

Ijraset Journal For Research in Applied Science and Engineering Technology
Emotion Detection on text using Machine Learning and Deep Learning Techniques
Authors: Balapuri ShivaSundar, Vadlakonda Rohith, Bhukya Suman, Kottoju Nagendra Chary
DOI Link: https://doi.org/10.22214/ijraset.2022.44293
Certificate: View Certificate
Abstract
Emotion detection on text is an important field of research in Artificial Intelligence and human-computer interaction. Emotions play key role in human interaction. Emotion detection is closely associated with sentiment detection, in which we detect the polarity of the text. But in emotion detection, we detect emotions such as joy, love, surprise, sadness, fear, and anger. Emotion detection helps the machines to understand human behavior and ultimately it provides users with emotional awareness feedback. In this paper, we are going to compare Machine Learning and Deep Learning techniques with their accuracy and f1 scores. The experimental results show the results provided by deep learning techniques (Bi LSTM and Bi GRU) with word embeddings are more accurate than the other techniques.
Introduction
I. INTRODUCTION
Emotion is subjective, complicated, and sensitive to the context. Emotional acceptance is used in several fields like medicine, law, advertising, etc. There are numerous techniques to detect human emotions, a few of them are by perceiving facial expressions, body movements, pressure level, heartbeat rate, etc.
But detecting emotion from the text is the difficult one, since all the previously mentioned processes have an environment and context. There is a lot of textual data on the internet that is to be classified to improve human-computer interaction. Emotion detection can be used in applications like-, Public sentimental analysis, social-media communication, and human-computer interaction.[3]
This paper considers six basic emotions joy, sadness, love, fear, anger, and surprise.
In this paper, we are going to use two machine learning (Random Forest classification and Logistic Regression) and two deep learning algorithms (Bi-LSTM and Bi-GRU). In deep learning, we are going to use pre-trained word embeddings .
Model performance is evaluated by prediction and accuracy. In the end, we compare the performances of models to predict the best model.
II. LITERATURE SURVEY
As emotion detection in text has lots of applications, the research in it is still developing and ongoing. There are various methods developed by researchers.
There are traditional methods that use the keywords in the sentence, which are called as lexicon-based methods and there are methods that use traditional machine learning algorithms, and find the emotion of the sentence [6] and there are some methods where deep learning methods like LSTM[2] and CNN are applied to the classification.
Word embedding is a technique that is used to replace the text with feature vectors that can be used to embed the text .
Though many researchers have proposed many different methods, there is always room for development. Therefore we aim to develop a method based on Bi LSTM and Bi GRU.
III. PROPOSED SYSTEM
This section describes various steps of our proposed system. Fig 1 shows the machine learning approach architecture and Fig 2 shows the deep learning approach architecture.
A. Machine Learning Approach
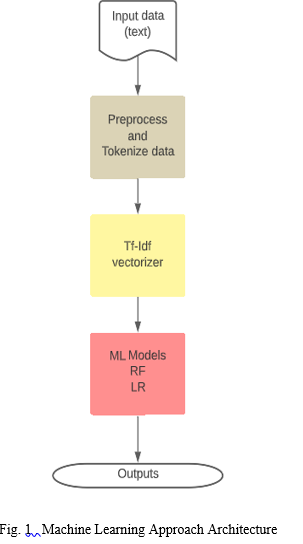
There are three steps involved in the machine learning approach.
- Preprocess and tokenize text:
a. Preprocess: In this step, we are removing all the punctuations, Html markups, hashtags, URLs, @names, and extra whitespaces and we are removing stop words, lemmatizing, and, stemming text.
b. Tokenize: Here we are converting all the sentences into tokens of words.
2. TF-IDF Vectorizer
TF-IDF Vectorizer is used to transform the text to feature vectors which can be used as inputs to the models. Here we transform input data into features.
3. ML Models
Here we are using two machine learning models
a. Random Forest Classifier: Random forest classification is an ensemble learning technique, which uses a technique called Bagging and it is easy to implement and provides better results than other traditional machine learning algorithms.
b. Logistic Regression: Logistic Regression is a statistical model that is used to predict probabilities of different possible results (outputs). This paper uses Multinomial logistic regression. This machine learning approach is used to compare the traditional methods with the RNN methods. The actually proposed method follows from here.
B. Deep Learning Approach
After preprocessing and tokenizing the data, we have converted those tokens into sequences and created an embedded matrix using pre-trained word vectors. By using the embedded matrix as weights we have created an embedded layer. Then we added the Bidirectional LSTM / Bidirectional GRU layers.
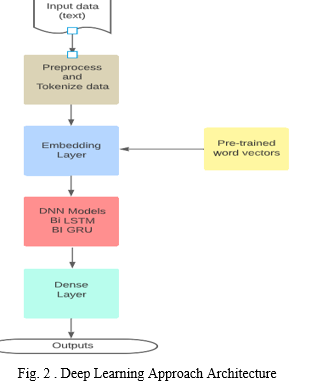
- DNN Models
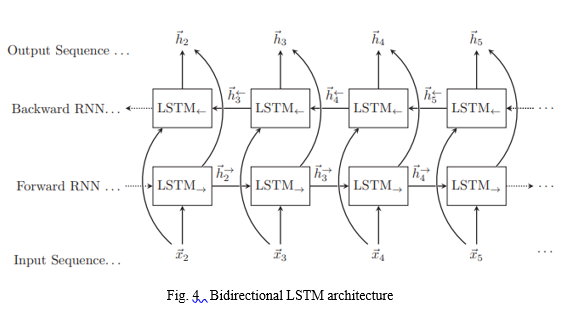
a. Bidirectional LSTM
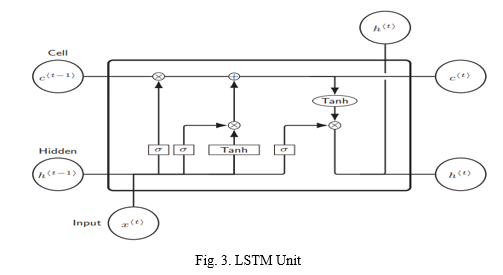
Bidirectional LSTM is a type of RNN, that consists of two LSTMs, that take inputs in both directions.
LSTM unit has cell, an input gate, an output gate, and a forget gate. The cell remembers values over arbitrary time intervals and the three gates regulate the flow of information in and out of the cell.
Forget gate is used to choose whether to remember the previous information or not.
Input gate is employed to quantify the importance of the new information carried by the input.
The output gate is used to determine the information in the state to be routed to the output.
b. Bidirectional GRU
Bidirectional GRU is a type of RNN, that consists of two GRUs, that take inputs in both directions.
GRU unit has two gates, an update gate, and a reset gate.
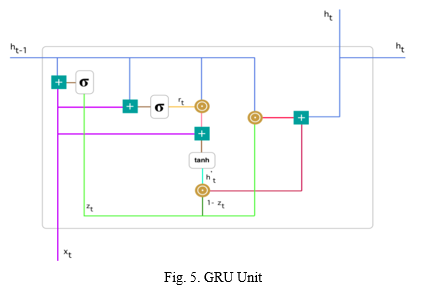
Update gate is used to see what proportion of the past information must be passed along to the future.
Reset gate is used to see what proportion of past information to forget.
2. Dense Layer
A dense layer is a deeply connected layer that is used to change the dimension of the output.
IV. EXPERIMENT AND RESULTS
A. Experimental Environment
In this paper, we have used Ubuntu 20.04 as the operating system, with 8GB RAM – 1TB Disk space as hardware, we used python 3.10 as the programming language and jupyter notebook as IDE.
B. Evaluation Metrics
We are using accuracy and f1 score as metrics to evaluate the model.
C. Emotion Recognition Dataset
The dataset we used is from Kaggle (‘Emotions Dataset for NLP’), it has two CSV files, one is for training and the other is for testing. It has two columns, content and sentiment. The training dataset has 16000 rows and the test dataset has 2000 columns.
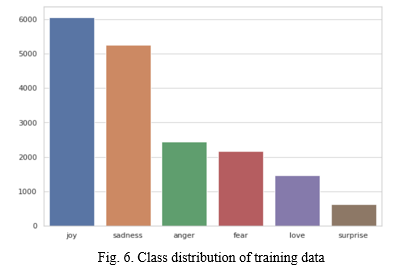
There are 6 labeled classes in the dataset – joy, sadness, anger, surprise, fear, and love.
Fig shows the training data class distribution.
D. Data Preprocessing
In section IIIA data preprocessing is covered.
E. Hyper Parameter Setting and Training
- Machine learning Techniques: We have used random forest and logistic regression. Table I and Table II provide the details of the parameters used in our model.
TABLE I
HYPERPARAMETERS OF RANDOM FOREST
|
Parameter |
Random Forest |
|
n_estimators |
50 |
|
max_features |
“auto” |
TABLE III
HYPERPARAMETERS OF LOGISTIC REGRESSION
|
Parameter |
Logistic Regression |
|
solver |
“lbfgs” |
|
Multi classes |
“auto” |
|
Max iterations |
200 |
2. Deep Learning Techniques: We have used BiLSTM and BiGRU. Table 3 provides the details of the parameters used in our model.
TABLE III
HYPERPARAMETERS OF Bi LSTM Bi GRU
|
Parameter |
Bi LSTM / Bi GRU |
|
batch size |
128 |
|
Learning rate |
0.001 |
|
Drop out |
0.2 |
|
epochs |
15 |
|
optimizer |
adam |
F. Results
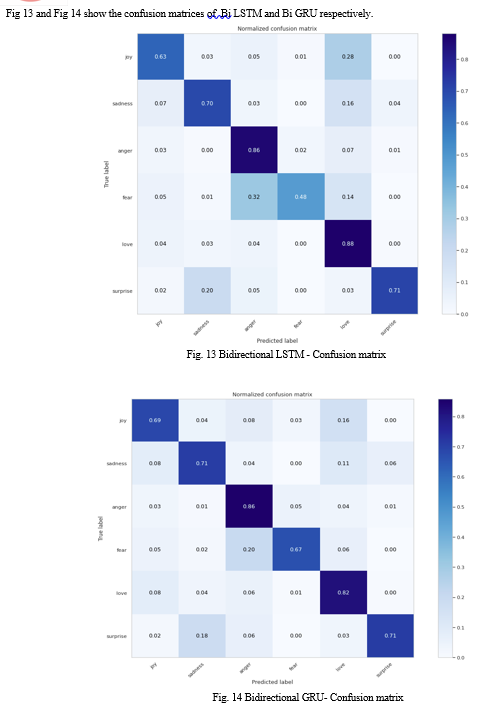
We have used accuracy, f1score(weighted) metrics, and confusion matrix, to show our results.
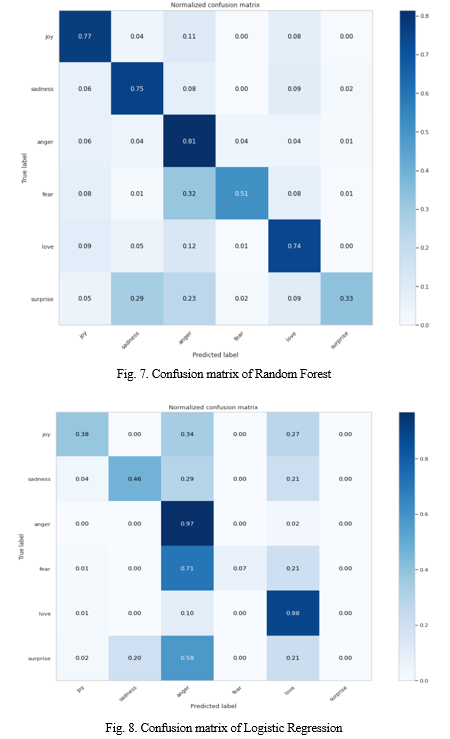
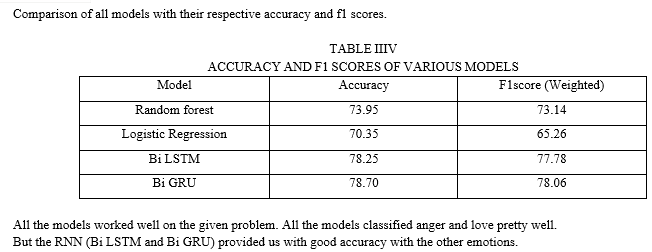
- Machine Learning Techniques: Among the machine learning approaches Random forest achieved the highest accuracy of (73.95%) and an f1score of (73.14) and Logistic Regression achieved an accuracy of (70.35%) and an f1score of (65.26).
Fig 7 and Fig 8 show the confusion matrices of Random Forest and Logistic Regression respectively.
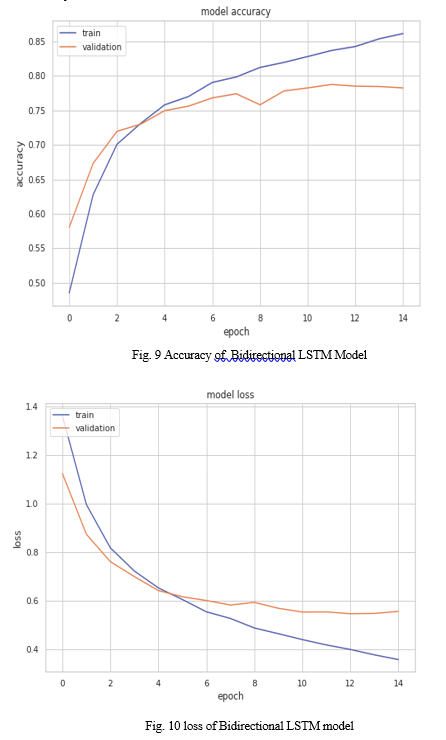
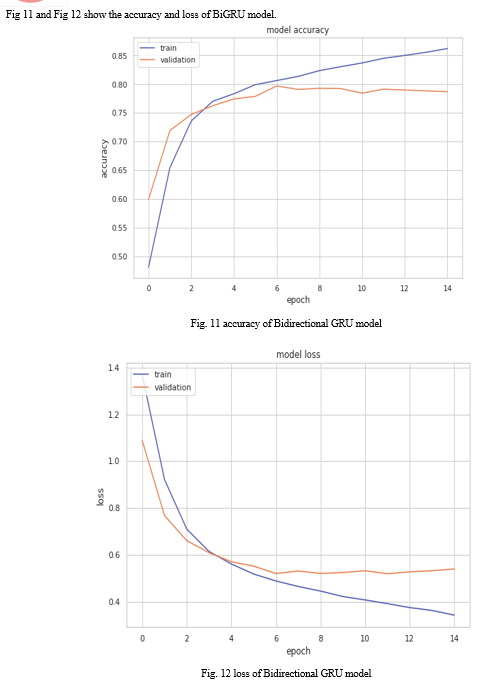
2. Deep Learning Techniques: Both approaches (BiLSTM and BiGRU) gave almost the same accuracies. BiGRU achieved an accuracy of (78.70%) and an f1score of (78.06) and BiLSTM achieved an accuracy of (78.25%) and an f1score of (77.78).
Fig 9 and Fig 10 show the accuracy and loss of BiLSTM model.
Conclusion
This paper investigated many Machine Learning models and RNNs. By seeing the above results we can conclude that the RNNs are performing better than the traditional machine learning algorithms in text emotion detection. Since, LSTM and GRU are the sequential models that are mainly used for NLP, they give better results. And we can conclude that statement experimentally by proving Bi LSTM (78.25% accuracy) and Bi GRU (78.70% accuracy) are giving better results. In the future, we can improve this area of research by implementing sophisticated deep neural networks or combining Neural network layers, and training the model with a lot of data.
References
[1] Seo-Hui Park, Byung-Chull Bae, Yun-Gyung Cheong, - Emotion-Recognition from Text Stories Using an Emotion Embedding model, IEEE ,2020. [2] Mounika Karnaa, Sujitha Juliet D.b, R.Catherine Joyc, - Deep learning-based Text Emotion Recognition for Chatbot applications, IEEE,2020 [3] Avishek Das, Omar Sharif, Mohammed Moshiul Hoque, and Iqbal H. Sarker – Emotion-Classification in a Resource Constrained Language Using Transformer-based Approach, arXiv:2104.08613v1 [cs.CL] , 2021. [4] Xinzhi Wang, Luyao Kou, Vijayan Sugumaran, Xiangfeng Luo, and Hui Zhang - Emotion Correlation Mining Through Deep Learning Models on Natural Language Text , IEEE Xplore,2020. [5] Erdenebileg Batbaatar, Meijing Li, And Keun Ho Ryu - Semantic-Emotion Neural Network for Emotion Recognition from Text, IEEE Access,2019. [6] Bernhard Kratzwald,Suzana Ili?,Mathias Kraus,Stefan Feuerriegel,Helmut Prendinger, - Deep learning for affective computing: Text-based emotion recognition in decision support ,Elsevier, November 2018.
Copyright
Copyright © 2022 Balapuri ShivaSundar, Vadlakonda Rohith, Bhukya Suman, Kottoju Nagendra Chary. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44293
Publish Date : 2022-06-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online