

Ijraset Journal For Research in Applied Science and Engineering Technology
Drug Recommendation System based on Sentiment Analysis of Drug Reviews using Machine Learning
Authors: Shubham Thorat, Tushar Bargal, Rahul Chavan, Shraddha Ghodekar, Prof. Nilesh Gunaware
DOI Link: https://doi.org/10.22214/ijraset.2022.47474
Certificate: View Certificate
Abstract
It\'s been like this since the coronavirus outbreak It is increasingly difficult to obtain legal treatment resources, such as the lack of specialists and health personnel, Appropriate equipment and medicines, etc. there are many Deaths attributable to the entire healthcare industry Rebellious. People started taking it due to lack of availability self-medication without proper advice, This made her health worse than usual. recent, Machine learning has been demonstrated in various the use of automation and creative work is increasing. The purpose of this paper is to propose a prescription system Medications that can significantly reduce the workload of specialists. Therefore, the proposed system provides drug recommendations A platform that requires patient feedback to predict mood Use a variety of vectorization techniques.
Introduction
I. INTRODUCTION
As Covid cases flood, there is a Worldwide deficiency of specialists, particularly in provincial regions There are less experts than in metropolitan regions. specialist should Finish their preparation between the ages of six and twelve. Consequently, expanding the quantity of specialists for a brief time frame is unthinkable. Telemedicine Framework Need to push higher quickly during this troublesome time second.
Clinical blunders are normal today. north of 200 100,000 individuals a year in China, 100,000 individuals Medicine mistakes are related with every year in the US. more In over 40% of cases, specialists commit errors while composing Requires a remedy as clinical experts have restricted supplies The information on which their choices are based. pick the best Meds are fundamental for the people who need an expert Through an inside and out comprehension of microorganisms, Antiviral Medications and Purchasers.
Notwithstanding, picking a course of treatment or a solution for explicit patient in light of reasons and early clinical history is demonstrating progressively challenging for clinicians. Thing updates have formed into an imperative and fundamental perspective for purchase things all around the world because of the speed of the web extension and development of the web organization area. Individuals all around the world have prior to purchasing it developed into customary perusing of remarks and searches web. Albeit most past exploration has zeroed in on assessing assumptions and proposition for medical care or logical treatments, was the internet business area seldom explored. How much individuals looking on the web for analysis since they are concerned their wellbeing expanded. US Seat Exploration Center. a study directed in 2013 viewed that as roughly 35% of people has explored for computerized clinical analysis, while around 60% of them individuals looked for wellbeing related issues. To assist specialists and patients with finding out about drugs for explicit wellbeing circumstances, suggesting meds the framework is obviously fundamental.
A "proposal stage" recommends things to clients in light of their necessities and advantages. These methodologies use client approaches surveys to dissect the client's feelings and propose a thought for their particular prerequisites. Drug proposal framework utilizes feeling order and component extraction restrictively give prescription relying upon the patient input. Feeling investigation is a development approaches, procedures and instruments for distinguishing a partition of wistful data from language, for example, suppositions and contemplations. Highlighting then again designing requires adding new elements to those that as of now exist to build the presentation of the model.
II. PROBLEM STATEMENT
The world is confronting a lack of specialists due to an overwhelming expansion of covid-19 cases particularly in country regions where there are less experts than in city regions. A specialist should complete his schooling somewhere in the range of six and twelve years. Thus, adding more specialists in a brief time frame is beyond the realm of possibilities. Foundation for Telemedicine should be executed quickly this troublesome second.
III. LITERETURE SURVEY
"A medication proposal framework in view of opinion examination from drug surveys utilizing AI." Garg, writer of Satvik the article recommended that the profound investigation of the medication audit review was researched to foster a reference program utilizing various sorts of AI like Strategic relapse, Perceptron, Multinomial Gullible Bayes, Edge classifier, Stochastic inclination plummet. , LinearSVC, utilized in Bow, TF-IDF, and splitters, for example, Choice Tree, Committed Backwoods, Lgbm, and Catboost are utilized in Word2Vec and Manual capability technique.
Improvement of hyper boundaries is likewise expected for segment calculations to work on model exactness. it has been recommended that the main way feelings can be removed from information and made contrasts is to make a good framework.
"Further developing pharmacovigilance utilizing drug surveys and online entertainment." is a sheet of Discussions, Brent and Katie MO guarantee that paper can utilize a wide assortment of specific specialty utilizations of BERT, their normalization can be restricted on the off chance that they are utilized to somewhat another space.
Notwithstanding difference, BERT has been displayed to emphatically address for an enormous number of episodes, 5 or 10 ages contrasted with the suggested 2-4 episodes, with the best exhibition on responsiveness test and NER information. Furthermore utilizing an extra delimiter over the BERT yield parts can give huge advantages, particularly in the event that the data set has a limited size as shown in the ADR grouping.
"A Weighted Message Portrayal System for Opinion Examination of Clinical Medication Surveys." Yadav, Ashima and Dinesh Kumar Vishwakarma makes sense of in this article that they propose a structure for message portrayal in light of weighty implanting words with a mix of the tf-idf weighting plan and Quick Message inserting.
In this paper, the job of profound examination in the clinical field is explored by breaking down understanding surveys of the famous drugs they consume. Test brings about the medication outline data sets show that the proposed strategy surpasses the standard outcomes tried in a few measurements.
Additionally, investigate the connection among extremity and medication fame.
"Correlation of Profound Learning Models for Feeling Examination of Medication Surveys" Colón-Ruiz, Cristóbal, and Isabel Segura-Bedmar the point is to think about top to bottom investigations of hard working attitudes structures in the field of medication investigation.
Impact of various implicit models on execution of various models, however not even one of them appear to give improved results than all underlying models or arbitrary triggers.
Opinion investigation is much of the time thought about an element of text detachment. In the proposed case, paper examines the undertaking utilizing the three proposed polarities (positive, negative and nonpartisan) yet in addition as a difficult order task utilizing 10 classes, which are norms characterized by clients to communicate their general fulfilment with the medication. for rundown.
"Viewpoint based feeling examination of medication audits utilizing cross-space and information learning." Gräßer, Felix et al that this work concentrated on the utilization of AI based profound examination of patient-created drug audits.
Invert models were prepared utilizing basic lexical highlights, for example, unigrams, bigrams, and trigrams separated from refreshes. But quiet fulfilment, profound variables connected with progress, and mental antagonistic results were examined.
Contingent upon the idea of an information sources, promising characterization results can be gotten. Since the datasets contain mark characterization models that are interesting or then again just accessible casually, we investigated various approaches to demonstrating.
Albeit inward preparation and area (for example state) assessment shows phenomenal characterization results, the exhibition of models prepared in a particular and tried in an alternate circumstance, changes between spaces. In any case, conditions related with similar clinical fields and they are to some degree treated with similar medications and show a higher likelihood of model transmission. Different information testing for example preparing and a class testing information from various sources could be good just with the pre-owned separator and capabilities.
IV. METHODOLOGY
The paper gives a idea about drug recommender system which useccs the patients sentiments for analysing the medicines and predict their effect on patients health using linear SVC, Word to Vec NLP, Smote, Bow, TF-IDF.
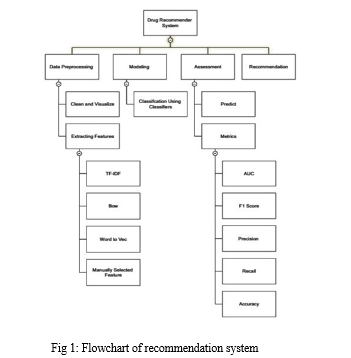
Fig. 1 indicates the proposed mannequin used to construct a medicinal drug recommender system. It carries 4 stages, specifically, Data preparation, classification, evaluation, and Recommendation
The likelihood of anomalous records has multiplied in today’s statistics due to its giant dimension and its foundation for heterogenous sources. Considering the truth that superb facts leads to higher fashions and predictions, records preprocessing has turn out to be vital, and the imperative step in the facts science/machine learning/AI pipeline. In this article, study about the want to method information and talk about distinctive techniques to every step in the process.
A. Data Preprocessing And Visualisation
In order to create a dataset that is intelligible, a procedure known as data preprocessing entails modifying raw data to address concerns arising from its incompleteness, consistency, and/or lack of a suitable depiction of trends.
Data preprocessing is not only frequently viewed as the most time-consuming step in creating a deep learning model, but it is also undervalued, especially in NLP. Therefore, the moment has come to advocate for it and accord data preparation the respect and significance it merits. This post, like my first, will draw inspiration from my experiences while working on text simplification. It will demonstrate some techniques, outlining both their benefits and drawbacks as well as the underlying theory.
B. Feature Extraction
Feature engineering serves to preprocess data in such a way so that it can be served to machine learning algorithms. One common application is preprocessing data that is read into machine learning pipelines. Feature extraction converts the raw data into numerical features compatible with machine learning algorithms. Feature extraction is also useful with images—by extracting the shape of an object or checking for patterns based on redness or quantum numbers, data scientists can create new features compatible with machine learning applications.
1. TF-IDF
.the word "term frequency" The acronym IDF refers for "inverse document frequency," or the frequency at which a term appears in documents. It is a technique for estimating the importance of words based on how frequently they appear.TF IDF provides information on the word's frequency of occurrence and its significance in the context of all evaluated documents (e.g. websites).
The TF IDF provides information about a word's frequency of use and significance in the context of all papers being studied (e.g. set of websites).
2. Precision
Precision is a term which has evaluated as the number of correct prediction shared by total predictions made during evaluation of model
Precision = TP/ TP+ FP
3. Recall
Review estimates the extent of genuine up-sides that were anticipated accurately. It considers bogus negatives, which are cases that ought to have been hailed for incorporation yet weren't. Review can be determined as:
Recall= TP/TP+FN
4. F1 Score
F1 is a general proportion of a model's exactness that joins accuracy and review, in that bizarre way that expansion and duplication simply blend two fixings to make a different dish out and out. That is, a decent F1 score implies that you have low bogus up-sides and low misleading negatives, so you're accurately distinguishing genuine dangers and you are not upset by deceptions. A F1 score is viewed as wonderful when it's 1, while the model is a complete disappointment when it's 0.
Keep in mind: All models are off-base, however some are helpful. That is, all models will produce a few bogus negatives, a few misleading up-sides, and perhaps both. While you can tune a model to limit either, you frequently face a trade-off, where a decline in bogus negatives prompts an expansion in misleading up-sides, or the other way around. You'll have to upgrade for the presentation measurements that are generally helpful for your particular issue.
F1 score = 2 * precision *recall / precision + recall
5. Accuracy
This is the most instinctive model assessment metric. At the point when we mention expectations by grouping the objective facts, the outcome is either right (Valid) or wrong (Misleading). The order precision estimates the level of the right arrangements with the equation beneath:
Precision = no. of right expectations/no. of complete data values
The higher the precision, the more exact the model. However, precision doesn't recount the full story, particularly for imbalanced datasets.
Accuracy = Total number of correct predictions/ total number of elements
C. Training Dataset Four Processing
Model is used to run the input data through the algorithm to correlate the processed output against the sample output. The result from this correlation is used A training model is a dataset that is used to train an ML algorithm. It consists of the sample output data and the corresponding sets of input data that have an influence on the output. The training to modify the model. This iterative process is called “model fitting”. The accuracy of the training dataset or the validation dataset is critical for the precision of the model.
Model training in machine language is the process of feeding an ML algorithm with data to help identify and learn good values for all attributes involved. There are several types of machine learning models, of which the most common ones are supervised and unsupervised learning.
V. EXISTING SYSTEM
The Existing Drug Recommender system that we have has few drawbacks as listed below:
- The existing systems has main drawback is that they only used to predict the wheather the medicine has positive or negative effect on the human body.
- It predicts review without letting the patient know about the medicine or drug that is use and effectiveness of that perticular drug on patients health
VI. ADVANTAGES OF PROPOSED SYSTEM
We have implemented a system that not only predicts the reviews based upon sentiment analysis of the patient Who have already used that perticular drug previously but also we have implemented a perticular drug library for let the patient know about the medicine or drug that they are using to find out a better medicine for their cure
VII. DISCUSSION
By introducing an intermediate region between an active and inactive interaction, a data-driven strategy was attempted to overcome the drawbacks of framing DTI prediction as a binary classification task in this study.This results in a solution that is more feasible and realistic while maintaining uncompromising performance.Realizing the order of individual data elements is just as important as understanding the data itself, as is the case with any sequential dataset.By means of attention, gCNN, and biLSTM networks, the information aspect received a lot of attention.As portrayed in the Prior area, dNNDR models reliably beat Related strategies in most execution measurements.When tested on a brand-new dataset (external validation), the other methods typically significantly deter, whereas the dNNDR models demonstrated exceptional effectiveness (Table 5).In addition, a graphical user interface was made to go along with feature extraction for any DTI prediction task.The dNNDR-featx program extracts the user-chosen molecular descriptors from plain text files containing drug-target pairs.Figure 1 provides a general overview of the interface.These results suggested that the proposed models could mature into promising methods for the identification of novel DTIs, despite the fact that experimental screening methods can only validate the binding energies of putative DTIs.In the end, the integrative approach that was proposed recommended a group of promising DTIs that had the potential to be experimentally validated as promising leads for new cancer therapies.However, dNNDR’s DTI predictions were supported by experimental and computational evidence in the existing literature (Supporting Information file 1).According to another report, salicylic acid, which is predicted to bind to mammalian carbonic anhydrases, inhibits carbonic anhydrase I.55 Aspirin, an acetyl derivative of salicylic acid, is computationally predicted to interact with phosphodiesterase 7B (PDE7B).54 Acetaminophen has been shown to bind with CYP1A1 (cytochrome P450 family 1 .
VIII. RESULTS
The medication audit test used in this review was gotten from the UCI ML asset. This information includes six parts: the name of the medication taken, the audit of the patient, the patient's status, the important count, which shows how much individuals who experienced the survey valuable, the date of the survey passage, and a 10-star patient rating that shows how acceptable the patient is by and large. As per the client's star rating, each audit in this work was classified as one or the other positive or negative. Positive appraisals are those with at least five stars, though negative appraisals shift from one to five stars.
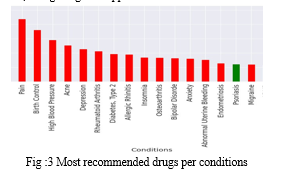
In fig 3 ,we clearly observed that the most conditions who make human to loose their lives due to lack of medicines or drugs are shown in above bar chart diagram.
Conclusion
Reviews are progressively becoming a part of our daily lives, whether we are making purchases, ordering takeout, or shopping online. Reviews assist us in making the best decisions. choices. Perceptron, Multinomial Naive Bayes, Logistic Regression, Ridge classifier, LinearSVC built on TF-IDF, Bow, and classifiers like LGBM, Decision Tree, and Random Forest were among the machine learning techniques utilised to build the recommender system. The Linear SVC utilising TF-IDF exceeds all other models with a 93 percent accuracy, according to our analysis of models using the five key metrics of f1score, validity, recall, precision, and AUC score. The Word2Vec Decision Tree method, on the other hand, performed the poorest, with only 78% accuracy. We combined the highest anticipated emotion values from each LGBM strategy on Word2Vec.
References
[1] Yadav, Ashima, and Dinesh Kumar Vishwakarma. \"A Weighted Text Representation framework for Sentiment Analysis ofMedical Drug Reviews.\" 2020 IEEE Sixth International Conference on Multimedia Big Data (BigMM). IEEE, 2020. [2] Wittich CM, Burkle CM, Lanier WL. Medication errors: an overview for clinicians. Mayo Clin Proc. 2014Aug;89(8):1116-25. [3] Garg, Satvik. \"Drug Recommendation System based on Sentiment Analysis of Drug Reviews using Machine Learning.\" 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence). IEEE, 2021. [4] System for Recommending Drugs Based on Machine Learning Sentiment Analysis of Drug Reviews Ankitha S1, Dr. H N Prakash21Student, Dept. of CSE, Rajeev Institute of Technology, Hassan, Karnataka, India [5] Haibo He, Yang Bai, E. A. Garcia and Shutao Li, ”ADASYN: Adaptive synthetic sampling approach for imbalanced learning,” 2008 IEEE Inter-national Joint Conference on Neural Networks (IEEE World Congresson Computational Intelligence), Hong Kong, 2008, pp. 1322-1328, doi:10.1109/IJCNN.2008.4633969
Copyright
Copyright © 2022 Shubham Thorat, Tushar Bargal, Rahul Chavan, Shraddha Ghodekar, Prof. Nilesh Gunaware. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47474
Publish Date : 2022-11-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online