

Ijraset Journal For Research in Applied Science and Engineering Technology
Enhancing Financial Auditing through Big Data: Leveraging Convolutional Neural Networks
Authors: Chowlur Ananda Naga Chaitanya, Byreddy Akhileswar Reddy
DOI Link: https://doi.org/10.22214/ijraset.2023.54405
Certificate: View Certificate
Abstract
Traditional auditing methodologies are going through demanding situations within the big facts age, together with restrained audit scope, unbalanced audit power allocation, and insufficient audit assessment. To reap high performance, the usage of huge statistics analytic procedures in economic auditing has been a sparkling trend on this area. Because of its first rate diploma of flexibleness, deep learning has grown to be famous in loads of fields. As a result, this studies adopts a not unusual deep studying version convolution neural community (CNN) and presents a big statistics-driven monetary auditing method based totally on CNN. Specifically, CNN\'s strong function abstraction capability is used to extract multi-stage features in substances, including visible characteristics, textual abilties, and so on.
Introduction
I. INTRODUCTION
With the advancement of massive records technology and the quick enlargement of company statistics, governments and organizations are intentionally attempting to use huge information technology to enhance governance and operational tiers [1].By growing an audit massive statistics platform to capture essential electronic audit data, the government wants to boom audit efficiency and audit insurance [2].It is represented by a whole series of organised and unstructured records, along with public fee range, nation-owned assets, and country-owned assets [3].In the modern economy, finance's primary function affects a country's healthy growth to a degree, and massive awful outcomes of economic risks damage america's economic and economic protection [4].As a end result, developing green financial auditing methods for key administration departments so one can beef up such supervisory capability has come to be more and more critical [5].The growing abundance of records, especially inside the age of large records, has posed new demanding situations to human knowledge. It continues to be a promising belief in trendy environment to apply synthetic intelligence algorithms to carry out clever auditing operations [6]. Many Internet financial companies have formed due to the monetary market's diversification and the increasing funding needs of small, medium, and micro organizations [7].Consumer finance organizations, on line micro-mortgage corporations, and P2P platforms are examples of those groups [8].It has performed an essential function in pleasurable SMEs' capital desires and fostering their improvement [9].The call for cash has extended, and as a result, the Internet credit industry has experienced an brilliant boom [10].However, as the Internet finance sector grows speedy, extra problems sooner or later floor [11]. It is viable to elevate the calibre and comparison of auditable work papers through using cloud computing and economic auditing techniques. In the cloud auditing model, each economic unit's financial transaction statistics is simultaneously saved at the cloud platform installation by the cloud provider. Auditors A particular developer not handles the advent, renovation, and updating of the audit software and programmes utilised. Additionally, technical problems may be totally delegated to certified cloud software program builders, boosting the compatibility of audit software. On the other hand, each economic entity makes use of the cloud platform. As a end result, they can learn how to control state-of-the-art audit equipment, to be able to significantly boom the audit's performance and satisfactory [12].
Both the excessive extent of records and the low performance of the earlier effort provide a challenge. In order to achieve the preferred consequences, we hire a new way to geometrically lessen the quantity of records applied to its performance. Big records finance is a rising financial paradigm because of the monetary industry's constant network and virtualization expansion. The economic zone has assumed the lead in developing information centres and updating software program and hardware structures inside the age of massive facts. Financial dangers step by step increase in conjunction with the ongoing innovation of economic offerings. Financial auditing has to adapt to the times as a critical sort of monetary supervision.
The utilisation of huge records technologies to deal with new troubles inside the economic auditing technique is the pinnacle priority. Massive amounts of information may be right now locked with the auditing's crucial factors, increasing audit effectiveness. This makes it feasible to pick out problems extra speedy, exactly, and correctly. The auditing of government finances is extraordinarily vital for countrywide governance. As an end result, this research proposes a convolution neural network-based huge statistics-pushed monetary auditing solution. In unique, CNN's powerful feature abstraction abilities are used to extract multi-level traits from substances, along with visible and textual facts. Then, the multi-supply capabilities from auditing substances can be properly fused for very last discrimination. The predominant contributions of our paintings are as follows:
- This paper introduces the development popularity of huge facts and the principle big facts technologies, blended with the issues faced by way of economic auditing inside the technology of huge statistics, and analyses the shortcomings of conventional auditing methods.
- The application of pc-aided auditing is proposed. Based at the monetary auditing practice, the case evaluation of the actual facts of the bank is done.
- The associated technology has reference price in the construction of an audit massive statistics platform. This paper combines traditional auditing techniques with new technology and new thoughts inside the massive statistics surroundings and makes a prospect for the destiny development of economic auditing within the generation of massive facts.
II. RELATED WORK
Since the concept of massive information become proposed, many advanced nations and some growing nations have performed lively exploration and studies. The theoretical components of large information in audit paintings, Chu introduced some concepts and methods of far-off records auditing inside the generation of large records via discussing some achievements associated with faraway information auditing [13].A new records shape is designed to successfully aid operations together with dynamic statistics insertion, addition, deletion, and change, to meet the frequent update calculation of big data, and to reduce the conversation fee of records operation and auditors. In addition, through modelling analysis, its miles proved that these faraway facts audit can provide better statistics security and destiny sensible software prospects [14].
Perez elaborated at the definition of bigdata, and added the impact of big records on the auditing enterprise in phrases of improving accuracy, increasing audit scope, and improving analytical models, which includes enhancing the efficiency of economic announcement auditing [15].
At the same time, it combines the characteristics and outcomes of large statistics evaluation with the wishes of audit paintings, analyses the problems encountered in the use of big records in audit work, and finally proposes that auditors must now not rely an excessive amount of on records relationships, because of facts assets [16].Due to the influence of statistics volume and time adjustments, many analysis conclusions can be misled by way of the evaluation outcomes, so big records should be implemented in combination with traditional audit techniques.
Wang conducted an evaluation of the development reputation of business banks and determined that the risk control of industrial banks in the age of massive facts has changed from internal prevention to outside manipulate, from an unfastened affiliation to a near association, and from clear and controllable to fuzzy and hard to control [17].Risk traits, regard facts and chance as the two important factors of bank operation, and propose techniques to maintain the competitiveness of commercial banks by means of setting up a big records audit device that may predict bank risks, attaching significance to internal management process manipulate audits, and strengthening bank hazard-associated audits [18].Maintain the banking zone's steady operations within the huge information age. In reaction to these challenges, Yang examined the problems with audit paintings in the context of large data, proposed paintings measure like innovative audit corporation strategies, audit technical strategies, and audit personnel training fashions, and outlined three improvement traits of statistics-primarily based auditing inside the huge records era [19].Utilise statistical techniques to study audit statistics, massive statistics processing strategies to advance audit evaluation from question verification to mining, and massive data evaluation concepts to develop audit analysis from causality analysis to correlation evaluation [20].
Financial auditing also pays growing interest to the usage of laptop software era as computer aided auditing regularly develops and popularises using modern technologies like computer systems, the Internet, and automated offerings [21].Therefore, how to use new technologies and new methods in the huge records surroundings to the realistic work of financial audit, innovate within the aspects of massive information series, analysis, mining, etc., use massive information technology to troubleshoot problem information, song capital drift, and decide audit cognizance At the same time, keeping off the dangers introduced by using massive data is an vital studies course of pc-aided auditing in my country. In the advanced model used, we have optimized a few parameters of the version to enhance its working efficiency. Given the business state of affairs of my country's banking financial establishments in the large data environment, this paper analyses and explores the heritage and feasibility of the application of huge data technology in monetary auditing, and makes use of software to perform practical case programs, to provide financial huge statistics inside the future. The audit gives ideas and methods for reference, to draw others.
III. CONVOLUTION NEURAL NETWORK-BASED DATA FUSION
According to the huge records processing cycle, the big facts generation device includes unstructured information collection era, information cleansing, and screening era, statistics disbursed storage system, facts-parallel computing analysis generation, records visualization generation, and so forth. In the context of big statistics, statistics resources are very extensive, along with mobile phones, computers, satellites, networks, media, social structures, way of transportation, radio frequency signals, and so on. However, the information of those channels generally has special formats, which is inefficient for the layout conversion of big quantities of records and increases the issue of records series [22].
According to facts, in the contemporary big facts' storage gadget, the percentage of unstructured statistics and semi-structured facts has accounted for about eighty%. Therefore, conventional statistics collection tools are presently not able to satisfy the wishes. After big statistics series, easy records preprocessing is required, which includes cleansing technology and screening era. These two large records technology's purposes to completely smooth up a big amount of corrupted, redundant, and vain records within the network, optimize multi-supply records and multimodal facts, integrate numerous varieties of information amassed, convert wonderful facts into usable statistics, and extract legitimate statistics for next analysis.
Therefore, facts cleansing and screening era can manage the best of facts from extraordinary resources and offer fundamental technical aid for statistics analysis. Unstructured statistics is stored in distributed report systems, so within the generation of massive data, disbursed garage systems are very critical. Most conventional records garage systems adopt a centralized method, and all statistics are stored on a separate server [23].
The reliability and safety of the storage server are the bottlenecks for enhancing machine overall performance, and cannot meet the desires of large facts garage packages. Input of the proposed version includes all the initial substances that need to be audited, which include units, accounting data, and so forth. The initial contents may be converted into virtual features that can be calculated inner neural network models.
Output of the proposed model is the discriminative auditing result. Similar to fashionable system getting to know models, the idea is also a normal peer-to-peer structure from features to results. The machine structure followed by the allotted records garage machine is scalable, with a couple of servers sharing the storage load pressure. The approach of the usage of the area server to find and store statistics cannot most effectively enhance the security, reliability, availability, and get admission to efficiency of the entire system, however also can also take gain of the extensible features.
Data visualization technology makes use of forms, pics, shades, animations, and other forms to visually provide an explanation for statistics information, that could genuinely and effectively convey information records. With the development of cloud computing and huge information, facts visualization technology is not glad with the use of conventional information visualization tools to extract facts from the database, and summarize and honestly reveal it.
New facts visualization products ought to meet the large records desires of the Internet explosion, speedy gather, filter out, examine, summarize, and present the facts required by means of decisionmakers, and update them in actual-time in keeping with new information.
In the technology of huge facts, within the face of large facts information, the usage of records visualization era can display the effects of statistics analysis extra intuitively and quite simply, and in addition help researchers examine and my massive data. Entity extraction is a subtask of named entity recognition in statistics extraction techniques.
Extract meaningful noun terms from the obtained facts, correctly perceive word barriers, and output treasured dependent understanding. The accuracy of the steps directly impacts the first-rate of the constructed map. Named entity reputation has many technical approaches [24].
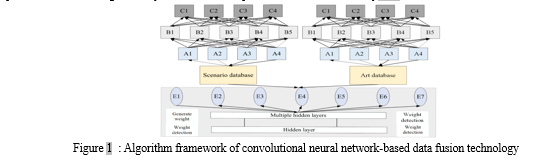
In this paper, the primary structural records assets for entity extraction are supported, and the extraction is accomplished using regularization, which realizes the data assist for the expected functions, as shown in Figure 1.
The statistics centre gadget is the centre configuration of the audit huge information platform. This system realizes the purchase, garage, management, and simple query application of all information resources of the platform, affords data help for the application analysis machine layer and gives evaluation and modelling for massive facts sets. The records centre system specifically includes features consisting of records resource and management, records series and processing, records authority control, and facts analysis packages.
The advent of large statistics era within the audit data middle is to fulfil the overall amount of submitted statistics and growth the enterprise coverage of information-primarily based auditing [25].
Finally, an organizational device of established records in facts sources is fashioned to offer massive records computing help capabilities for statistics evaluation and processing. To remedy the storage hassle of big records and obtain full insurance of audit data, the creation of dispensed statistics warehouse generation is a critical answer. A green SQL on-Hadoop is an effective method. By evaluating several allotted computing engine technologies, it's far believed that HAWQ has extensive blessings in many factors, and is extra appropriate for auditing structured information analysis and modelling. The composition, shape, and education techniques of those fashions are special, however they're all synthetic neural networks composed of artificial neurons. Except for ELM,
Maximum of the alternative ANN fashions has a deep network structure, which can extract the deep capabilities of the data. Compared with the LR and LDA models, an average feature of the ANN model is that it is a nonlinear version.The input layer is used to get hold of input sample capabilities, so the variety of neurons in the enter layer is determined in keeping with the function measurement of the enter samples. After the enter layer tactics the sample capabilities, the processing end result is surpassed to the hidden layer. The hidden layer passes the result to the final output in step with the records surpassed by using the enter layer and the relationship weights and bias parameters between the neuron layers. The output layer receives the very last processing end result. In the sphere of personal credit score scoring, the output layer is generally set to 2 neurons, due to the fact personal credit score scoring is a binary type hassle.
After the above analysis, in the ANN model, the relationship weights and biases among the artificial neurons have a huge impact on the output of the model. When building an ANN model, the quantity of neurons in every layer can be decided, however the connection weights and bias sizes need to be adjusted via iterative education of the model.
It may be seen from the sampling procedure of the algorithm that the ADASYN algorithm considers the distribution of minority samples [26].
The set of rules determines the samples that every pattern desires to generate in keeping with the area of each minority sample and the variety of samples that want to be generated. However, while nearest buddies are almost all samples of the bulk magnificence, the set of rules will synthesize extra samples close to, which may also increase the difficulty of classification.

When a massive file is uploaded, many fragmented facts will be generated, and the fragmented information statistics desires to be persevered thru the database. One is to check the integrity of the shards while merging documents; the other is to test the record add development through the shard facts while resuming the add is required. However, while there are many simultaneous upload responsibilities, there can be many sharded records examine and write database duties. The information comes from Hummingbird Data, that is an open-source economic database that aggregates 10,000 time series from mainstream monetary markets and provides fantastic loose statistics. As the get right of entry to frequency will increase, the database often falls into a overall performance bottleneck, which subsequently turns into a concurrency bottleneck for report importing.
For this trouble, there are normally three ways to solve it. One is to reduce the number of concurrent clients and lessen records series responsibilities at the same time, and the other is to alter the size of the fragmented record. Third, an excessive-overall performance cache database is used to finish the patience of fragmentation records. After trying out and verification, the shard length is about to 10 MB, and Redis is used in place of the relational database to record shard records, as shown in Figure 2. Although the conventional foremost-agent concept is to start with relevant to discussing cash keeping conduct, it's also applicable to reading the behaviour of businesses the usage of financial price range to allocate financial belongings. The funding choices of the control of the agency can be laid low with the uncertainty of economic rules. Since the shareholders of the employer switch the management rights to the management and do not take part inside the management of the business enterprise, the management could have greater discretion over funding behaviours which include economic asset allocation. In response to modifications inside the external surroundings, the control may not absolutely follow the goal of maximizing shareholder fee and allocating excessive-risk, high-yield financial assets by using converting the motivation of monetary asset allocation to make sure the maximization of the management’s pastimes. To apprehend the scientific and rationality of corporate management’s choice-making, shareholders have created a chain of structures inclusive of a data disclosure system, inner control system, and business enterprise investor dating control, to alleviate the major-agent problem between the two [27]. At the equal time, as an external supervision and governance issue, auditing can efficaciously transfer facts between the employer’s shareholders and control, and further, alleviate the principal-agent hassle by using related to a third celebration in supervision. Online small and micro loan businesses and P2P structures have reached several thousand.
The audit research object cannot cowl all Internet financial agencies. Except for licensed purchaser finance corporations, the alternative two varieties of organizations use sample surveys.
IV. DESIGN OF FINANCIAL AUDITING MODEL
Auditing is based totally on a mobile Internet-based totally auditing vocational education platform, which presents audit practitioners with a platform for on line dialogue and getting to know of auditing technologies and techniques inside the new era, the audit generation and methods can preserve pace with the instances and hold up with the pace of informatization and claudication. Auditing builds an internet and offline interactive audit conversation platform, applies the brand-new Internet and cloud era systems, paperwork audit training massive statistics, and eventually achieves the aim of comprehensively serving the professionalization of auditing. Electronic data auditing is a new kind of auditing technique proposed within the generation of cloud computing. It takes the speedy processing and computing techniques of cloud computing as the basis and takes digital records because the auditing carrier. Its technical characteristic is verification, no longer mining. It analyses electronic facts consistent with audit goals and analyses facts to serve audit targets, rather than excavation-kind data analysis carried out far from audit objectives [28].
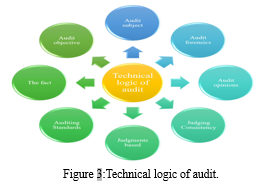
The main audit manner remains divided into three levels: audit education, audit implementation, and audit report the paintings of the audit making plans section is the implementation of an on-web site audit plan for the audit be counted. As is proven in Figure three, the paintings within the audit report level includes components: making audit conclusions with affordable guarantee and reading and determining the final audit opinion kind. The large statistics anti-money laundering audit system is appropriate for auditing establishments to behaviour compliance audits at the enterprise records of huge nation-owned and commercial banks. With huge data correlation analysis because the middle era, the gadget achieves efficient and accurate minute-level processing functionality, breaking through the contemporary limit of hourly-degree processing functionality in foreign countries [29].Analyse and evaluate the efficiency consequences of other unique services, together with the new credit evaluation machine, associated client discovery, and product recommendation. Industry experts said that the machine represents a brand-new technology of anti-cash laundering audit era inside the future. Compared with the hourly ‘‘rule chain generation’’ widely used overseas, it is modern progress and has a excessive software value.
The audit implementation system is a statistics system in which auditors use computers because the primary hardware to carry out audit projects, and is subdivided into two elements: an on-site audit implementation system and an online audit implementation device according to unique implementation strategies. The on-website audit implementation device is a fully functional and smooth-to-use statistics system advanced to meet the necessities of presidency auditors to behaviour on-web page audits on audit objects. The online audit implementation device is the fundamental statistics gadget software used by audit institutions to enforce on-line audits.
In the standardized management of the audit unit after the audit, the technique of dynamic and remote audit is adopted to gain the advantages of pre, in, and publish-audit audits. It also can conduct fashion analysis and forecast evaluation on the beyond audit statistics mixed with the modern facts, and advise corresponding measures. The audit opinion is proven in Figure 4.
Since few groups inside the monetary enterprise use the‘‘private cloud’’ of the cloud provider platform to keep their financial records, auditors seldom can straight away benefit the audit statistics of the audited entity from the cloud provider platform at the same time as carrying out economic audits. The 3-celebration supervision departments first reap the crucial audit statistics after which import the statistics into the cloud database via statistics migration. However, at gift, maximum authorities' auditors use popular-motive series software program, and their open interfaces have no longer been redeveloped according to actual paintings [30].
The built-in features and fashions may also now not fulfil all forms of information tasks, so the software program has a secondary improvement interface. However, in actual paintings, auditors are a bit conservative whilst using the software, and are familiar with using the same set of templates to procedure all statistics. Audit work outcomes in low performance and effectiveness of audit paintings. And inside the statistics collection and migration stage, the auditors lack necessary data cleaning and verification steps, which makes the collection and migration facts incomplete. It is not unusual for employees to only import the accumulated information into the audit software program without logical judgment, which often leads to the failure of the assignment to progress.
V. ALGORITHM PERFORMANCE RESULTS
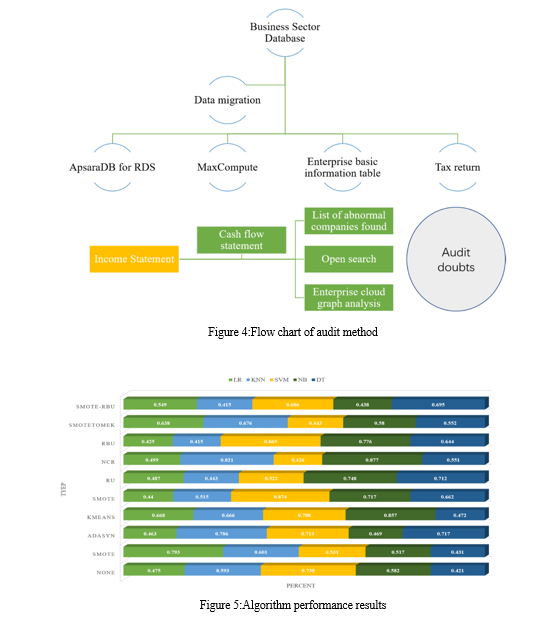
Since the NCR sampling set of rules does now not set the wide variety of redundant samples to be eliminated, the redundant samples to be eliminated are only related to the selected samples and their neighbouring samples, so the cleansing impact is quite constrained. After the German dataset is down-sampled via NCR, there are nonetheless 476 samples in the majority magnificence. In the Default facts set after RU and RBU down-sampling processing, the number of samples inside the classes is the same, both of which might be 6636 instances. Like German, after NCR processing, there are still 13,214 samples within the majority elegance of the Default dataset. The experimental results display that the capacity of NCR to easy up redundant samples isn't as exact because the other two algorithms.
After being processed through SMOTE-Tomek, there are 626 samples of both sorts inside the German dataset. Not simplest that, but the varieties of samples within the Default dataset also is the identical, with 22706 instances. Using Kmeans SMOTE-RBU to method the German records set, the two kinds of samples acquired are both valued as 500. The default records set after processing has the equal range of styles of samples, which is 15000. Compared with the original data set, the number of samples has no longer modified, which avoids the effect of adjustments within the usual range of samples on the class outcomes. After sampling and normalizing the dataset, a classifier is used to degree the performance of each sampling set of rules, as shown in Figure 5.
K-means SMOTE-RBU sampling set of rules designed in this paper has the best Accuracy index and outperforms different sampling algorithms on all five classifiers. On the Five classifiers, the highest classification accuracy executed was 0.8211. After sampling processing, the gap between the four evaluation signs have narrowed extensively. Compared with None, the effects of Kmeans SMOTE-RBU have obvious advantages. The Accuracy index has increased from 0.7060 to 0.8051, and the value has elevated with the aid of 0.0991, that's 14% better than that of None. The cost of the F-degree has accelerated with the aid of 0.1, and the development rate exceeded 15%. The fee of G-imply increased by using 0.24, which shows an enormously obvious development. The AUC index value is likewise multiplied via nearly 0.2. This segment specially analyses the above two experimental effects.
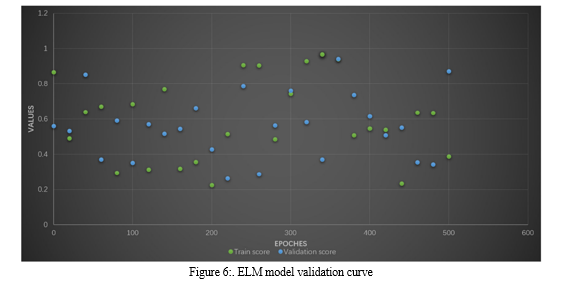
The overall performance evaluation indicators used in this experiment are still 4 indicators: Accuracy, F-measure, G-imply, and AUC. First, to set the ideal wide variety of ELM hidden layer nodes, this paper draws the verification curve of the ELM version, and the change of the curve is proven in Figure 6. The above determine contains four small figures, every small parent represents the trade in a information set. The horizontal axis within the determine is the range of neurons within the ELM hidden layer. The vertical axis represents the category accuracy. As may be visible from Figure 6, at the Australian, Japanese, and German datasets, because the wide variety of nodes will increase, the training accuracy of the ELM version keeps to growth, however the validation accuracy does not. On these three datasets, whilst the variety of hidden layer nodes increases to round 50, the validation accuracy no longer will increase with the range of nodes. On the Default facts set, while the number of nodes will increase to greater than 50, the increase in the verification accuracy isn't apparent. Based on the above 4 records units, this paper units the number of hidden layer nodes of the ELM network to 50.
Other fundamental models' classification performance has been improved to varied degrees after being coupled with the 1DCNN network. The NB model's performance enhancement stands out among these fundamental models the most.
With an increase of 6.84%, its accuracy index went from 0.8478 to 0.9058. There was an increase of 6.93% in the F-measure, from 0.8476 to 0.9064. The G-mean (0.9113) and AUC (0.9120) indices are raised further, reaching 8.3%. The four SVM model metrics have been improved by 1.64% (Accuracy), 1.63% (F-measure), 1.33% (G-mean), and 1.08% (AUC) in comparison to the NB model. The indicators' profits are 2.63% for accuracy, 2.48% for F-degree, 1.53% for G-mean, and 1.61% for AUC.
The XGBoost model has an increase of 4.20% (Accuracy), 4.10% (F-measure), 3.17% (G-mean) and 2.94% (AUC), which are higher than the SVM and Adaboost models, in addition to an increase in baseline by 1, respectively % New example. After integrating the 1DCNN network, the classification performance of LR, KNN, SVM, NB, DT, Adaboost and XGBoost has improved to some extent. The accuracies of the SVM model and the F-measure index increased by 1.7% and 1.5%, respectively. The Accuracy index of the NB model did not increase significantly, but the G-mean and AUC indices increased by 5.97% and 6.59%, respectively. In addition, the F-measure value also increased by 1.8%, the four parameters of the DT model increased by about 1.83%, the Adaboost model increased by about 2.7% and the four parameters of the XGBoost increased by 0.85% (Accuracy), 1.2%; and there is a. (f) No -measure), increased by 2.07% (G-mean), and 1.95% (AUC), which is not clear.
VI. ANALYSIS OF THE APPLICATION RESULTS OF THE FINANCIAL AUDIT MODEL
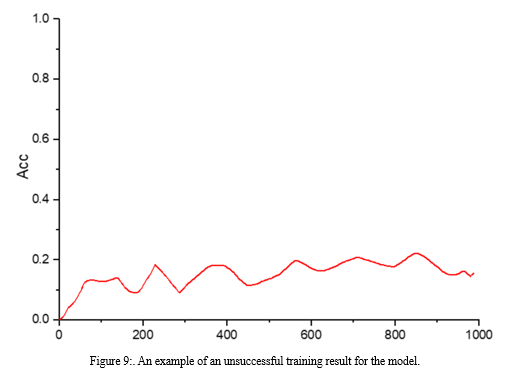
The case data on this paper comes from the credit loan database of XX Bank. Considering the confidentiality of bank facts, this paper simplest selects a part of the statistics for evaluation, including 3 statistics tables: mortgage sub-account, loan subaccount, and mortgage issuance and recovery registration e-book. Among them, a total of 4,961 pieces of statistics are gathered inside the mortgage sub-account, a complete of 26,050 portions of information are accrued inside the mortgage sub-account, and a complete of forty-one,366 portions of records are accrued in the mortgage issuance and recovery check in. The accuracy rate of the unsuccessful effects of the model may be very low, and it can be visible from the result graph whether or not it's far a success or no longer. When reading via conventional Excel gear, in the process of processing the loan issuance and recuperation registration e book with a massive quantity of information, it's going to come across problems including slow strolling velocity, disordered records filtering, and unclear picture show.
When applying the R language to research these statistics, first make a macro-remark of the information, and then in addition technique the objects that want to be focused on in keeping with the situation, and attempt to visualize the statistics effects to facilitate the discovery and exploration of next problems. Finally, according to some functional relationships, suspicious troubles are checked, and recommendations for follow-up work are recommend in mixture with conventional auditing methods.
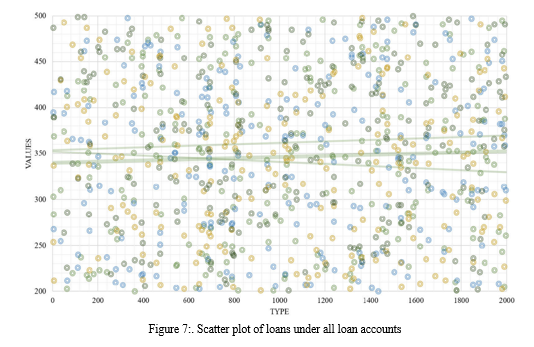
The particular code and analysis manner are as follows. To examine the loan distribution, first, extract the two variables of the mortgage account V2 and the loan amount V15, and use the ggplot2 bundle to draw a scatter diagram of the mortgage state of affairs beneath all loan money owed, in which the abscissa is the mortgage account variety, and the ordinate is the mortgage amount.
Due to a huge amount of selected information, the overlapping coverage between the scatter points, and the distinct loan situations below specific loan money owed, the scatter factors in the discern have low awareness, no regularity, and negative visualization impact. However, in step with the statistical effects of the outline in the preceding step, all mortgage data are divided into 46 loan kinds. According to exclusive mortgage kinds, all loan information is similarly visualized, as proven in Figure 7. Based at the previous perturbation factor map, load the IDPmisc package to coloration the concentration of the records. From the legend on the proper facet of the determine, we are able to see that the darker the colour block inside the determine, the better the repetition of the loan facts. Among the loan kinds beginning with 20, the facts with the loan quantity of five million yuan is the maximum focused, observed by means of zero yuan, which desires to be checked based on the actual enterprise scenario.
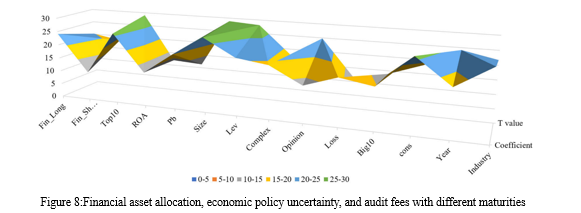
The first is the location of the subsidiary creditors themselves. The relevant commercial enterprise rules promulgated by the Banking and Insurance Regulatory Commission of China did now not define microcredit organizations as economic establishments. Microcredit groups are personal businesses of creditors. Once registered with the local Department of Industry and Commerce, the microcredit enterprise might be registered with the local monetary institution or monetary organization. Microcredit agencies had been not yet issued to direct supervision through the Banking and Insurance Regulatory Authority of China and the People’s Bank of China. Thus, small company creditors cannot enjoy the favourable selective policies of financial institutions. The finances did now not have particular designated regulations on preferential tax remedy for small corporate creditors. Similarly, in prison subjects along with exertions disputes, the ways wherein microcredit agencies and financial institutions address them are very different Such situations of lifestyles aren't to be had to microcredit businesses of the positive fashion, as proven in Figure 8 .
Second, the growth of the Internet financial market has intensified the fierce competition among various players in the sector. The microcredit corporate market is basically divided into two categories. One is the personal credit market and the other is the corporate credit market. But licensed consumer finance companies and P2P platforms, are competing fiercely for market share. Banks and other traditional financial institutions are also targeting the online financial lending industry. As shown in Figure 9, it is the result of a failed model. If the model fails, we usually change the parameters of the model, such as the number of training steps and the size of each training session. Consequently, it has significantly affected the size and characteristics of small corporate lending customer bases. In addition, many smaller lenders have poor risk management, limited loan pre-approval and post-loan supervision, and significant overpayments.
Although convolution operations are involved in the suggestion, calculation is especially within the layout of numerical evaluation. Unlike laptop vision tasks, there is no too complicated tensor transformation. Inside the hardware with one ‘‘Tesla V100’’ GPU, the walking time for the training technique is averagely within the variety of 15-20 seconds. For testing, the running time for one piece of sample is simply less than 0.1 Seconds. Compared with typical machine gaining knowledge of-primarily based strategies, the time complexity is not expanded. While the proposal can have better popularity performance, which can be regarded as a more realistic manner inside the investigated hassle state of affairs.
Under this situation, if an agency allocates quick-time period monetary assets with sturdy liquidity and excessive liquidity, it may alleviate the economic distress resulting from financing constraints to a positive quantity. On the opposite, the allocation of lengthy-time period economic property with the characteristics of terrible liquidity, massive capital career, and long term, will similarly boom the danger of corporate cash flow breakage and growth the inherent danger of audit risk. To lessen inspection threat, auditors want to put in force greater Adequate audit methods, which in flip require higher audit premiums.
Conclusion
In the era of big statistics, laptop-aided auditing has acquired increasingly attention from audit departments and auditors, mainly economic auditing. The utility of computer statistical analysis software has steadily deepened, and the development and alertness of the R language have additionally received increased interest. And from this, the software of laptop-aided auditing is proposed. Based on the economic auditing exercise, the case analysis of the real information of the financial institution is done. From the perspective of a financial auditor, within the software program environment of the R language, the financial institution mortgage records have been comprehensively made. In the process of case software, the meaning of R language code is fully and comprehensively defined, the common features and models within the R language are discovered in aggregate with audit exercise, and the content material of statistics visualization is especially realized. At the equal time, the records evaluation of each step additionally combines conventional audit strategies to reflect on consideration on the feasible issues behind the case information and recommend tips for the comply with-up audit paintings. Finally, through the code writing and visual presentation of the R language, the application of economic big information auditing is found out, and the operating ideas of monetary massive records auditing are tentatively planned to provide certain assist to auditors.
References
[1] G. Z, Y. K, B. K. A, Z. D, A.-O. Y.D and G. M., \"‘Deep information fusion-driven POI scheduling for mobile,\" in IEEE , 2022 [2] L. L. Z. G. P. V. F. T.-H. a. K. Y. Q. Li, \"Smart assessment and forecasting framework for healthy development,\" in Cities,, Art. no. 103971, Dec. 2022. [3] Y. L. S. X. Y. Y. L. T. G. a. K. Y. L. Yang, \"Generative adversarial learning for intelligent trust management in 6G wireless networks,\" in IEEE Netw., vol. 36, no. 4, 134–140, Jul. 2022, Jul. 2022. [4] Y. S. J. L. K. Y. Q. M. J. W. Z. F. a. Y. S. Z. Zhou, \"Secret-to-image reversible transformation for generative steganography,\" in IEEE Trans. Dependable Secure Comput., early access, Oct. 27, 2022 [5] Z. G. Y. Z. P. V. A. C. a. B. B. G. Q. Zhang, \"A deep learning-based fast fake news detection model for cyber-physical,\" Pattern Recognit. Lett, vol. 168, pp. 31-38, 2023. [6] K. Y. N. K. W. W. S. M. a. M. G. Z. Guo, \"Deep-distributed-learning-based POI recommendation under mobileedge network,\" IEEE Internet Things J, vol. 10, no. 1, pp. 303-317, 2023 [7] D. M. C. C. X.-R. F. A. B. a. K. Y. Z. Guo, \"‘Autonomous behavioral decision for vehicular agents based on cyberphysical social intelligence,\" in ’ IEEE Trans. Computat. Social Syst., early access, Oct. 27, 2022 [8] A. I. E.-D. L. M. L. a. E.-S.-M. E.-K. E. M. Hassib, \"‘WOA + BRNN: An imbalanced big data classification framework using,\" Soft Comput, vol. 24, no. 8, pp. 5573-5592, 2020. [9] H. M. L. W. S. M. a. G. W. Y. Li, \"‘Optimized content caching and user association for edge computing in densly deployed heterogenous networks,\" IEEE Trans. Mobile Comput., vol. 21, no. 6, pp. 2130-2142, 2022 [10] Z. B. A. H. K. Y. Y. Z. a. M. G. L. Zhao, \"ELITE: An intelligent digital twin-based hierarchical routing scheme,\" in IEEE Trans. Mobile Comput, may 31 2022. [11] K. Y. K. K. S. M. W. W. P. S. a. J. J. P. C. R. Z. Guo, \"Deep collaborative intelligence-driven traffic forecasting in green internet of vehicles,\" in IEEE Trans. Green Commun. Netw.,, jul 2022. [12] Z. Y. K. Y. X. T. L. X. Z. G. a. P. N. L. Zhao, \"A fuzzy logic-based intelligent multiattribute routing scheme for twolayered SDVNs,\" IEEE Trans. Netw. Service Manage., vol. 19, no. 4, pp. 4189-4200, 2022. [13] M. K. C. a. K. O. Yong, \"Big data analytics for business intelligence in,\" Open J. Social Sci.,, vol. 9, no. 9, pp. 42-52, 2021. [14] D. S. S. T. S. a. M. A. V. D. Appelbaum, \"A framework for auditor data literacy: A normative position,\" Accounting Horizons, vol. 35, no. 2, pp. 5-25, 2021. [15] L. F.-R. P. a. A. R. Blasco, \"A data science approach to cost estimation making big data and machine learning,\" Revista de Contabilidad-Spanish Accounting Rev, vol. 25, no. 1, pp. 45-57, 2022 [16] T. Sun, \"Applying deep learning to audit procedures: An illustrative,\" Accounting Horizon, vol. 33, no. 3, pp. 89-109, 2019. [17] Y. Y. T. W. R. S. S. a. J. Z. J. Wang, \"‘Big data service architecture: A survey,\" ’ J. Internet Technol., vol. 21, no. 2, pp. 393-405, 2020. [18] W. Q. a. Y. Ge, \"‘The implementation of leisure tourism enterprise,\" ’ Int. J. Syst. Assurance Eng. Manage, vol. 12, no. 4, pp. 801-812, 2021. [19] F. Yang and M. Wang, \"‘A review of systematic evaluation and improvement in the big data environment,\" Frontiers Eng. Manage, vol. 7, no. 1, pp. 27-46, mar 2020. [20] J. Y. H. C. a. D. P. Y. Li, \"Theory and application of artificial intelligence in financial industry,\" Data Sci. Finance Econ, vol. 1, no. 2, pp. 96-116, 2021. [21] T. S. a. L. J. Sales, \"Predicting public procurement irregularity:An application of neural networks,’,\" J. Emerg. Technol. Accounting,, vol. 15, no. 1, pp. 141-154, 2018. [22] A. Ç. a. E. C. M. Yildirim, \"‘Investigation of cloud computing based big data on machine learning algorithms,’,\" Bitlis Eren Üniversitesi Fen Bilimleri Dergisi, vol. 10, no. 2, pp. 670-682, 2021 [23] E. G. V. V. D. a. I. P. M. Connolly-Barker, \"Internet of Things sensing networks, deep learning-enabled smart process planning, and big data-driven innovation in cyber-physical system-based manufacturing,\" Econ., Manage., Financial Markets,, vol. 15, no. 2, pp. 23-30, 2020. [24] Z. Y. a. C. Z. J. Li, \"‘Study on the interaction between big data and,\" Syst. Res. Behav. Sci, vol. 39, no. 3, pp. 641-648, 2022. [25] Vagliano et al., \"Open innovation in the big data era with the MOVING platform,\" IEEE MultimediaMag, vol. 25, no. 3, pp. 8-21, 2018. [26] A. Praveena and B. Bharathi, \"An approach to remove duplication records in healthcare dataset based on mimic deep neural network (MDNN) and chaotic whale optimization (CWO),,\" Concurrent Eng.,, vol. 29, no. 1, pp. 58-67, 2021. [27] L. M. Cristea, \"Emerging IT technologies for accounting and auditing practice,\" Audit Financiar, vol. 18, no. 160, pp. 731-751, Oct. 2020 [28] M. X. S. Y. a. S. X. Q. Yi, \"Identifying untrusted interactive behaviour in enterprise resource planning systems based on a big data pattern recognition method using behavioural analytics,\" Behav. Inf., vol. 41, no. 5, pp. 1019-1034, 2022. [29] P. W. a. L. S. K. Valaskova, \"‘Deep learning-assisted smart process planning, cognitive automation, and industrial big data analytics in sustainable cyber-physical production systems,\" J. Self-Governance Manage. Econ.,, vol. 9, no. 2, pp. 9-20, 2021. [30] M. D. V. J. J. M. H. S. a. M. Z. H. Munim, \"Big data and artificial intelligence in the maritime industry:A bibliometric review and future research directions,\" Maritime Policy Manage , vol. 47, no. 5, pp. 577-597, 2020. [31] M. K. C. a. K. O. Yong, \"Big data analytics for business intelligence in,\" Open J. Social Sci., vol. 9, no. 9, pp. 42-52, 2021.
Copyright
Copyright © 2023 Chowlur Ananda Naga Chaitanya, Byreddy Akhileswar Reddy. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET54405
Publish Date : 2023-06-25
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online