

Ijraset Journal For Research in Applied Science and Engineering Technology
Fake News Detection using Machine Learning
Authors: Vookanti Anurag Reddy, CH Vamsidhar Reddy, Dr. R. Lakshminarayanan
DOI Link: https://doi.org/10.22214/ijraset.2022.41124
Certificate: View Certificate
Abstract
This Project comes up with the applications of NLP (Natural Language Processing) techniques for detecting the \'fake news\', that is, misleading news stories that comes from the non-reputable sources. Only by building a model based on a count vectorizer (using word tallies) or a (Term Frequency Inverse Document Frequency) tfidf matrix, (word tallies relative to how often they’re used in other articles in your dataset) can only get you so far. But these models do not consider the important qualities like word ordering and context. It is very possible that two articles that are similar in their word count will be completely different in their meaning. The data science community has responded by taking actions against the problem. There is a Kaggle competition called as the “Fake News Challenge” and Facebook is employing AI to filter fake news stories out of users’ feeds. Combatting the fake news is a classic text classification project with a straight forward proposition. Is it possible for you to build a model that can differentiate between “Real “news and “Fake” news? So a proposed work on assembling a dataset of both fake and real news and employ a Naive Bayes classifier in order to create a model to classify an article into fake or real based on its words and phrases.
Introduction
I. INTRODUCTION
These days’ fake news is creating different issues from sarcastic articles to a fabricated news and plan government propaganda in some outlets. Fake news and lack of trust in the media are growing problems with huge ramifications in our society. Obviously, a purposely misleading story is “fake news “ but lately blathering social media’s discourse is changing its definition. Some of them now use the term to dismiss the facts counter to their preferred viewpoints. The importance of disinformation within American political discourse was the subject of weighty attention , particularly following the American president election . The term 'fake news' became common parlance for the issue, particularly to describe factually incorrect and misleading articles published mostly for the purpose of making money through page views. In this paper,it is seeked to produce a model that can accurately predict the likelihood that a given article is fake news. Facebook has been at the epicenter of much critique following media attention. They have already implemented a feature to flag fake news on the site when a user sees’s it ; they have also said publicly they are working on to to distinguish these articles inan automated way. Certainly, it is not an easy task. A given algorithm must be politically unbiased – since fake news exists on both ends of the spectrum – and also give equal balance to legitimate news sources on either end of the spectrum. In addition, the question of legitimacy is a difficult one. However, in order to solve this problem, it is necessary to have an understanding on what Fake News is. Later, it is needed to look into how the techniques in the fields of machine learning, natural language processing help us to detect fake news.
II. WORKING
A. Existing System
There exists a large body of research on the topic of machine learning methods for deception detection, most of it has been focusing on classifying online reviews and publicly available social media posts. Particularly since late 2016 during the American Presidential election, the question of determining 'fake news' has also been the subject of particular attention within the literature. Conroy, Rubin, and Chen outlines several approaches that seem promising towards the aim of perfectly classify the misleading articles. They note that simple content-related n-grams and shallow parts-of-speech (POS) tagging have proven insufficient for the classification task, often failing to account for important context information. Rather, these methods have been shown useful only in tandem with more complex methods of analysis. Deep Syntax analysis using Probabilistic Context Free Grammars (PCFG) have been shown to be particularly valuable in combination with n-gram methods. Feng, Banerjee, and Choi are able to achieve 85%-91% accuracy in deception related classification tasks using online review corpora. Feng and First implemented a semantic analysis looking at ‘object: descriptor’ pairs for contradictions with the text on top of Feng’s initial deep syntax model for additional improvement. Rubin, Lukoianova and Tatiana analyze rhetorical structure using a vector space model with similar success. Ciampaglia et al. employ language pattern similarity networks requiring a pre-existing knowledge base.
B. Disadvantages
- It is not possible to find whether the given data is Real or Fake.
- Fake data will be increases.
C. Proposed System
In this paper a model is build based on the count vectorizer or a tfidf matrix ( i.e ) word tallies relatives to how often they are used in other artices in your dataset ) can help . Since this problem is a kind of text classification, Implementing a Naive Bayes classifier will be best as this is standard for text-based processing. The actual goal is in developing a model which was the text transformation (count vectorizer vs tfidf vectorizer) and choosing which type of text to use (headlines vs full text). Now the next step is to extract the most optimal features for count vectorizer or tfidf-vectorizer, this is done by using a n-number of the most used words, and/or phrases, lower casing or not, mainly removing the stop words which are common words such as “the”, “when”, and “there” and only using those words that appear at least a given number of times in a given text dataset.
D. Flow Of The Project
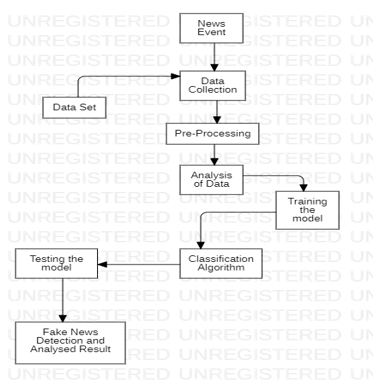
E. Advantages
- It is possible to find whether the given data is Real or Fake.
- Fake data will be decreases.
III. RESULTS & DISCUSSIONS
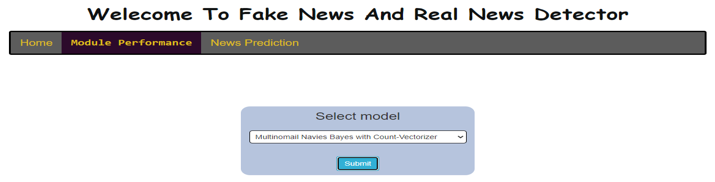
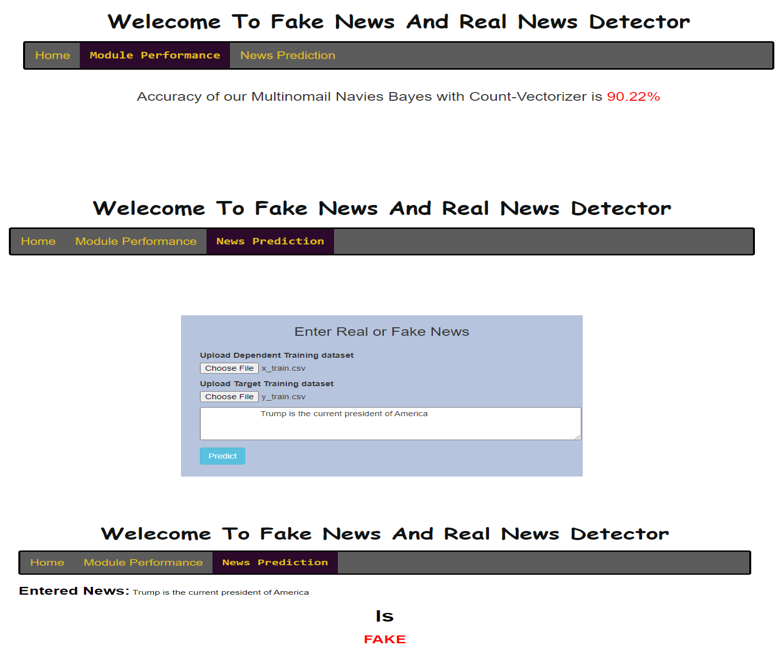
Conclusion
With an increasing focus of academic researchers and practitioners alike on the detection of online misinformation, the current investigation allows for two key conclusions. First, computational linguistics can aide in the process of identifying fake news in an automated manner well above the chance level. The proposed linguistics-driven approach suggests that to differentiate between fake and genuine content it is worthwhile to look at the lexical, syntactic and semantic level of a news item in question. The developed system’s performance is comparable to that of humans in this task, with an accuracy up to 76%. Nevertheless, while linguistics features seem promising, we argue that future efforts on misinformation detection should not be limited to these and should also include meta features (e.g., number of links to and from an article, comments on the article), features from different modalities (e.g., the visual makeup of a website using computer vision approaches), and embrace the increasing potential of computational approaches to fact verification (Thorne et al., 2018). Thus, 3400 future work might want to explore how hybrid decision models consisting of both fact verification and data-driven machine learning judgments can be integrated. Second, we showed that it is possible to build resources for the fake news detection task by combining manual and crow sourced annotation approaches. Our paper presented the development of two datasets using these strategies and showed tha wort they exhibit linguistic properties related to deceptive content. Furthermore, different from other available fake news datasets, our dataset consists of actual news excerpts, instead of short statements containing fake news information. Finally, with the current investigation and dataset, we encourage the research community and practitioners to take on the challenge of tackling misinformation.
References
[1] Majed AlRubaian, Muhammad Al-Qurishi, Mabrook Al-Rakhami, Sk Md Mizanur Rahman, and Atif Alamri. 2015. A Multistage Credibility Analysis Model for Microblogs. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015 (ASONAM \'15), Jian Pei, Fabrizio Silvestri, and Jie Tang (Eds.). ACM, New York, NY, USA, 1434-1440. DOI: http://dx.doi.org/10.1145/2808797.2810065 [2] Majed Alrubaian, Muhammad Al-Qurishi, A Credibility Analysis System for Assessing Information on Twitter, IEEE Transactions on Dependable and Secure Computing, 1-14. DOI : http://dx.doi.org/ 10.1109/TDSC.2016.2602338 [3] Manish Gupta, Peixiang Zhao, Jiawei Han, 2012. Evaluating Event Credibility on Twitter, Proceedings of the 2012 SIAM International Conference on Data Mining, 153-164 , DOI: http://epubs.siam.org/doi/abs/10.1137/ 1.9781611972825.14 [4] Krzysztof Lorek, Jacek Suehiro-Wici´nski, Micha l Jankowski-Lorek, Amit Gupta, Automated credibility assessment on twitter, Computer Science, 2015, Vol.16(2), 157-168, DOI: http://dx.doi.org/10.7494/csci. 2015.16.2.157 [5] Ballouli, Rim El, Wassim El-Hajj, Ahmad Ghandour, Shady Elbassuoni, Hazem M. Hajj and Khaled Bashir Shaban. 2017. “CAT: Credibility Analysis of Arabic Content on Twitter.” WANLP@EACL (2017). [6] Alina Campan, Alfredo Cuzzocrea, Traian Marius Truta, 2017. Fighting Fake News Spread in Online Social Networks: Actual Trends and Future Research Directions, IEEE International Conference on Big Data (BIGDATA), 4453-4457 [7] Carlos Castillo, Marcelo Mendoza, and Barbara Poblete. 2011. Information credibility on twitter. In Proceedings of the 20th international conference on World wide web (WWW \'11). ACM, New York, NY, USA, 675-684. DOI: http://dx.doi.org/10.1145/1963405. 1963500 [8] Muhammad Abdul-Mageed, Mona Diab, Sandra Kübler,2014. SAMAR: Subjectivity and sentiment analysis for Arabic social media, Computer Speech & Language, Elsevier BV, ISSN: 0885-2308, V.28, Issue: 1, 20- 37, DOI: http://dx.doi.org/10.1016/j.csl.2013.03.001 [9] Niall J. Conroy, Victoria L. Rubin, and Yimin Chen. 2015. Automatic deception detection: methods for finding fake news. In Proceedings of the 78th ASIS&T Annual Meeting: Information Science with Impact: Research in and for the Community (ASIST \'15). American Society for Information Science, Silver Springs, MD, USA, , Article 82 , 4 pages. [10] Granik, M., & Mesyura, V. 2017. Fake news detection using naive Bayes classifier. 2017 IEEE First Ukraine Conference on Electrical and Computer Engineering (UKRCON), 900-903. [11] Hertz, J., Palmer, R.G., Krogh. A.S. 1990 Introduction to the theory of neural computation, Perseus Books. ISBN 0-201-51560-1 [12] Thandar M., Usanavasin S. 2015 Measuring Opinion Credibility in Twitter. In: Unger H., Meesad P., Boonkrong S. (eds) Recent Advances in Information and Communication Technology 2015. Advances in Intelligent Systems and Computing, vol 361. Springer, Cham [13] Aker, A., Bontcheva, K., Liakata, M., Procter, R., & Zubiaga, A. 2017. Detection and Resolution of Rumours in Social Media: A Survey. CoRR, abs/1704.00656. [14] W. Vorhies, Using algorithms to detect fake news - The state of the art, 2017, [online] Available: http://www.datasciencecentral.com/profiles/ blogs/using-algorithms-to-detect-fake-news-the-state-of-the-art. [15] Ehsanfar, Abbas and Mo Mansouri. 2017. “Incentivizing the dissemination of truth versus fake news in social networks.” 2017 12th System of Systems Engineering Conference (SoSE), 1-6. [16] Hal Berghel. 2017. Alt-News and Post-Truths in the \"Fake News\" Era. Computer 50, 4 (April 2017), 110-114. DOI: https://doi.org/10.1109/ MC.2017.104 [17] Buntain, C., & Golbeck, J. 2017. Automatically Identifying Fake News in Popular Twitter Threads. 2017 IEEE International Conference on Smart Cloud (SmartCloud), 208-215
Copyright
Copyright © 2022 Vookanti Anurag Reddy, CH Vamsidhar Reddy, Dr. R. Lakshminarayanan. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET41124
Publish Date : 2022-03-31
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online