

Ijraset Journal For Research in Applied Science and Engineering Technology
Discriminative Transfer Learning for Driving Pattern Recognition in Unlabeled Scenes
Authors: Ghodake Sanket Tukaram , Jadhav Tushar Anil, Pund Mayuri Vishwanath , Pund Raviraj Vishwanath, Dandekar Pooja Kantilal
DOI Link: https://doi.org/10.22214/ijraset.2022.47750
Certificate: View Certificate
Abstract
Driving behavior has a large impact on behaviour of driver. The lack of a labeled data problem in a driving scene substantially hinders the driving pattern recognition accuracy. However, modeling driving behavior under the dynamic driving conditions is complex, making a quantitative analysis of the the driving behaviour. In this paper, the Driver behaivor dataset was collected from dataset repository. Then, we have to implement the pre-processing techniques. Then, the system is developed the machine learning algorithm such as Random forest and Support Vector Machine algorithm. The experimental results shows that some performance metrics such as accuracy, precision, recall and f1-score. By using the ML is, to classify the Aggressive, normal, slow.
Introduction
I. INTRODUCTION
Recently, driving pattern recognition, that is, identifying specific movements of cars, such as driving in a lane, turning left, parking, etc., has been extensively studied given its critical importance for self-driving vehicles and intelligent transportation systems.
The driving status, such as GPS, gear, and speed information, is important and can be used for driving pattern recognition, but it may be highly variable depending on driving scenes such as different parking lots.
Hence, massive labeled data are often required for accurate driving pattern recognition.However, it is almost impossible to collect sufficient labeled driving data from every driving scene in practice.
Consequently, driving pattern recognition for unlabeled scenes becomes a challenging problem of central importance. It is generally assumed that each driving pattern, such as turning left should be highly correlated across related scenes, despite their large disagreements in distribution.
II. OBJECTIVE
The main objective of our project is,
Guide: Prof Gunaware N.G.
HOD: Hiranawale S.B.
- To predict or to classify the driving pattern.
- To implement the machine learning algorithm.
- To detect the aggressive/normal effectively.
- To enhance the performance analysis.
A. Existing system
Driving pattern recognition based on features, such as GPS, gear, and speed information, is essential to develop intelligent transportation systems. However, it is usually expensive and labor intensive to collect a large amount of labeled driving data from real-world driving scenes. The lack of a labeled data problem in a driving scene substantially hinders the driving pattern recognition accuracy. To handle the scarcity of labeled data, we have developed a novel discriminative transfer learning method for driving pattern recognition to leverage knowledge from related scenes with labeled data to improve recognition performance in unlabeled scenes. Note that data from different scenes may have different distributions, which is a major bottleneck limiting the performance of transfer learning. To address this issue, the proposed method adopts a discriminative distribution matching scheme with the aid of pseudolabels in unlabeled scenes.
B. Proposed System
In our proposed system, we detect the Driving pattern by using the machine learning algorithm. First, we select and view the imported dataset for future purpose. And we get missing values and fill the default values to the dataset. We encoding the label in the dataset. And we split the dataset to the Train and Test data for predict the driving pattern of aggressive, normal or slow. Then we use two algorithms for more accuracy, prediction and which is more accurate value. There are Random forest algorithm, SVM Algorithm. Now, we fit the training data from the dataset. Then we predict the test dataset using training dataset. Then the test values get the results of actual and predicted. And we get the performance of the dataset. It is essential to train the models on data which includes fraud and relevant non fraud. By using the ML algorithm the system is, to classify the aggressive or not and results shows that the accuracy, precision, recall and f1-score and also prediction. This shows that method used in this project can predict the possibility of aggressive accurately in most of the cases. This module is the simple and effective way to avoid such driving pattern and save those expenditures.
C. Disadvantages
The results is low when compared with proposed.
Time consumption is high.
Theoretical limits.
D. Advantages
It is efficient for large number of datasets.
The experimental result is high when compared with existing system.
Time consumption is low.
Provide accurate prediction results
III. SYSTEM ARCHITECTURE
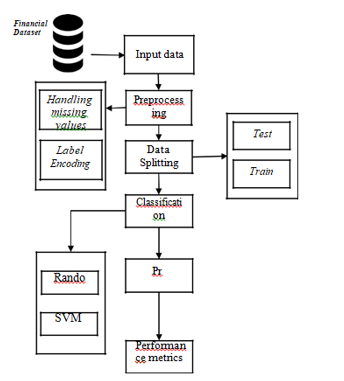
Modules
- Data selection
- Data preprocessing
- Data splitting
- Classification
- Prediction
- Performance Metrics
A. Data Selection
The input data was collected from the dataset repository like Kaggle.
In this process, the input data have some columns like AccX, AccY, Accz, GyroX, GyroY, GyroZ, Time Stamp, etc.
In this work all having test dataset and train dataset in the test data set having a 1000 dataset and in the train data having a 3000+ data.
B. Data pre-processing
Data pre-processing is the process of removing the unwanted data from the dataset.
Pre-processing data transformation operations are used to transform the dataset into a structure suitable for machine learning.
This step also includes cleaning the dataset by removing irrelevant or corrupted data that can affect the accuracy of the dataset, which makes it more efficient.
Missing data removal
Missing data removal: In this process, the null values such as missing values and Nan values are replaced by 0.
Missing and duplicate values were removed and data was cleaned of any abnormalities. Label Encoding: In this process, the string values are converted into integer for more prediction.
C. Data Splitting
During the machine learning process, data are needed so that learning can take place.
In addition to the data required for training, test data are needed to evaluate the performance of the algorithm but here we have training and testing dataset separately.
In our process, we have to divide as training and testing.
Data splitting is the act of partitioning available data into two portions, usually for cross-validator purposes.
One Portion of the data is used to develop a predictive model and the other to evaluate the model's performance.
IV. CLASSIFICATION
A. Random Forest Algorithm
Random forest is a machine learning algorithm for fraud detection. It's an unsupervised learning algorithm that identifies fraud by isolating outliers in the data.
B. SVM Algorithm
SVM or Support Vector Machine is a linear model for classification and regression problems. It can solve linear and non-linear problems and work well for many practical problems. The idea of SVM is simple: The algorithm creates a line or a hyperplane which separates the data into classes
Conclusion
In this project, we propose an approach to utilise the Support Vector Machine and Random Forest algorithm for driving pattern recognition. We call the approach the SVM on datasets with significantly reduced dimensionality. The Classifications classifier gives high accuracy results that are comparable or superior to RF algorithm techniques in spite of working with reduced data. Title Author Year Methodology Advantages/Disadvant ages Electric Vehicle Energy Consumptio n Estimation for a Fleet Management System Abbas Fotouhi 1, Neda Shateri 2 , Dina Shona Laila 2 , Daniel J. Auger 2019 The proposed estimator consists of a vehicle model, a driver model, and terrain models. It is demonstrated that a combination of these three parts can provide an accurate estimation of EV energy consumption on a particular route. As part of this study, a commercially-available passenger car is modelled using MATLAB/Simulink. A number of specific routes are selected for EV road testing to be driven for simulation model verification. In the second part of this study, the impact of energy consumption estimation accuracy is investigated at a larger scale for a fleet of EVs. It is quantitatively demonstrated how much sensitive is the performance of a FMS to the accuracy of the energy estimator. Advantages: High performance and accuracy. Disadvantages: One drawback of this algorithm is its dependency on the starting point Future Enhancement In future, discovery of additional information based on cause-event driving pattern well as prediction of detection based on cause events, etc.The working of the proposed approach in a Wireless Sensor Network node.
References
[1] A. Ferdowsi, U. Challita, and W. Saad, “Deep learning for reliable mobile edge analytics in intelligent transportation systems,” IEEE Veh. Technol. Mag., vol. 14, no. 1, pp. 62–70, Jan. 2019. [2] S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Trans. Knowl. Data Eng., vol. 22, no. 10, pp. 1345–1359, 2010. [3] L. Zhang, “Transfer adaptation learning: A decade survey,” 2019. [Online]. Available: arXiv:1903.04687. [4] S. J. Pan, I. W. Tsang, J. T. Kwok, and Q. Yang, “Domain adaptation via transfer component analysis,” IEEE Trans. Neural Netw., vol. 22, no. 2, pp. 199–210, Feb. 2011. [5] M. Long, J. Wang, G. Ding, J. Sun, and P. S. Yu, “Transfer joint matching for unsupervised domain adaptation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2014, pp. 1410–1417. [6] B.Gong, Y. Shi, F. Sha, and K. Grauman, “Geodesic flow kernel for unsupervised domain adaptation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2012, pp. 2066–2073. [7] B. Sun, J. Feng, and K. Saenko, “Return of frustratingly easy domain adaptation,” in Proc. AAAI Conf. Artif. Intell., 2016, pp. 2058–2065. [8] R. Aljundi, R. Emonet, D. Muselet, and M. Sebban, “Landmarks-based kernelized subspace alignment for unsupervised domain adaptation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2015, pp. 56–63. [9] M. Ghifary, W. B. Kleijn, and M. Zhang, “Domain adaptive neural networks for object recognition,” in Proc. Pac. Rim Int. Conf. Artif. Intell., 2014, pp. 898–904. 10. Y. Lin et al., “Cross-domain recognition by identifying joint subspaces of source domain and target domain,” IEEE Trans. Cybern., vol. 47, no. 4, pp. 1090–1101, Mar. 2017.
Copyright
Copyright © 2022 Ghodake Sanket Tukaram , Jadhav Tushar Anil, Pund Mayuri Vishwanath , Pund Raviraj Vishwanath, Dandekar Pooja Kantilal. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47750
Publish Date : 2022-11-29
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online