

Ijraset Journal For Research in Applied Science and Engineering Technology
Face Mask Detection Analysis
Authors: Riya Talwar, Nishita Badola, Yamini Ratawal
DOI Link: https://doi.org/10.22214/ijraset.2022.47436
Certificate: View Certificate
Abstract
COVID-19 pandemic has affected the world gravely, according to the World Health Organization (WHO), coronavirus disease (COVID-19) has globally infected over 170 million people causing over 3.6 million deaths [1] . Wearing a protective mask has become a norm. However, it is seen in most public places that people do not wear masks or don’t wear them properly. In this paper, we propose a high accuracy and efficient face mask detector based on MobileNet architecture. The proposed method detects the face in real-time with OpenCV and then identifies if it has a mask on it or not. As a surveillance task, it supports motion, and is trained using transfer learning and compared in terms of both precision and efficiency, with special attention to the real-time requirements of this context.
Introduction
I. INTRODUCTION
The rapid spread of COVID-19 forced the World Health Organization to declare COVID-19 as a global pandemic [2]. Wearing a mask is one of the prevention measures that can limit the spread of coronavirus. Therefore, it is necessary to wear a mask properly at public places like super-markets and shopping malls.
Facemask can interrupt airborne infection of coronavirus disease COVID-19 effectively, such that the disease never reaches the respiratory system of the person. Facemask is a non-invasive and cheap method to reduce mortality and morbidity rate from the new coronavirus strain that attacks the respiratory system aggressively.
Since the outbreak of COVID-19, facemasks are routinely used by the general public to reduce exposure. Masks, when worn properly, effectively, prevent tainted individual to cause contact transmission as droplets carrying the virus may withal arrive on adjacent surfaces. The need to monitor large groups of people to curb the exponential growth in cases and death is becoming more difficult in public places. So, we propose an automation process for detecting face masks which could contribute to personal protection and public epidemic response, a Face Mask Detection System to identify whether a person is wearing a mask or not. We will use a two-phase architecture for detecting face and face masks using OpenCV and TensorFlow.
II. LITERATURE SURVEY
In face detection method, a face is detected from an image that has several attributes in it. According to [3], research into face detection requires expression recognition, face tracking, and pose estimation. Given a solitary image, the challenge is to identify the face from the picture.
Face detection is a difficult errand because the faces change in size, shape, colour, etc and they are not immutable. It becomes a laborious job for opaque image impeded by some other thing not confronting camera, and so forth. Authors in [4] think occlusive face detection comes with two major challenges: 1) unavailability of sizably voluminous datasets containing both masked and unmasked faces, and 2) exclusion of facial expression in the covered area. Utilizing the locally linear embedding (LLE) algorithm and the dictionaries trained on an immensely colossal pool of masked faces, synthesized mundane faces, several mislaid expressions can be recuperated and the ascendancy of facial cues can be mitigated to great extent.
According to the work reported in [5], convolutional neural network (CNNs) in computer vision comes with a strict constraint regarding the size of the input image. The prevalent practice reconfigures the images before fitting them into the network to surmount the inhibition.
Here the main challenge of the task is to detect the face from the image correctly and then identify if it has a mask on it or not. In order to perform surveillance tasks, the proposed method should also detect a face along with a mask in motion.
III. OUR APPROACH
The proposed method consists of a classifier and a pre-trained CNN which contains two 2D convolution layers connected to layers of dense neurons. The algorithm for face mask detection is as follows:
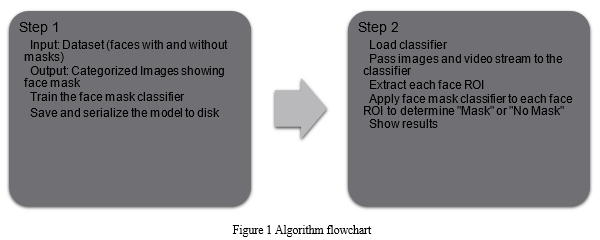
A. Data Preparation
Our approach deals with image and video data using Python libraries NumPy and OpenCV. All the images were labelled “mask” and “no mask”. For each image in the dataset we visualize the image in 2D, convert any Gray-scale image to RGB, resize the image input to 300 x 1 and normalize the image and convert it into 4 dimensional array.
B. Pre-Processing
We use Scikit-learn for binarizing class labels, segmenting our dataset and video feed and to produce a classification report. Imutils for finding and listing images in our dataset and Matplotlib to plot our training and error curves. Pre-processing steps mentioned above were applied to all the raw input images to convert them into cleaner versions which our model can understand. Finally we convert our data inputs into tensors which our machine learning model understands.
C. Mobile Net
Mobile Net V2 builds upon the ideas of V1, using depth wise separable convolution as efficient building blocks [6]. However, V2 introduces two new features to the architecture:
- Linear bottlenecks between the layers
- Shortcut connections between the bottlenecks
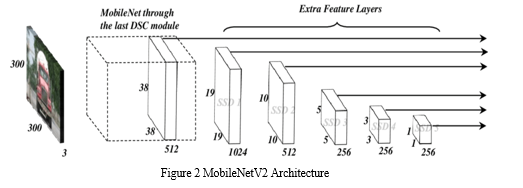
The typical MobileNetV2 architecture has as many layers listed above, the weights of each layer in the model is predefined based on the ImageNet data. The weights indicate the padding, strides, kernel size, input channels and output channels. We chose MobileNet as the classifier to build a model because it can be deployed on a mobile device. The final layer SoftMax function gives the result of two probabilities each on represents the classification of “mask” or “not mask”.
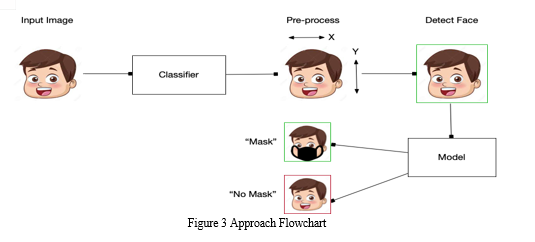
D. Fine-Tuning
We load the MobileNetV2 classifier with pre-trained ImageNet weights, leaving off head of network and create a new FC head, and append it to the base in place of the old head. We freeze the base layers of the network. The weights of these base layers will not be updated during the process of backpropagation, whereas the head layer weights will be tuned.
The model is compiled with Adam optimizer and binary cross-entropy loss function. After compilation we make predictions on the test set, grabbing the highest probability class label indices. Then, we print a classification report in the terminal for inspection, after finalizing and serializing our face mask classifier to disk.
We can finally load our model in video stream for real-time face mask detection using VideoStream class.
IV. TESTING AND RESULTS
In our project we calculate error by using f1-score, precision and recall.
A. Precision and Recall
In pattern recognition, information retrieval and classification (machine learning), precision (also called positive predictive value) is the fraction of relevant instances among the retrieved instances, while recall (also known as sensitivity) is the fraction of relevant instances that were retrieved. Both precision and recall are therefore based on relevance [7].
B. F1-Score
In statistical analysis of binary classification, the F-score or F-measure is a measure of a test's accuracy. It is calculated from the precision and recall of the test, where the precision is the number of true positive results divided by the number of all positive results, including those not identified correctly, and the recall is the number of true positive results divided by the number of all samples that should have been identified as positive. Precision is also known as positive predictive value, and recall is also known as sensitivity in diagnostic binary classification [8].
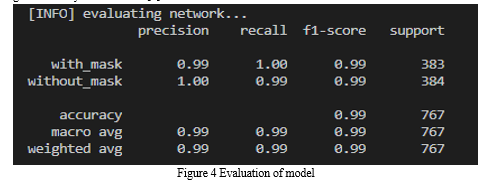
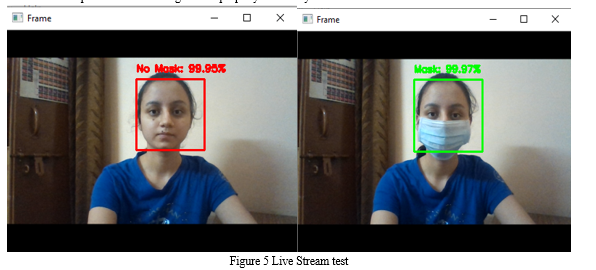
As observed above, we obtain ~99% accuracy on our test set. We have successfully trained our model and tested it on our test set and real-time video stream using a laptop’s camera. Our Mask detector correctly labels the person’s face as either “Mask” or “No Mask”. As you seen in the image bellow that the face is properly labelled “Mask” when a person is wearing a mask and labelled as “No Mask” when the person is not wearing a mask properly or entirely.
Conclusion
In this report, a face mask detection system was presented which was able to detect face masks. The architecture of the system consists of TensorFlow and OpenCV. A novel approach was presented which gave us high accuracy. The dataset that was used for training the model consists of more than 3800 face images. The model was tested with real-time video streams. The training accuracy of the model was around 99%. This model is ready to use in real world use cases and to implement in CCTV and other devices as well. Deploying our face mask detector to embedded devices could reduce the cost of manufacturing such face mask detection systems, hence why we choose to use this architecture.
References
[1] W. H. Organization, “WHO Coronavirus (COVID-19) Dashboard,” 10 June 2021. [Online]. Available: https://covid19.who.int. [2] E. Mahase, “Covid-19: WHO declares pandemic because of “alarming levels” of spread, severity, and inaction.,” Bmj, vol. 368, no. 0, 2020. [3] M. D and S. R, “An approach to face detection and recognition,” International Conference on Recent Advances and Innovations in Engineering (ICRAIE), 2016. [4] G. S, L. j, Y. Q and L. Z, “Detecting masked faces in the wild with lle-cnns,” Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2682-2690, 2017. [5] G. S, D. N and N. M, “Reshaping inputs for convolutional neural network: Some common and uncommon methods.,” Pattern Recognition, vol. 93, pp. 79-94, 2019. [6] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov and L.-C. Chen, “Computer Vision and Pattern Recognition,” The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4510-4520, 2018. [7] Wikipedia, “Precision_and_recall,” [Online]. Available: https://en.wikipedia.org/wiki/Precision_and_recall. [8] Wikipedia, “F-score,” [Online]. Available: https://en.wikipedia.org/wiki/F-score.
Copyright
Copyright © 2022 Riya Talwar, Nishita Badola, Yamini Ratawal. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47436
Publish Date : 2022-11-12
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online