

Ijraset Journal For Research in Applied Science and Engineering Technology
Early Detection of Brain Degeneration Disease Using Deep Learning
Authors: Prof. Vinay Kumar M, Varshitha R, Srivani G, Swapna , Tejashwini N T
DOI Link: https://doi.org/10.22214/ijraset.2023.51642
Certificate: View Certificate
Abstract
Brain Degeneration Disease (BD) – is an illness that causes memory loss and cognitive decline. It also causes irreversible brain shrinkage, ultimately resulting in death. The creation of efficient treatments for BD depends on early identification. Utilizing machine learning, a branch of artificial intelligence that enables computer systems to gain knowledge from massive and intricate data sets using a variety of statistical and optimization techniques is one promising strategy for the early detection of BD. Several studies have utilized machine learning techniques to detect BD in its early stages. However, these studies have been criticized for their validity due to factors such as the use of non-pathologically verified datasets from various imaging modalities, differences in pre-processing techniques, feature selection, and class imbalance, making it difficult to make a fair comparison between the results obtained. To address these limitations, a novel model has been developed that involves an initial pre-processing step, followed by attribute selection, and finally classification using association rule mining. This model-based approach shows promise for early diagnosis of BD and can accurately distinguish BD patients from healthy controls. The project utilizes modified versions of convolutional neural networks (CNNs) such as VGG16, AlexNet, and MobileNet, which have been adapted to suit specific research goals and objectives. By using this approach, the authors aim to provide a more reliable and robust model for the early detection of BD, ultimately leading to better outcomes for patients.
Introduction
I. INTRODUCTION
Brain Degeneration Disease (BD) is a type of dementia that primarily affects individuals in their middle or old age. This disease is characterized by the progressive decline of cognitive and behavioral functions, which are linked with the degeneration of specific brain cells and the presence of neuritic plaques. The symptoms of BD usually develop gradually over time and can eventually impair an individual's capacity to perform everyday tasks.
The disease can affect people of any age, however advancing years is the greatest risk factor for BD, Initially, the symptoms may be mild, such as minor memory loss, but as the disease progresses, patients can experience a significant decline in cognitive function and communication skills. Although there is no known cure for BD, early diagnosis can help slow down the progression of the disease and improve patients' overall quality of life.
According to projections made by Zhang (2011) and Brookmeyer (2007), the prevalence of BD will rise sharply over the following two decades, resulting in an anticipated doubling of incidence by 2050. Especially in the beginning phases of the disease, a quick and precise identification of BD is essential. A productive cough, a high temperature with shivering shivers, shortness of breath, sharp or piercing chest discomfort during deep breaths, and an increased respiratory rate, on the other hand, are often indications of infectious pneumonia.
Elderly people may exhibit clear symptoms of confusion individuals with Brain Degeneration disease. Machine learning is a valuable tool for data interpretation and analysis, enabling the classification of patterns and modeling of data. It allows for decision-making that may not be feasible with traditional methods, while also saving time and effort (Mitchell, 1997; Duda, 2001). The field of medical imaging has made substantial use of machine learning for computer-assisted diagnosis and information retrieval. (Supekar, 2008; Bookheimer, 2000). Additionally, it has been applied in several other fields and applications (Cruz, 2006). As well as in various other applications (Cruz, 2006). Specifically, machine learning has been used in the detection and classification of brain diseases using CT images (Cruz, 2006) and X-rays (Patrician, 2004). Although machine learning has been applied in many fields, researchers have only recently begun exploring its potential for predicting BD.
The literature on Brain Degeneration disease prediction using machine learning is still limited due to the relative novelty of the field. However, numerous cellular, medical, and biological variables have been measured as a result of the ongoing advancement of imaging techniques and high-throughput diagnostics.
The ability to forecast diseases using conventional metrics and human sense of smell might not always be sufficient, and therefore, non-traditional and computational approaches such as machine learning have become increasingly necessary. The utilization of machine learning in disease prediction and visualization is part of a larger trend toward personalized medicine (Cruz, 2006) and predictive analytics (Weston, 2004). This trend is significant not only for improving patients' health outcomes and quality of life but also for physicians in making treatment decisions and for health economists.
Upon analysis of the existing literature, certain common patterns and limitations were observed. The most prominent trends included the rapid expansion in the utilization of machine learning Methods for BD detection and prognosis. However, there were several gaps identified, such as an imbalance of events with attributes, usage of pathologically unproven data sets which caused uncertainty in the results, class imbalance, overtraining and inadequate external validation. Nonetheless, it became clear from better-designed studies that machine learning techniques, as opposed to conventional statistical techniques, had the ability to increase the precision of BD prediction. Machine learning is a significant tool in predicting and diagnosing BD. However, there are several limitations in the existing studies, such as class imbalance, overtraining, and lack of external validation. A new approach to identifying the first signs of BD is suggested in order to address these problems. This proposed model uses pathologically proven datasets and includes a pre-processing step to eliminate class imbalance. In order to avoid the "curse of dimensionality," it also entails attribute selection utilising machine learning techniques. To prevent over-training, the model separates the collected information as training and testing data then chooses representative training data. The model further applies classification using association rule mining with minimum support and confidence to improve BD prediction accuracy.
II. LITERATURE SURVEY
- The research work described in the accompanying article intends to create an architecture for identifying MRI assessment of brain aspects and Alzheimer's condition diagnosis (AD). The suggested approach is centred using a 3D convolutional network (3D ConvNet) that has AD/NC has three layers that are completely interconnected. classification and five convolutional layers for extraction of features. To determine their effect on AD classification, the study examined several super-parameters pre-processing, data separation, and dataset size. The study used 340 people in an ADNI sample with 1198 MRI scans of the brain. Test results for the suggested method showed:
Accuracy – 98.74%
AD Rate – 100%
False alert rate – 2.4%
Additionally, the proposed method's robustness was shown by comparison with seven cutting-edge techniques.Summary: This article introduces a convolutional artificial neural network (CNN) approach for Alzheimer's disease diagnosis and proposes a CNN design.
2. Google Colaboratory, a service in the cloud built on Jupyter Notebooks supporting machine learning research and education, was thoroughly examined by Carneiro and colleagues. With an emphasis on Colab's capacity to speed up Deep learning and GPU-centric applications, the authors evaluated its hardware capabilities, performance, and constraints. The efficiency of Colaboratory's hardware assets was compared to that of a normal workstation and a 20-core Linux server in the study. The outcomes showed that the based on the cloud service's performance was on par with specialised testbeds that had equivalent resources. The study comes to the conclusion that Colaboratory could be used successfully for deep learning and other GPU-focused applications.
Summary: This paper discusses the use of computer vision techniques such as segmentation and localization in Google Colaboratory for deep learning.
3. By the use Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET) neuroimages, Cheng and Liu presented a novel technique for diagnosing Alzheimer's disease (AD). Instead of relying on manual feature extraction, their solution makes use of multiple levels convolutional neural networks (CNNs) to slowly acquire and merge the multi-modality characteristics for AD classification. The suggested method entails building deep 3D-CNNs, which condenses all of the input from the brain into a finite number of high-level traits specific to each modality. Next, a 2D CNN is cascaded to merge the high-level characteristics for image categorization. This technique can automatically identify general features for AD classification from MRI and PET imaging information.
Summary: This research proposes preprocessing and segmentation of the MRI images using neural networks.
4. Cui and Liu present a novel method for diagnosing Alzheimer's illness with mild cognitive decline by looking at the hippocampus. The majority of current techniques employ MRI imaging to determine the form and volume properties of the hippocampus, which is an important biomarker to determine Alzheimer's illness . The visual characteristics of the hippocampal region are important for the identification of the disease, and the authors speculate that areas close to the hippocampus might be critical for AD diagnosis. Therefore, by using three-dimensional in nature highly interconnected convolutional networks and shape analysis, the authors suggest a novel strategy that combines global and local hippocampus features. By combining local visual and global form cues, this method seeks to improve classification accuracy.
Summary: This study makes a case for categorizing Alzheimer's illness using deep learning methods.
III. PROPOSED SYSTEM:
This system aims at developing an effective solution for the classification of Brain Degeneration disease. To accomplish this task, the system employs four different deep learning algorithms, which are Modified CNN, MobileNet, AlexNet and VGG16. These algorithms were chosen for the capacity to perform classification jobs with high accuracy.
Advantages of proposed system:
- Accurate classification
- Less complexity
- High performance
A. System Architecture:
This project's architecture is based on widely used machine learning prediction methods. To determine if a person has a brain degenerative disease or not, the machine learning model undergoes training using different dataset parameters. Different algorithms for machine learning are used with the pre-processed dataset used for training to train the model such as CNN, VGG16, Alexnet, and MoblieNet models. The model is then evaluated on a separate testing dataset to measure accuracy and performance.
After the model has been trained, the user can input an image to be classified. The stage of the brain degenerative condition that is around, which can be whether you're mildly, moderately, not at all, or very mildly demented, will subsequently be displayed as the outcome. The following Figure shows the proposed system's architectural layout.
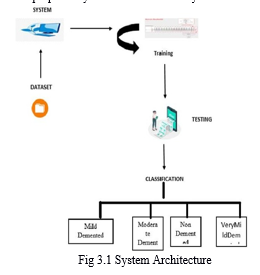
B. Methodology
The proposed system utilizes machine learning techniques to analyze a large dataset of MRI images to identify patterns and relationships that can be used to detect brain degeneration disease. The performance of different algorithms, including CNN, VGG16, AlexNet, and MobileNet, will be assessed to determine the most accurate and effective method for detection. Fig. displays a block diagram of the implementation procedure.
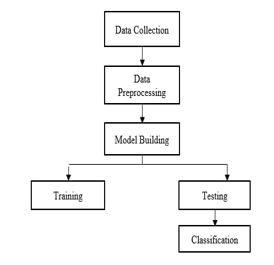
The gathering of data, preprocessing, training, and classification are just a few of the steps that go into categorising different forms of brain degeneration disorders, which include mildly, moderately, not at all, or very mildly demented.
Initially, a dataset of MRI images of Brain Degeneration diseases is collected. The images are then preprocessed by resizing and reshaping them to a suitable format for model training. The model is then trained using Deep Learning Techniques utilising the preprocessed dataset. The photos are then categorised using the trained model into groups like mildly, moderately, not at all, or very mildly demented.
When a user uploads an image, it goes through the same preprocessing and classification process, and the classified image output is displayed.
C. Algorithms
- Convolutional Neural Network:
a. Step 1a: Convolutional operation:
The convolution procedure is used in the Convolutional Neural Network (CNN) process' first stage. The feature detectors in the network of neurons serve as filters during this stage. These feature detectors help in both identifying patterns as well as acquiring the characteristics of feature maps. The neural network is comprised of multiple layers, each detecting various features and mapping out their results. The success of this first phase has a significant impact on the detection process' accuracy.

b. Step 1b: ReLU Layer
The Convolutional Neural Network, or CNN, process continues to the ReLU layer. In order to add nonlinearity to the network, this layer is used. A common activation function in deep learning networks of neurons is the ReLU. Due of its efficacy and simplicity, it is extensively utilised. The highest value among the input and null is produced by the ReLU function using input values. This implies that any adverse data is set to zero and that every positive input is received and processed as is. The function of ReLU can be described mathematically as
Within a neural network, ReLU Layer is often positioned after the convolutional layer. This layer's function is to add nonlinearity to the model. Without non-linearity, the model would be a linear function and would not be able to learn complex relationships between the input and output.
The ReLU layer helps to activate certain features that are important for classification or regression tasks. It helps to reduce noise or pointless data from the data by limiting the inputs that are negative to zero. Faster training and greater accuracy may result from this. Overall, the ReLU layer is an important component in deep learning neural networks, and its simplicity and effectiveness have made it a popular choice for many applications.
c. Step 2: Pooling Layer
The pooling layer, which comes after a convolutional layer within a convolutional neural network (CNN), is a crucial layer. The pooling layers major job is to make the input volume's spatial dimensions smaller, which lowers the future layers of the network's processing and memory needs.
Convolutional Neural Networks (CNNs) use a variety of pooling layers, including maximum pooling, mild pooling, as well as minimum pooling. Maximum pooling is the one of these that CNNs employ the most frequently. The input volume is divided into rectangular, non-overlapping parts by this layer, and the highest value inside each zone is then chosen and output. This results in down sampling the input volume while retaining the most important features.
.Pooling layers can help to make a CNN more robust to small translations in the input data, by creating a degree of spatial invariance. They can also help to reduce over-fitting, by preventing the network from memorizing the precise coordination of properties in the input volume. Finally, pooling layers can help to decrease the computation and required memory space of subsequent layers in given network, making it easier to train and deploy the model on resource-limited devices.
d. Step 3: Flattening
Convolutional Neural Networks (CNNs) have a flattening process that converts a 2D matrix of characteristics into a 1D vector that can be input into a fully interconnected neural network layer. Based on the retrieved features, the network may perform regression and classification tasks by levelling the outcomes of the convolutional and pooling layers. High-level features can be extracted from the input data using this approach, and those features can subsequently be utilised to create predictions or categorise data.
The flattening process occurs after the convolutional and pooling layers have been applied to the input image. The convolutional layers extract relevant features from the input image, while the pooling layers down sample these features and retain only the most significant information. The output from these layers is a set of 2D feature maps. The feature maps must be converted into a 1D vector that can be input towards an entirely connected neural network layer in order to perform regression or classification operations on them. This is achieved by flattening the feature maps into a single vector of values. This vector represents the learned features of the input image and can be used to make predictions. The flattening process does not involve any parameters or learnable weights. It simply reshapes the feature maps into a single vector. The vector is then transferred to any number of fully connected neural network layers for regression or classification after being flattened.
e. Step 4: Full Connection
The fully connected layer in Convolutional Neural Networks (CNNs) is a sort of an layer that normally positions at the end of the network and is in charge of producing predictions based on the learnt features. Its input is the flattened output of the layers of convolution and pooling that came before it. The fully connected layer creates a mapping between the target variable and the high-level characteristics retrieved by the convolutional layers. This is accomplished using a group of neurons, when each neuron forms weighted connections with each neuron in the layer above. These weights are optimised during training to reduce the error of prediction on the training set.
The pooling and convolutional layers receive the input data during the forward motion in order to extract key features. These features are then sent through the fully linked layer after becoming flat and merge as one-dimensional vector. The fully connected layer is made up of a group of neurons that take the input vector that has been provided as their input and multiply it with a set of trainable weights and biases to produce an output. The non-linear activation function, such as the softmax function, is added to the output of the fully connected layer to generate the distribution of probabilities over the possible classes. Using this probability distribution, a forecast is then made, selecting the portion with the largest chance as the output.
The entirely inter-connected layer has a significant impact on how effectively a CNN performs and how well the network generalizes to new inputs. This is accomplished by learning the relationship between the properties of the input and the desired outcome, which enables the neural network to make precise forecasts on data that it has never seen before.
Overall, the flattening process is an essential step in a CNN as it allows for the retrieval of meaningful properties from the input picture and enables the network to perform complex classification or regression tasks.
2. VGG16
The VGG16 model is a deep - CNN created by the group called Visual Geometry Group, which was founded at the university of Oxford in 2014. Numerous computer vision applications use it, for picture identification, identifying objects, and segmentation. Due to its outstanding performance, this particular version of the first the VGG network has proven widely used in the computer vision industry. A CNN of sixteen layers, containing thirteen convolutional layers and 3 fully inter-connected layers, is the VGG16 architecture. Each layer in this design executes the 3x3 convolution operation and implements a rectified linear unit's (ReLU) activating function, layering convolutional layers of identical size. The application of max-pooling approaches minimise the feature maps' spatial components. The top layer of the network is the softmax layer, which creates the allocation of chances over all potential classes. A convolutional neural network created primarily for image classification applications is the VGG16. It has three fully linked layers and 13 convolutional layers. Each block of the convolutional layers, which are arranged sequentially, has several 3x3 convolutional layers as well as a max pooling layer for representations of data with multiple. 4,096 neurons each are present in the first two completely linked layers, and the final fully linked layer contains 1,000 neurons enabling the categorization of 1,000 groups. Class probabilities are computed employing the activation function of softmax from the results of the last layer. The VGG16 has shown state-of-the-art performance on a variety of benchmarking data sets, such as the ImageNet large-scale visual recognition contest (ILSVRC) during 2014, where it reached a top-5 error rate of 7.5%. It is an effective framework for transfer learning in many computer vision applications because of its simplicity and great accuracy.
3. MobileNet
Google created MobileNet, a CNN architecture, in 2017 with mobile and embedded vision software in mind. It has depth wise separated convolutional layers, which are made up of pointwise and depth wise convolutional layers. The point-by-point convolution layer mixes the outcomes of the depth wise convolution layer using a 1x1 convolution, whereas the depth wise convolution layer performs an spatial convolution operation independently to each input channel. This layout helps the network operate more efficiently and with less memory usage while retaining high accuracy. With fewer parameters in the network due to the use of depthwise separated convolution, inference times and memory usage are sped up. During the final fully connected layer, a layer for world-wide average pooling is added to further minimise the numeral parameters and guard against overfitting. From MobileNetV1 to MobileNetV3, there are various versions of MobileNet available, each with new architectural features. Squeeze-and-excitation modules, for instance, are used in MobileNetV2, while neural architecture search is used in MobileNetV3. Because of its efficiency and precision, MobileNet is a great option of real-time video and image categorization on mobile devices along with other platforms with limited resources. It has demonstrated strong performance on many benchmarked datasets.
4. Alex Net
In their article "ImageNet Classification using Deep Convolutional Neural Networks" from 2012, Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton introduced the deep-CNN known as AlexNet. It outperformed the next runner-up by a large margin and took first place in the 2012 the ImageNet large-scale visual recognition contest (ILSVRC) with peak-5 error rates of 15.3%.
Architecture of AlexNet consists of 8 layers, containing five convolutional layers and three fully linked layers. The initial convolutional layer contains 96 kernels that are 11x11 in size, the 2nd layer consists of 256 kernels that are 5x5 in size, and the 3rd layer consists 384 kernels that are 3x3 in size. The fourth and the fifth convolutional layers, respectively, feature 384 and 256 3x3 kernels. Max-pooling layers come after every convolutional layer.
The implementation of the Rectified Linear Unit (ReLU) activated function, which performed better than the conventional sigmoid activation function, was one of AlexNet's noteworthy contributions. To expand the training dataset and enhance the model's generalizability, additionally, the authors applied data enhancement methods like accidental popping and straight flipping. As a result, the model's precision increased, and overfitting was decreased.
A major development in the realm of computer vision, AlexNet paved the path for the creation of more complex and potent convolutional neural networks.
IV. FUTURE ENHANCEMENTS
Larger datasets: While current datasets have provided good results, larger datasets may help improve the accuracy of the models. Efforts should be made to collect more data from diverse populations to train and validate the models.
Longitudinal data: Brain Degeneration disease is a progressive disease, and analyzing data over time may provide more accurate and reliable diagnosis. Gathering and analyzing longitudinal data on the progression of the disease may help to identify earlier signs of the disease and improve diagnostic accuracy. Multimodal data: Combining information from various sources, such as MRI scans, genetic information, and cognitive evaluations, may assist to increase the precision of models used to diagnose brain degeneration. Integrating data from several sources may help to better understand the condition and may assist to find more accurate biomarkers.
Explainable AI: One of the biggest problems with utilizing AI models to diagnose brain degeneration is that they are difficult to understand. A greater knowledge of the underlying mechanics of the disease may result from the development of explainable AI models, which could assist in identifying the specific characteristics that lead to the diagnosis.
Create a user-friendly platform where people are able to post their brain images for analysis in order to identify those who are at a higher risk for acquiring brain degeneration at a young age, which can result in more effective treatment.
Conclusion
The goal of this project was to create a deep learning-based method for categorizing MRI scans into four groups: mildly, moderately, not at all, or very mildly demented. The project\'s major goal was to reliably assess a patient\'s level of dementia using their MRI scans. The dataset used in this project consisted of a large number of MRI images, which were first preprocessed to enhance the pictures\' quality. Three different deep learning algorithms were used in this project, namely Modified CNN, MobileNet, and VGG16. These algorithms were trained on the preprocessed MRI images to develop a robust and accurate classification model. After training, the model was tested by uploading a new MRI image and classifying it into one of the four categories based on the pattern of the image. The efficacy of this experiment may aid in dementia early diagnosis, which is essential for dementia therapy and management. Keep in understanding that the accuracy of the model can change depending on the quality of the MRI images and the range of data in the training dataset.
References
[1] Bäckström, K., Nazari, M., Gu, I.Y., Jakola, A.S.: An efficient 3D deep convolutional network for Alzheimer’s disease diagnosis using MR images. In: 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), pp. 149–153, April 2018. [2] Carneiro, T., Medeiros Da NóBrega, R.V., Nepomuceno, T., Bian, G., De Albuquerque, V.H.C., Filho, P.P.R.: Performance analysis of Google colaboratory as a tool for accelerating deep learning applications. IEEE Access 6, 61677–61685 (2018). [3] Cheng, D., Liu, M.: CNNs based multi-modality classification for AD diagnosis. In: 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), pp. 1–5, October 2017. [4] Cui, R., Liu, M.: Hippocampus analysis by combination of 3-D DenseNet and shapes for Alzheimer’s disease diagnosis. IEEE J. Biomed. Health Inform. 23(5), 2099–2107 (2019). [5] Jabason, E., Ahmad, M.O., Swamy, M.N.S.: Classification of Alzheimer’s disease from MRI data using an ensemble of hybrid deep convolutional neural networks. In: 2019 IEEE 62nd International Midwest Symposium on Circuits and Systems (MWSCAS), pp. 481–484, August 2019. [6] Khan, S., Rahmani, H., Shah, S., Bennamoun, M.: A Guide to Convolutional Neural Networks for Computer Vision. Synthesis Lectures on Computer Vision, No. 1. Morgan & Claypool Publishers (2018). [7] Hara, K., Kataoka, H., Satoh, Y.: Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet? In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6546–6555 (2018)Google Scholar [8] He, G., Ping, A., Wang, X., Zhu, Y.: Alzheimer’s disease diagnosis model based on three- dimensional full convolutional DenseNet. In: 2019 10th International Conference on Information Technology in Medicine and Education (ITME), pp. 13–17, August 2019. [9] Cohen, J.P., Bertin, P., Frappier, V.: Chester: A Web Delivered Locally Computed Chest X-Ray Disease Prediction System. arXiv:1901.11210 (2019) [10] Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, pp. 2261–2269 (2017). [11] Kollias, D., Tagaris, A., Stafylopatis, A., Kollias, S., Tagaris, G.: Deep neural architectures for prediction in healthcare. Complex Intell. Syst. 4(2), 119–131 (2017). [12] Lee, C.S., Nagy, P.G., Weaver, S.J., Newman-Toker, D.E.: Cognitive and system factors contributing to diagnostic errors in radiology. Am. J. Roentgenol. 201(3), 611–617 (2013).
Copyright
Copyright © 2023 Prof. Vinay Kumar M, Varshitha R, Srivani G, Swapna , Tejashwini N T. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET51642
Publish Date : 2023-05-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online