

Ijraset Journal For Research in Applied Science and Engineering Technology
A Review on Fake News Detection
Authors: Adwait Bandal, Tushar Rane
DOI Link: https://doi.org/10.22214/ijraset.2023.52318
Certificate: View Certificate
Abstract
The widespread increase of fake news, generated by both humans and machines, has negative impacts on both society and individuals, politically and socially. The fast-paced nature of social networks makes it difficult to promptly evaluate the reliability of news. Hence, there is a growing need for automated tools to detect fake news. Compared to traditional machine learning techniques, deep learning-based approaches have shown higher accuracy in detecting fake news. Attention and Bidirectional Encoder Representations for Transformers are some of the emerging deep learning-based methods used for this task. A hybrid Neural Network architecture, which combines CNN and LSTM, is also used along with two different dimensionality reduction techniques, PCA and Chi-Square. These techniques are compared with regular ML techniques such as Decision Tree, logistic Regression, K Nearest Neighbor, Random Forest, Support Vector Machine, and Naive Bayes, as well as RNN and LSTM, in terms of parameters like F1-score and accuracy. The goal is to identify the best approach for detecting fake news.
Introduction
I. INTRODUCTION
The volume of information and data is growing rapidly, and with it, the incidence of false information is also increasing. The freedom of users to publish content on online news platforms, including social media and news websites, has led to the spread of inaccurate and misleading information in recent years [1].
The prevalence of fake news is on the rise due to the increasing use of social media and other forms of media. With the ease of information sharing, the number of people who are impacted by it is also increasing. Social media platforms, such as Twitter, Facebook, Instagram, and YouTube, have become the primary source of news for people worldwide, especially in developing countries.
As a result, individuals from any location can utilize these popular platforms to publish statements and spread false information through various networking sites, potentially pursuing illegitimate goals [2].
The terms rumor and fake news are closely associated with each other. Fake news or disinformation is deliberately fabricated, while rumors are unverified and questionable pieces of information that are spread without the intention to deceive [8]. On social media sites, spreaders’ intentions might be difficult to determine. As a result, any false or incorrect information is typically branded as misinformation on the Internet. Differentiating between real and fake information can be a difficult task. Nonetheless, numerous approaches have been implemented to tackle this issue. Machine learning (ML) techniques have been utilized to detect false information propagated online, such as knowledge verification, natural language processing (NLP), and sentiment analysis [9].
A. Motivation
Social media is used by individuals of various age groups. Both younger and older generations tend to trust all the information present on social media platforms, as they may lack the necessary awareness regarding fake news. Consequently, they become easy targets for individuals seeking to spread false information, making them vulnerable to fraud. Such incidents have become increasingly common, with reports of such cases surfacing almost daily. Thus, it is essential to devise and implement an effective strategy to combat fake news for the benefit of the public. According to a research poll, 64% of the United States population acknowledged that fake news has caused significant confusion regarding the factual content of reported events. Furthermore, the propagation of large-scale false information cascades can have severe consequences in various fields, such as business, marketing, and stock shares.
For example, in 2013, a false news report circulated on Twitter that Barack Obama was injured in an explosion, causing $130 billion in stock value to be wiped out [3].
???????B. Challenges
The most challenging aspect of identifying false news is determining whether a piece of information is based on factual evidence. A fact is a basic idea based on something that occurred at a particular time and place, often involving an individual or group of people. Computers may struggle to determine the significance of information, especially if they are responsible for delivering it to individuals via different channels. Given that many social media posts focus on describing events, it is crucial to adhere to the core journalistic standards when assessing the validity of news
II. LITERATURE SURVEY
The paper titled "Fake News Stance Detection Using Deep Learning Architecture (CNN-LSTM)" [3] presents a hybrid model that combines the Convolutional Neural Network (CNN) with the Long Short-Term Memory (LSTM) model for better detection of fake news. The study conducted in 2020 primarily focused on determining the best data pre-processing techniques to use with the CNN-LSTM model. The Principal Component Analysis (PCA) technique provided the best results, with an accuracy of 97.8 percent when the hybrid model was employed for fake news detection.
Another study in 2022 A Taxonomy of Fake News Classification Techniques: Survey and Implementation Aspects [2] compares traditional machine learning and deep learning techniques with the LSTM model. This study clearly shows that the performance of new deep learning techniques and models is better compared to machine learning models for fake news detection.
In the OPCNN-FAKE: Optimized Convolutional Neural Network for Fake News [1]. Detection Optimized Convolution Neural Network gave the best performance when compared to machine learning models like LR, SVM, DT, RF, KNN, NB and deep learning models of RNN and LSTM.
According to the experiments in A Novel Stacking Approach for Accurate Detection of Fake News [6], some models like K-Nearest Neighbors had better performance on small dataset and other models like Decision Tree, Support Vector Machine, Logistic Regression, CNN, GRU, LSTM had a lot worse performance on small datasets. To select the best model, we used a corrected version of McNemar’s test to determine if models’ performance is significantly different. According to our final experiments, among all individual models, Random Forest with TF-IDF has the highest accuracy on the ISOT dataset and Logistic Regression with TF-IDF has the highest accuracy on the KDnugget dataset.
Stance Detection is a widely researched task in the field of Natural Language Processing (NLP). It involves analyzing text to determine whether the writer or speaker is in favor, against, or neutral towards a particular subject or target [12]. Stance detection is the basis of various other tasks, including fake news detection, claim validation, and argument search [13]. Previous studies on fake news detection have primarily focused on target-specific stance prediction, which involves determining the stance of a text entity towards a specific topic or named entity. Target-specific stance prediction has been used in various research studies for analyzing tweets (where the text represents the stance of a single entity) [12] and online debates [10], [11]. Such target-specific approaches are based on structural features [10], and linguistic and lexical features [11].
Some researchers have developed neural networks for detecting fake news. One such model, proposed by Umer et al. [3], combines the Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) architecture with dimensionality reduction methods like PCA and Chi-Square to check if the news article's headline matches its text body. This model achieved the highest accuracy of 97.8% in a shorter time. Another CNN-based deep neural network called FNDNet was created by Kaliyar et al. [14] and achieved a state-of-the-art accuracy of 98.36% on the Kaggle fake news dataset. Kumar et al. [15] performed a CNN + BiLSTM ensemble model with attention mechanism on their own datasets and FakeNewsNet dataset and achieved the highest accuracy of 88.78%.
A Comprehensive Review on Fake News Detection with Deep Learning [5] done in 2021 lists the most used machine learning and deep learning techniques and models with different datasets over the past few years. It also provides an insight towards the performance of these models. Almost all of the previous studies emphasis the need for data pre-processing and the techniques used for feature extraction and dimensionality reduction. They state that the performance of the models hugely depends on the features used for training and testing the models. So, a review of dimensionality reduction techniques like Chi-Square and PCA as well as feature selection is of importance.
In a comprehensive study, Analyzing Machine Learning Enabled Fake News Detection Techniques for Diversified Datasets [4] the basic concept of fake news detection has been described in detail with their types, features, and characteristics, and also the taxonomy for the fake news detection model has been described. Several methods have been developed to detect users spreading fake news or rumors.
A comparison was conducted on three datasets (liars, fake news, and corpus) using both traditional machine learning and deep learning techniques. The results showed that deep learning techniques performed better than traditional methods. Specifically, the Bi-LSTM model achieved the highest detection rate for fake news with an accuracy and F1 score of 95%.
Using an ensemble method instead of a simple classifier can result in better fake news detection. By combining deep learning (DL) and machine learning (ML) algorithms in an ensemble model, where an LSTM can identify the original article and auxiliary features can be passed through a second model, higher accuracy can be achieved [2]. Research has shown that a simpler GRU model outperforms an LSTM, and combining GRU and CNNs can lead to the best results. CNN, LSTM, and ensemble models have all been used successfully in previous research [3], but other models like SeqGAN and Deep Belief Network (DBN) have not been explored much. It is recommended that researchers experiment with these models. Additionally, RNN models like LSTM are being replaced by Transformers like BERT for NLP tasks, but Generative Pre-trained Transformer (GPT) has not yet been utilized in fake news detection. Fine-tuning GPT for fake news detection tasks could be a promising area for future research.
???????A. Datasets
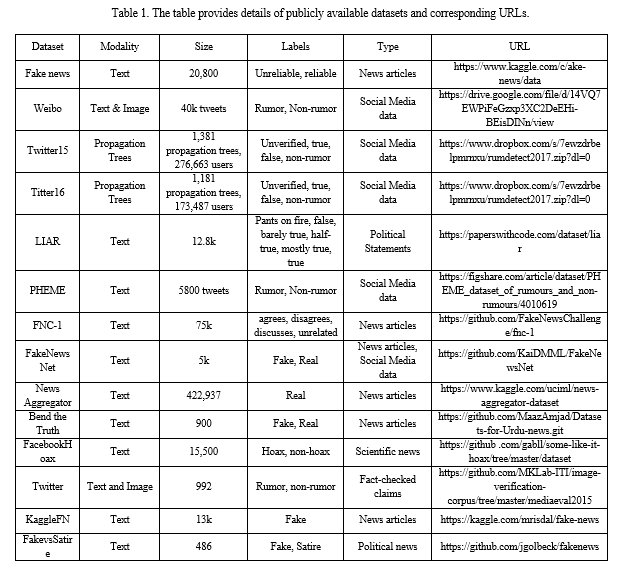
The lack of a reliable benchmark dataset with accurate labels is a major challenge in detecting fake news. This poses difficulties for researchers in obtaining useful features and building models. In recent years, several datasets have been compiled for use in DL and ML, but they vary greatly in terms of size, modality, and labels. Some datasets are focused solely on political statements (such as PolitiFact), while others are based on news articles (FNC-1) or social media posts (Twitter). The diversity of these datasets makes it challenging to compare and evaluate different models.
Fake news is often sourced from fraudulent websites created with the intent to spread disinformation. These fabricated news stories are then shared on social media platforms by their creators and further disseminated by malicious individuals, bots, and inattentive users who do not verify the source before sharing. While most datasets consist of news content, relying solely on current language features and writing styles is not enough to develop an effective detection model.
The availability of public datasets such as Fake news, Twitter15, and Liar have contributed to the development of detection models for fake news. In a comparative study conducted by Kaliyar et al. [14], their proposed model was tested against existing methods using the Kaggle dataset. The results showed that their model achieved the highest accuracy of 93.50% in detecting fake news using the same dataset.
III. METHODOLOGY
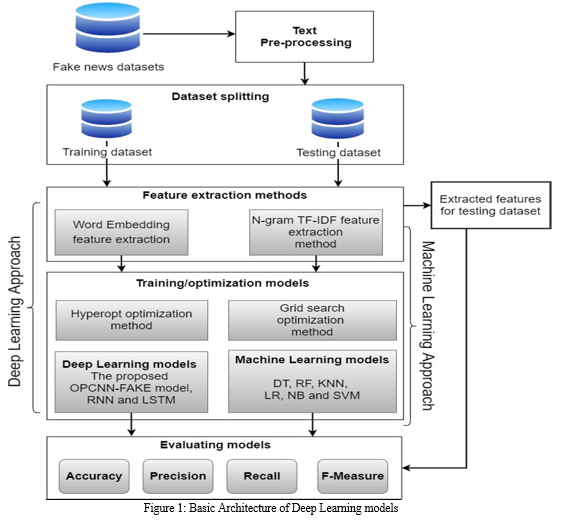
Deep learning is a type of machine learning that enables computers to learn by example, just as humans do. This technique allows computer models to directly learn how to classify data based on visual, textual, or auditory inputs.
???????A. Framework/Basic Architecture
Data Generation: The success of any machine learning application relies on having access to sufficient data, which must come from a reliable source. In most cases, the data is generated as a byproduct of one of the core business functions.
Data Collection: In order for data to be useful in machine learning, it must be easily accessible and stored in a structured and centralized manner. The accuracy of the resulting model depends heavily on the quality of the data used to train it. If the data is inaccurate or outdated, the model's predictions will also be unreliable and irrelevant. Therefore, it is essential to ensure that the data used for machine learning is of high quality and up-to-date.
Feature Extraction: Raw data needs to be preprocessed before feeding it to an algorithm. This involves selecting relevant features, transforming, combining, and preparing the data to make it suitable for analysis by the algorithm. The goal of this process is to convert the raw data into numerical features that can be processed while retaining the important information in the original dataset. Preprocessing also includes handling missing or erroneous data, scaling, normalization, and encoding categorical variables into a numerical format that algorithms can understand. The quality of feature engineering significantly impacts the accuracy and performance of the machine learning model.
Dimensionality Reduction: Dimensionality reduction is an essential technique used to minimize the number of features in a dataset while retaining crucial information as much as possible. It involves the transformation of high-dimensional data into a lower-dimensional space while still preserving the critical aspects of the original data. Principal Component Analysis (PCA) is a popular technique that utilizes a linear transformation to reduce the dimensions of a feature set. The outcome dataset is simpler yet retains the properties of the initial data set.
Training: During the training process, a machine learning algorithm is provided with sufficient training data to learn from, and it adjusts its internal parameters to recognize patterns and relationships within the data. The goal is to develop a model that can accurately predict outcomes or classify new data points based on the patterns it has learned from the training data. The training process typically involves iterating through the data multiple times, refining the model and updating its
parameters until the desired level of accuracy is achieved. Once the model is trained, it can be used to make predictions on new data that it has not seen before.
Evaluation: To ensure that the machine learning model is capable of performing well on real-world data, it is crucial to test it carefully on data that the model has not seen during its training. This helps to avoid the risk of deploying a model that only works well on familiar data and fails to perform when confronted with new, unseen data. Therefore, it is important to have a robust testing and validation process to assess the model's generalization ability and to ensure that it can be applied to new data accurately.
???????B. Different Approaches
- Dimensionality Reduction
Principal Component Analysis (PCA) is a common technique utilized for dimensionality reduction, which applies a linear transformation to decrease the number of dimensions in a feature set. The output dataset has fewer dimensions but still captures the critical features of the initial dataset. This helps to simplify the data while retaining the essential characteristics of the original dataset.
The Chi-Square Statistics is a method that can be used to measure the level of dependence between two variables, such as variable a and variable b. By comparing this dependence to a chi-square distribution with one degree of freedom, it is possible to determine whether the dependence is significant or not. This method can also be used in feature selection, where the goal is to select the most important features for a particular problem. The formula for the Chi-Square feature selection method involves calculating the observed and expected values for each feature, and then computing the chi-square value. The degree of freedom (c) is used as a threshold value to determine which features are important and which ones can be discarded.
Artificial Neural Networks- A neural network is a complex system of algorithms designed to identify underlying relationships within a dataset. It operates by mimicking the way the human brain works, with networks of neurons that can be either organic or artificial in nature.
2. Machine Learning Models
a. Logistic Regression: Logistic regression is a type of statistical model that is primarily used for binary classification problems. Despite its name, it is not a regression model. Logistic regression is considered a simple and efficient method for binary and linear classification problems. It is a classification model that is easy to implement and is known to provide good performance when the classes are linearly separable.
b. Decision Tree: The Decision Tree algorithm is a widely used Supervised learning technique that can be applied to both classification and regression problems. However, it is mostly used for classification tasks. Decision Trees are structured as trees, with internal nodes representing features of the dataset, branches indicating decision rules, and each leaf node indicating the outcome or classification. This algorithm is very intuitive, easy to understand, and can handle both categorical and numerical data. It is also robust to outliers and missing data.
c. K Nearest Neighbour: K-nearest neighbors (KNN) is a supervised learning algorithm used for classification and regression problems. It is a non-parametric method that uses the proximity of data points to make predictions or classifications about the grouping of new data points. KNN works under the assumption that similar data points can be found near each other in the feature space, and therefore the class or value of a new data point can be estimated by looking at the class or value of its nearest neighbors. KNN is commonly used for classification tasks, but it can also be used for regression by averaging the values of the K nearest neighbors.
d. Naive Bayes: Naive Bayes classifiers are a family of probabilistic classifiers based on applying Bayes' theorem with a strong assumption of independence between the features. It is a simple but effective algorithm used for classification tasks in machine learning. The classifier works by calculating the probability of a given data point belonging to a particular class based on the probabilities of each feature being associated with that class. The independence assumption can be naive in some cases, but it still performs well in many real-world applications.
3. Deep Learning models
a. CNN: A Convolutional Neural Network (CNN), also referred to as ConvNet, is a type of deep neural network that excels in processing grid-like data structures such as images. A digital image is a representation of visual data in binary format. It is composed of pixels arranged in a grid pattern, where each pixel represents a value that describes its color and brightness. CNNs use a series of convolutional and pooling layers to extract features from the input image and produce a final output classification or regression result.
b. RNN: Recurrent Neural Networks (RNNs) are a class of neural networks that are designed to work with sequential data, such as time series or natural language text. They are based on the idea of saving the output of a particular layer and feeding it back to the input to predict the output of that layer at the next time step. This allows RNNs to remember the previous inputs and use that information to make predictions. Unlike traditional neural networks, which have a fixed number of layers and parameters, the nodes in different time steps of an RNN are connected, forming a "chain" that allows information to flow from one time step to the next.
c. LSTM: LSTM is a specialized type of recurrent neural network that is designed to handle sequence data with long-term dependencies. It is particularly useful for processing sequential data with gaps of unknown length between important events, and can be used in a variety of applications such as speech recognition, machine translation, video games, and healthcare. LSTM has feedback connections that allow it to process both individual data points and entire sequences of data, making it a powerful tool for deep learning tasks. It is known for its ability to maintain information over long periods of time, which is critical in tasks that require understanding context and making predictions based on that context.
d. Attention: The attention mechanism is a recent advancement in deep neural networks that has gained significant attention. It enables neural networks to selectively focus on specific parts of the input while disregarding others, mimicking the behavior of human attention. This mechanism has been widely used in various applications such as natural language processing, computer vision, and speech recognition. In particular, the attention mechanism is used as a bridge between the encoder and decoder in a neural network architecture.
e. BERT: BERT (Bidirectional Encoder Representations from Transformers) is a state-of-the-art deep learning model for natural language processing (NLP). It was developed by Google and has achieved remarkable performance in a wide range of NLP tasks, such as sentiment analysis, text classification, question-answering, and language translation. BERT is based on a transformer architecture and uses a pre-training strategy to generate contextual word representations, which allows it to better understand the meaning and context of words in a sentence.
???????C. Performance
The complexity of K Nearest Neighbors to find the k closest neighbor-
Train Time Complexity = O(knd)
Loops through every training observation and computes the distance d between the training set observation and new observation. Time is linear with respect to the number of instances (n) and dimensions (d).
Space Complexity = O(nd)
Testing takes longer because you have to compare every test instance to the whole training data.
The complexity of Logistic Regression-
Training Time Complexity means in logistic regression, it means solving the optimization problem.
Train Time Complexity=O(nd)
Space Complexity = O(d)
The complexity of SVM-
Training Time Complexity=O(n²)
Note: if n is large, avoid using SVM.
Run-time Complexity= O(k*d)
K= number of Support Vectors,
d=dimentionality of the data
The complexity of Decision Tree-
Training Time Complexity= O(n*log(n)*d)
n= number of points in the Training set
d=dimentionality of the data
Run-time Complexity= O(maximum depth of the tree)
The complexity of Random Forest-
Training Time Complexity= O(n*log(n)*d*k) k=number of Decision Trees
Run-time Complexity= O(depth of tree* k)
Space Complexity= O(depth of tree *k)
The complexity of Naive Bayes-
Training Time Complexity = O(n*d)
Run-time Complexity = O(c*d)
We have to retrieve feature for each class’s ‘c’
???????D. Evaluation
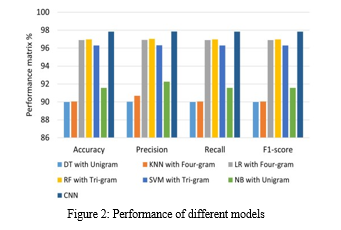
Diverse evaluation metrics are used to evaluate the model’s efficiency. The evaluation matrix is an essential device for arranging and organizing an evaluation. The confusion matrix shows an overview of model performance on the testing dataset from the known true values. It provides a review of the model’s success and useful results of true positive, true negative, false positive, and false negative. To test their models, researchers considered distinctive sorts of metrics such as accuracy (A), precision (P), and recall(R). The selection of metrics relies entirely on the model form and its implementation strategy.
Deep learning techniques and models prove to be better than machine learning models when it comes to detection of fake news. They provide a much more efficient performance and higher accuracy rates. The emerging models that include the hybrid models and attention, BERT and others seem to perform well but their performance varies across different datasets. The result ultimate depends on how the data is handles and seen by the model. The amount of data, variations in it, number of features, dimensionality all contribute the computational complexity and performance of the model. Most of the work done since 2017 involves different deep learning techniques. Newer studies focus more on emerging techniques and hybrid models that are proving to be better in every sense. Still a lot of refining needs to be carried out to accurately identify fake news. With the help of deep learning most of the spread of fake news and frauds can stopped if implemented correctly at the right time.
IV. ACKNOWLEDGMENTS
I would like to express my gratitude to my mentor Mr. Tushar Rane for his continued support and positive outlook. Sir gave me the chance to work on “FAKE NEWS DETECTION”. I would like to express my thanks to the people who have helped me most throughout my project, my friends. Their interesting ideas, thoughts helped me understand and better my seminar work. I would also like to thank the head of IT Department Dr. A. S. Ghotkar and all the academic staff of the IT Department for their support.
Conclusion
Detection of fake news has many applications. It can be used to control or even stop the spread of fake news and false information on social media. It is helpful in detecting misleading information and hoaxes. Fake news detection can be used to identify fraudulent messages and click baits. Humans have been proven to be not proficient in differentiating between truth and falsehood when overloaded with deceptive information. Studies in social psychology and communications have demonstrated that human ability to detect deception is only slightly better than chance. Hence, use of deep learning in fake news detection makes it more efficient. Massive dissemination of fake news and its potential to erode democracy has increased the demand for accurate fake news detection. Recent advancements in this area have proposed novel techniques that aim to detect fake news by exploring how it propagates on social networks. Nevertheless, to detect fake news at an early stage, i.e., when it is published on a news outlet but not yet spread on social media, one cannot rely on news propagation information as it does not exist. Fake news detection has been an area of interest since early 2017. A lot of work has since been carried out. Fake news is set to increase in coming years as the spread of information becomes easier. But we can also be assured that new on better ways of detecting it will be developed and implemented in the future. Intensive research has been carried out for the detection of fake news for quite a few years now. It has been done to reduce the influence of fake news on the society. With development and advances in machine learning and deep learning more effective ways are being researched and tested.
References
[1] M. H. Goldani, R. Safabakhsh, and S. Momtazi, ‘‘Convolutional neural network with margin loss for fake news detection,’’ Inf. Process. Manage., vol. 58, no. 1, Jan. 2021, Art. no. 102418. [2] H. Saleh, A. Alharbi and S. H. Alsamhi, ”OPCNN-FAKE: Optimized Convolutional Neural Network for Fake News Detection,” in IEEE Access, vol. 9, pp. 129471-129489, 2021, doi: 10.1109/ACCESS.2021.3112806. [3] M. Umer, Z. Imtiaz, S. Ullah, A. Mehmood, G. S. Choi and B. -W. On, ”Fake News Stance Detection Using Deep Learning Architecture (CNN-LSTM),” in IEEE Access, vol. 8, pp. 156695-156706, 2020 [4] Shubha Mishra, Piyush Shukla, Ratish Agarwal, ”Analyzing Machine Learning Enabled Fake News Detection Techniques for Diversified Datasets”, Wireless Communications and Mobile Computing, vol. 2022, Article ID 1575365, 18 pages, 2022. [5] M. F. Mridha, A. J. Keya, M. A. Hamid, M. M. Monowar and M. S. Rahman, ”A Comprehensive Review on Fake News Detection With Deep Learning,” in IEEE Access, vol. 9, pp. 156151-156170, 2021. [6] T. Jiang, J. P. Li, A. U. Haq, A. Saboor and A. Ali, ”A Novel Stacking Approach for Accurate Detection of Fake News,” in IEEE Access, vol. 9, pp. 22626-22639, 2021, doi: 10.1109/ACCESS.2021.3056079. [7] D. Rohera et al., ”A Taxonomy of Fake News Classification Techniques: Survey and Implementation Aspects,” in IEEE Access, vol. 10, pp. 30367-30394, 2022, doi: 10.1109/ACCESS.2022.3159651 [8] A. Zubiaga, A. Aker, K. Bontcheva, M. Liakata, and R. Procter, ‘‘Detection and resolution of rumours in social media: A survey,’’ ACM Comput. Surveys, vol. 51, no. 2, pp. 1–36, Jun. 2018. [9] M. D. Ibrishimova and K. F. Li, ‘‘A machine learning approach to fake news detection using knowledge verification and natural language processing,’’ in Proc. Int. Conf. Intell. Netw. Collaborative Syst. Cham, Switzerland: Springer, 2019, pp. 223–234. [10] M. A. Walker, P. Anand, R. Abbott, and R. Grant, ‘‘Stance classification using dialogic properties of persuasion,’’ in Proc. Conf. North Amer. Chapter Assoc. Comput. Linguistics: Hum. Lang. Technol., Stroudsburg, PA, USA, 2012, pp. 592–596. [11] S. Somasundaran and J. Wiebe, ‘‘Recognizing stances in ideological online debates,’’ in Proc. NAACL HLT Workshop Comput. Approaches Anal. Gener. Emotion Text, Los Angeles, CA, USA, Jun. 2010, pp. 116–124. [12] S. Mohammad, S. Kiritchenko, P. Sobhani, X. Zhu, and C. Cherry, ‘‘SemEval-2016 task 6: Detecting stance in tweets,’’ in Proc. 10th Int. Workshop Semantic Eval. (SemEval-2016), San Diego, CA, USA, Jun. 2016, pp. 31–41. [13] C. Stab, T. Miller, and I. Gurevych, ‘‘Cross-topic argument mining from heterogeneous sources using attention-based neural networks,’’ 2018, arXiv:1802.05758. [14] R. K. Kaliyar, A. Goswami, P. Narang, and S. Sinha, ‘‘FNDNet—A deep convolutional neural network for fake news detection,’’ Cognit. Syst. Res., vol. 61, pp. 32–44, Jun. 2020. [15] S. Kumar, R. Asthana, S. Upadhyay, N. Upreti, and M. Akbar, ‘‘Fake news detection using deep learning models: A novel approach,’’ Trans. Emerg. Telecommun. Technol., vol. 31, no. 2, p. e3767, Feb. 2020.
Copyright
Copyright © 2023 Adwait Bandal, Tushar Rane. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET52318
Publish Date : 2023-05-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online