. S, Gowthami. S, Sakthi. V, Saranya. G, Valarmathi. S, Vijayalakshmi. V. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET51761
Publish Date : 2023-05-07
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online