

Ijraset Journal For Research in Applied Science and Engineering Technology
Fake News Detection Using Deep Learning
Authors: Nazakat Farooq Khan, Ankur Gupta
DOI Link: https://doi.org/10.22214/ijraset.2022.46838
Certificate: View Certificate
Abstract
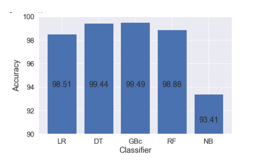
Social media news may be a double-edged sword. There are a number of benefits to utilizing it: It\'s simple to use, takes little time, and is user-friendly. It\'s also simple to share socially significant data with others. On the other hand, a number of social networking sites adapt the news based on personal opinions and interests. This sort of misinformation is spread over social media with the intent of causing harm to a person, organization, or institution. Because of the prevalence of fake news, computer tools are needed to detect it. Fake news detection aims to aid users in spotting various sorts of fake news. We can tell if the news is genuine or created if we have encountered fake or authentic news before. We may use a number of models to understand social media news. This is a donation in two ways. We must first give datasets containing both fake and accurate news and conduct multiple experiments before developing a false news detector. Various machine learning techniques are used to categorize the data. Random Forest, Logistic Regression, Naives Bayes, Gradient Boost and Decision Tree techniques are used and compared. It was found that Gradient Boost has the best accuracy.
Introduction
I. Introduction
Fake news swiftly grew in popularity as a means of disseminating or spreading false information in attempt to influence people's behaviour. The proliferation of false news[2] during the 2016 US presidential elections exposed it as incontrovertible. The following are some facts about false news in the United States. Sixty-two present of Americans get their news from social media. On Facebook, bogus news has a higher share than real news[4]. False news also influenced the "Brexit" referendum in the United Kingdom. In this paper, I investigate the possibility of detecting fake news using traditional learning approaches by just adding text.
Data mining prospects[5] are used to detect fake social media news. The characteristics come first, followed by the measurement. The latter is inaccurate information. In order to construct detection models, characterization must occur before attempting to identify bogus news.
Authenticity and aim are two aspects of the concept of fake news. Authenticity entails the verification of falsifiable information, which implies that the conspiracy theory is not included in the falsified news since it is either false or true in most circumstances. The document's purpose, the second component, consists of writing incorrect facts in order to fool the reader.
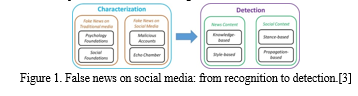
The qualities used to categorize the fake news are four key raw components to consider: They are:
Source: Where the information comes from, who developed it, and whether or not this source can be trusted.
Title: A quick description of the news the reader tries to draw.
Body: The real linguistic substance of the news is written in the body.
Textual content is generally agreed upon alongside visual information, such as photographs, movies, or music.
With verbal and visual core characteristics, these four main components may be reconstructed. As previously said, bogus material is utilized to persuade a customer and is generally written in a way that appeals to the reader. Non-fake warnings, on the other hand, tend to use a more formal language register.
These are linguistic characteristics that can have lexical characteristics due to the total number of words, frequency of words, or specific words. The second consideration is visual elements, aspects of appearance. In fact, manipulated images are frequently utilized to give textual information more weight.
II. Literature review
Ruchanskyet al. [11] employed a hybrid low-profile detection technique that included diverse capabilities, such as the temporal interaction of n users with m news items, across time.
Tacchiniet al. [12] has developed a method for detecting false information based on data from social media sites such as likes and users. Thorne advocated a stacked ensemble classification to cope with a false news classification problem. In reality, an article either supports or opposes a fact.
Granik and Mesyura[13] categorize news from buzz data sets using Nave Bayes classifiers. Yang has employed the visual portions of neural networking visuals in addition to text and social characteristics. Wang employs visual cues to identify fake news, but he does it with unfavourable neural networks.
Himank Gupta et. al. [16] gave a framework based on different machine learning approach that deals with various problems including accuracy shortage, time lag (BotMaker) and high processing time to handle thousands of tweets in 1 sec. Firstly, they have collected 400,000 tweets from HSpam14 dataset. Then they further characterize the 150,000 spam tweets and 250,000 non- spam tweets. They also derived some lightweight features along with the Top-30 words that are providing highest information gain from Bag-of-Words model. 4. They were able to achieve an accuracy of 91.65% and surpassed the existing solution by approximately18%.
Marco L. Della Vedova et. al. [17] first proposed a novel ML fake news detection method which, by combining news content and social context features, outperforms existing methods in the literature, increasing its accuracy up to 78.8%. Second, they implemented their method within a Facebook Messenger Chabot and validate it with a real-world application, obtaining a fake news detection accuracy of 81.7%. Their goal was to classify a news item as reliable or fake; they first described the datasets they used for their test, then presented the content-based approach they implemented and the method they proposed to combine it with a social-based approach available in the literature. The resulting dataset is composed of 15,500 posts, coming from 32 pages (14 conspiracy pages, 18 scientific pages), with more than 2, 300, 00 likes by 900,000+ users. 8,923 (57.6%) posts are hoaxes and 6,577 (42.4%) are non-hoaxes.
Mykhailo Granik et. al. in their paper [18] shows a simple approach for fake news detection using naive Bayes classifier. This approach was implemented as a software system and tested against a data set of Facebook news posts. They were collected from three large Facebook pages each from the right and from the left, as well as three large mainstream political news pages (Politico, CNN, ABC News). They achieved classification accuracy of approximately 74%. Classification accuracy for fake news is slightly worse. This may be caused by the skewness of the dataset: only 4.9% of it is fake news.
III. methodology
A. Logistic Regression
Logistic regression explains the likelihood of categorization difficulties with two possible outcomes. It is an expansion of the linear regression classification problem model. For regression, the linear regression model works well, but classification does not. Why is this the case? What gives? What gives? One class with 0 for two classes, one class with 1 for one class, and one class using linear regression for one class. Most linear models are weighted, and it works theoretically. However, there are a couple flaws with this strategy: A linear model is unlikely to produce classes; instead, it will treat them as numbers in the ideal hyperplane, minimizing the distance between points and hyperplanes. It just connects items and cannot be interpreted as probability. A linear model also extrapolates and produces values that are below and below zero. There is no significant threshold for differentiating between one class and another since the anticipated result is a linear interpolation of points rather than a probability. Stack overflow is a nice example of this problem. Linear models do not address multi-class classification issues.
- Advantages and Disadvantages
Many of the advantages and disadvantages of the linear regression model apply to the logistic regression model. Many people have regressed logistically, despite the fact that they are suffering with their restricted expression (e.g. manually formed interactions) and that alternative models can help. Another disadvantage of the logistic regression model is that it is more difficult to understand since weight interpretation is many and does not add up. The logistical regression might lead to total separation. The logistic regression model cannot be trained further if the two groups are fully distinguished. This is due to the fact that the weight for this feature would never converge since its ideal weight was infinite. It’s a shame, because it's such a valuable trait. However, if you have a simple rule that divides both groups, you won't require any machine training. Weight penalization or the generation of a prior probability distribution of weights can be used to solve the entire separation problem.
On the right, the logistic regression model provides you with not just a classification model, but also an opportunity. This is a significant advantage over models that can only be identified by their finish. Knowing that an instance has a 99 present chance for a class vs. 51 percent makes a major impact.
It may also be converted to a multi-class regression. The Multinomial regression is then triggered.
B. Decision Tree
Linear regression and logistic regression patterns fail when characteristics and outcomes are non-linear or interact with one another. Now is your chance to shine in the decision tree! Data is multiplied by particular cut-offs in functions in tree-based models. A sub-set per instance is used to create different sub-sets. End nodes or feature nodes relate to the last subsets, whereas internal nodes or splits refer to the secondary subsets. To forecast the outcome, the average training results for each node are used. Classification and regression may both be done with trees.
- Advantages
The tree structure enables for the recording of interactions between data components.
Different groups find facts simpler to understand than linearly regressive multi-dimensional hyperplanes. It has an obvious importance, no question. With its nodes and limits, the tree structure provides a natural visualisation.
Because an instance forecast may always be contrasted with the relevant "what if" scenario, a mere node of the tree, the tree explanations are conflicting. The findings are divided into 1 to 3 divisions if the tree is tiny. A three-depth tree just requires three characteristics and split points to represent a specific instance's prediction. The tree predicts the correctness of the forecast. The short trees are relatively simple and general, as each division is easy to grasp with one or two leaves and binary decisions.
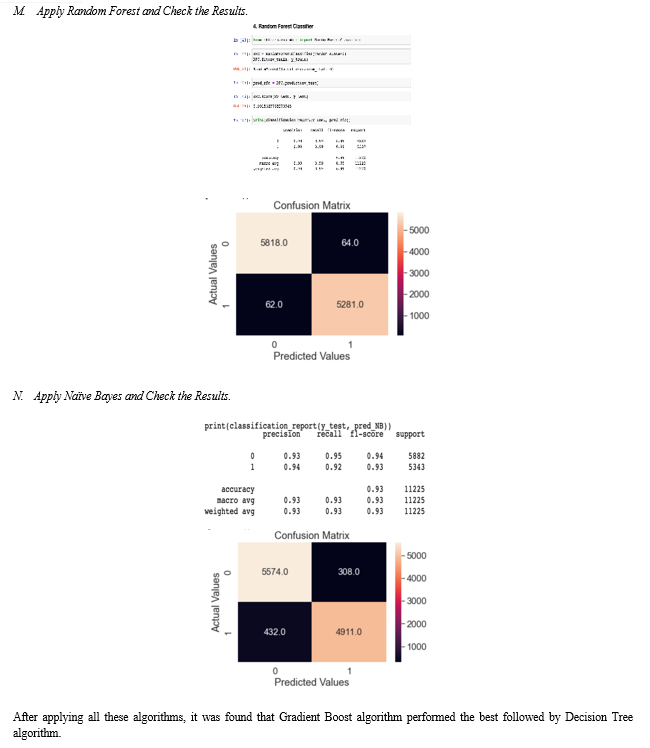
C. Random Forest
Random Forest excels at categorization issues [3]. This method was selected for four primary reasons. First, given the numerical and categorical feature set, the notion of traversing a collection of questions using decision trees makes more sense. For example, if the domain score and Facebook popularity indicators are low, it is a solid sign that the news may be untrustworthy. A comparable comparison of the word vector will aid in the identification of a trend in bogus news. Second, the random forest supports a variety of feature types, such as binary, categorical, numerical, and, in particular, the spare matrix, which is utilised to represent the word vector. Third, because random forest employs a collection of decision trees that are trained on a portion of the dataset, overfitting is extremely rare. Overfitting is a challenging problem to detect and correct, and each option to reduce overfitting is a step toward constructing a stronger classifier. Finally, random forest performs well on huge data sets, and as the corpus grows, this is a good approach for the job. It's worth noting that the random forest approach, like any other ensemble algorithm, takes longer to train than popular algorithms like Logistic Regression and Decision Trees. This problem, however, may be solved by employing additional workers in a parallel and distributed system setting.
D. Naives Bayes
It is a powerful classification model that performs well when we have a small dataset and it requires less storage space. It does not produce good results if words are co related between each other [18].
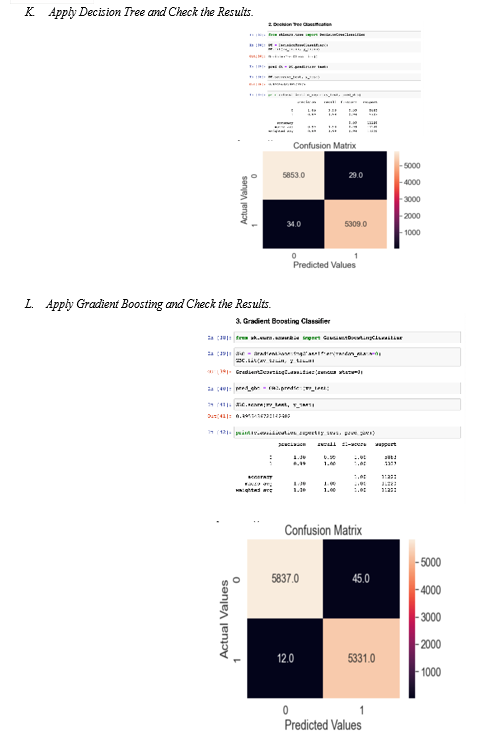
E. Gradient Boosting
The statistical prediction model is another name for the gradient boosting technique. Although it enables the generalisation and optimization of the differential loss functions, it yet behaves relatively similarly to previous boosting techniques. Gradient boosting is typically used in regression and classification processes.


Conclusion
With more people using the internet, spreading false information is becoming easier. Many people use the Internet and social media on a regular basis. On these sites, there are no limits on posting news. As a result, some people take advantage of these channels and start disseminating false information about people or organizations. This might ruin a person\'s reputation or have an impact on a business. False news can also influence public opinion about a political party. This fake news must be discovered. We used five different machine learning algorithms and found Gradient Boost to be the best.
References
[1] Great moon hoax. https://en.wikipedia.org/wiki/Great Moon Hoax. [Online; accessed 25-September-2017]. [2] S. Adali, T. Liu, and M. Magdon-Ismail. Optimal link bombs are uncoordinated. In AIRWeb, 2005. [3] L. Akoglu, R. Chandy, and C. Faloutsos. Opinion fraud detection in online reviews by network effects. In ICWSM, 2013. [4] H. Allcott and M. Gentzkow. Social media and fake news in the 2016 election. Journal of Economic Perspectives, 2017. [5] E. Arisoy, T. Sainath, B. Kingsbury, and B. Ramabhadran. Deep neural network language models. In WLM, 2012. [6] K. Bharat and M. Henzinger. Improved algorithms for topic distillation in a hyperlinked environment. In SIGIR, 1998. [7] C. Castillo, D. Donato, A. Gionis, V. Murdock, and F. Silvestri. Know your neighbors: web spam detection using the web topology. In SIGIR, 2007. [8] C.-C. Chang and C.-J. Lin. LIBSVM: a library for support vector machines, 2001. Software available at http://www.csie.ntu.edu.tw/?cjlin/ libsvm. [9] K. Chellapilla and D. Chickering. Improving cloaking detection using search query popularity and monetizability. In AIRWeb, 2006. [10] J. Chung, C¸ . Gulc¸ehre, K. Cho, and Y. Bengio. Empirical evaluation ¨ of gated recurrent neural networks on sequence modeling. CoRR, abs/1412.3555, 2014. [11] E. Convey. Porn sneaks way back on web. The Boston Herald, 1996. [12] N. Daswani and M. Stoppelman. The anatomy of clickbot.a. In HotBots, 2007. [13] L. Deng, G. Hinton, and B. Kingsbury. New types of deep neural network learning for speech recognition and related applications: An overview. In ICASSP, 2013. [14] Z. Dou, R. Song, X. Yuan, and J. Wen. Are click-through data adequate for learning web search rankings? In CIKM, 2008. [15] Sharma, Uma & Saran, Sidarth & Patil, Shankar. (2020). Fake News Detection Using Machine Learning Algorithms. [16] H. Gupta, M. S. Jamal, S. Madisetty and M. S. Desarkar, \"A framework for real-time spam detection in Twitter,\" 2018 10th International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, 2018, pp. 380-383 [17] M. L. Della Vedova, E. Tacchini, S. Moret, G. Ballarin, M. DiPierro and L. de Alfaro, \"Automatic Online Fake News Detection Combining Content and Social Signals,\" 2018 22nd Conference of Open Innovations Association (FRUCT), Jyvaskyla, 2018, pp. 272- 279. [18] M. Granik and V. Mesyura, \"Fake news detection using naive Bayes classifier,\" 2017 IEEE First Ukraine Conference on Electrical and Computer Engineering (UKRCON), Kiev, 2017, pp. 900-903.
Copyright
Copyright © 2022 Nazakat Farooq Khan, Ankur Gupta. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET46838
Publish Date : 2022-09-20
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online