

Ijraset Journal For Research in Applied Science and Engineering Technology
Diabetic Retinopathy Detection using Convolutional Neural Networks
Authors: Vedant Narendra Joshi, Mehul Rajendra Gujar, Siddhant Rahul Chaudhary, Sanat Pradeep Paranjape, Jagruti Wagh
DOI Link: https://doi.org/10.22214/ijraset.2022.43006
Certificate: View Certificate
Abstract
Diabetic Retinopathy is a medical disorder in which diabetes mellitus causes damage to the retina. Diabetic Retinopathy is diagnosed using coloured fundus pictures, which requires trained clinicians to recognise the presence and importance of several tiny characteristics, making it a time-consuming task. We present a CNN-based technique to detect Diabetic Retinopathy in fundus pictures in this research. A new segmentation strategy using Gabor filters is employed to prepare the data used to train the model. Data augmentation is used to gather enough data to train the model due to the short dataset. Intricate characteristics in fundus images are detected by our segmentation model, which also detects the presence of DR. The model is efficiently trained using a high-end Graphics Processor Unit (GPU).
Introduction
I. INTRODUCTION
Diabetic Retinopathy is a consequence of diabetes that affects the eyes. Damaged blood vessels in the retina, a light-sensitive tissue, are the primary cause of DR. Patients with Type 1 or Type 2 diabetes are more likely to have this condition. If the patient has a long-term case of diabetes and the blood sugar level is not regulated consistently, the odds of this issue developing in the eye increase. Diabetic Retinopathy is one of the most common causes of blindness in the Western countries. Preventing Diabetic Retinopathy has found to be quite beneficial when people with diabetes are monitored regularly. This process is shown to be essential if Diabetic Retinopathy is discovered in its early stages due to the availability of treatment. Diabetic Retinopathy, the main cause of blindness among working-age adults, affects millions of individuals.
The Aravind Eye Hospital in India wants to diagnose and prevent this condition in rural areas where medical screening is difficult. The classification of Diabetic Retinopathy is heavily influenced by the weighting and position of various characteristics. When performed by clinicians, the task takes a long time. Computers are employed to assist physicians in real-time, and if properly taught, they can make faster classifications. The efficacy of automated grading for Diabetic Retinopathy has been a widely discussed topic in computer imaging research, with promising results [1][2].
Convolutional Neural Networks (CNNs), a subset of deep learning, have a long history of use in image processing and interpretation, particularly medical imaging. In the 1970s, network architectures designed to cope with picture data were routinely created with beneficial applications, outperforming other approaches to difficult jobs such as handwritten character recognition. However, it wasn't until the implementation of dropout, rectified linear units, and the associated rise in computational capacity through graphics processor units (GPUs) that neural networks became practical for more sophisticated image recognition applications. Large CNNs are currently being used to successfully tackle highly complicated picture identification challenges involving multiple object classes. We present a deep learning-based CNN technique for detecting Diabetic Retinopathy in fundus pictures in this research. For better model training, we also created a new segmentation approach for blood vessel segmentation. This has been a topic of discussion in previous studies because it is a diagnostically relevant medical imaging task. Image Augmentation methods are used on the photos to increase the dataset to compensate for the low number of images in the training dataset. More photos also resulted in higher training results.
II. RELATED DATA
The data for this research study came from the Kaggle-hosted APTOS 2019 Blindness Detection Competition. The data set includes 3,662 RGB images of fundus images that have been classified into five levels of DR. To train the model faster, the image is pre-processed. Data segmentation is used in the preprocessing stage to emphasise the blood vessel in the fundus images. Because the data is insufficient, it is supplemented to enhance the dataset's size. The data is split into two groups: 2,930 photos for training and 732 images for validation.
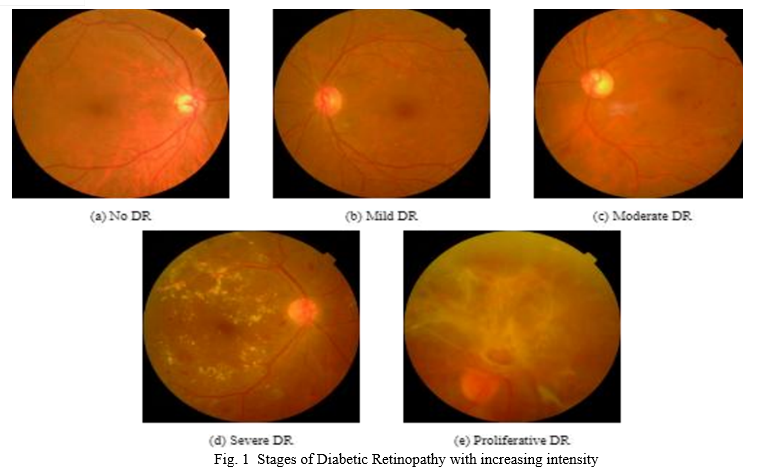
III. PROPOSED METHODOLOGY
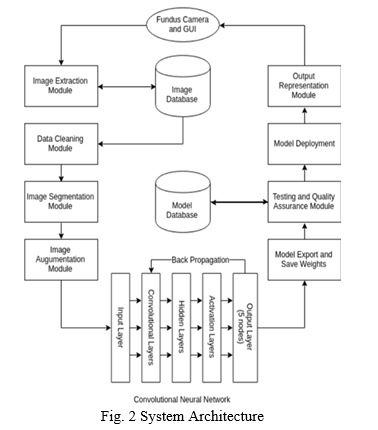
The proposed architecture for the implemented work consists primarily of five steps: loading data, image segmentation, data augmentation, model training, and model saving. The above-mentioned system architecture has been shown in the following flowchart in Fig. 2.
A. Loading the Dataset
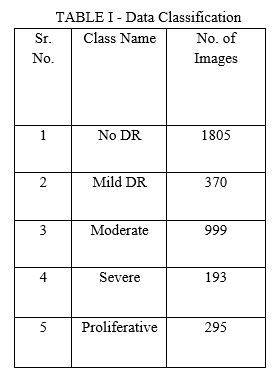
Kaggle provided the dataset, which included 3,662 fundus photos in total. The dataset is separated into two parts: a Training Set with 2930 photos and a Validation Set with 732 images for training and evaluation. Table-I shows the categorical classification of the photographs, which is divided into five groups.
B. Segmentation
The importance of blood vessels in identifying Diabetic Retinopathy in the retina has long been recognised. Before a computer-aided diagnosis approach can be employed, the retinal vascular tree must be segmented. To better the blood vessel anatomy in the retina, a segmentation module is applied.
By highlighting the blood vessels in the retina, the segmentation module improves the model's accuracy. Any image classification problem necessitates segmentation, which helps any image classification model train and classify better.
Previous research has employed U-NET, a type of Convolutional Neural Network, to segment blood vessels in the retina [3]. This network cannot be employed in this study since it requires segmented retinal photos for training, which are not available in this dataset, and segmenting the image manually is a time-consuming task.
Another proposed effort [4] is a fully convolutional AlexNet for retinal vascular segmentation. The STARE dataset, which contains previously segmented training data, was also suggested as a good fit for this type of network. An ensemble classification-based technique for retinal blood vessel segmentation is also reported [5].
We provide a new architecture for segmenting blood vessels in the retina generated from fundus images, as there has been no segmentation module in previous research for DR classification using this dataset. In our research, we use a combination of transformations and filters to acquire a good enough segmentation to train the model. The Open-Source Computer Vision Library (CV2) in Python is used to do all of the following modifications.
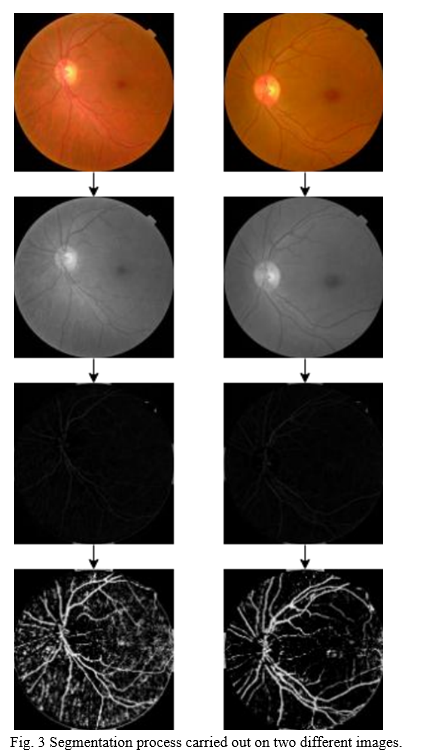
The segmentation module goes through the steps below, with the results given in Figure 3.
- Convert the image to grayscale: The original image is three-dimensional. We convert the image to grayscale to reduce the complexity, resulting in a one-dimensional image.
- Apply Gabor Filtering: Gabor Filters are used to detect specific frequency pixels in a picture. Gabor filters are mostly employed in image texture analysis [6].
- Apply Thresholding: Thresholding is used to create binary pixels. The threshold is applied according to a certain value of the threshold. Thresholding is a technique for converting grayscale to binary images.
- Apply Opening Morphological Transformations: This transformation is used to reduce noise from the final image. Erosion and dilation are the only two steps in the opening morphological transformation.
C. Augmentation
The model cannot be properly trained using the original pre-processed pictures. To enhance the number of images, augmentation techniques such as rotation, zoom, horizontal flip, vertical flip, blurring, brightness, and saturation are applied to all images. The ImageDataGenerator in the Keras Preprocessing Library was used to generate all of the parameter values at random. The data is supplemented, resulting in a training dataset with 14,650 photos and a validation dataset with 3,660 images.
D. Training the Model
After exploring other CNN models, we chose the multiclass InceptionV3 architecture for our training. Our neural network's ability to learn deeper features is improved by adding more convolutional layers. InceptionV3 is a commonly used image recognition model that has been demonstrated to attain high accuracy on the ImageNet dataset [7]. The network contains 48 layers and uses the SoftMax activation function to forecast our classification. The learning rate was kept at 0.0005 and batch normalisation was conducted. The network is additionally initialised with Gaussian initialization to reduce initial training time. The network is trained over 200 epochs to attain the documented accuracy.
IV. RESULTS
3,660 pictures from the collection were saved for validation purposes. In this classification issue, specificity is defined as the number of photos correctly predicted as not having DR in relation to the total number of images not having DR. The ratio of the total number of photos on which DR is successfully identified to the total number of images is known as accuracy. The final neural network has a 94 percent specificity and an 83.44.
The network's classification was as follows:
0 – No DR, 1 – Mild DR, 2 – Moderate DR, 3 – Severe DR, and 4 – Proliferative DR.
The following Fig. 4 shows the confusion matrix of final classification results.
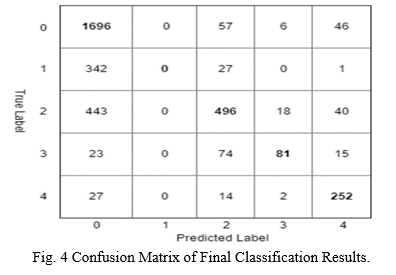
Fig. 4 Confusion Matrix of Final Classification Results.
V. ACKNOWLEDGMENT
Presenting the final year project research paper on Diabetic Retinopathy Detection Using Convolutional Neural Networks brings us great pleasure and satisfaction. We would like to thank our guide, Mrs. Jagruti Wagh, for encouraging us to keep on going and for her continuous guidance. We would like to express our gratitude to everyone who has assisted us in any way during the development of this project, whether directly or indirectly.
Conclusion
The bulk of pictures labelled as proliferative DR are appropriately detected by our neural network. Our network is learning the features needed to classify fundus images and is showing promising results. Other studies using large datasets have discovered a trade-off between sensitivity and specificity [8]. In the future, we plan to evaluate several image categorization models. We\'ll also try a few alternative ways to blood artery segmentation to see if we can improve our results. We will try to collect more photographs if at all possible, in order to train the model on a larger dataset.Finally, we\'ve shown how to train CNNs to detect Diabetic Retinopathy in fundus images. Ophthalmologists can employ CNNs to acquire a second opinion on a categorization problem.
References
[1] Fleming A.D., Philip S., Fonseca S., Goatman K.A., Mcnamee P., Scotland G.S., et al. “The efficacy of automated disease/no disease grading for diabetic retinopathy in a systematic screening programme,” Brit J Opthamol 2007; 91(11):1512-1517. [2] Goatman K.A., Fleming A.D., Phillip S., Sharp P.F., Prescott G.J., Olson J.A., “The evidence for automated grading in diabetic retinopathy screening,” Current Diabetes Reviews 2011; 7:246 – 252. [3] Olaf R., Phillip F., and Thomas B., “U-Net: Convolutional Networks for Biomedical Image Segmentation,” arXiv: 1505.04597 [cd.CV] [4] Zhein Jiang, Hao Zhang, Yi Wang, Seok-Bum Ko. “Retinal blood vessel segmentation using fully convolutional network with transfer learning” Computerized Medical Imaging and Graphics 2018; 1-15. [5] Muhammad M.f., Paolo R., Andreas H., Bunyarit U., Alicja R.R., Christopher G.O., et al. “An Ensemble Classification-Based Approach Applied to Retinal Blood Vessel Segmentation,” in IEEE Transactions on Biomedical Engineering, vol. 59, no. 9, pp.2538-2548, Sept 2012 [6] F. Farokhian and H. Demirel, “Blood vessels detection and segmentation in retina using Gabor filters,” 2013 High Capacity Optical Networks and Emerging/Enabling Technologies, Magosa, 2014, pp. 104-108. [7] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna. “Rethinking the Inception Architecture for Computer Vision,” arXiv:1512.00567 [cs.CV]. [8] Goatman K.A., Fleming A.D., Phillip S., Sharp P.F., Prescot G.J., Olson J.A. “The evidence for automatic grading in diabetic retinopathy screening,” Current Diabetes Reviews 2011; 7:246 – 252.
Copyright
Copyright © 2022 Vedant Narendra Joshi, Mehul Rajendra Gujar, Siddhant Rahul Chaudhary, Sanat Pradeep Paranjape, Jagruti Wagh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43006
Publish Date : 2022-05-20
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online