

Ijraset Journal For Research in Applied Science and Engineering Technology
Drug Classification Using Machine Learning
Authors: Navaneetha krishnan M, Venkatesan P
DOI Link: https://doi.org/10.22214/ijraset.2022.43609
Certificate: View Certificate
Abstract
The advancement and progress in technology and related techniques have created a chance for progress in many scientific fields and various industries. Machine learning has become important tool for drug designs and discovery with the supply of bit data from large databases. during this paper I analyze Machine Learning and Deep learning techniques which help Pharma industry altogether stages of drug discovery which incorporates target validation, prognostic biomarkers, clinical trials
Introduction
I. INTRODUCTION
CSIR is one in every of the biggest publicly funded research organizations within the world. OSDD is intended as a CSIR led Team India consortium with global partnerships. Tuberculosis (TB) is OSDD’s first target for drug discovery thanks to its high incidence and mortality in India and other developing countries.
There has been no major breakthrough which may substitute the lengthy DOTS therapy for tuberculosis. Pharmaceutical industry has made a commendable contribution to the invention of medicine for several diseases. The market size and inability of patients to procure costly drugs discourages substantial investment in Tuberculosis. the identical editorial has quoted Margaret Chan, Head of the globe Health Organization, as stating that the sector of TB research has been too isolated and inward-looking.
OSDD tries to bring research on mycobacteria to the open sky in order that researches across the planet can share and collaborate, thereby bringing many eyeballs to the matter. the shortage of participation of brilliant youngsters from the academia in present drug discovery model, fails to tap the resources of brilliant minds to deal with this problem. so as to tackle these challenges, OSDD tries to collectively aggregate the abilities of researchers in academia, research
laboratories, industry et al for a collaborative, sustained and coordinated attempt at drug discovery for tuberculosis. Currently quite 1500 registered participants are engaged on quite 100 projects posted online. These participants are from 31 countries. OSDD harnesses the competencies of personal sector through public private partnerships in an open mode.
All research results are published on the web site, whether worn out the academia, industry, public sector laboratories or by collaborating researchers. The new drug that's likely to return out of the drug discovery process are made available as a ‘generic’ molecule, freed from property (IP) constraints for the industry to manufacture and distribute anywhere within the world, thereby ensuring that the costs are affordable.
II PROPOSED WORK AND MODEL DESIGN
A. Existing System
The challenges of applying ML lie primarily with the dearth of interpretability and repeatability of ML-generated results, which can limit their application. altogether areas, systematic and comprehensive high-dimensional data still have to be generated. With ongoing efforts to tackle these issues, yet as increasing awareness of the factors needed to validate ML approaches, the applying of ML can promote data-driven higher cognitive process and has the potential to hurry up the method and reduce failure rates in drug discovery and development.
B. Proposed System
The machine learning techniques that are accustomed answer the drug discovery questions covered during this Review. a variety of supervised earning techniques (regression and classifier methods) are wont to answer questions that need prediction of knowledge categories or continuous variables, whereas unsupervised techniques are wont to develop models that enable clustering of the info. ADME, absorption, distribution, metabolism and excretion; CNN, convolutional neural network; CT, computed tomography; DAEN, deep autoencoder neural network; DNN, deep neural network; GAN, generative adversarial network; MRI, resonance imaging; NLP, tongue processing; PK, pharmacokinetic; RNAi, RNA interference; RNN, recurrent neural network; SVM, support vector machine; SVR, support vector regression.
III. MODULES
A Data Collection
Before analyzing and visualization we'd like the data and this information can gathered from different open source data websites available on the web. This data are in raw form, it should be the PV solar array sales, renewable energy consumption or production in any specific area or regions where solar or wind which one is more favorable. As here we are specializing in the renewable energy data sets so we'll be considering following websites where this data is on the market.
B. Hypothesis Definition
This is an awfully important step to analyse any problem. the primary and foremost step is to grasp the matter statement. the concept is to seek out out the factors of a product that makes an effect on the sales of a product. A null hypothesis may be a sort of hypothesis employed in statistics that proposes that no statistical significance exists in an exceedingly set of given observations. An alternative hypothesis is one that states there's a statistically significant relationship between two variables
C. Data Exploration
Data exploration is an informative search utilized by data consumers to create true analysis from the knowledge gathered. Data exploration is employed to analyse the info and data from the info to create true analysis. After having a glance at the dataset, certain information about the information was explored. Here the dataset isn't unique while collecting the dataset. during this module, the distinctiveness of the dataset is created
D. Data Cleaning
In data cleaning module, is employed to detect and proper the incorrect dataset. it's accustomed remove the duplication of attributes. Data cleaning is employed to correct the dirty data which contains incomplete or outdated data, and also the improper parsing of record fields from disparate systems. It plays a major part in building a model.
E. Feature Engineering
In the feature engineering module, the method of using the import data into machine learning algorithms to predict the accurate directions. A feature is an attribute or property shared by all the independent products on which the prediction is to be done. Any attribute can be a feature, it's useful to the model.
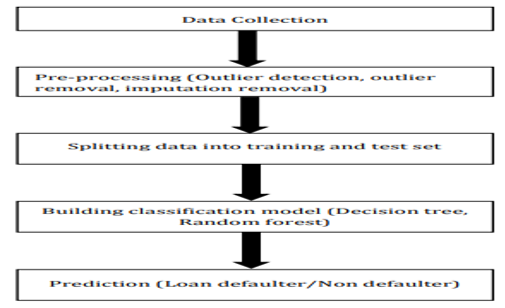
IV. DATAFLOW DIAGRAM
Data flow diagrams are wont to graphically represent the flow of information in a very business data system. DFD describes the processes that are involved in a very system to transfer data from the input to the file storage and reports generation. Data flow diagrams are often divided into logical and physical. The logical data flow chart describes flow of information through a system to perform certain functionality of a business. The physical data flow chart describes the implementation of the logical data flow.The visual representation makes it a decent communication tool between User and System designer. The target of a DFD is to point out the scope and limits of a system. The DFD is additionally called as a knowledge flow graph or bubble chart. It are often manual, automated, or a mix of both. It shows how data enters and leaves the system, what changes the knowledge, and where data is stored.
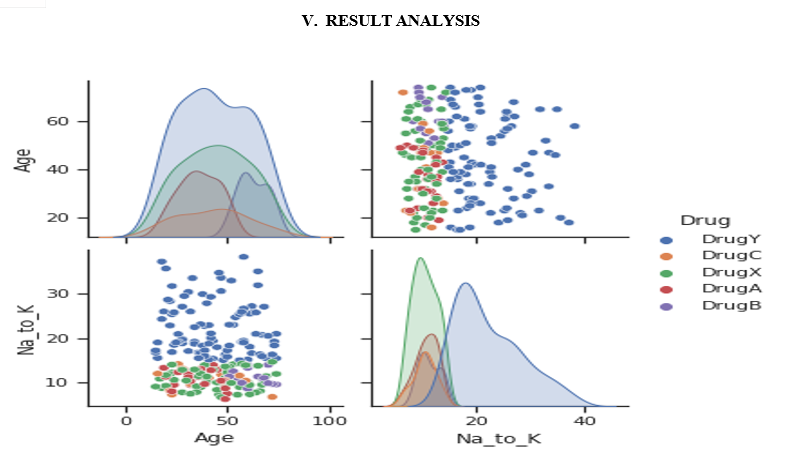
V. ACKNOWLEDGMENT
This Research Article was supported by Department of MCA, Karpagam College of Engineering, Coimbatore. I have great satisfaction in presenting this article on "Smart Disease Predictor using Machine Learning". I take this opportunity to express my sincere thanks to my guide, Prof Mr.M.Navaneetha Krishnan, for providing the technical guidelines and suggestions regarding the line of this work. I want to convey my gratitude for his constant encouragement, support and guidance throughout the project's development. I am grateful to Dr. K.Anuradha (Director In-Charge, Department of MCA); my project would not have shaped up without their support. I wish to express my deep gratitude toward all my Professor at Karpagam College of Engineering, Coimbatore, for their encouragement.
Conclusion
The AI technology is employed in pharmaceutical industries including ML algorithms and deep learning techniques in existence. In life science, ML models predict the trained data in an exceedingly known framework i.e., the compound structure can perform alternative tools like PPT inhibitors, macrocycles with traditional algorithms. Additionally, deep learning models are often considered the chemical structures and QSAR models from pharmaceutical data which was pertinent for molecules with appropriate properties, because to the forward success rate in clinical trials. AI technology has taken a forward step in stepping into computer-aided drug development to retrieve the powerful capabilities in data processing
References
[1] Mamoshina, P. et al.Machine learning on human muscle transcriptomic data for biomarker discovery and tissue-specific drug target identification.Front. Genet. 9, 242 (2018). [2] LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521, 436 (2015). [3] Hinton, G. Deep learning — a technology with the potential to remodel health care. JAMA 320, 1101–1102 (2018). [4] Wong, C. H., Siah, K. W. & Lo, A. W. Estimation of run success rates and related parameters. Biostatistics https://doi.org/10.1093/biostatistics/kxx069 (2018). [5] Jeon, J. et al. a scientific approach to spot novel antineoplastic targets using machine learning, inhibitor design and high-throughput screening. Genome Med. 6, 57 (2014).
Copyright
Copyright © 2022 Navaneetha krishnan M, Venkatesan P. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43609
Publish Date : 2022-05-30
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online