

Ijraset Journal For Research in Applied Science and Engineering Technology
Fake News Detection using Machine Learning - A Working Model of Fake News Detection
Authors: E.V. Nagalakshmi , E. Sai Vineeth, Y. Goutham, T. Vamshi Krishna
DOI Link: https://doi.org/10.22214/ijraset.2023.51637
Certificate: View Certificate
Abstract
This project aims to address the pressing issue of fake news, which has become increasingly prevalent in today\'s society. With the internet and social media making news more accessible than ever, the spread of fake news can have a significant impact on social, economic, and political environments. In response to this challenge, this project investigates the use of machine learning algorithms to accurately classify news as real or fake. The project utilizes KNN, Decision Tree, and Logistic Regression algorithms to analyze large datasets of news articles and learn the patterns and characteristics of real and fake news. The primary objective of this project is to provide users with a tool that can accurately detect fake news and help prevent its spread
Introduction
I. INTRODUCTION
Fake news has become a prevalent issue in modern society due to the rapid dissemination of information through social media platforms and other digital channels. The spread of fake news can have serious consequences, leading to the manipulation of public opinion, political instability, and even violence. Therefore, it is essential to identify and prevent the spread of fake news to mitigate its negative impact. In this report, we explore the use of machine learning algorithms for fake news detection.
Machine learning algorithms can be used to automate the process of fake news detection by learning patterns and characteristics that distinguish fake news from genuine news. Machine learning algorithms use statistical methods to learn from labelled data and generalize to new, unseen data. This approach is particularly well-suited to fake news detection as it can leverage large volumes of data to identify subtle patterns and trends that might be difficult for humans to discern. By training machine learning models on large datasets of labelled news articles, it is possible to develop highly accurate models that can classify new articles as either fake or genuine with high precision. This can help to prevent the spread of fake news and protect the public from misinformation and manipulation.
A. Objectives Of The Project
- Develop a machine learning model that can accurately authenticate whether a given news article is real or fake.
- Collect and prepare a diverse set of training data that includes various scenarios and aspects of fake news.
- Explore and use different machine learning algorithms such as logistic regression, k-nearest neighbors, and decision tree classifier to find the best algorithm for detecting fake news.
- Evaluate the performance of each algorithm based on accuracy and confusion matrix.
- Continuously refine and improve the model to adapt to the ever-changing landscape of fake news.
II. LITERATURE SURVEY
- Convolutional Neural Networks: Rohit Kumar Kaliyar developed A Deep Neural Network techniques for fake news detection . He used Fake or Real News Dataset for detecting the fake news by classifying with Convolutional Neural Networks, Long Short term memory, Naïve Bayes, Decision Tree, Random Forest and K-Nearest Neighbour techniques. In this by increasing the depth of the network the accuracy is increased when using the CNN method. In this by using k-nearest neighbour algorithm the accuracy is decreased and also precision, recall, f1-score values are reduced. In this he gained maximum accuracy of 91.3% by using CNN algorithm. Belhakimi Mohamed Amine, Ahlem Drif, Silvia Giordano developed a Merging deep learning model for fake news detection
- B. K-Nearest Neighbour: Ankit Kesarwani, Sudakar Singh Chauhan and Anil Ramachandran Nair developed a K-Nearest Neighbour Classifier technique for Fake News Detection on Social Media. In this they use Buzz Feed news. It contains the information about the Facebook news. In this the model has achieved maximum accuracy when the value of K taken between15 to 20. In this they gain the maximum accuracy of 79% tested against Facebook news dataset.
- C. Logistic Regression: It is a Machine Learning classification algorithm that is used to predict the probability of a categorical dependent variable. In logistic regression, the dependent variable is a binary variable that contains data coded as 1 (yes and success) or 0 (no and failure). Uma Sharma, Sidarth Saran, Shankar M. Patil developed a Fake News Detection using Machine Learning Algorithms They used liar dataset for detecting if fake news by Naïve Bayes Classifier, Logistic Regression, Random Forest. They used Bag-Of-Words, N-Grams, TF-IDF. Logistic regression shows better results with accuracy of 65%. Iftikhar Ahmad, Muhammad Yousaf, Suhail Yousaf and Muhammad Ovais Ahmad implemented a model for fakenews detection on social media
III. METHODOLOGY FOR FAKE NEWS DETECTION USING ML
A. Data Set
For a project on fake news detection using machine learning, several Python libraries were utilized to process and analyze the data, as well as to train and evaluate the machine learning models. These libraries included NumPy, Pandas, Seaborn, Matplotlib, and scikit-learn (sklearn).
To load and preprocess the data, NumPy and Pandas were used, which provided efficient numerical operations and powerful data manipulation and analysis capabilities, respectively. Seaborn and Matplotlib were also used to create visualizations of the data, which helped to better understand its characteristics and identify potential patterns. Finally, scikit-learn was used to train and evaluate the machine learning models. This library provided a wide range of machine learning algorithms, as well as tools for data preprocessing, feature extraction, and model selection. Common algorithms used in fake news detection include decision trees, support vector machines (SVMs), and neural networks. To prepare the data for machine learning, the data was first loaded and cleaned using Pandas. Scikit-learn was then used to extract features from the textual data, such as sentiment analysis, lexical diversity, and topic modeling. These features were used to train and evaluate the machine learning models, which were also implemented using scikit-learn. Overall, the libraries used in the project provided a powerful set of tools for processing, analyzing, and visualizing the data, as well as for training and evaluating the machine learning models. These tools were critical in enabling effective detection of fake news from textual data using machine learning
B. Data Pre-Processing
- Data Cleaning: The first step in data preprocessing is cleaning the data, which involves removing any unnecessary or irrelevant information from the dataset, such as HTML tags, URLs, and special characters. This can be done using regular expressions and built-in Python functions.
- Text Tokenization: After cleaning the data, the text needs to be tokenized, which involves splitting the text into individual words or tokens. This can be done using Python's NLTK library or the built-in string. Split () function
- Stop Words Removal: Stop words are common words that do not carry much meaning in the text, such as "the", "and", and "a". Removing stop words can improve the accuracy of the machine learning model by reducing the noise in the data. This can be done using Python's NLTK library or other NLP libraries.
- Stemming/Lemmatization: Stemming and lemmatization are techniques used to reduce words to their root forms. This can be done using Python's NLTK library or other NLP libraries.
- Feature Extraction: After preprocessing the text, the next step is to extract features from the data. This can include features such as word frequency, sentiment analysis, lexical diversity, and topic modeling. This can be done using Python's scikit-learn library or other NLP libraries.
- Data Splitting: Finally, the pre-processed data needs to be split into training and testing sets for machine learning. This can be done using Python's scikit-learn library or other machine learning libraries
IV. MACHINE LEARNING ALGORITHMS
A. Logistic Regression
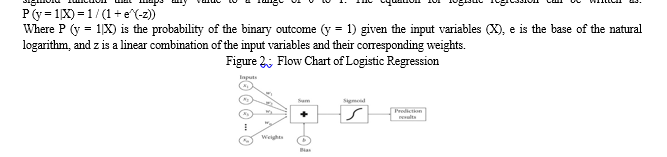
Logistic regression is a statistical algorithm used for binary classification problems, which involves predicting one of two possible outcomes. It is a supervised learning algorithm that is commonly used for predicting the probability of an event occurring, based on one or more input variables.
- Mathematical Analysis
The logistic regression algorithm uses a logistic function to model the probability of the binary outcome. The logistic function is a sigmoid function that maps any value to a range of 0 to 1. The equation for logistic regression can be written as:
2. Steps Included
a. Step1: Data preparation: Obtain a labelled data set with a binary dependent variable and one or more independent variables
b. Step2: Model formulation: Formulate a logistic regression model by specifying the relationship between the dependent variable and independent variables as a logistic function.
c. Step3: Parameter estimation: Estimate the parameters of the logistic regression model using maximum likelihood estimation.
d. Step4: Model evaluation: Evaluate the performance of the logistic regression model using metrics such as accuracy, precision, recall, and F1 score.
e. Step5: Model improvement: Refine the logistic regression model by adding or removing independent variables, transforming variables, or using a different model formulation to improve its performance
3. Merits
a. Logistic regression is a simple and interpretable algorithm, making it easy to understand and explain to non-technical stakeholders.
b. It is a powerful algorithm for binary classification problems, with high accuracy and good performance on large datasets
c. Logistic regression can handle both continuous and categorical input variables, making it versatile for a wide range of applications.
4. Demerits
a. Logistic regression assumes a linear relationship between the input variables and the output, which may not always be the case in real-world scenarios.
b. It is a parametric algorithm, which means it requires a specific functional form for the model, and may not work well on data that does not conform
c. Logistic regression may suffer from overfitting, especially when the number of input variables is large compared to the size of the training dataset.
B. Decision Tree
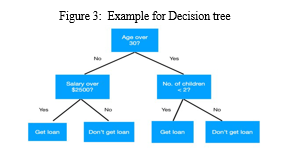
Decision tree is a popular machine learning algorithm used for classification and regression tasks. It is a supervised learning algorithm that creates a tree-like model of decisions and their possible consequences, allowing for predictions based on the input variables.
In the following example, we’ve to approve a loan on the basis of the age, salary, and no. of children the person has. We ask a conditional question at each node and make splits accordingly, till we reach a decision at the leaf node (i.e., get loan/don’t get loan).
- Mathematical Analysis
The decision tree algorithm works by recursively partitioning the data into subsets based on the values of the input variables, using a tree-like structure to represent the decision-making process.
At each node of the tree, a decision is made based on the values of one of the input variables, with each possible outcome leading to a new branch in the tree.
The algorithm continues to split the data into smaller and smaller subsets until a stopping criterion is met.
2. Steps Included
Step1: Data preparation: Obtain a labelled data set with a categorical or continuous dependent variable and one or more independent variables.
Step2: Tree formulation: Formulate a decision tree by recursively splitting the data into subsets based on the independent variables.
Step3: Split selection: Select the best split for each node by maximizing a split criterion, such as information gain or Gini index.
Step4: Model evaluation: Evaluate the performance of the decision tree by comparing the predictions to the actual values of the dependent variable
3. Merits
a. Decision trees are easy to interpret and explain, as the resulting tree structure can be visualized and easily understood by non-technical stakeholders.
b. Decision trees can handle both continuous and categorical input variables, making it versatile for a wide range of applications.
c. Decision trees are capable of capturing complex nonlinear relationships between the input variables and the output, making it a powerful algorithm for data with complex patterns.
4. Demerits
a. Decision trees can be prone to overfitting, especially when the number of input variables is large compared to the size of the training dataset.
b. Decision trees are sensitive to the choice of hyperparameters, which can significantly affect the performance of the model.
c. Decision trees are not robust to small changes in the data, as the resulting tree structure can be highly sensitive to the exact values and order of the input variables.
C. K-Nearest Neighbors
K-Nearest Neighbors (KNN) is a type of supervised learning algorithm used for both regression and classification.
KNN tries to predict the correct class for the test data by calculating the distance between the test data and all the training points. Then select the K number of points which is close to the test data.
The KNN algorithm calculates the probability of the test data belonging to the classes of ‘K’ training data and class holds the highest probability will be selected. In the case of regression, the value is the mean of the ‘K’ selected training points.
Suppose, we have an image of a creature that looks similar to cat and dog, but we want to know either it is a cat or dog. So, for this identification, we can use the KNN algorithm, as it works on a similarity measure.’
Our KNN model will find the similar features of the new data set to the cats and dogs’ images and based on the most similar features it will put it in either cat or dog category.

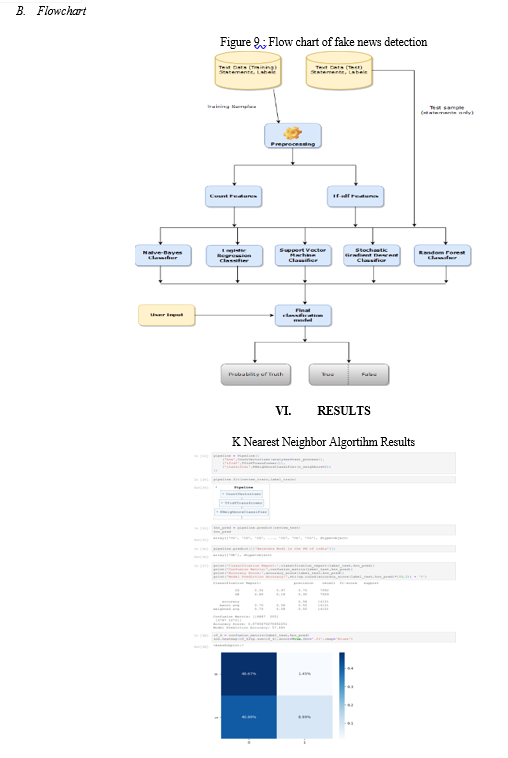
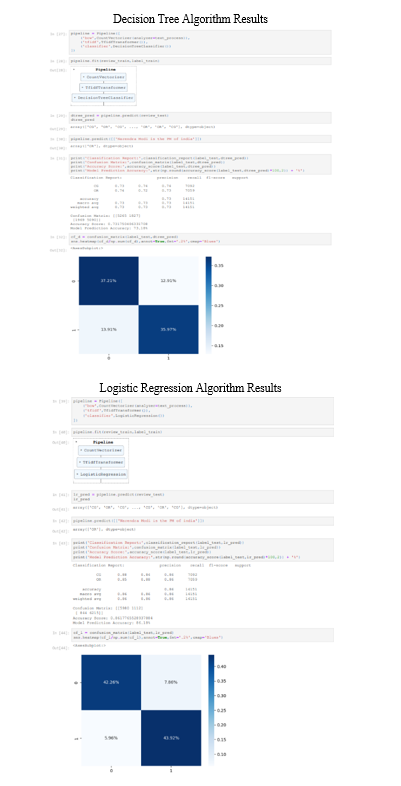

Conclusion
A. Conclusion 1) In conclusion, the use of machine learning for fake news detection has proven to be a promising approach in addressing the issue of misinformation. 2) Through the application of various techniques such as natural language processing, feature engineering, and classification algorithms, we are developing a model that can effectively distinguish between fake and real news articles. 3) Accuracy of the model can be improved with the use of more advanced algorithms and larger datasets; our results indicate that machine learning can play a valuable role in combating the spread of fake news. 4) It is important to continue refining and validating these models to help promote the dissemination of accurate information and combat the negative effects of misinformation on society. B. Future Scope Improving the accuracy of the model by using more advanced algorithms, such as deep learning techniques, to further enhance the ability to differentiate between fake and real news articles. 1) Expanding the scope of the project to include detection of more types of misinformation, such as propaganda, disinformation, and conspiracy theories. 2) Developing a real-time system that can analyze news articles as they are published to quickly identify and flag potentially fake news stories. 3) Integrating the fake news detection model with existing social media platforms to automatically flag potentially fake news stories, helping to prevent the spread of misinformation
References
Base Paper: Survey on fake news detection, International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 Published by, www.ijert.org ICACT – 2021 [1] Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu, “Fake News Detection on Social Media: A Data Mining Perspective” arXiv:1708.01967v3 [cs.SI], 3 Sep 2017 [2] Kai Shu, Amy Sliva, Suhang Wang, Jiliang Tang, and Huan Liu, “Fake News Detection on Social Media: A Data Mining Perspective” arXiv:1708.01967v3 [cs.SI], 3 Sep 2017 [3] M. Granik and V. Mesyura, \"Fake news detection using naive Bayes classifier,\" 2017 IEEE First Ukraine Conference on Electrical and Computer Engineering (UKRCON), Kiev, 2017, pp. 900-903. [4] Fake news websites. (n.d.) Wikipedia. [Online]. Available: https://en.wikipedia.org/wiki/Fake_news_website. Accessed Feb. 6, 2017 [5] Cade Metz. (2016, Dec. 16). The bittersweet sweepstakes to build an AI that destroys fake news
Copyright
Copyright © 2023 E.V. Nagalakshmi , E. Sai Vineeth, Y. Goutham, T. Vamshi Krishna . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET51637
Publish Date : 2023-05-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online