

Ijraset Journal For Research in Applied Science and Engineering Technology
Finding Advisors in Collaborative Environment with Fine-Grained Knowledge Sharing
Authors: Prof. N. M. Yawale, Mrunal Taware, Aarzoo Pathan, Shreyash Sonar, Vansh Sute
DOI Link: https://doi.org/10.22214/ijraset.2024.60338
Certificate: View Certificate
Abstract
As the digital world continues to expand, traditional search engines face difficulties in the ability to provide users with excellent and rapid information retrieval. Additionally, users have shown a low tolerance for retrieving irrelevant information and are increasingly expecting to be served with personalized information that meets their needs and preference. Personalized environments are of many advantages to applications such as e-commerce and research due to their need to provide the best possible results to the users as fast as possible. Personalized web environments that customize search results to specific users based on their behavior and preference while searching are becoming increasingly popular to solve this problem. Short-term and long-term user preferences are constructed from data on actions and top queries, visited content, and user preferences. Lots of websites already use this kind of personalized search, and it\'s making a big difference in how people use the internet.
Introduction
I. INTRODUCTION
In today's digital landscape, the internet stands as the foremost reservoir of information globally. It represents an expansive and continually expanding trove of data, characterized by its vastness and diversity. Despite its unstructured nature, this repository holds immense value, transforming the dynamics of information acquisition, sharing, and exchange.
Yet, the rapid proliferation of online content presents a significant challenge: navigating through this abundance of information. Tailoring searches to meet individual needs has become increasingly intricate for users, web service providers, and business analysts alike. Without a refined search strategy, individuals risk succumbing to information overload or encountering sluggish search experiences, compounded by difficulties in filtering and prioritizing relevant content.
The struggle to access pertinent, timely information amidst a deluge of extraneous data is a universal phenomenon. This deluge spans across multiple channels, including email, websites, and printed materials, posing hurdles to maintaining focus and productivity.
To confront these obstacles, the practice of knowledge sharing has emerged as a crucial remedy. Analogous to environmental recycling, the sharing and reuse of information serve to minimize redundancy, economize time, mitigate errors, and foster advancement. Within collaborative environments, tapping into the insights and experiences of others can streamline information retrieval processes, circumventing redundant efforts and optimizing efficiency. For example, if Alice encounters difficulty in locating a downloadable dictionary, consulting with someone like Bob, who has already accessed it, or reviewing Bob's search history can yield expedited and more fruitful outcomes, sparing individuals from fruitless searches.
II. LITERATURE REVIEW
Expert search is all about finding the right people who know their stuff in a particular field. In the beginning, we started by creating databases that described what skills people had. Then, in 2005, things really took off with the TREC enterprise track. That's when Balog and his team introduced a cool new way called Model 2 to figure out how relevant documents were to a topic and bring all the scores together. Since then, lots of methods have popped up, mostly focusing on gathering up scores from related documents. People have also looked into finding experts in online question answering groups and academic circles.
But here's where our advisor search comes in differently. First off, we're not just looking for any experts; we want ones with super detailed knowledge, which isn't usually what traditional expert searches focus on. And the info we're dealing with—sessions—isn't like the documents you'd find in a regular database. Sessions show how people learn stuff, with all kinds of hints about what they're into. So, if we just use regular expert search methods on session data, we might not get the best results. We need to pay attention to these hints and break down session data into smaller parts to find the right advisors. In our project, we've come up with some fancy ways to do just that, and it's way better than just tweaking old expert search methods for session data.
III. METHODOLOGY
This project introduces a personalized online search engine utilizing collaborative and content filtering techniques.
- Content Filtering: Content-based filtering algorithms use content, service, or feature similarities to offer personalized recommendations. By analyzing item attributes and user preferences, they suggest relevant content aligned with individual interests. Unlike collaborative filtering, this approach operates autonomously, making it ideal for suggesting specialized or personalized content, enhancing user engagement across various platforms.
- Collaborative Filtering: Collaborative filtering uses similar users' preferences to offer customized recommendations to individuals. By identifying shared tastes among users, it suggests items or content that match the specific user's preferences, enhancing recommendation accuracy across various contexts.
Upon receiving a user query, we analyze and refine the keywords based on the user's profile and preferences. Search results are fetched from Google through the Custom Search Google API. As users engage with the search results, the system tracks click-through data to identify their preferred keywords, which are then stored in a database. Leveraging these preferences, we identify users with similar profiles and preferences, known as "Advisors," and recommend them to the user on a query-by-query basis.
This dissertation presents a novel approach to foster knowledge sharing through user data analysis, with the primary goal of identifying suitable "advisors" based on their web browsing behavior.
The core focus of this dissertation revolves around finding advisors and relevant search results from the web using usage mining. Our objective is to enhance the delivery of search results by conducting thorough analyses of user-accessed data. The proposed method places significant emphasis on fine-grained knowledge sharing within collaborative environments. It entails summarizing web surfing data into detailed aspects to enable more precise and targeted searches. Furthermore, we incorporate privacy measures, allowing users to maintain anonymity when sharing their search queries with others. Through this approach, we aim to effectively guide users in their search endeavors while prioritizing their privacy and improving their search experience.
IV. WORKING
The aim is to refine the process of identifying individuals with specialized skills by considering not just their proficiency but also their internet browsing habits. This approach introduces a structured framework for pinpointing potential "advisors" who likely possess the necessary knowledge based on their online activities. It presents an advanced method for sharing knowledge within collaborative environments, with the goal of optimizing problem-solving and decision-making processes.
The process involves a thorough analysis of internet browsing data, examining the nuances of individual online behavior. This analysis is followed by conducting tailored searches designed to effectively address specific challenges. By leveraging these insights, organizations can more efficiently access the wealth of expertise within their networks. This, in turn, enhances their problem-solving capabilities and facilitates more informed decision-making.
This comprehensive approach not only takes into account traditional indicators of expertise but also integrates insights derived from individuals' online behaviors. By acknowledging the significance of both expertise and internet browsing patterns, organizations can cultiva
te a more dynamic and adaptable knowledge-sharing environment, leading to increased efficiency and innovation.
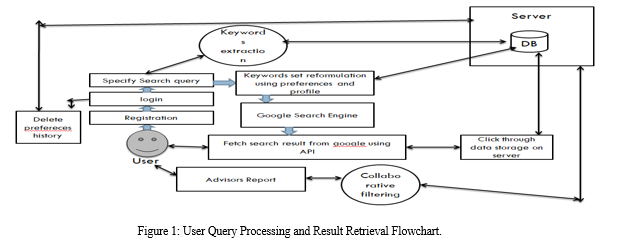
- Session 1 begins with the user providing their name and inputting a query into a search engine.
- As the search engine retrieves information, it concurrently constructs a database containing the user's name, entered query, and pertinent search links.
- In subsequent sessions, when another user starts session 2, their query is compared with those stored in our database.
- If there's a match, the stored data is recommended; otherwise, a new display is generated focusing on the required topic.
V. RESULTS AND DISCUSSION
Designed with a focus on optimizing search engine operations and ensuring user satisfaction. Each module is essential in improving the overall search experience by contributing to system efficiency and user-centric design. Let's delve into their specific roles and how they enhance the search engine's functionality and usability.
A. Administrator
Administrators are essential for the smooth operation and optimization of search engines. Their primary responsibility involves managing access to the backend system through authentication, ensuring security and accountability. Once logged in, administrators oversee critical settings, monitor system health, and perform maintenance tasks, with all actions logged for auditing purposes.
Understanding user behavior is key, facilitated by functions like "View Users" to analyze user profiles and activity logs. Decision Support System (DSS) Reporting provides data-driven insights for strategic planning, while reports like Most Visited Categories and Links aid in content optimization and user engagement.
Personalization is a focus, with features like Users’ Interests and Search Keywords optimizing search relevance and user satisfaction. Overall, administrators play a vital role in ensuring search engines meet user needs effectively.
B. End User Module
The End User Module caters to users' needs by facilitating registration, search, and preference management. Users can personalize their experience through preferences, view tailored search results, and modify settings as needed. The aim is to provide a seamless and personalized search experience.
C. Log Maintenance Module
Log Maintenance involves systematic practices for collecting, storing, and utilizing log data to track user behavior and aid in system maintenance. Efficient log management ensures integrity, security, and effective monitoring of system health and trends.
D. Mining Module
The Mining Module refines search results through data collection, analysis, and personalization, enhancing relevance and user satisfaction. By analyzing user behavior and predicting future patterns, search engines can better tailor results to individual preferences.
E. Content and Services Delivery Module
This module focuses on enhancing search results and user experience through data mining, content personalization, and delivery optimization. By delivering personalized and relevant content, search engines improve user satisfaction and loyalty.
F. Finding Advisors Module
The Finding Advisors module uses collaborative filtering and personalized search query reports to help users find suitable financial advisors. By analyzing user behavior and generating personalized reports, users can efficiently discover advisors tailored to their needs and preferences, facilitating informed decision-making.
VI. ACKNOWLEDGEMENTS
We would like to express our gratitude to the distributors and analysts for allowing us to use their resources. We would especially like to thank Prof. N. M. Yawale, our internal guide, for her steadfast support, advice, and important assistance throughout this project. Her insightful suggestions have greatly contributed to our work.
Conclusion
Nowadays, the practice of sharing detailed knowledge in supportive contexts is prevalent. We have identified that disclosing nuanced knowledge, which mirrors an individual’s interactions with the external environment, is the solution to this challenge. A dual-phase approach is employed to extract this detailed knowledge and integrate it with a sophisticated expert search mechanism to identify appropriate mentors. Examination of authentic web browsing data has yielded promising outcomes. There are open issues for this issue. The fine-grained knowledge could have a various leveled structure. For sample, \"Java IO\" can contain \"Document IO\" and \"System IO\" as sub-knowledge. To find out fine-grained knowledge we proposed content filtering and collaborative filtering approaches. In this system we are finding users preferences based on click through data and users’ profiles. When the user searches any query, the query will be modified based on users’ profile to improve the search result. Also, we will find out preferences if any for entered query. The search result will be given as per the preferences based on content filtering approach and another window will show the result based on collaborative filtering approach. So, we can conclude that the proposed system will be very useful for users to get appropriate result.
References
[1] K. Balog, L. Azzopardi, and M. de Rijke. Formal models for expert finding in enterprise corpora. In SIGIR, pages 43–50, 2006. [2] M. J. Beal, Z. Ghahramani, and C. E. Rasmussen. The infinite hidden markov model. In Advances in neural information processing systems, pages 577–584, 2001. [3] M. Belkin and P. Niyogi. Laplacian eigenmaps and spectral techniques for embedding and clustering. In NIPS, 2001. [4] D. Blei and M. Jordan. Variational inference for dirichlet process mixtures. Bayesian Analysis, 1(1):121–143, 2006. [5] D. M. Blei, T. L. Griffiths, M. I. Jordan, and J. B. Tenenbaum. Hierarchical topic models and the nested chinese restaurant process. In NIPS, 2003. [6] D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent dirichlet allocation. Journal of machine Learning research, 3:993–1022, 2003. [7] X. Liu, W. B. Croft, and M. Koll, “Finding experts in communitybased question-answering services,” in Proc. 14th ACM Int. Conf. Inf. Knowl. Manage., 2005, pp. 315–316 [8] D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent dirichlet allocation. Journal of machine Learning research, 3:993–1022, 2003. [9] P. R. Carlile. Working knowledge: how organizations manage what they know. Human Resource Planning, 21(4):58–60, 1998. [10] N. Craswell, A. P. de Vries, and I. Soboroff. Overview of the trec 2005 enterprise track. In TREC, 2005. [11] H. Deng, I. King, and M. R. Lyu. Formal models for expert finding on dblp bibliography data. In ICDM, pages 163–172, 2009. [12] Y. Fang, L. Si, and A. P. Mathur. Discriminative models of integrating document evidence and document-candidate associations for expert search. In SIGIR, pages 683–690, 2010. [13] T. S. Ferguson. A bayesian analysis of some nonparametric problems. The Annals of Statistics, 1(2):209–230, 1973. [14] A. K. Jain. Data clustering: 50 years beyond k-means. Pattern Recognition Letters, 31(8):651–666, 2010. [15] M. Ji, J. Yan, S. Gu, J. Han, X. He, W. Zhang, and Z. Chen. Learning search tasks in queries and web pages via graph regularization. In SIGIR, 2011.
Copyright
Copyright © 2024 Prof. N. M. Yawale, Mrunal Taware, Aarzoo Pathan, Shreyash Sonar, Vansh Sute. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60338
Publish Date : 2024-04-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online