

Ijraset Journal For Research in Applied Science and Engineering Technology
Dimensional Reduction Techniques for Huge Volume of Data
Authors: Soudagar Londhe, Manasi Patil
DOI Link: https://doi.org/10.22214/ijraset.2022.40572
Certificate: View Certificate
Abstract
Huge volume of data and information is needed with the expanding advancement in the current collection of tools, cloud storage, strategic techniques and increasing development of science technology. With the appearance of complete genome successions, the biomedical area has encountered an exceptional progression. This genomics has prompted the advancement of new high-produced strategies techniques that are huge amounts in measures of information and data, which inferred the exponential development of numerous organic and biological data sets. This paper represents different linear and non-linear dimensionality reduction techniques and their validity for different kinds of data information datasets and application regions.
Introduction
I. INTRODUCTION
In recent years, a tremendous large volume of data has been generated and used in various application areas. Also, the complexity, size, heterogeneity, and dimensionality of data information are growing rapidly. A huge amount of data is continuously and consistently generated in different formats like text, digital images, videos, and speech signals. Applications of High Data can be found in domains like social media, technology, medicine, web, and business.
High dimensionality data can result in accuracy, visualization, recognition, classification, and patterns and can cause overfitting. This issue can be avoided by adding subsequent data dimensions to each data point in exponential. With the Selection of features and extraction of features, i.e. feature transformation various dimensionality reduction can be implemented. By eliminating repetitive and unconnected features, extraction of feature transforms and changes initial datasets to the decreased dataset by conserving required information from the initial dataset. The selection of features collects the subsets from the data set that is the most relevant information data to the problem. Selecting the proper technique for dimensionality reduction can reduce the effort for feature analysis.
Reduction techniques offer a way to reduce input variables before applying them to machine learning models. It can be applied to pre-processing stage of data analysis and building models. Many reduction techniques are available with different data types but a particular technique may not be suitable for a particular application.
Paper is organized in a flow of sequence, where it describes different Dimensionality Reduction Techniques based on Linear and Non-Linear types of data set. Further datasets like Bioinformatics, Cancer Diagnosis and Prognosis and Character classification are tested for dimensionality reduction. Observation for before reduction and after reduction is computed.
II. DIMENSIONALITY REDUCTION TECHNIQUES
Dimensionality Reduction is a process of transforming and generating the high dimensional representation of datasets into low dimension representations. It transforms the original data set having higher dimensions and converts it into new data representing lower dimensionality while it preserves the original meanings of the data as much as possible. This data can be easily processed, analyzed, and visualized.


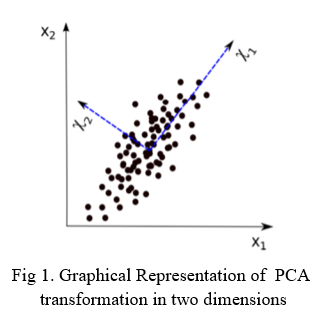





The problem is divided by optimizations of relatively k problems. For each data optimization, one base of X is computed. The first base of data x1 is found by searching p units of dimensional data of unit length vector. Projected data then maximizes the one-dimension computed for the Projection index. To prevent the same projection data direction in successive following data iterations, projection aims to discard any information in the same direction from the source data. The process is repeated for all bases of data until all k subsequent bases are computed.
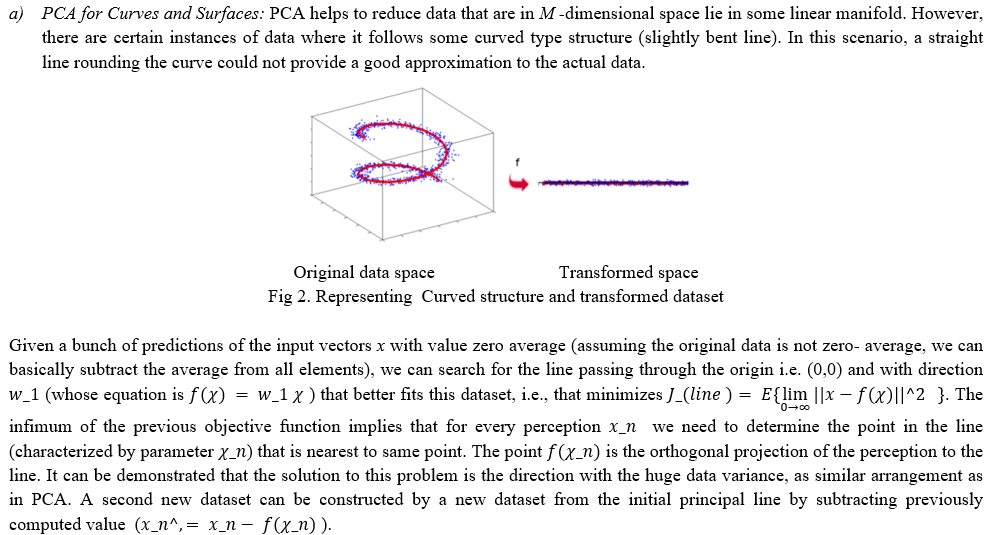
B. Non-Linear Dimensionality Reduction Techniques
A dimension reduction technique is associated and connected with a pair of data that consists of high-dimensional input data organized space to a low-dimensional corresponding output data space. A non-linear dimension reduction technique is used when a map's relationship is non-linear in nature. Following are some of the techniques.
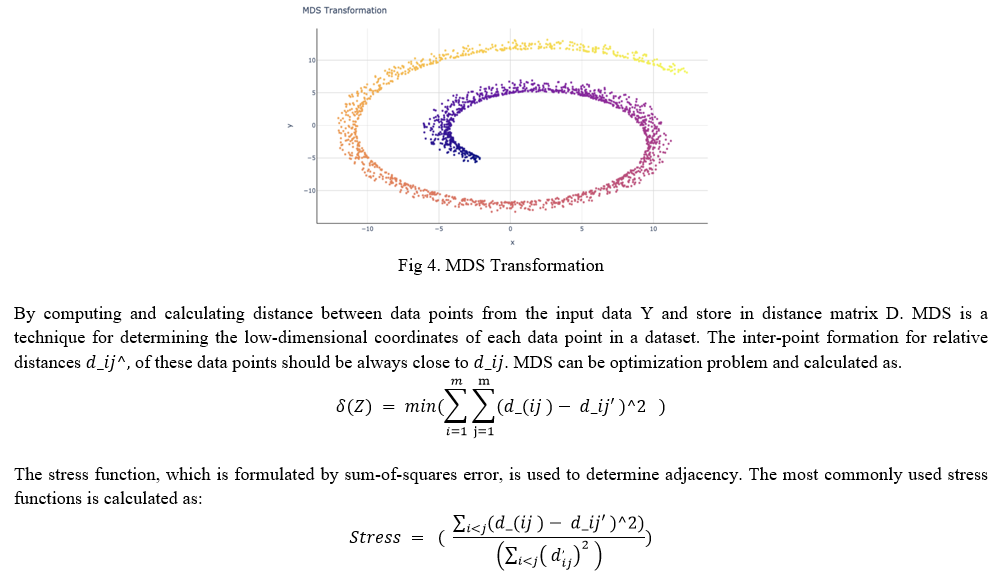
1) Multidimensional Scaling (MDS): MDS computes and calculates the distance between data points from each pair in the original high-dimensional space data and maps it to a lower-dimensional space while it preserves the distances between points as much as possible. Multidimensional scaling works better when the value of the input distance matrix is combined into the elements of the d dimensional space region such that the relation of pairwise distances is preserved into embedded data space. By calculating sum of square errors between the non-similarities data and their corresponding data embedding inter-vector distances transformation of data can be achieved by calculating stress function





III. EXPERIMENTAL RESULTS
Generally, large data of real-world data are non-linear in nature. Spam data, three-dimensional data like Insurance Benchmark and cancer datasets are chosen for analysis. Here cancer dataset abstracts around 57 attributes and 26 instances, Spam contains around 4600 records for 57 attributes and Insurance dataset abstracts around 85 attributes with 750 total records for analysis. For all these high dimensional data computing and analyzing is very difficult and all these variables does not affect classification result. So, by removing irrelevant data we can reduce dimensionality data.
By removing attributes from the high dimensionality data takes less execution time, the accuracy may affect the loss of data for classification. For this project, dimensionality reduction is performed and performance is measured for Elapsed time and accuracy with the help of matlab.
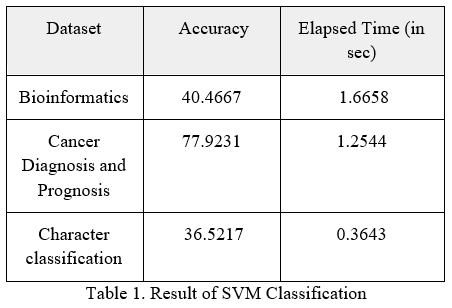
A. Result of SVM Classification
High dimensional data has been used on SVM classification in this paper. Elapsed Time and Accuracy for value classification are noted and results are displayed using the table.
.
To Show effectiveness Linear Discriminant Analysis is mainly processed for the dimensionality reduction. From analysis 86, 58 and 60 variable data are computed and then transformed into 32, 39 and 33 on bioinformatics, cancer diagnosis and character classification datasets respectively. In the next step, with the help of Principal Component Analysis thessse high dimensional data sets are processed which produces better data results than the LDA reduction method by giving 25, 8 and 14 respectively. Then ICA technique is performed on the high dimensional data which produces the results data 16, 8, and 5 bioinformatics, cancer diagnosis and character classification datasets respectively which is better compared to PCA and LDA dimensionality reduction techniques and the dimensions of low dimensional data are shown in the table.
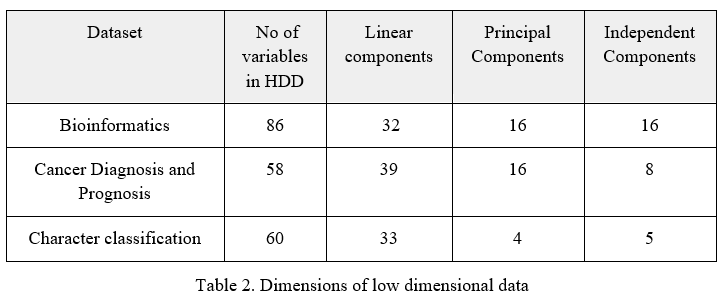
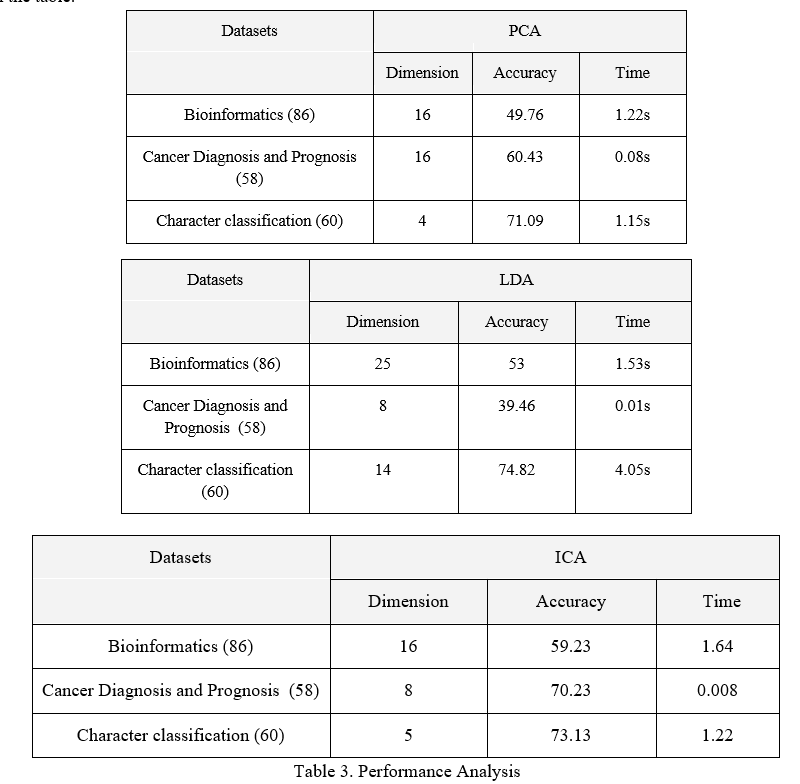
These lower-dimensional data from the above techniques are then again processed on the SVM classification and the corresponding Performance of the SVM classification is computed and calculated. From calculations, it proves and explains that for lower-dimensional data the performance of SVM is better and best computed than that of the higher-dimensional for SVM and the result is shown in the table.
Conclusion
In this paper, we present the different techniques to reduce the dimensionality of the original data points. As more and more data is generated, need for dimensionality reduction techniques also increased to reduce uncertainty in the decision-making of the data. For less computation power linear techniques are used which uses linear transformation. Time and cost are high for Non-linear techniques and have been correctly implemented in many different complex computations like audio, video and biomedical data. From the survey of datasets from above results, it comes to know that, for handling data of linear dimensional Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) are the best techniques. For handling non-linear dimensionality reduction Support Vector Machine (SVM), Independent Component Analysis (ICA) and Multi-Dimensional Scaling (MDS) are the best reduction techniques.
References
[1] X.L. Zhang, Nonlinear Dimensionality Reduction of Data by Deep Distributed Random Samplings, in Asian Conference on Machine Learning, volume 2015, pp. 221–233. [2] Zizhu Fan; Yong Xu; Zhang, D., \"Local Linear Discriminant Analysis Framework Using Sample Neighbors\", IEEE Transactions on Neural Networks, On page(s): 1119 - 1132 Volume: 22, July 2011 [3] Samarasena Buchala, Neil Davey, Tim M. Gale & Ray J Frank (2005) Analysis of linear and nonlinear dimensionality reduction methods for gender classification of face images, International Journal of Systems Science, 36:14, 931-942 [4] N. Kwak , \"Principal component analysis based on L1-norm maximization\", IEEE Transaction on Pattern Analysis and Machine Intelligence, volume. 30, no. 9, pages.1672 -1680 Year : 2008 [5] Chen Meng, Oana A. Zeleznik, Gerhard G. Thallinger, Bernhard Kuster, Amin M. Gholami, Aedín C. Culhane, Briefings in Bioinformatics, Volume 17, Issue 4, July 2016, Pages 628–641 [6] X. He, Incremental Semi-supervised Subspace Learning for Image Retrieval, in: Proceedings of the 12th Annual ACM International Conference on Multimedia, ACM, 2004, pp. 2–8. [7] P. Huang, T. Li, Z. Shu, G. Gao, G. Yang, C. Qian, Locality-regularized linear regression discriminant analysis for feature extraction, Inf. Sci. (NY) 429 (2018) 164–176. [8] S. Chen, H. Zhao, M. Kong, B. Luo, 2D-lpp: a two-dimensional extension of locality preserving projections, Neurocomputing 70 (4–6) (2007) 912–921. [9] A. Hyvarinen, Fast and fixed-point algorithms for independent component analysis, IEEE Trans. Neural Netw. 10 (3) (1999) 626–634. [10] T. Radüntz, J. Scouten, O. Hochmuth, B. Meffert, Automated eeg artifact elimination by applying machine learning algorithms to ica-based features, J. Neural Eng.14 (4) (2017) 46004. [11] D. Zhou, X. Yang, Face Recognition Using Improved-lda, in: International Conference Image Analysis and Recognition, Springer, 2004, pp. 692–699.56 [12] S. Deegalla, H. Boström, K. Walgama, Choice of Dimensionality Reduction Methods for Feature and Classifier Fusion with Nearest Neighbor Classifiers, in 15th International Conference on Information Fusion (FUSION), IEEE, 2012, pp. 875–881. [13] R. Vidal, Y. Ma, S. Sastry, Generalized principal component analysis (gpca), IEEE Trans Pattern Anal Mach Intell 27 (12) (2005) 1945–1959. [14] G.H. Golub, C. Reinsch, Singular Value Decomposition and Least Squares Solutions, in: Linear Algebra, Springer, 1971, pp. 134–151. [15] L. Cao, Singular Value Decomposition Applied to Digital Image Processing, in: Division of Computing Studies, Arizona State University Polytechnic Campus, Mesa, Arizona State University Polytechnic Campus, 2006, pp. 1–15. [16] Y. Wang, L. Zhu, Research and Implementation of Svd in Machine Learning, in: IEEE/ACIS 16th International Conference on Computer and Information Science(ICIS), IEEE, 2017, pp. 471–475. [17] F. Husson, J. Josse, B. Narasimhan, G. Robin, Imputation of mixed data with multilevel singular value decomposition, J. Comput. Graphical Stat. (2019) 1–26. [18] P. Wiemer-Hastings, K. Wiemer-Hastings, A. Graesser, Latent Semantic Analysis, in: Proceedings of the 16th International Joint Conference on Artificial Intelligence, 2004, pp. 1–14. [19] H.T. Tu, T.T. Phan, K.P. Nguyen, An Adaptive Latent Semantic Analysis for Text Mining, in: International Conference on System Science and Engineering (ICSSE), IEEE, 2017, pp. 588–593. [20] M. Kedadouche, Z. Liu, M. Thomas, Bearing Fault Feature Extraction Using Autoregressive Coefficients, Linear Discriminant Analysis and Support Vector Machine under Variable Operating Conditions, in: Advances in Condition Monitoring of Machinery in Non-Stationary Operations, Springer, 2018, pp. 339–352. [21] G. Baudat, F. Anouar, Generalized discriminant analysis using a kernel approach, Neural Comput. 12 (10) (2000) 2385–2404. [22] J.A. Lee, A. Lendasse, M. Verleysen, Nonlinear projection with curvilinear distances: isomap versus curvilinear distance analysis, Neurocomputing 57 (2004) 49–76. [23] J.H. Friedman, J.W. Tukey, A projection pursuit algorithm for exploratory data analysis, IEEE Trans. Comput. 100 (9) (1974) 881–890. [24] J.A. Lee, M. Verleysen, Nonlinear Dimensionality Reduction, Springer Science & Business Media, 2007. [25] B. Schölkopf, A. Smola, K.R. Müller, Kernel Principal Component Analysis, in: International Conference on Artificial Neural Networks, Springer, 1997, pp. 583–588. [26] A.S. Rao, J. Gubbi, M. Palaniswami, Anomalous Crowd Event Analysis Using Isometric Mapping, in: Advances in Signal Processing and Intelligent Recognition Systems, Springer, 2016, pp. 407–418. [27] X. Zheng, Y. Yuan, X. Lu, Dimensionality reduction by spatial-spectral preservation in selected bands, IEEE Trans. Geosci. Remote Sens. 55 (9) (2017) 5185–5197. [28] M.M. Nezhad, E. Gironacci, M. Rezania, N. Khalili, Stochastic modeling of crack propagation in materials with random properties using isometric mapping for dimensionality reduction of nonlinear data sets, Int. J. Numer. Methods Eng. 113 (4) (2018) 656–680. [29] D. Fitria, M.A. Ma’sum, E.M. Imah, A.A. Gunawan, Automatic arrhythmias detection using various types of artificial neural network-based learning vector quantization (lvq), Jurnal Ilmu Komputer dan Informasi 7 (2) (2014) 90–100. [30] S. Hu, Y. Gu, H. Jiang, Study of Classification Model for College Students’ M-learning Strategies Based on Pca-lvq Neural Network, in: 8th International Conference on Biomedical Engineering and Informatics (BMEI), IEEE, 2015, pp. 742–746. [31] J. Lin, D. Gunopulos, Dimensionality Reduction by Random Projection and Latent Semantic Indexing, in: Proceedings of the Text Mining Workshop at the 3rd SIAM International Conference on Data Mining, 2003. [32] F.M. Schleif, Small Sets of Random Fourier Features by Kernelized Matrix Lvq, in: Self-Organizing Maps and Learning Vector Quantization, Clustering and Data Visualization (WSOM), 2017 12th International Workshop on, IEEE, 2017, pp. 1–5. [33] L.v.d. Maaten, G. Hinton, Visualizing data using t-sne, Journal of machine learning research 9 (2008) 2579–2605. (Nov) [34] A. Konstorum, E. Vidal, N. Jekel, R. Laubenbacher, Comparative analysis of linear and nonlinear dimension reduction techniques on mass cytometry data, bioRxiv (2018) 273862. [35] A. Gisbrecht, A. Schulz, B. Hammer, Parametric nonlinear dimensionality reduction using kernel t-sne, Neurocomputing 147 (2015) 71–82. [36] F.S. Tsai, K.L. Chan, Dimensionality Reduction Techniques for Data Exploration, in: 2007 6th International Conference on Information, Communications & Signal Processing, IEEE, 2007, pp. 1–5. [37] U.D. Dixit, M. Shirdhonkar, Logo Based Document Image Retrieval Using Singular Value Decomposition Features, in: International Conference on Signal and Information Processing (IConSIP), IEEE, 2016, pp. 1–4. [38] Rukshan Pramoditha, 11 Dimensionality reduction techniques you should know in 2021- Reduce the size of your dataset while keeping as much of the variation as possible, TowardsDataScience, [39] S. Hao, Y. Xu, H. Peng, K. Su, D. Ke, Automated Chinese Essay Scoring from Topic Perspective Using Regularized Latent Semantic Indexing, in: 22nd International Conference on Pattern Recognition (ICPR), IEEE, 2014, pp. 3092–3097. [40] Pulkit Sharma, The Ultimate Guide to 12 Dimensionality Reduction Techniques (with Python codes), Analytics Vidya, August 27, 2018 [41] F. Cai and V. Cherkassky, “Generalized SMO algorithm for SVM-based multitask learning,” IEEE Trans. Neural Netw. Learn. Syst., vol. 23, no. 6, pp. 997–1003, Jun. 2012. [42] S. Dhir and S.-Y. Lee, “ Discriminant independent component analysis ”, IEEE Transaction on Neural Networks, volume. 22, pages : 845 -857 2011
Copyright
Copyright © 2022 Soudagar Londhe, Manasi Patil. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40572
Publish Date : 2022-03-01
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online