

Ijraset Journal For Research in Applied Science and Engineering Technology
Efficient Technique on Face Recognition Using CNN
Authors: Vivek Rai, Debasree Das, Sunistha Kundu, Arpita Santra
DOI Link: https://doi.org/10.22214/ijraset.2021.39531
Certificate: View Certificate
Abstract
World is facing a severe health crisis due to the fast transmission of the coronavirus(Covid-19).WHO has issued many guidelines for prevention of the spread of coronavirus. According to WHO, the best way to reduce the spread of coronavirus is by wearing mask in public and crowded areas. In this paper, a 2-stage CNN model is proposed to check whether the people are wearing mask or not. The proposed model is trained and tested on a number of data sets.
Introduction
I. INTRODUCTION
In the new world of coronavirus, multidisciplinary efforts[1,2] have been organized to slow the spread of the pandemic. The AI community has also been a part of these endeavours. In particular, developments for monitoring social distancing or identifying face masks have made-the-headlines. Rapid advancements in the fields of Science and Technology have led us to a stage where we are capable of achieving feats that seemed improbable a few decades ago. Technologies in fields like Machine Learning and Artificial Intelligence have made our lives easier and provide solutions to several complex problems in various areas. Modern Computer Vision algorithms are approaching human-level performance in visual perception tasks. From image classification to video analytics , Computer Vision has proven to be a revolutionary aspect of modern technology. In a world battling against the Novel Coronavirus Disease (COVID-19) pandemic, technology has been a lifesaver. With the aid of technology, ‘work from home’ has substituted our normal work routines and has become a part of our daily lives. However, for some sectors, it is impossible to adapt to this new norm. As the pandemic slowly settles and such sectors become eager to resume in-person work, individuals are still skeptical of getting back to the office. 65% of employees are now anxious about returning to the office (Woods, 2020). Multiple studies have shown that the use of face masks reduces the risk of viral transmission as well as provides a sense of protection. However, it is infeasible to manually enforce such a policy on large premises and track any violations. Computer Vision provides a better alternative to this. Using a combination of image classification, object detection, object tracking, and video analysis, we developed a robust system that can detect the presence and absence of face masks in images as well as videos. In an effort to paint a more complete picture, we decided to show the creative process behind a solution for a seemingly simple use case in computer vision:Identify face mask usage. In this paper, we propose a two-stage CNN architecture, where the first stage detects human faces, while the second stage uses a lightweight image classifier to classify the faces detected in the first stage as either ‘Mask’ or ‘No Mask’ faces.
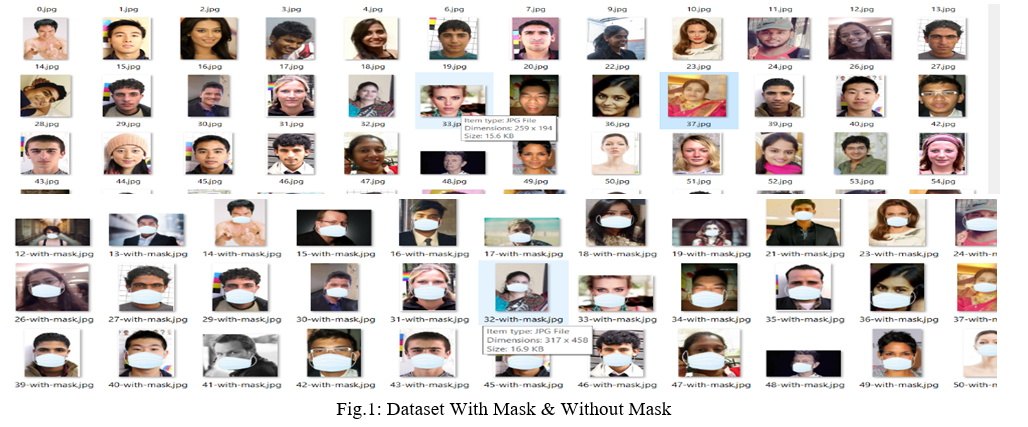
II. THE DATASET
In this paper, we have used Simulated Masked Faced Dataset(SMFD). It hasapproximately 1500 images that consist of 750 mask images and 750 without mask images. From this dataset,1200 images of both categories are used for training and the remaining 300 images are used for testing the model. Few images are given as shown in Fig.1.
III. PROPOSED METHODOLOGY
The stages of computation that we follow for our model is the pre-processing is done then the testing & training is done and after that the classification is done.
A. Pre-processing
Data is the most important component of Machine Learning[3]. In order to train models, we should have the ‘right data’ in the ‘right format’ and in the right size. Firstly, we collect the dataset from the public domain containing images of person wearing mask and without mask. These images collected from the public domain are raw images . These raw images are to be processed before they are ready to use. Each image is different from other image based on size. More uniformity in data means more accuracy of the model. All the images are converted to gray scale images where the gray scale images are the ones which consists of 8 bits per pixel. This means it canhave 256 different shades where 0 pixels will represent black color while 255 denotes white. A grayscale image has only 1 channel where the channel represents dimension. So, this process of converting original image to gray scale image is applied to every image , since the Computer understand the image as array of pixel values. So, every image is converted to array of its pixel value where 0 denote black and 255 denote white and then it is resized to a specific dimension.
B. Training and Testing Of Data
Training data and testing of data are two important concepts in machine learning.
- Training Data: The observations in the training set form the experience that the algorithm uses to learn. In supervised learning problems, each observation consists of an observed output variable and one or more observed input variables
- Test Data: The test set is a set of observations used to evaluate the performance of the model using some performance metric. It is important that no observations from the training set are included in the test set. If the test set does contain examples from the training set, it will be difficult to assess whether the algorithm has learned to generalize from the training set or has simply memorized it. A program that generalizes well will be able to effectively perform a task with new data. In contrast, a program that memorizes the training data by learning an overly complex model[4] could predict the values of the response variable for the training set accurately, but will fail to predict the value of the response variable for new examples. Memorizing the training set is called over-fitting. A program that memorizes its observations may not perform its task well, as it could memorize relations and structures that are noise or coincidence. Balancing memorization and generalization, or over-fitting and under-fitting, is a problem common to many machine learning algorithms. Regularization may be applied to many models to reduce over fitting.
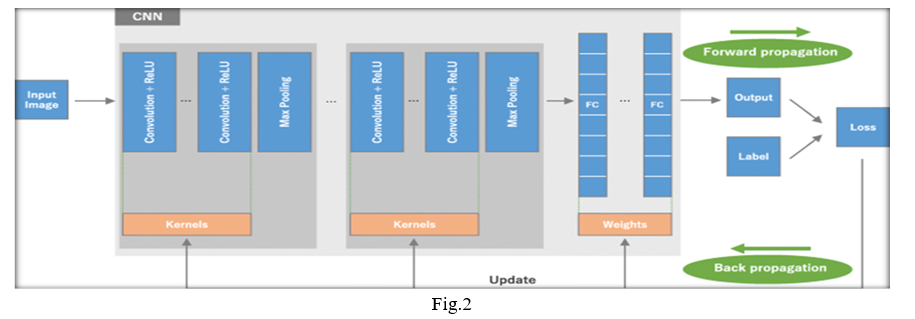
C. Classification
The main process that we have used for our model is by using CNN.Convolutional Neural Networks (ConvNets or CNNs) are a category of Neural Networks that haveproven very effective in areas such asimage recognition and classification.In digital images, pixel values are stored in a two-dimensional (2D) grid, i.e., an array of numbers (above Fig), and a small grid of parameters called kernel, an optimizable feature extractor, is applied at each image position, which makes CNNs highly efficient for image processing, since a feature may occur anywhere in the image. As one layer feeds its output into the next layer, extracted features can hierarchically and progressively become more complex. The process of optimizing parameters such as kernels is called training, which is performed so as to minimize the difference between outputs and ground truth labels through an optimization algorithm called backpropagation and gradient descent, among others.
A CNN[5] is composed of a stacking of several building blocks as shown in Fig.2: convolution layers, pooling layers (e.g., max pooling), and fully connected (FC) layers. A model’s performance under particular kernels and weights is calculated with a loss function through forward through forward propagation on a training dataset, and learnable parameters, i.e., kernels and weights, are updated according to the loss value through backpropagation with gradient descent optimization algorithm. ReLU, rectified linear unit.
- Convolution Layer: A convolution layer is a fundamental component of the CNN architecture that performs feature extraction, which typically consists of a combination of linear and nonlinear operations, i.e., convolution operation and activation function.
- Nonlinear Activation Function: The outputs of a linear operation such as convolution are then passed through a nonlinear activation function. Although smooth nonlinear functions[6], such as sigmoid or hyperbolic tangent (tanh) function, were used previously because they are mathematical representations of a biological neuron behaviour, the most common nonlinear activation functionused presently is the rectified linear unit (RELU),which simply computes the function:f(x)=max(0,x) In this model, we have used Relu activation function .
a. Why ReLU is Important: ReLU’s purpose is to introduce non-linearity in our ConvNet. Since, the real world data would want our ConvNet to learn would be non-negative linear values.
3. Pooling Layer: Pooling layers section would reduce the number of parameters when the images are too large. Spatial pooling also called subsampling or downsampling which reduces the dimensionality of each map but retains important information. Spatial pooling can be of different types:
a. Max Pooling
b. Average Pooling
c. Sum Pooling
Max pooling takes the largest element from the rectified feature map. Taking the largest element could also take the average pooling. Sum of all elements in the feature map call as sum pooling. In our model we have used the max pooling method.
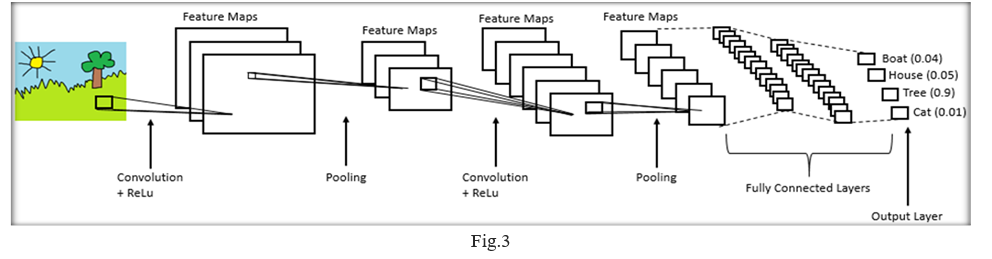
4. Fully Connected Layer: The layer we call as FC layer, we flattened our matrix into vector and feed it into a fully connected layer like a neural network. With the fully connected layers, we combined these features together to create a model. Finally, we have an activation function such as softmax or sigmoid to classify the outputs into certain classes as shown in (Fig.3).
IV. RESULT
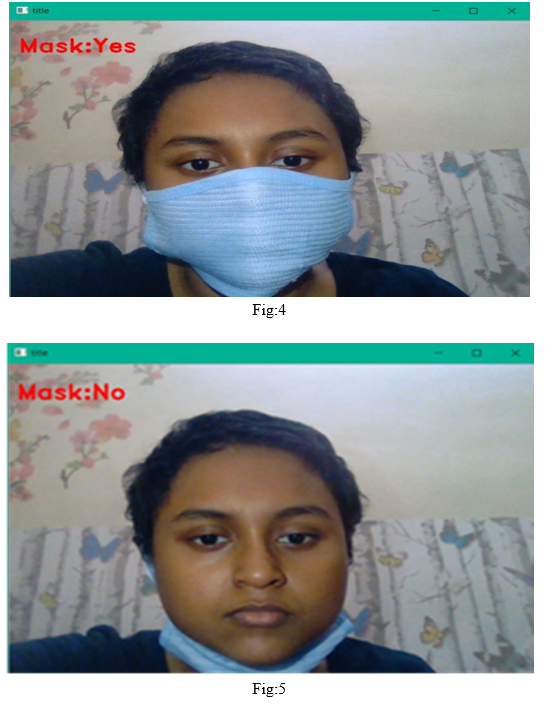
After classification of images and training of model , our fully connected Convolution Neural Network is ready to use . After loading the model, we use web cam to capture the live images. After capturing live images from web cam we resize and fed the live image to our model for prediction . Our model return the probability of having mask and without mask and based on accuracy of the model we came to know that the user or the person is wearing mask or not . As shown in Fig.4
Conclusion
This Face Mask detection project can capture single image at a time and give the prediction . This program of detection of Face mask does not depend on gender. Corporate giants from various verticals are turning to AI and ML, leveraging technology at the service of humanity amid the pandemic. Digital product development companies are launching mask detection API[7] services that enable developers to build a face mask detection system quickly to serve the community amid the crisis. The technology assures reliable and real-time face detection of users wearing masks. Besides, the system is easy to deploy into any existing system of a business while keeping the safety and privacy of users’ data. So the face mask detection system is going to be the leading digital solution for most industries, especially retail, healthcare, and corporate sectors andwill also to serve the communities with the help of digital solutions.
References
[1] J. Deng, J. Guo, N. Xue, S. Zafeiriou, “ArcFace: Additive Angular Margin Loss for Deep Face Recognition,” in CVPR, Jun. 2019, pp. 4685-4694. [2] B. Liu, W. Deng, Y. Zhong, M. Wang, J. Hu, X. Tao, and Y. Huang,“Fair Loss: Margin-Aware Reinforcement Learning for Deep Face Recognition”, in ICCV, Oct. 2019, pp. 10051-10060. [3] M. Cascella, M. Rajnik, A. Cuomo, S. C. Dulebohn, and R. Di Napoli,‘‘Features, evaluation and treatment coronavirus (COVID-19)[updated 2020 Apr 6],’’ in StatPearls [Internet]. Treasure Island,FL, USA: StatPearls Publishing, Jan. 2020. [Online]. Available: https://www.ncbi.nlm.nih.gov/books/NBK55477/ [4] World Health Organization. Coronavirus disease (COVID-19)Pandemic. Accessed: Apr. 30, 2020. [Online]. Available: https://www.who.int/emergencies/diseases/novel-coronavirus-2019. [5] C. Wang, P. W. Horby, F. G. Hayden, and G. F. Gao, “A novel coronavirus outbreak of global health concern,” The Lancet,vol. 395, no. 10223, pp. 470–473, 2020. [6] Q. Li, X. Guan, P. Wu et al., “Early transmission dynamics in Wuhan, China, of novel coronavirus–infected pneumonia,” New England Journal of Medicine, vol. 382, no. 13, pp. 1199–1207, 2020. [7] J. Cohen and D. Normile, “New SARS-like virus in China triggers alarm,” Science, vol. 367, no. 6475, pp. 234-235, 2020.
Copyright
Copyright © 2022 Vivek Rai, Debasree Das, Sunistha Kundu, Arpita Santra. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET39531
Publish Date : 2021-12-20
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online