

Ijraset Journal For Research in Applied Science and Engineering Technology
Food Recommendation System using One-Stage Algorithm
Authors: Ms. P. Jayalakshmi, Samuel Raj, Subbarayudu , Pavan Kumar
DOI Link: https://doi.org/10.22214/ijraset.2023.52023
Certificate: View Certificate
Abstract
There are a number of reasons why it\'s helpful when people suggest their favourite foods. There has been a rise in the use of automated systems that provide recommendations for various forms of food, including recipes, restaurants, and grocery stores. Scientists have been looking at these sorts of systems for a long time, and their findings show they may help individuals not just identify food they would want to eat, but also fuel themselves more properly. This article summarises the current status of so-called food recommender systems, focusing on both foundational and cutting-edge approaches to the issue, as well as essential specialisations such food recommendation systems for groups of users or systems that encourage healthy eating. Assisting consumers in finding their ideal meal is a crucial function of food recommender systems. Choosing what to eat is a complicated and multi-faceted process that is impacted by many things, including the ingredients, the look of the dish, the user\'s own preference on food, and many situations, such as what had been eaten at the previous meal. This paper formalises the meal suggestion issue as forecasting user preference on recipes using three essential factors: the user\'s (and other users\') history, the recipe\'s components, and the recipe\'s descriptive picture. In order to solve this difficult issue, we design a special neural network. The recommender creates a model of eating habits based on responses to previous surveys. The model is then used to prompt respondents, based on the meals they have previously picked, to submit any linked items they may have forgotten to mention. Model-generated cues were evaluated against those that were manually programmed by dietitians.
Introduction
I. INTRODUCTION
Identifying and merging different types of setting and area data into the individual model and examining the exceptional properties of foods are two of the primary challenges impacting food recommendation, and the challenge that must be overcome before a unified framework can be proposed. Any food item included in the training set should be easily identifiable by the best classifier. The overall correctness of digital photographs may be affected by a wide range of factors, such as rotation distortion colour distribution lighting circumstances, and so on. Training is a time-consuming procedure that must be repeated several times before the desired results can be achieved. There is a strong correlation between the number and quality of training pictures utilised and the performance of the resulting classifier.
According to the World Health Organisation, noncommunicable illnesses counting cardiovascular infection, malignant growth, constant respiratory sickness, and diabetes account for a staggering percentage of global mortality. It also highlights the fact that such illnesses are avoidable via programmes that target common risk factors including poor dietary habits. Whereas a cookie-cutter approach may not work here, Consumers are more likely to stick to a healthy, pleasurable, and nutritional diet when the diet is tailored to their specific needs, preferences, lifestyle, and budget based on factors such as their health status, phenotype, and genotype. Patients, whether they be healthy or suffering from conditions like cancer, diabetes, or food allergies, may all benefit from personalised nutrition. Food has significant social, cultural, and religious importance since it is an integral component of everyone's daily life. However, it might be difficult to settle on a meal choice. The sheer volume of options may be too much for them to handle. The most basic need of every population is food. Because food is so central to daily life, food recommender systems have quickly become an integral part of many lifestyle services and are frequently held up as a possible method of influencing people towards a healthier way of living.
The maintenance of one's physical health depends on eating a well-balanced diet. However, dietary requirements might vary widely from one individual to the next and from one health condition to another. It is, thus, crucial to learn how to tailor dietary suggestions to individual needs. The last ten years have seen explosive development in mobile technology and online services. With the advent of online communities, virtual entertainment, and recipe sharing sites, as well as client survey locales, consumers have easier access to vast volumes of multimedia online material related to food.
While this expansion is great for consumers, it also creates difficulties when trying to narrow down the hundreds of potential options to just one. Since meal recommendations may help consumers quickly zero in on a manageable list of satisfying food options, they are becoming more important in meeting the potentially massive service demand that may arise. The term "personalised nutrition" refers to the practise of providing individualised recommendations for healthy eating based on an individual's genetic information, as well as other factors such as their current state of health, lifestyle, nutritional consumption, and phenotypic characteristics. In recent years, there has been a rise in research efforts dedicated to the management of these alternative data in an attempt to reduce the price tag associated with managing genetic data. In this context, numerous computational methods aimed at promoting healthy diets have been developed.
Any framework that produces customized ideas as result or coordinates the client in a customized way to fascinating or supportive things with regards to a wide scope of accessible conceivable outcomes is considered a recommender framework (RS). Since they have developed as a successful answer for tackle the data over-burdening issue, they are being utilized in a wide assortment of settings, from web based business and e-figuring out how to e-government and e-the travel industry. Recommender systems (RSs) are computer programmes designed to help people choose the most relevant and helpful products and services available among a wide variety of possibilities. They've recently come to the fore as a useful tool for assisting users with decision making. Recommendations often pertain to basic low-risk decision-making processes, such as purchasing a product, listening to music, or watching a movie; however, these systems may also be used to settle on more modern high-risk decisions to do things like maintain a healthy lifestyle, save money, and maximise available time.
Maintaining a healthy weight and treating and controlling food-related diseases like obesity and diabetes both benefit from careful monitoring of daily dietary consumption. Until recently, this was done by poring through manually kept daily records. A more thorough daily monitoring of one's diet is now possible with the use of user-friendly technological aids that assist users in keeping track of their food intake. Using computer vision methods, it is possible to create automated systems for finding and identifying various meals, as well as for estimating how much food there is. If you want to know how many calories are in the food on your plate, for instance, all you have to do is snap a photo of it with your phone and run it through a visual understanding framework.
A fully convolutional one-stage method (FCOS) is an object identification model that predicts the bouncing boxes and class names of items in a picture utilizing a fully convolutional architecture and a single-stage detection pipeline. Traditionally, object detection models have used a two-stage pipeline where object proposals are generated in the principal stage and afterward refined in the subsequent stage. However, FCOS eliminates the need for a proposal generation step by predicting the class and location of objects directly from the input image. The FCOS algorithm works by dividing the picture into a matrix of fixed-size cells and predicting the class and location of objects within each cell. Specifically, for each cell, FCOS predicts the classification scores for all possible object classes and the offset from the cell's nucleus outward to its boundary. To achieve this, FCOS uses a fully convolutional architecture that comprises of a spine network followed by an element pyramid organization (FPN) and a recognition head. The spine network separates include from the information picture, while the FPN produces a bunch of element maps at various scales. The identification head then, at that point, processes these element guides to create the last object predictions. FCOS has several advantages over traditional object detection models, including better speed and accuracy. Since it eliminates the need for a proposal generation step, FCOS is able to detect objects in real-time with high accuracy. Additionally, because it is fully convolutional, FCOS is able to process images of arbitrary sizes, making it more flexible and scalable.
A food recommendation system using a Fully Convolutional One-Stage algorithm can be used to give customized food proposals to clients in view of their inclinations, dietary limitations, and other factors. The Fully Convolutional One-Stage algorithm is a profound learning model that is ordinarily utilized for object detection and segmentation in computer vision tasks. In the case of food recommendation, the algorithm can be trained on a large dataset of food images and associated metadata such as ingredient lists, nutritional information, and user ratings.
To recommend foods, the algorithm takes in a user's input such as their preferred cuisine, dietary restrictions, and taste preferences. The algorithm then uses this input to generate a bunch of competitor food things that match the client's criteria. The algorithm then uses its trained model to score each candidate food item based on how closely it matches the client's inclinations and dietary limitations. The consequence of the computation is a bunch of suggested food things that the client is probably going to appreciate in view of their preferences and dietary restrictions. The recommendations can be further refined by incorporating additional user feedback and behavior data to improve the accuracy of the recommendations over time. Overall, a food recommendation system using a Fully Convolutional One-Stage algorithm has the potential to provide personalized and accurate food recommendations to users, helping them discover new foods that they will enjoy while also promoting healthy eating habits.
II. LITERATURE SURVEY
- Antonio Corradi, Paolo Bellavista, and Isam Mashhour Al Jawarneh Juan Manuel Murillo, Javier Berrocal, Luca Foschini, Rebecca Montanari, and Luca Foschini.
The Internet is increasingly being relied upon as the primary information resource for all facets of human existence. In today's information-saturated environment, people turn to their social networks and internet resources for advice on how to spend their time, where to go, and what to eat. The abundance of options accessible online leads to data glut and makes decision-making more difficult. The majority of existing recommender systems rely on a static model that does not take the context of the user's actions into account throughout iterative interactions. We argue that the next generation of suggestion frameworks ought to have the option to involve setting in novel and proficient ways, which may lead to more reliable rating forecasts statistically. Despite its importance, however, using context information in Deep Learning (DL)-based recommendations has received very little attention from the academic community. One major contributing factor is that most existing DL algorithms are not conceived from the outset to add context oriented labels. In this paper, we contribute essentially to shutting this hole by fostering a mixture calculation that adjusts and reuses a pre-separating context oriented fuse technique and feeds the new aspect to a DL-based brain cooperative sifting approach, consequently holding and recuperating the upsides of the two methodologies while keeping away from their disadvantages. Quantitative discoveries outperforming the baselines overwhelmingly are also reported in the study.
2. Jaewoo Kang, Kana Maruyama, Mogan Gim, Michael Spranger, and Spranger's wife Mogan Gim.
There are an infinite number of possible permutations of a given dish, making it difficult to predict which complementary ingredients would work best. We offer recipe bowl, a cooking proposal framework that takes as information a rundown of fixings and a bunch of cooking labels and outputs a list of recipes that could use those items. To train recipe bowl, we create a dataset in which the model predicts an objective fixing that has been removed from the original recipe, and we use this dataset to devise a recipe completion task. The Bowl uses a set encoder and a two-way decoder to make predictions about recipes. To build significant set portrayals, we utilize the Set Transformer in the set encoder. By and large, technique makes a set portrayal of a pass on one-out recipe and guides it to the fixing and recipe implanting space. The progress of our technique has been displayed in tests. Also, new disclosures connecting with culinary aptitude rise up out of investigations of model forecasts and translations. As a set-based culinary recommender for expected fixings and feasts, we give recipe bowl. We utilize the Set Changed structure to encode parts into a set setting portrayal and train the model in a directed learning recipe finishing circumstance in view of an extended dataset from Receptor. For the formed recipe culmination issue, our model outperformed both state-of-the-art ML methods and baselines based on set encoding variation. The recommendation results show that for any given combination of ingredients, recipe bowl may come up with a wide variety of credible suggestions. We clustered the vector embeddings in a meaningful way based on their expected position in the Embedding Space. We looked at the consideration loads that were removed from the Set Encoder and found that they were helpful to our models' performance, and we also looked at visualisations of the set setting vectors that are the immediate results from the Set Encoder. In conclusion, our established set representation methodologies and created recipe completion job were effective in recommending components and recipes. While the recipe bowl provided viable recipe options for a given set of components, several of these candidates were contradictory with the specified ingredients and so needed further improvement.
3. Giovanni Semeraro, Cataldo Musto, Federica Cena, and Amon Rapp.
Recommender systems (RSs) are computer programmes that make suggestions for, or direct the user towards, items that could be of interest or use to them. In recent years, RSs have been widely used as a reliable decision-making aid. People's preferences, long-term objectives, context, and present circumstance are only few of the factors that influence the choices individuals make. RSs often overlook this subtlety. The ability of an RS to effectively aid in decision-making hinges on its ability to be holistic, or based on a comprehensive portrayal of the client, which incorporates encoding heterogeneous client highlights (like individual interests, mental qualities, wellbeing information, and social associations) that might start from various information sources. Be that as it may, there are procedures that must be followed to receive such comprehensive suggestions: First, we need to zero in on the reason for making this choice; next, we may apply good judgment and subject ability to give the client the best recommendations possible. In this piece, we lay forth a theoretical foundation for this kind of comprehensive RS, which may guide researchers and developers as they create it. We back up the claims made about the framework by detailing how it was used to create and assess a comprehensive food RS.
This article introduces the idea of holistic recommendation, which is a collection of recommendations based on a user's profile that integrates information from a wide assortment of sources to make a total picture of that individual. Then, we provided a methodological framework to help designers create more comprehensive recommendation systems. Finally, we demonstrated how the framework may be used to the creation of a holistically based food recommender, therefore validating it. We propose to test the meal recommender described in Section VI with actual users in the future to evaluate the reliability of the holistic suggestions. Here, we talk about some of the most pressing new problems that this strategy raises. Maintaining confidentiality. The interaction between one's way of life, one's buying habits, and one's personal information makes holistic suggestion a particularly challenging addition to the test of registering protection saving models [42].
4. Ali Kashif Bashir, Fazal Noor, Fazal Iwendi, and Joseph Henry Anajemba.
Strong diets, as endorsed by a dietician or a falsely canny mechanized clinical eating regimen based cloud framework, have been demonstrated to enhance health, extend life expectancy, and decrease the risk of developing further diseases. However, doctors and nurses haven't completely grasped the recommender system's appeal to patients and dietitians. This study provides a profound learning answer for a therapeutically based wellbeing dataset, one that can naturally determine the appropriate diet for a particular patient given their specific diagnosis as well as demographic information such as age, gender, weight, height, illness, and dietary restrictions. Calculated relapse, credulous bayes, Repetitive Brain Organization (RNN), Multi-facet Perceptron (MLP), Gated Intermittent Units (GRU), and Long Momentary Memory (LSTM) are only a portion of the AI and profound learning calculations that this study framework is designed to support. Thirty individuals' records, representing 13 illness characteristics and a thousand items, make up the medical dataset amassed through the web and clinics. 8 attributes are characterized in the item segment. To apply significant and machine and learning-based shows to this IoMT information, their attributes were first inspected and encoded. We looked at the consequences of various AI and profound learning techniques, and the LSTM strategy was demonstrated to be the best concerning exactness of forecast, review, accuracy, and $F1$-measures. Utilizing the LSTM profound learning model, we had the option to get 97.74% precision. For the allowed class, we get an accuracy of 98%, review of close to 100%, and F1-proportion of $99%F1$, while for the denied class, we get an accuracy of 89%, review of 73%, and F1-proportion of $80%. Solid weight control plans, for example, those recommended by a Dietician or a Blood vessel A shrewd cloud-based robotized clinical eating regimen may extend life expectancy, prevent illness, and enhance health. However, doctors and nurses still don't completely grasp the reasoning behind the recommender system used by patient-nutritionists. It's been said that the most ideal way to foresee what's in store is to check the past out. A similar 0.2 - 0.05 sloping testing curve is used. The training curve is shown in blue, while the test curve is shown in green. The blue curve represents the training phase and it begins at 93% after the first 50 epochs.
5. Nawaz brothers: Zubair Nawaz, Muhammad Kamran Malik, Sidra Nawaz, and Safia Kanwal.
A wide range of textual material, including news, research papers, eBooks, personal blogs, and user reviews, is being generated by a large number of websites online. These websites often include a great deal of textual material, making it difficult for users to locate specific information. Text-based RSs are now being development as a means of fixing this problem. They are computers programmed to quickly and efficiently sift through large amounts of text for the information they need. There are a number of methods available for creating and assessing such structures. Although several studies have compiled the broad characteristics of rs, there is currently a dearth of in-depth literature reviews on text-based rs. This publication provides a comprehensive analysis of recent research into text-based RS.
To complete this study, we collected works published between 2010 and 2020 from the world's most prestigious online libraries. The four most important features of the examined text-based recommendation systems are the focus of this study. These include data sets, feature extraction methods, computational strategies, and metrics for measuring performance. Publicly accessible datasets are thoroughly explored in this work since benchmark datasets play an important part in any research. Many private datasets are also utilised for text-based RS that are not accessible to the general public.
To make it easier for new researchers to get acquainted with these qualities, we have centralised all the properties of both publicly accessible and private datasets. In addition, the techniques of feature extraction from text are briefly introduced, and their use in the development of text-based RS is reviewed. A variety of computational methods that make advantage of these characteristics are then explored. Some measures are established to assess these systems. We have summarised these criteria for assessment and organised them in a Venn diagram according to their level of favourability.
The results of the poll indicate that Word Embedding is the most popular method of feature selection currently being employed. The poll also concludes that suggestion accuracy is improved by combining text characteristics with additional factors.
The research underlines the fact that the majority of effort is done on English textual data, and that the most common area of application is news recommendation.
6. Krishnaveni Chilka2, Sakshi Channe3, Mamata Gandhe4, Ms. Pradnya Mehta5, Tanmai Muke1,.
The food recommendation algorithm in this study is diet-based. Here, we've implemented a system to make it easier for the user to find and purchase nutritious food. Since the COVID-19 pandemic, there has been a heightened global awareness of the need of maintaining a healthy immune system. In order to determine what ingredients are needed, this framework has utilized AI calculations and techniques. K-implies grouping, the Irregular Woods Order calculation, and rank-based cooperative sifting are the methods used by this system. The system's primary function is to advise the user on what to eat in order to sustain and improve his or her health. It's an effort to make eating out a more wholesome option for people. The full title of the work in progress is "Disorder-based Food Recommendation System." Immunity and health are crucial in the aftermath of the global Covid19 epidemic. This method aims to provide individuals with healthy food selections to help them stick to that diet. The user may join the service after registering. After deciding on a dining establishment, the user will be invited to provide their personal health information, including their level and weight to compute their Weight Record (BMI),as well as data about any additional conditions they may have, such as high blood pressure or diabetes. Based on their specific dietary needs, the restaurant will serve them the dishes they have selected. This is a restaurant review website, so you know it has to be good, right? It's common knowledge that machine learning algorithms are put to use all around the world for forecasting and advising. The algorithms provide output by recognising patterns and trends in the supplied data. The user's future actions may then be predicted using these findings.
7. Trung-Hieu Tran; Quang-Nhat Le; Quang-Hop Do; Gia-Huy Lam; Quang-Linh Tran;.
Mobile devices allow consumers to take pictures of the food they eat for use in meal recommendation systems. Images of food will be analysed to determine what kind it is, then sent into a recommendation engine that will utilise the data to make suggestions based on the users' expected preferences. Therefore, the ability to recognise food images is crucial to the success of the meal suggestion system. As many meals share similar colour and texture, this used to be a challenging subject in computer vision. With the advent of AI and, more specifically, deep learning methods, it is now much simpler to code a system to identify what kind of food is shown in a picture. This research compares the efficacy of multiple methods for food picture identification, including classical machine learning and cutting-edge deep learning approaches. To this goal, a new Vietnamese food image dataset including 12,017 images of 15 meals was developed for use in conducting algorithmic evaluations. Features in food pictures have been extracted using both classic machine learning methods like Histogram of Inclination (Hoard) and Scale-Invariant Component Change (Filter) and state of the art profound learning models like VGG16, Versatile Net, ANN, Resnet18, Resnet50, and Densenet121. The gathered attributes have been put to use in order through Calculated Relapse (SF) and SoftMax (SM). The findings of this paper's comparisons give a solid foundation upon which to choose suitable picture recognition methods with which to construct an effective meal recommendation system.
8. M Malathi; S Sarujith; Samyuktha Menon.
Restaurants are the go-to for most celebrations these days. It's no secret that the number of restaurants and online meal ordering platforms continues to grow as word of mouth spreads. If you want to save consumers time they might spend browsing through a list of restaurants and food products, provide a suggestion system instead. Recommending restaurants and food products based on user ratings demonstrates the quality of that item at that restaurant and boosts the dependability of this recommendation system for new users since the ratings are provided by public users.
9. Mehrdad Rostami.
Deep Learning and Graph Clustering, a New Approach to Time-Aware Food Recommendation. It is widely accepted that food recommender-systems might be useful in encouraging consumers to adopt healthy eating behaviours. The purpose of this work is to create another mixture food recommender-framework to address the impediments of existing ones, like neglecting to consider food parts, time contemplations, cold beginning clients, cold beginning food items, and local area considerations. Food content-based recommendation is the first step in the proposed strategy, followed by user-based recommendation.
In the first stage, clients and food things are bunched utilizing chart grouping, and in the subsequent stage, clients and food things are grouped utilizing a profound learning based strategy.
Likewise, an all-encompassing strategy is utilized to upgrade the idea quality by thinking about time and client local area related hardships. Utilizing five separate execution rules (Accuracy, Review, F1, AUC, and NDCG), we looked at our model against a gathering of best in class recommender-frameworks. The created food recommender-system outperformed the competition in experiments utilising data taken from.
10. Food Recommendation System.
One tactic for dealing with the deluge of data being generated online is to categorise and organise it. We can't stress enough how crucial recommender systems are, what with how they're used in so many online apps and how they solve so many issues that arise from having too many options. The growing reliance on IT is a result of its widespread use across all areas of business. One of the fastest-growing sectors of the economy, the hospitality and food service sector has made significant contributions to national prosperity in recent decades.
Existing methods of recommending restaurants don't take into account the user's present perspective or provide a tailored experience. The suggested system tailors its suggestions for food and dining establishments to each individual user, taking into account factors including the latter's taste preferences and budget. Zomato's data is used to find eateries close to the user. For Manu Gupta; Sriniha Mourila; Sreehasa Kotte; K. Bhuvana Chandra, we created a website in which they would be asked to provide some basic personal information.
You can tell a lot about a person by how they respond to a situation by observing their body language. The software suggests stuff to eat and places to eat based on the user's inputs. The user is presented with a number of alternatives, each of which is accompanied with a rating of the respective restaurant. The top three restaurants on the list are the ones we think the consumer will like the most, with the other six serving as solid backups. PyCharm is used to create this model in which the restaurants are partitioned geographically using the KNN technique. Websites written with Flask tend to be intuitive and easy to navigate. Customers who aren't sure what to eat based on their current emotional state may use this app to get some suggestions.
III. EXISTING SYSTEM
Users can change their eating habits and adopt a healthy diet with the aid of food recommender systems, which are thought to be an effective tool. The goal of this study is to foster a clever half breed dinner suggestion framework to tackle the deficiencies of current frameworks, for example, their failure to account for social context, new users, and food products, as well as the time component in preparing meals. Two steps make up the proposed method: user-generated culinary content suggestions and recommendations. In the first step, we utilise graph clustering to categorise persons and foods, and then we offer a deep learning method to the user. Graph clustering is used in the first stage to group people together, and then a deep learning method is used in the second stage to group foods together.
In addition, the quality of the user's suggestion is improved by using a holistic approach that takes into thought time limitations and client local area concerns.. Clients can change their dietary patterns and embrace a sound eating routine with the aid of food recommender systems, which are thought to be an effective tool. This exploration plans to foster an original mixture dinner proposal framework to settle the weaknesses of current frameworks, for example, their failure to account for contextual elements, new users, new food products, and the time factor in food preparation. The suggested technique consists of two stages: (1) user suggestion, and (2) food content-based recommendation. In the first stage, graph clustering is used to classify individuals and foods, and the user is then recommended a deep learning strategy.
Using two different performance criteria, Precision Recall F AUC and NDCG, we compared our model to a group of cutting-edge recommender systems. Allrecipes.com data was used in experiments to show how well the built food recommender framework worked.
The expansion of the Web and the expansion in the quantity of individuals who use it has prompted the far and wide utilization of recommender frameworks that pick things that are fairly applicable to clients' requirements. Food suggestion frameworks, which are fundamental parts of numerous way of life administrations , are used in a number of lifestyle applications.
Users can change with the aid of food recommender systems, which are thought to be an effective tool.
The goal of this research is to foster an original half and half dinner suggestion framework to settle the inadequacies of current frameworks, for example, their failure to account for contextual elements, new users, new food products, and the time factor in food preparation. The suggested technique consists of two phases: user suggestion and recommendation based on food composition.
In the first stage, graph clustering is used to classify individuals and food items, and the user is then recommended a deep learning strategy.
In this examination, a one of a kind half and half food recommender framework is worked to fix the issues of existing frameworks, for example, their inability to consider food parts, time stamps, cold beginning clients, cold beginning dinners, and client networks.
The proposed strategy adopts an all-encompassing strategy, intending to work on the recommender framework's precision by including client and content-based models, as well as time data trust organizations and client networks. The proposed approach considers both client input and healthful information while making proposals. Grouping in light of diagrams is utilized in each of the three phases:
M. Rostami, et all’s. imaginative time-mindful food suggestion framework. The subsequent stage utilizes a diagram bunching and profound learning based strategy to order the two people and food things into unmistakable gatherings. The model has been looked at against the most recent proposed food recommender framework, which integrates LDA HAFR and FGCN procedures, alongside a couple of others, utilizing two separate measurements:
Accuracy Review F AUC and NDCG. As per the aftereffects of the tests, the made food recommender framework performed better compared to the cutting edge food recommender frameworks. We anticipate upgrading the structure with more client data (counting orientation, age, weight, level, area, and culture) to work on the general execution of the feast idea.
The intensity of symptoms caused by non-infectious illnesses may also be reduced by following a healthy dietary pattern. The nutritional qualities of each item will be used as supporting evidence in future recommendations depending on individual health and illness conditions.
Disadvantages Of The Existing System:
- There is a deficiency of knowledge on which contextual factors are most relevant and how to appropriately account for them in an algorithm.
- Complexity of its real time implementation.
- Metrix are typically poorer than in other domine.
- Cannot be implemented real time.
- More model parameters and higher model complexity.
- High level of communication and computation overheads.
- Suffers from the scarcity of data.
IV. PROPOSED ARCHITECTURE
In this architecture, the user interacts with a User Interface to input their food preferences. The Recommendation API then receives this input and queries the Recipe Database to retrieve a list of recipes that match the user's preferences.
The Ingredient Embedding Model and User Preference Embedding Model use machine learning techniques to generate a vector representation of each ingredient and user preference, respectively. These vectors are then used to calculate the similarity between ingredients and user preferences in the Ingredient Similarity Service and User Preference Similarity Service, respectively.
The Recommendation API then combines the similarity scores for ingredients and user preferences to generate a final set of recommendations, which are returned to the User Interface for display to the user. This architecture can be extended and optimized with additional layers of machine learning models, data processing pipelines, and services to further enhance the recommendation accuracy and user experience.
A System Requirements Specification (SRS) (also known as a Software Requirements Specification) is a documentor set of documentation that describes the features and behavior of a system or software application. Depending on the methodology employed (agile vs waterfall) the level of formality and detail in the SRS will vary, but in general an SRS should include a description of the functional requirements, system requirements, technical requirements, constraints, assumptions and acceptance criteria.
A. Architecture Diagram
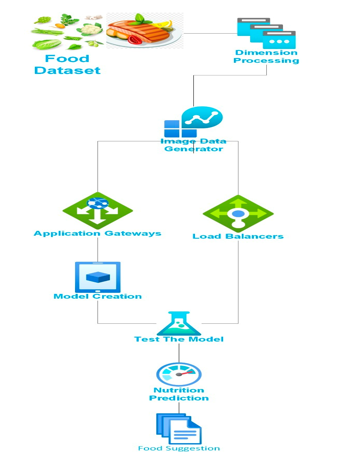
B. Algorithm
- Fully Convolutional One-Stage Algorithm
C. Advantages of Proposed Algorithm
- Fully Convolutional One-Stage Algorithm Advantages learn from events and make decisions through commenting on similar events.
- Even if a neuron is not responding or a piece of information is missing, the network can detect the fault and still produce the output.
- Can infer unseen relationships on unseen data as well, thus making the model generalize and predict on unseen data
D. Modules
- Image Processing
When applied to a grayscale picture, thresholding seeks to binarize it according to pixel density. Thresholding is a straightforward method for performing a segmentation operation between an image's foreground and background. The output is set by an intensity threshold parameter. If the pixel's value was higher or lower than the threshold, it would be changed to white or black, respectively. In Morphology, a picture is analysed with the use of a little guide called a structuring element. Each pixel in the picture is compared to a reference, such as a kernel, to determine where it should be placed. These procedures work well when applied to binary pictures. In order to carry out morphological procedures, a kernel must be supplied, which in turn affects the final product. Erosion, dilation, opening, and shutting are the four morphological techniques investigated in this work.
High-frequency information, such noise, is cancelled out by blurring the picture. In this work, we compare the average filter, the Gaussian filter, and the median filter as blurring tools. The average filter modifies the picture's core element by averaging pixels within a given kernel region before convolving the resultant image. The Gaussian filter uses a Gaussian kernel to accomplish blurring. In other words, it can filter out Gaussian noise.
Image processing can be used in a food recommendation system to extract features from food images, which can then be used as input to recommend similar dishes or ingredientshe User Interface component provides an image recognition system that extracts features from food images. The Feature Extraction component utilizes a pre-prepared Convolutional Brain Organization (CNN) to remove significant elements from food images. The Feature Encoding component then reduces the dimensionality of these features and encodes them in a more manageable format. The Recommendation Engine component utilizes collaborative filtering or similar techniques to recommend similar dishes or ingredients based on the encoded features. The Data Storage and Management component manages and stores data related to the food images and recommendations, while external systems can be connected to the food recommendation system through APIs and data sources. Note that this is a simplified architecture and many other components and techniques can be added to work on the precision and effectiveness of the food recommendation system.
2. Train Validation Test
Train and Validation Split All three datasets are further divided into Test Training and Validation data. Test Data is a small chunk of data obtained randomly from the dataset which occupies .% of each dataset. Training Data is the % of the remaining data used for training the models. Validation Data is the % of the remaining data used for validating the classifier. The classifiers used this validation data to avoid overfitting and improve model performance. In a food recommendation system using a fully convolutional algorithm, it is important to split the data into training, validation, and test sets to evaluate the performance of the model. Here is a general process for splitting the data into these sets: preparation: The first step is to gather the data, which in this case would consist of food images and their corresponding labels. The data should be cleaned, and any necessary preprocessing (such as resizing or cropping the images) should be done. Split the data: The data should be split into training, validation, and test sets. A common split is 70% for training, 15% for validation, and 15% for testing, although this can vary depending on the size of the dataset. Data augmentation: Data augmentation techniques (such as rotation, flipping, or zooming the images) can be applied to the training set to increase the variability of the data and improve the performance of the model. Train the model: The model is trained on the training set using a fully convolutional algorithm. The model should be evaluated on the validation set during training to monitor its performance and prevent overfitting. Tune hyperparameters: Hyperparameters (such as learning rate, batch size, or number of epochs) can be adjusted based on the performance of the model on the validation set. Evaluate the model: Once the model has been trained and the hyperparameters have been tuned, it should be evaluated on the test set to obtain an unbiased estimate of its performance. Fine-tune the model (optional): If the performance of the model is not satisfactory, it can be fine-tuned using additional techniques (such as transfer learning or ensemble methods) to improve its accuracy. Overall, splitting the data into training, validation, and test sets allows us to evaluate the performance of the fully convolutional algorithm on new and unseen data, and ensures that the model is not overfitting to the training set.
3. Model Creation and Food Recognition
Embedding-based models associate each user and item with an embedding (i.e. a real-valued vector) which has become the mainstream to model user-item interactions in recommendation. Note that we can also view an embedding layer as a look-up operation which retrieves an embedding from the parameter matrix of the embedding layer. AUC Area Under the Roc Curve (AUC) measures the probability that a classifier will rank a randomly chosen positive instance higher than a randomly chosen negative one. Recall Recall is the probability that positive items are ranked in top-k item recommendation. In food recommendation systems, food recognition is a crucial task that involves identifying the type of food in an image. Here is an overview of the process for creating a model for food recognition:
E. Data Collection
The first step in creating a model for food recognition is to gather a large dataset of food images. This dataset should include a diverse set of food types, lighting conditions, angles, and backgrounds to ensure that the model can accurately recognize different types of food in a variety of situations. Data preprocessing: Once the data is collected, it should be preprocessed to remove any irrelevant information and to standardize the size, format, and color of the images.
This preprocessing step is critical to ensure that the model can accurately identify food in new and unseen images. Model architecture: Next, a suitable model architecture should be selected. In food recognition, popular models include Convolutional Neural Networks (CNNs), which are designed to handle image data and have been shown to be effective at recognizing food images. Model training: The selected model should be trained using the preprocessed data. During training, the model learns to identify food images by adjusting the weights of its layers. It is important to use appropriate optimization algorithms and hyperparameters during training to ensure that the model is learning effectively.
F. Evaluation
After training, the model should be evaluated using a separate test dataset to assess its accuracy and ability to recognize food in new images. Various evaluation metrics, such as accuracy, precision, and recall, can be used to evaluate the performance of the model. Fine-tuning: If the model does not perform well, it can be fine-tuned by adjusting the hyperparameters, changing the model architecture, or incorporating additional data or training techniques. Overall, creating a model for food recognition involves collecting and preprocessing data, selecting an appropriate model architecture, training the model, evaluating its performance, and fine-tuning the model as needed to
G. Evaluation Metrics
- Unit Testing
Individual software units or components are tested as part of the level of software testing known as UNIT TESTING. The goal is to confirm that each piece of software operates as intended. The smallest testable component of any software is called a unit. It typically has one or more inputs and one output. An individual programme, function, process, etc. can all be considered units in procedural programming. The smallest unit in object-oriented programming is a method, which can be a part of a base/super class, abstract class, or derived/child class. (Some treat an application module as a unit. This should be avoided because that module presumably contains a lot of different units.) Frameworks for unit testing, drivers, stubs, and mock/fake code In order to help with unit testing, objects are used.
2. Integration Testing
INTEGRATION TESTING is a level of software testing where individual units are combined and tested as a group. The purpose of this level of testing is to expose faults in the interaction between integrated units. Test drivers and test stubs are used to assist in Integration Testing. Integration testing: Testing performed to expose defects in the interfaces and in the interactions between integrated components or systems. See also component integration testing, system integration testing. Integration tests determine if independently developed units of software work correctly when they are connected to each other. The term has become blurred even by the diffuse standards of the software industry, so I've been wary of using it in my writing. In particular, many people assume integration tests are Objects are employed to help in units that are unnecessarily large in reach when a lesser scope would suffice. It's best to begin with some background information, as is typical with these things. In the 1980s, when I first learned about integration testing, the waterfall model of software development predominated. In a larger project, the interface and behaviour of the various system components would be specified during the design phase. Developers would then be given modules to programme. Although it wasn't unusual for one programmer to be in charge of a single module, this one would be so large that building it might take many months. This task was completed separately, and the programmer would deliver it to QA for testing once they thought it was complete.
3. Sanity Testing
When QAs don't have enough time to execute all the test cases—whether they're for functional, user interface, operating system, or browser testing—they perform sanity testing. Regression testing has a subcategory known as sanity testing. Sanity testing is done after obtaining the software build to make sure the introduced code changes are functioning as anticipated. This testing serves as a checkpoint to see if the build's testing can move forward or not. The main goal of this testing is to ascertain whether the modifications or the suggested functionality function as intended. To save time and money, the testing team rejects the build if the sanity test is unsuccessful. The build is only put to use after passing the smoke test and becoming accepted for additional testing by the quality assurance team. The team's primary goal throughout this testing procedure is to confirm the application's functionality, not to perform in-depth testing.
To determine whether the build we received from the development team is testable or not, smoke testing is carried out.
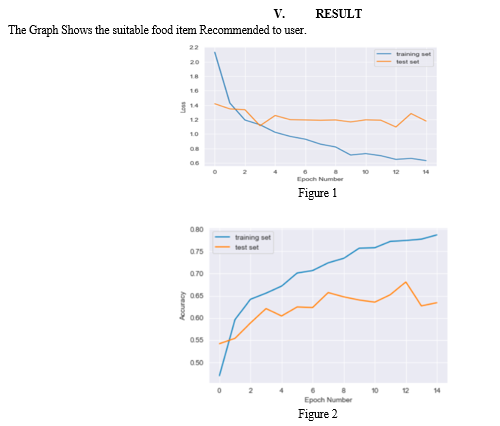
Conclusion
A. Conclusion Given how crucial food recommendations are to people\'s quality of life and the potential benefits they could have for human health, they represent an important and promising research area. It gives users access to graded food products built on a dynamic personal model built from food photos and heterogeneous food analysis to comprehend attributes. food quality and flavour B. Future Work Evaluation of food recommenders and the techniques used to do so are another area that needs to improve in the community. The majority of literature review has been done offline with private collections. We must work together as a community to establish uniform data gathering procedures, baseline methodologies, and, most importantly, additional online research to comprehend how our procedures function as real systems used in realistic situations.
References
[1] Anand Shanker Tewari ; Abhay Kumar ; Asim Gopal Barman, \"Book recommendation system based on combine features of content based filtering, collaborative filtering and association rule mining\",2014 IEEE International Advance Computing Conference (IACC),Year: 2014,Page s: 500 – 503. [2] JunBo Xia, \"E-Commerce Product Recommendation Method Based on Collaborative Filtering Technology\", 2016 International Conference on Smart Grid and Electrical Automation (ICSGEA), 11-12 Aug, 2016. [3] Yi-Jing Wu ; Wei-Guang Teng, \"An enhanced recommendation scheme for online grocery shopping\", 2011 IEEE 15th International Symposium on Consumer Electronics (ISCE),Year:2011, Pages: 410 – 415. [4] Priyanka A. Nandagawali ; Jaikumar M. Patil, \"Community based recommendation system based on products\", 2014 International Conference on Power, Automation and Communication (INPAC), 6-8 Oct, 2014. [5] S. Linko, “Expert systems what can they do for the food industry?” Trends Food Sci. Technol., vol. 9, no. 1, pp. 3–12, 1998. [6] A.McAfee, E. Brynjolfsson, T. H. Davenport, D. Patil, and D.Barton, “Big data,” Manage. Revolution Harvard Bus. Rev., vol. 90, no. 10, pp. 61–67,20. [7] H. Arem and E. Loftfield, “Cancer Epidemiology: A Survey of Modifiable Risk Factors for Prevention and Survivorship,” American Journal of Lifestyle Medicine, vol. 12, no. 3, p. 200–210, 2018. [8] M. S. Donaldson, “Nutrition and cancer,” Nutrition Journal, vol. 3, pp. 19–25, 2004. [9] M. Jovanovik, A. Bogojeska and D. e. a. Trajanov, “Inferring Cuisine — Drug Interactions Using the Linked Data Approach,” Scientific Reports, vol. 5, no. 9346, 2015. [10] K. Veselkov, G. Gonzalez, S. Aljifri, D. Galea, R. Mirnezami, J. Youssef, M. Bronstein and I. Laponogov, “HyperFoods: Machine intelligent mapping of cancer-beating molecules in foods,” Scientific Reports, vol. 3, no. 9237, 2019. [11] C. Anderson, “A survey of food recommenders,” ArXiv, vol. abs/1809.02862, 2018. [12] J. R. Aunan, W. C. Cho and K. Søreide, “The Biology of Aging and Cancer: A Brief Overview of Shared and Divergent Molecular Hallmarks,” Aging and disease, vol. 8, no. 5, p. 628–642, 2017. [13] T. Mikolov, K. Chen, G. Corrado and J. Dean, “Efficient Estimation of Word Representations in Vector Space,” Proceedings of the International Conference on Learning Representations, 2013. [14] M. Chary, S. Parikh, A. F. Manini, E. W. Boyer and M. Radeos, “A Review of Natural Language Processing in Medical Education,” The Western Journal of Emergency Medicine, vol. 20, no. 1, 2019. [15] T. Mikolov, K. Chen, G. Corrado and J. Dean, “Efficient Estimation of Word Representations in Vector Space,” Proceedings of the International Conference on Learning Representations, 2013. [16] A. Salvador, M. Drozdzal, X. Giro-i-Nieto and A. Romero, “Inverse Cooking: Recipe Generation from Food Images,” Computer Vision and Pattern Recognition, 2018. [17] A. Salvador, N. Hynes, Y. Aytar, J. Marin, F. Ofli, I. Weber and A. Torralba, “Learning cross-modal embeddings for cooking recipes and food images,” Computer Vision and Pattern Recognition, 2017. [18] I. T. Jolliffe and J. Cadima, “Principal component analysis: a review and recent developments,” Philosophical Transactions of The Royal Society A Mathematical Physical and Engineering Sciences, vol. 374, no. 2065, 2016. [19] L. v. d. Maaten and G. Hinton, “Visualizing Data using t-SNE,” Journal of Machine Learning Research, vol. 9, pp. 2579–2605, 2008. [20] V. D. Blondel, J.-L. Guillaume, R. Lambiotte and E. Lefebvre, “Fast unfolding of communities in large networks,” J. Stat. Mech., 2008.
Copyright
Copyright © 2023 Ms. P. Jayalakshmi, Samuel Raj, Subbarayudu , Pavan Kumar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET52023
Publish Date : 2023-05-11
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online