

Ijraset Journal For Research in Applied Science and Engineering Technology
Diabetic Retinopathy Disease Classification Using Retina Images: A Review
Authors: Syed Efath Hamid Andrabi, Ankur Gupta
DOI Link: https://doi.org/10.22214/ijraset.2022.42432
Certificate: View Certificate
Abstract
Diabetic Retinopathy (DR) is a frequent consequence of diabetes mellitus that results in vision-impairing lesions on the retina. It can cause blindness if it is not caught early. Unfortunately, DR is not a curable condition, and therapy simply keeps vision from deteriorating. Early identification and treatment of DR can lower the risk of vision loss greatly. Unlike computer-aided diagnostic procedures, the physical diagnosis of DR visual fundus pictures by ophthalmologists is time-, effort-, and cost-intensive, as well as prone to misdiagnosis. Deep learning has recently been one of the most popular strategies for improving experience in a range of fields, particularly medical image analysis and classifications. In medical image analysis, convolutional neural networks are becoming increasingly extensively employed as a deep learning approach, and they are quite successful. The latest state-of-the-art approaches for detecting and classifying DR colour fundus pictures using deep learning techniques have been examined and analysed for this paper. In addition, the colour fundus retina datasets accessible on DR have been examined. Different difficult subjects that need further examination are also mentioned.
Introduction
I. Introduction
The treatment of disorders is more effective in the healthcare profession when they are recognized early. Diabetes is a condition in which the body's glucose levels rise due to a shortage of insulin [1]. It has a global impact of 425 million adults [2]. The retina, heart, nerves, and kidneys are all affected by diabetes [1,2].
Diabetic Retinopathy (DR) is a diabetic condition that causes the retina's veins and arteries to enlarge and leak fluids and blood [3]. If DR progresses to an advanced degree, it might result in visual loss. DR is responsible for 2.6 percent of blindness worldwide [4]. For diabetic patients who have had the condition for a long time, the chances of developing DR increase. Regular retinal screening is necessary for diabetic people to diagnose and treat DR early enough to avert blindness [5]. . The presence of various sorts of lesions on a retina picture is used to identify DR. Microaneurysms (MA), haemorrhages (HM), and soft and hard exudates (EX) are examples of these lesions [1,6,7]. The initial symptom of DR is microaneurysms (MA), which appears as little red spherical spots on the retina due to a weakening in the vessel's walls. There are sharp borders and the size is less than 125m. As illustrated in Fig. 1, Michael et al. [8] divided MA into siX kinds. AOSLO reflectance and conventional fluorescein imaging were used to Identify the many types of MA. Haemorrhages (HM) are bigger patches on the retina that are more than 125 m in diameter and have an uneven edge. As indicated in Fig. 1, there are two forms of HM: flame (superficial HM) and blot (deeper HM).
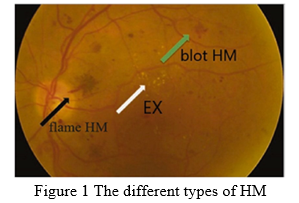
Plasma leakage causes hard exudates, which look as bright yellow patches on the retina. They are situated in the retina's outer layers and feature sharp borders. Soft substances (also known as cotton wool) are white patches on the retina caused by nerve fiber dilation. Oval or circular is the shape. MA and HM are red lesions, while soft and hard exudates are brilliant lesions (EX). Dependent on the occurrence of these lesions, there are five phases of DR: no DR, mild DR, moderate DR, severe DR, and proliferative DR. Figure 2 shows a selection of DR stage images.
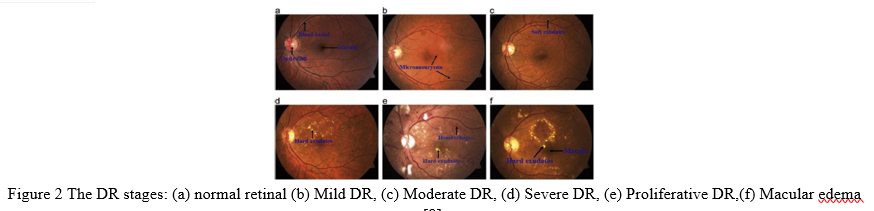
Automated solutions for DR detection are less expensive and time consuming than manual diagnosis [10]. Manual diagnosis is more likely to result in a misdiagnosis and takes more time than automatic procedures. This research examines contemporary deep learning-based DR automated approaches for detecting and classifying DR.
II. Background
Deep learning (DL) is a subset of machine learning approaches that entails hierarchical layers of non-linear processing stages for learning unsupervised features and pattern classification [11]. DL is a type of computer-assisted medical diagnostic [12]. The classification, segmentation, detection, retrieval, and registration of pictures are all examples of DL applications in medical image analysis.
DL has recently been popular in the identification and categorization of DR. Even when multiple heterogeneous sources are combined, it can successfully learn the characteristics of input data [14]. Restricted Boltzmann Machines, convolutional neural networks (CNNs), auto encoders, and weak coding are only a few of the DL-based approaches [15]. Unlike machine learning approaches, the performance of these methods improves as the volume of training data grows [16]. This is due to an increase in the taught features. Furthermore, DL techniques did not necessitate feature extraction by hand. The distinctions between DL and machine learning approaches are shown in Table 1
CNNs are more commonly utilized more than the other approaches in medical image analysis [7], and it is extremely successful [15]. Convolution layers (CONV), pooling layers, and fully linked layers are the three primary layers in the CNN architecture (FC). The CNN's number of layers, size, and number of filters are all determined by the author's vision. Each layer in the Cnns has a distinct function. Different filters convolve a picture in the CONV layers to extract the features. To minimize the size of feature maps, the pooling layer is usually applied after the CONV layer. There are several pooling approaches, but the most popular are averaging swimming and maximum pooling [1]. . FC layers are a little feature that may be used to characterize the whole input picture. The most commonly utilized classification engine is the SoftMax activation function. On the ImageNet dataset, there are several pretrained CNN topologies available, including AlexNet [14], Inception-v3 [2], and ResNet [21]. Some research, such as [2], transfer learned these before the models to speed up training, while others create their own CNN for class from start. Pre-trained models' transfer learning procedures include finetuning the last FC layer, finetuning several layers, or training all layers.
In general, the process for detecting and classifying DR pictures employs
DL starts with gathering the data and then doing the necessary pre-processing to enrich and enhance the pictures. Then, as seen in Fig. 3, information is supplied to the DL technique, which extracts the features and classifies the pictures. The next sections will walk you through these stages.
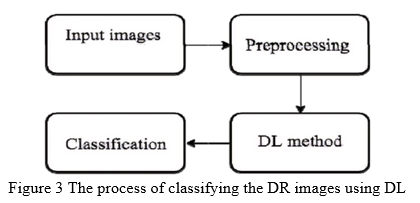
III. Methodology
A. Retina Dataset
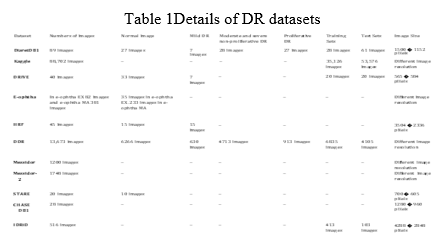
There are several freely accessible datasets for detecting DR and vasculature in the retina. These datasets are frequently used to train, validate, and test systems, as well as to evaluate the results of one system to that of others. Retinal imaging includes fundus color pictures and optical coherence tomography (OCT). OCT pictures are two- and three-dimensional images of the retina acquired with low-coherence light that reveal a lot about the structure and thickness of the retina, whereas fundus images are two-dimensional photographs of the retina taken with reflected light [24]. OCT retinal scans have been available for a few years now. A wide range of publically available fundus imaging databases are routinely used. Diaretdbi, Kaggle, DDR, drive, Stare, ROC, and more datasets are included.
B. Performance Measures
There are a variety of performance metrics that may be used to assess the classification performance of DL algorithms. Accuracy, sensitivity, specificity, and the area under the ROC curve are all popular DL measures (AUC). The proportion of aberrant pictures classified as abnormal is referred to as sensitivity, whereas the percentage of normal images categorized as normal is referred to as specificity [65]. AUC is a graph that shows the relationship between sensitivity and specificity. The percentage of correctly categorized photos is known as accuracy. The formulae for each measurement are listed below..
Specificity ¼ TN / (TN FP) (1)
Sensitivity ¼ TP/ (TP FN) (2)
Accuracy ¼ TN þ TP/(TN þ TP þ FN þ FP) (3)
The number of illness pictures recognized as disease is known as true positive (TP). The number of normal pictures labeled as normal is known as true negative (TN), whereas the number of normal images categorized as illness is known as false positive (FP). The number of illness pictures labeled as normal is known as false negative (FN). Figure 4 shows the percentage of performance measures employed in the studies that are relevant to the current work.
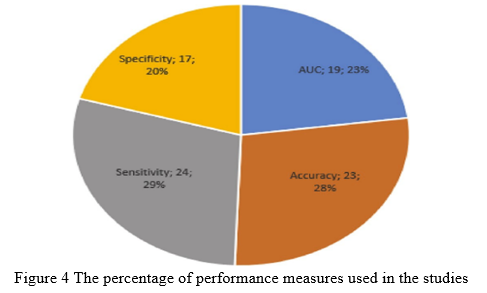
C. Image Pre-processing
Picture pre-processing is a crucial step for removing image noise, enhancing image characteristics, and ensuring image consistency. [4]
Many researchers, as seen in Refs. [1], scaled the photographs to a set resolution to make them appropriate for the network. Cropped pictures were utilized to eliminate the image's excess areas, and data normalization was performed to normalize the photos to a comparable distribution, as described in Ref. [5]. Only the green channel of photos was extracted in some publications, such as [3], because to its strong contrast [6], while the images were transformed to grayscale in others, such as Ref. [4].
A median filter, Gaussian filter, and NonLocal Means Denoising techniques, as used in the works of , are examples of noise reduction methods. When certain picture classes were imbalanced or the dataset size needed to be increased, data augmentation techniques were used, as in Ref. [5]. Translation, rotation, shearing, flipping, contrast scaling, and rescaling are examples of data augmentation techniques. For contrast augmentation, a morphological technique was applied, such as in Ref. [9]. In the research of [4], the canny edge approach was utilized to extract features.
IV. PREVIOUS works
A. Diabetic retinopathy screening systems
Several studies have attempted to use DL to automate the identification and categorization of DR lesions. These approaches may be divided into three categories based on the classification method used: binary classification, multi-level classification, and multi-level classification.
- Binary Classification
This section highlights the research that was done to divide the DR dataset into only two categories. Using a CNN, K. Xu et al. [1] automatically categorised the photos in the Kaggle [6] dataset as normal or DR images. A total of 1000 photos from the dataset were used. Before feeding the photos to the CNN, data augmentation and scaling to 224*224*3 were done. Several transformations, including as rescaling, rotation, flipping, shearing, and translation, were utilized to enlarge the dataset pictures via data augmentation. Eight CONV layers, four max-pooling levels, and two FC layers made up the CNN architecture. For classification, the SoftMax function was used to the last layer of CNN. This approach was 94.5 percent accurate..
Each picture was classed as referable DR (refer to moderate stage or greater) or non-referable DR (no DR or mild stage) in a research conducted by G. Quellec et al. [7]. Kaggle (88,702 picture) [6, DiaretDB1 (89 image) [5, and private E-ophtha (107,799 image) [8] were used to create the photos. The photos were shrunk, cropped to 448 448 piXels, normalized, and the FOV was degraded by 5% during the pre-processing step. The supplemented data were applied after a big Gaussian filter was applied. AlexNet [1] and the two networks of the o O solution [4] were the CNN architectures employed. The CNNs discovered MA, HM, mild, and hard EX. There was an area under the ROC curve in this investigation.
In their work, M. T. Esfahan et al. [2] employed a well-known CNN, ResNet34 [9], to categorize DR photos from the Kaggle dataset [6] into normal or DR images. On the ImageNet database, ResNet34 is one of the available pretrained CNN architectures. To increase the quality of the photos, they used a series of image preparation techniques. The Gaussian filter, weighted addition, and picture normalization were all used in the image preprocessing. The picture size was 512 512 piXels and the image number was 35000. They claimed a sensitivity of 86 percent and an accuracy of 85 percent.
To assess if a picture was referable DR, R. Pires et al. [10] created their own CNN architecture. The suggested CNN has 16 layers, comparable to the VGG-16 [5] and o O team [48] pretrained CNNs. During training, we employed two-fold cross-validation and multi-image resolution. After initializing the weights by the trained CNN on a reduced picture resolution, the CNN of the 512 512-image input was trained. To reduce overfitting, the CNN was subjected to drop-out and L2 regularization approaches. The CNN was trained using the Kaggle dataset [26], and the Messidor-2 [11] and DR2 datasets were used to test it. Data augmentation was used to balance the classes in the training dataset. When testing the hypothesis, the study produced a 98.2 percent area under the ROC curve.
H. Jiang et al. [12] used three pretrained CNN models to categorize their own dataset as referable DR or non-referable DR: Inception V3 [10], Inception-Resnet-V2 [13], and Resnet152 [11]. The Adam optimizer was used to adjust CNN's weights during their training. The Adaboost algorithm was used to combine these models. Before being given to the CNNs, the dataset of 30,244 photos was scaled to 520 520 piXels, improved, and augmented. The accuracy of the work was 88.21%, and the area under the curve (AUC) was 0.946.
To recognize referable DR pictures, Y. Liu et al. [14] developed a weighted pathways CNN (WP-CNN). To balance the classes, they gathered approximately 60,000 photos tagged as referable or non-referable DR and supplemented them numerous times. Before being fed to the CNN, these pictures were shrunk to 299 299 piXels and normalized. The WP-CNN has a number of CONV layers with varying kernel sizes in various weighted routes that were blended by averaging. With 94.23 percent accuracy in their dataset and 90.84 percent in the STARE dataset, the WP-CNN of 105 layers outperformed pretrained ResNet [11], SeNet [55], and DenseNet [56] architectures.
G. Zago et al. [7] used two CNN models to identify DR red lesions and DR pictures based on enhanced 65*65 patches. The CNNs utilized were VGG16 [1] that had been pre-trained and a bespoke CNN with five CONV, five max-polling layers, and an FC layer. To categorize patches into red lesions or non-red lesions, these models were trained on the DIARETDB1 [2] dataset and evaluated on the DDR [3], IDRiD [4], Messidor-2, Messidor [8], Kaggle [6], and DIARETDB0 [59] datasets. The picture with DR or without DR was then identified using a lesion probability map of test images. For the Messidor dataset, this research had the greatest sensitivity of 0.94 and an AUC of 0.912.
Unfortunately, the researchers that divided DR pictures into two groups did not take into account the five phases of DR. The DR phases are vital for determining the specific stage of DR so that the retina may be treated with the appropriate treatment and blindness is avoided..
2. Multi-level Classification
This section examines the research that classified the DR dataset into several categories. V. Gulshan et al. [6] developed a CNN-based approach for detecting DR and diabetic macular edema (DME). To test the model, they employed the Messidor-2 [1] and eyepacs-1 datasets, which comprise 1748 and 9963 photos, respectively. Before feeding these pictures to the CNN, they were normalized and scaled to a diameter of 299 piXels. They used a linear average function to obtain the final result after training 10 CNNs using the pre-trained Inception-v3 [10] architecture with a variety of pictures.. Referable diabetic macular edema, moderate or worse DR, severe or worse DR, or completely gradable pictures were used to classify the photos. They achieved a specificity of 93% in both datasets, as well as sensitivity of 96.1 percent and 97.5 percent for the Messidor-2 and eyepacs-1 datasets, respectively; however, they did not expressly detect non-DR or the five DR stage photos.
To identify and categorize DR pictures, M. Abramoff et al. [6] used a CNN with an IDX-DR device. The Messidor-2 [31] dataset, which comprises 1748 photos, was subjected to data augmentation. To detect DR lesions as well as retina normal structure, their multiple CNNs were combined using a Random Forest classifier. The photos in this project were divided into three categories: no DR, referable DR, and vision threatening DR. They reported a sensitivity of 96.8% and a specificity of 87.0 percent, with an area under the curve of 0.980. Unfortunately, photos of the moderate DR stage were mistaken for no DR, and the five DR phases were not taken into account.
H. Pratt et al. [12] suggested a technique for classifying photos from the Kaggle dataset [2] into five DR phases using a CNN-based algorithm. Color normalization and picture scaling to 512 512 piXels were done in the pre-processing step. Ten CONV layers, eight max-pooling levels, and three FC layers made up their proprietary CNN architecture. For 80,000 test photos, the Soft- Max function was utilized as a classifier. To prevent overfitting, CNN employed L2 regu- larization and dropout approaches. Their findings included a 95 percent specificity, a 75 percent accuracy, and a 30 percent sensitivity. Unfortunately, CNN does not identify lesions in the photos, and they only utilized one dataset to test their CNN.
S. Dutta et al. [13] used the Kaggle dataset [6] to identify and classify DR pictures into five DR phases. They used 2000 photos to examine the performance of three networks: the back propagation neural network (BNN), the deep neural network (DNN), and the CNN. The RGB photos were scaled to 300 300 piXels and turned to grayscale, after which the statistical characteristics were retrieved. In addition, a series of filters was used, including edge detection and a median filter.,
V. Discussion
The present research looked at 33 articles. All of the investigations presented in this paper used deep learning approaches to control the diabetic retinopathy screening system. Due to a growth in the number of diabetic patients, the demand for efficient diabetic retinopathy screening equipment has lately become a major concern. Using DL for DR detection and classification solves the challenge of picking trustworthy features for ML; nevertheless, it requires a large amount of data to train. To enhance the amount of photos and overcome overfitting in the training stage, most research employed data augmentation.. The studies discussed in this article To address the difficulty of data size and to assess the DL approaches on several datasets, 94 percent of them utilized public datasets, and 59 percent of them used a mixture of two or more public datasets, as shown in Fig. 5.
One of the drawbacks of using deep learning in the medical profession is the quantity of the datasets required to train the DL systems, as DL requires a lot of data. The amount of the training data, as well as the quality and balance of its classes, have a significant impact on the output of DL systems. As a result, the present public dataset sizes must be raised, while large datasets, such as the public Kaggle dataset, must be processed to remove mislabeled and low-quality data.
The use of DL approaches in the research described here varied. The number of research that constructed their own CNN structure vs those that decided to employ existing structures with transfer learning, such as VGG, ResNet, or AlexNet, is slightly different. Building a new CNN architecture from start takes a lot of time and effort, however employing transfer learning makes the process of constructing and building new architecture more easier and faster. On the other hand, the accuracy of the system that constructed their own CNN structure is higher than that of the systems that used existing structures. Researchers should concentrate on this aspect, and further study should be undertaken to distinguish between the two tendencies.
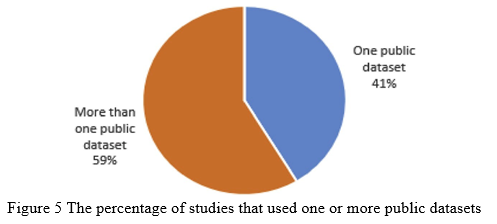
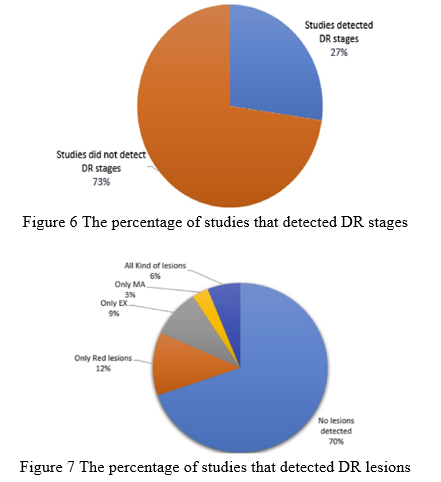
The majority of the studies (73%) solely identified the fundus input picture as DR non-DR, whereas 27% classified it as one or more phases, as seen in Fig. 6. On the other hand, 70% of existing investigations failed to find the afflicted lesions, whereas 30% of them did. Only 6% of the investigations, as indicated in Fig. 7, were successful in categorizing pictures and determining the type of impacted lesion on the preserved image. The availability of a reliable DR screening system capable of identifying all types of lesions and DR stages leads to an effective follow-up system for DR patients, avoiding the risk of losing sight. The existence of a gap that needed to be filled was the gap that needed to be filled.
 ???????
???????
Conclusion
Automated screening methods drastically shorten the time it takes to identify diagnoses, saving ophthalmologists time and money while also allowing patients to receive treatment sooner. Automated DR detection systems are critical for recognizing DR at an early stage. The DR phases are determined by the type of retinal lesions that occur. This article looked at the most current automated methods for detecting and classifying diabetic retinopathy that employed deep learning techniques. . The publically accessible fundus DR datasets have been provided, and deep-learning methodologies have been briefly discussed. Because of its effectiveness, most studies have adopted the CNN for DR image categorization and detection. The helpful strategies for detecting and classifying DR using DL were also explored in this paper.
References
[1] Taylor R, Batey D. Handbook of retinal screening in diabetes:diagnosis and management. second ed. John Wiley & Sons, Ltd Wiley-Blackwell; 2012. [2] International diabetes federation - what is diabetes [Online]. Available, https://www.idf.org/aboutdiabetes/what-is-diabetes.html. [3] American academy of ophthalmology-what is diabetic retinopathy? [Online]. Available, https://www.aao.org/eyehealth/diseases/what-is-diabetic-retinopath y. [4] Bourne RR, et al. Causes of vision loss worldwide, 1990-2010: a systematic analysis. Lancet Global Health 2013;1(6):339–49. [5] Harper CA, Keeffe JE. Diabetic retinopathy management guidelines. EXpet Rev Ophthalmol 2012;7(5):417–39 [6] E. T. D. R. S. R. GROUP. Grading diabetic retinopa thy from stereoscopic color fundus photographs- an extension of the modified Airlie House classification. Ophthalmology 1991;98(5):786–806. [7] Scanlon PH, Wilkinson CP, Aldington SJ, Matthews DR. A Practical manual of diabetic retinopathy management. first ed. Wiley-Blackwell; 2009. [8] Dubow M, et al. Classification of human retinal microaneurysms using adaptive optics scanning light ophthalmoscope fluorescein angiography. Investig Ophthalmol Vis Sci 2014;55(3):1299–309. [9] Bandello F, Zarbin MA, Lattanzio R, Zucchiatti I. Clinical strategies in the management of diabetic retinopathy. second ed. Springer; 2019. [10] Scotland GS, et al. Costs and consequences of automated algorithms versus manual grading for the detection of referable diabetic retinopathy. Br J Ophthalmol 2010; 94(6):712–9. [11] deng Li. A tutorial survey of architectures, algorithms, and applications for deep learning. APSIPA Trans. Signal Inf Process 2014;3(2):1–29. [12] V Vasilakos A, Tang Y, Yao Y. Neural networks for computer-aided diagnosis in medicine : a review. Neurocomputing 2016;216:700–8. [13] Wilkinson CP, et al. Proposed international clinical diabetic retinopathy and diabetic macular edema disease severity scales. Am Acad Ophthalmol 2003;110(9): 1677–82
Copyright
Copyright © 2022 Syed Efath Hamid Andrabi, Ankur Gupta. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET42432
Publish Date : 2022-05-09
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online