

Ijraset Journal For Research in Applied Science and Engineering Technology
Learning-Based Fake News Detector Using Multiple Features Using Machine Learning
Authors: C. Lakshmi Kara Gupta, D. Sumanth Reddy, K. A. Uday Kiran, A. Senthil Selvi
DOI Link: https://doi.org/10.22214/ijraset.2022.40920
Certificate: View Certificate
Abstract
Lately, the ascent of Online Interpersonal organizations has prompted a multiplication of social news like item ads, political news, big name data, and so forth. Some of the Social media platforms such as Facebook, Instagram, and Twitter are influenced by their customers through with fake news. Shockingly, a few clients utilize dishonest means to develop their connections and notoriety by getting out the counterfeit word as texts, pictures, and recordings. Notwithstanding, the new data showing up on an internet-based informal community is suspicious, and much of the time, it misdirects different clients in the organization. Counterfeit word is gotten out purposefully to delude peruses to trust bogus news, which makes it hard for recognition systems to identify counterfeit news dependent on the shared substance. The approach of the Internet and the quick acceptance of online media platforms ready for data spreading that has never been watched in human being history in the past. With the existing use of online social media platforms, customers are producing and distributing other data place than any further time in latest celebration, several of which are untrue with no importance to the actual planet. Robotized order of a text paper as dishonesty or misrepresentation is a tricky responsibility. Really, just as a specialist in a particular region requires to examine various angles prior to doing a judgment on the integrity of an editorial. In this design, we plan to use a machine learning collection style for the automatic category of news report papers. Our analysis examines individual produced properties that can be used to split fake matter from honest. By developing those things, we prepare a mix of several AI sums employing various grouping approaches and evaluate their showcase on 4 real world datasets. The practice evaluation acknowledges the unparalleled showcase of our planned ensemble undergraduate methodology in distinction with different scholars.
Introduction
I. INTRODUCTION
There has happened a rapid growth in the increase of fake news broadcast as of late, highly unquestionably found in the 2016 US selections. Such replication of communicating things available that don't adapt to real circumstances has provoked various problems restricted to judicial concerns only as including several territories, for order, sports, welfare, and learning. One such district touched by bogus news is the economic industry regions, where conversation can have catastrophic results and may break the marketplace.
Our ability to take a selection differs mostly on the type of information we burn up through, our viewpoint is shaped determined on the information we have. There is increasing proof that customers have responded amazingly to newsflash that later rolled up have being fake. One late situation is the place of the smart Coronavirus, where fake rumors continued over the Net about the begin, environment, and lead of the infection. The condition crushed as more citizens read about the fake stuff on the network. Realizing such news online is a shocking task.
Fortunately, a pair of computational procedures can be used to look at explicit articles as fake ward on their printed content. The greater part of these strategies use reality looking at targets, for case, "PolitiFact" and "Snopes". There are a team of gathers up with by specialists that have strategies of localities that are established as and fake. Whatever, the issue with these sources is that human being supremacy is likely to identify papers places as false. More considerably, the experience verifying sites include things from areas like governmental problems and are not tallied up to understand fake news stories from numerous areas like distraction, sports, and originality.
The Internet comprises data in various associations like accounts, documents, and good. News flowed online in a shapeless procedure is for the most bit problematic to see and the party as this decisively requires human capability. In some case, computational tactics, for instance, usual linguistic management (NLP) can be used to see discrepancies that various a text article that is deceitful from things that rely on real considerations. Different strategies combine the examination of triggering of fake news strangely, with genuine news. Substantially more unambiguously, the scheme analyzes how a fake article triggers unquestionably on an organization relative with an original article.
The reaction that an article gets can be removed at a notional level to organize the article as authentic or fake. A new blend technique can in like way be used to isolate the social concern of an editorial close by examining the text-based parts to calculate whether an editorial is perceptive.
A. Objective
The main aim is to find false news, which is a classic text classification problem with a simple fix. It is important to develop a model that can distinguish between "real" and "fake" news. The false news detection problem is stated as a credibility rating inference problem in Fake Detector, and the objective of Fake Detector is to explore a forecasting model for dynamically insinuating the credibility labels of news articles, creators, and subjects.
B. Problem Statement
Fake news, sometimes called as false information, have took over a big proportion of online today. The availability and rapid development of cybersecurity add to its dangers. Today, states, companies, and personalities have acquired attention through fake news in online for several reasons. To achieve desired result, sensational news is routinely produced and spread via social networks. On either side, it may also involve any retelling of an event that's been intentionally overstated. This might include labeling web pages with false titles or taglines in hopes of catching readers' attention. Such disinformation may result in penalties acts, public unrest, bank crimes based on such distortion, political benefit, expanding the number of visitors, getting rich associated with a clicking, etc. This may have had an impact here on significance of serious news. The worry is that other electronic media may use this as a source for their news, propagating it even farther. The issue is assessing the authenticity of the news and online content on web pages. Another key issue is recognizing the bots engaged in the spreading of false news.
C. Purpose
We recommended using current methodologies in combination with textual characteristics as a feature input to improve total accuracy for identifying if an article is correct or incorrect. Since more than one model is trained using a particular approach to reduce overall error and increase model performance, ensemble learners generally have higher or higher accuracies. The motivation behind gathering demonstrating is comparable to the one we are already used to in our daily lives, for example, mentioning the views of multiple experts before making a certain plan to cut the risk of a bad decision or a bad outcome.
A classification algorithm, for example, can be trained on a specific dataset with a unique set of parameters to generate a decision boundary that, to some extent, fits the data. The algorithm's output is determined not only by the parameters used it to train the model, but also by the type of training data used. If the training data is less uniform, the existing system may overfit and produce skewed results whenever used to unobserved data. To decrease the risk of overfitting, techniques such as cross-validation are applied. Several models can be trained on a different set of parameters to generate multiple decision boundaries on randomly selected training data.
II. LITERATURE SURVEY
|
Ref. No. |
PAPER TITLE |
AUTHOR, YEAR |
ALGORITHM
|
MERITS
|
DEMERITS
|
|
1 |
Machine Learning Algorithms for Fake News Detection are indeed being explored. Shlok Gilda proposed Machine Learning Algorithms for Fake News Detection based on a dataset from Signal Media and a list of sources from Open Sources.co. On a corpus of around 11,000 articles, use maximum - likelihood documents repetition (TF-IDF) of phrases and ’ll expect grammar (PCFG) recognition. |
S. Gilda, 2017.
|
Natural language processing
|
Simple Approach
|
Average Accuracy
|
|
2 |
The impact of online evaluations on businesses has expanded significantly in recent years, and they are now critical to determining business performance across a range of industries, from eateries to resorts to e-commerce. |
Barbado, araque & Igleias, 2019
|
Deep learning
|
Consistent performance
|
Complex Model
|
|
3. |
The Nave Bayes Classifier is being used to identify fake news. Fake News Detection Using a Naive Bayes Classifier was proposed by Mykhailo Granik and Volodymyr Mesyura. In this study, the Buzz News Dataset was utilised to train and validate the naive Bayes classifier. |
Mykhailo Granik, Volodymyr Mesyura (2017) |
Naïve Bayes Classifier |
|
|
|
4. |
Recognizing Fake News in Popular Twitter Requests Automatically Finding Fake Media in Popular Twitter Discussions Automatic. This specific range a dataset from Twitter using the CREDBANK crowdsourced dataset and the PHEME journalist annotated dataset. |
Threads.Cody Buntain, Jennifer Golbeck (2017) |
Machine learning
|
High Accuracy
|
Lack of other ML algorithms
|
A. Exiting System
Existing detection methods for these junks may be loosely divided into three types. The first group contains techniques that use content-based characteristics, including such word/language models and duplicated content analysis. The second tier of approaches, such as link-based believe propagation pruning of connections, rely heavily on graph connectivity information. For spam detection, the last set of techniques uses data such as click - stream usage patterns and HTTP existing older. The similarities between fake news and conventional spam have been highlighted, rendering existing spam sensing devices ineffective for identifying fake news articles.
B. Issues in the Existing System
- Problem Formulation: The subject of false news detection addressed in this paper is a new research problem, and a formal description and statement of the problem are required before investigating the problem.
- Textual Information Usage: A set of textual information regarding the contents, profiles, and descriptions of news stories, producers, and subjects may be gathered from online social media. Effective feature extraction and a learning model will be required to gather signals demonstrating their credibility.
C. Summary of Literature Survey
In comparison to other studies. From three positions, our change in mean from others in the field. First, we examine the many classifications of fake news in contemporary fake news studies, and the risks it presents to the public. We explain how fake news is related to phrases like deceptive news, false news, satirical news, disinformation, misinformation, cherry-picking, clickbait, and rumor. In contrast to similar polls and forums, which frequently give a particular definition for fake news, this survey highlights the difficulties in defining false propaganda and introduces both a narrow and a broad definition for it. Second, whereas earlier studies have highlighted the need of interdisciplinary fake news research, we give a pathway towards it by completing a thorough literature scan across diverse fields, result in the complete list of well-known concepts. We show how these ideas are related to false news and its spreaders, as well as practical techniques for recognizing and interfering with fake news. Third, previous surveys for false news detecting have largely confined their scope to examining studies from a certain perspective (or within a particular research field, including such NLP and data mining).
III. PROPOSED METHODOLOGY AND MODULES
A. System Architecture
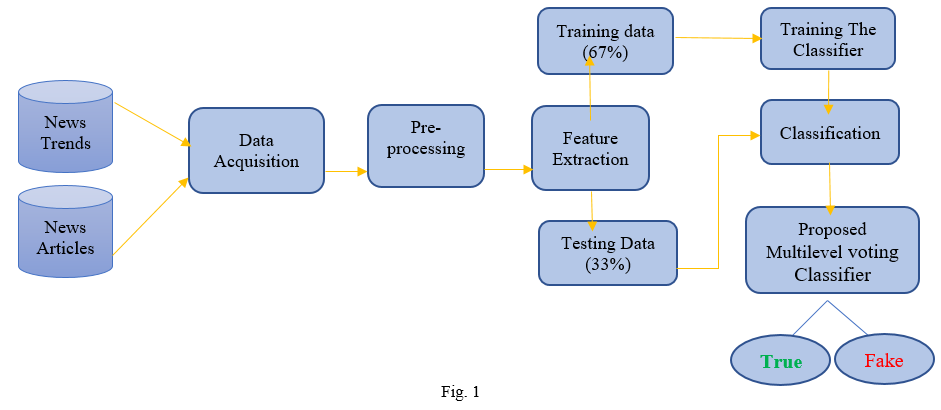
Figure 1 shows the suggested system architecture for detecting bogus news articles. To prepare the structure, two bodies were acquired from three separate suppliers by transferring datasets from News Trends and News article websites. Avoid words and copied content from news reports are removed at the pre-handling step. In the following stage, misplaced values, i.e., not available (NA) values, are gathered and cleaned. The saved data is then divided into two parts: training (0.67) and testing (0.33) sets. The element withdrawal stage is then performed to retrieve relevant elements from text-based information. The characteristics are taken from the articles at this step. Currently, web-based systems administration is for the most part used as the fountain of information because of its directness, ease to get to nature. Anyhow, consuming news from online life is a twofold-edged blade because of the inescapable of phony news, i.e., news with deliberately bogus information. Forgery news is a significant issue since it influences individuals similarly as society charitable. In the web-based life, the information is spread speedy and hence revelation part should more likely than not anticipate news sufficiently fast to stop the dispersal of phony news. Thus, recognizing counterfeit news using online systems management media is a basic and besides an indeed testing issue. In this paper, Group Casting a ballot Classifier based, a wise discovery framework is proposed to manage news order both genuine and phony undertakings. Here, eleven for the most part notable AI calculations like Gullible Bayes, K-NN, Strategic Relapse, and so forth are developed for finding. After cross-approval, we employed the best three AI calculations in Group Casting a ballot Classifier. The trial results attest that the proposed system can achieve around 94.5% results like exactness.
B. Architecture Diagram
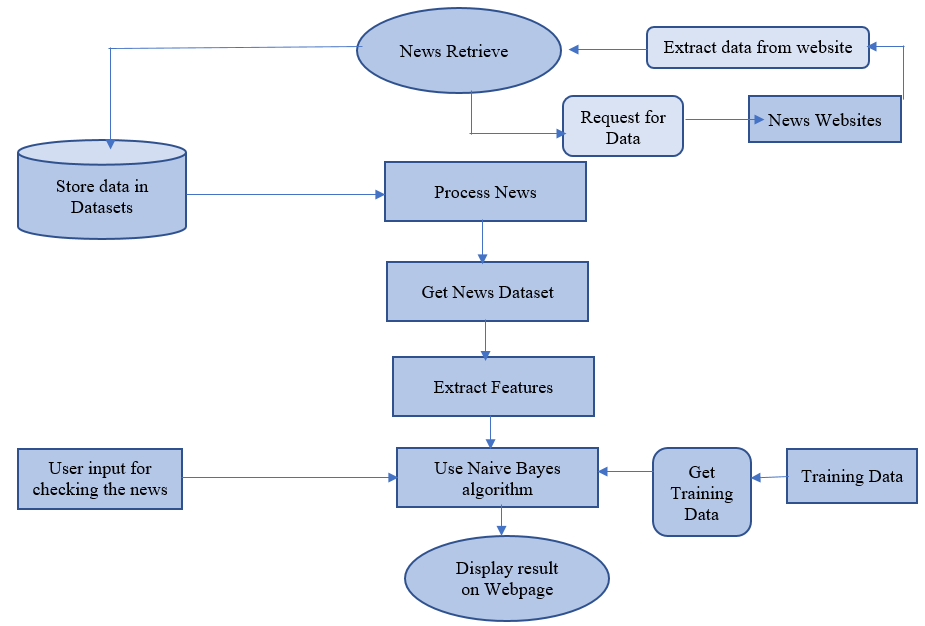
Firstly, we should collect the data from websites and requests for updated news to those websites, and then we need to retrieve the data and then store it in a database like an excel sheet. And then when we run the program first the news checking website will take the news heading from the stored database and then it will go to the processing stage and then it will collect the text for that news heading from the dataset. Then the news will get extracted and then we use the naïve Bayes algorithm for checking the news which we entered is real or fake to do that we need to train the datasets whether the news is real or fake and at last it will show the results in the webpage. Loke this we can know the given input is real or fake.
IV. MODULES AND ALGORITHMS
A. Module Description
These are some modules we have used in our project:
- Python: A module is a Python object with self-assertively named credits that you can tie and reference. Just, a module is an archive involving Python code. A module can characterize capacities, classes, and factors.
- Pandas: Panda is an wide open-resource library in Python. This one give prepared to-utilize superior execution information constructions and information investigation apparatuses. Pandas module runs on top of NumPy and it is famously utilized for information science and information investigation.
- Scikit-learn: Scikit-learn is a open AI store for Python. It features several computations like help trajectory machinery, random woods, and k-neighbors, and it similarly endorses Python geometric and plausible libraries like NumPy and SciPy.
- NLTK: NLTK stands for Natural Language Toolkit, and it is a suite of libraries and programs in Python for Natural Language Processing Tasks. It is one of the most usually developed NLP Python libraries. It can execute various NLP tasks like tokenization, stemming, POS tagging, lemmatization, and grouping to name a few.
B. Algorithm
This part goes with coaching the classifier. Different classifiers were discovered to predict the course of the book. We examined explicitly four distinctive AI calculations Multinomial Gullible Bayes Aloof Forceful Classifier and Strategic relapse. The applications of these classifiers have been performed utilizing the Python library Sci-Kit Learn.
- Naive Bayes Algorithm: It is a way of arranging indicators that is predicated on the Bayes Hypothesis and assumes their autonomy. In simple terms, an Innocent Bayes classifier assumes that the presence of one element in a class is independent of the concentration of that other. This classification strategy is based on the Bayes theorem, which states that the availability of one characteristic in a class is unrelated to the presence of any other feature. It allows you to estimate the posterior probability. Recurrence of a Term it determines how commonly a keyword comes in a report. Since document some in, a term may attract more attention in a document or file than in a shorter one.

2. Multinomial Naive Bayes Algorithm: Multinomial Credulous Bayes calculation is for the most part the Guileless Bayes calculation applied to multinomial circulation information. The multinomial dispersion implies that with every preliminary there can be k >= 2 results. This directed grouping calculation is reasonable for arranging discrete information like word counts of text.
Assume you have a message report, and you extricate every one of the one-of-a-kind words and make numerous elements where each element addresses the include of the word in the archive. In such a case, we have a recurrence as an element. In such a situation, we utilize multinomial Gullible Bayes. It overlooks the non-event of the highlights. Along these lines, assuming you have recurrence 0, the likelihood of event of that component will be 0 consequently multinomial innocent Bayes overlooks that element. It is known to function admirably with text characterization issues.
To see how Credulous Bayes functions, first, we need to comprehend the idea of Bayes' standard. This likelihood model was detailed by Thomas Bayes can be composed as:
Posterior Probability = Conditional Probability * Prior Probability / Predictor prior probability
P(A/B) = (P(A∩ B)/P(B)) = P(A)*P(B/A) / P(B)
where,
PA= the prior probability of occurring A
PBA= the condition probability of B given that A occurs
PAB= the condition probability of A given that B occurs
PB= the probability of occurring B
V. RESULT
A. When the given heading is Fake News
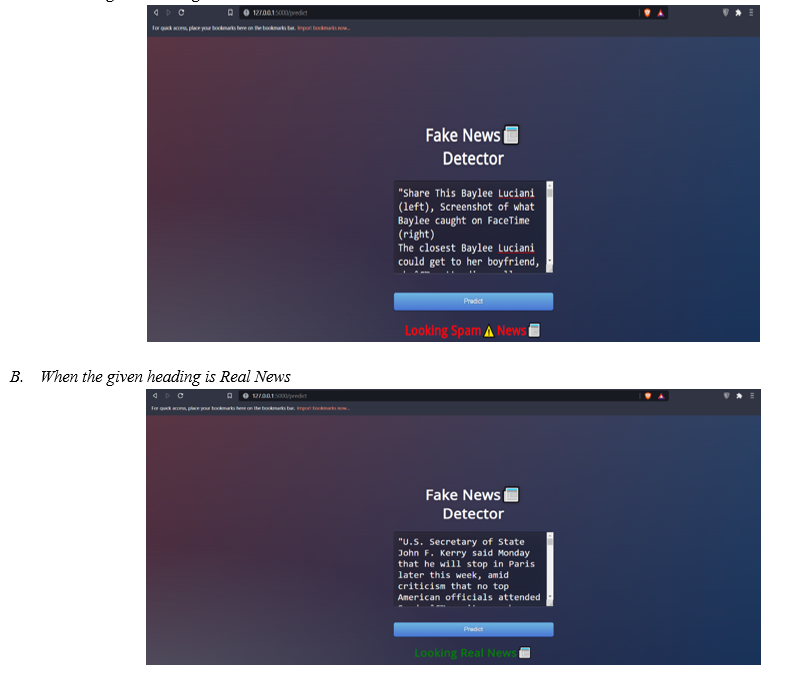
VI. FUTURE WORK
Later, we need to add the LIWC apparatus (Phonetic Request and Word Count). Semantic Application and Phrase Sum is a text investigation system that works out the level of words in each text that fall into at least one of more than 80 phonetic, mental, and effective classifications demonstrating different social, intellectual, and full of feeling processes.
Conclusion
Most tasks are completed online in the twenty-first century. Papers which were once famous as printed editions are now being ignored by applications such as Facebook, Twitter. The growing problem of fake news only complicates things and strives to influence or sway people\'s opinions and attitudes against the integration of digital technologies. When a person is fooled by disinformation, one of two things would happen: people begin to believe that their ideas on a particular topic are true as assumed. To address the phenomenon, we developed our Fake News Detection method, that accepts user input and classifies it as real or false. Various Machine Learning Techniques must be applied to do this. The model is expected to use a suitable dataset, and execution assessment is also carried out using several execution measures. To classify news headlines or pieces, the best one, i.e. the model with the best accuracy, is used.
References
[1] M. Granik and V. Mesyura, “Fake news detection using naive Bayes classifier,” 2017 IEEE 1st Ukr. Conf. Electr. Comput. Eng. UKRCON 2017 - Proc., pp. 900–903, 2017. [2] A. Martínez-Garcia, S. Morris, M. Scholl, F. Tracy, and P. Carmichael, “Case-based learning, pedagogical innovation, and semantic web technologies,” IEEE Trans. Learn. Technol., vol. 5, no. 2, pp. 104–116, 2012. [3] P. R. Humanante-Ramos, F. J. Garcia-Penalvo, and M. A. Conde-Gonzalez, “PLEs in Mobile Contexts: New Ways to Personalize Learning,” Rev. Iberoam. Tecnol. del Aprendiz., vol. 11, no. 4, pp. 220–226, 2016. [4] T. Granskogen and J. A. Gulla, “Fake news detection: Network data from social media used to predict fakes,” CEUR Workshop Proc., vol. 2041, no. 1, pp. 59–66, 2017. [5] R. V. L, C. Yimin, and C. N. J, “Deception detection for news: Three types of fakes,” Proc. Assoc. Inf. Sci. Technol., vol. 52, no. 1, pp. 1–4, 2016. [6] H. Gupta, M. S. Jamal, S. Madisetty and M. S. Desarkar, \"A framework for real-time spam detection in Twitter,\" 2018 10th International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, 2018, pp. 380-383. [7] M. L. Della Vedova, E. Tacchini, S. Moret, G. Ballarin, M. DiPierro, and L. de Alfaro, \"Automatic Online Fake News Detection Combining Content and Social Signals,\" 2018 22nd Conference of Open Innovations Association (FRUCT), Jyvaskyla, 2018, pp. 272-279. [8] C. Buntain and J. Golbeck, \"Automatically Identifying Fake News in Popular Twitter Threads,\" 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, 2017, pp. 208-215. [9] S. B. Parikh and P. K. Atrey, \"Media-Rich Fake News Detection: A Survey,\" 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, 2018, pp. 436-441 [10] Scikit-Learn- Machine Learning In Python. [11] Dataset- Fake News detection William Yang Wang. \" liar, liar pants on _re\": A new benchmark dataset for fake news detection. arXiv preprint arXiv:1705.00648, 2017.
Copyright
Copyright © 2022 C. Lakshmi Kara Gupta, D. Sumanth Reddy, K. A. Uday Kiran, A. Senthil Selvi. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET40920
Publish Date : 2022-03-22
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online