

Ijraset Journal For Research in Applied Science and Engineering Technology
Forecasting Sales for Super Store Data
Authors: Samarla Shivani, Sadiq Ahmed, Dr. T. Ramaswamy
DOI Link: https://doi.org/10.22214/ijraset.2023.48556
Certificate: View Certificate
Abstract
In moment’s ultramodern world, large shopping promenades and commerce calculate on data about the deals of particulars and products and their colourful dependent or independent factors as a crucial step in Prognosticating unborn demand and force operation. Deals are so important to your business that soothsaying deals helps you plan your unborn opinions. Deals soothsaying isn’t accurate enough, it’s a time- consuming process and is mathematically created using being formulas that can only be answered through statistics. Linear retrogression is a machine learning algorithm Grounded on supervised literacy. Retrogression models are intended for predictors grounded on independent variables. It is primarily used to find relationships between variables and predictions. ARIMA stands for Bus Regression Integrated Moving Average. It is one of the simplest and most effective machine learning algorithms for time series forecasting. It’s a combination of autoregression and emotional normalcy.
Introduction
I. INTRODUCTION
The project can be further collaborated in web-based applications and any device with Internet of Things (IoT) with built-in intelligence for ease of use.
Different stakeholders involved in the sales information can also provide more input to help generate hypotheses, allowing more cases to be considered to produce more realistic and more accurate results.
Most organizations need forecasting. The reason for such a prediction is that the customer needs sufficient lead time for product delivery and does not want to wait too long. Clearly, an organization must anticipate what future demand will look like and have sufficient inventory levels to reduce the time it takes to get products to customers. This project uses time series analysis based on time stamped data.
II. LITERATURE REVIEW MATERIALS AND METHODOLOGY
A. Existing System
Sales forecasting is done mathematically using existing formulas that are not accurate enough, are time-consuming processes, and can only be solved by statistics. In the current system, they assume current sales based on industrial trends and the status of the current sales pipeline, but they are unable to predict future sales. The amount of data available is growing all the time, and such a large volume of unprocessed data must be thoroughly analysed in order to produce highly relevant and finely pure gradient findings that meet current standards. As with the evolution of Artificial Intelligence, it is not incorrect to say that Machine Learning (ML), like Artificial Intelligence (AI) over the last two decades, has advanced at a rapid rate. ML is a major pillar of the IT industry, and with it, a fairly central, albeit often overlooked role.
B. Proposed System
As of January 2019, data gathering, superstore’s data scientists collected sales data of 9800 different orders throughout their stores. It can be inferred from all of the data what role certain qualities of an item play and how they affect sales.
- Raw Data
During the January 2019 data collection, superstore data scientists collected sales data from 9800 different orders in the store.
2. Data Cleaning
Preprocessing of this dataset includes performing an analysis of the independent variables. B. Check for null values in each column and replace or fill with relevant supported data types to make analysis and model fitting as smooth as possible.
3. Algorithm
A machine learning algorithm grounded on supervised literacy is direct retrogression. Run a retrogression task. Grounded on retrogression models, the target predictor. Independent variables. Chancing connections between variables and prognostications is its main operation. Retrogression models vary in the nature of the relationship between dependent and. The volume of independent variables used, as well as independent variables. Autoregressive Integrated Moving Average, or simply ARIMA, stands for. It belongs to the group. The most straightforward machine learning algorithms to use. Soothsaying for time series. Moving average and autoregressive analysis are combined in this. He uses SARIMA, also known as Seasonal ARIMA, or Seasonal Autoregressive Integrated Moving Average. A unequivocal support for univariate time series data with a in ARIMA extension.
C. Related Studies
Pre-processing of this dataset includes performing an analysis of the independent variables. B. Check for null values in each column and replace or fill with relevant supported data types to make analysis and model fitting as smooth as possible.
The plot above was created using the pandas tool and reports the counts of the variables in the numeric columns and the values in the categorical columns. For numeric columns, the maximum and minimum median values and their percentile values play a decisive role. Algorithms used Scikit-Learn can be used to fully monitor machine learning systems.
- Estimate Sales for this Data set using the Following Algorithm
Linear Regression Algorithm Regression can be described as a parametric technique used to predict a continuous or dependent variable based on a supplied set of independent variables. This technique is called parametric because different assumptions are made based on the dataset.
Y = βo + β1X +
The equations shown are used for simple linear regression. These parameters can be expressed as: Y
Variable to Predict X - The variable used to make the prediction is the 1 unit change in X and indicates the change in Y. Also called the gradient term. become ε - the difference between the predicted value and the actual value is represented by this parameter and also represents the residual value
No matter how efficiently a model is trained, tested, and validated, there will always be a difference between the actual and predicted values, and this is an irreducible error, so the learning algorithm's prediction results are flawless. cannot be relied upon.
2. Random Forest Algorithm
Random Forest Algorithm is a highly accurate sales forecasting algorithm. Easy to use and understand when it comes to predicting the outcome of machine learning activities. Random forest classifiers are used for sales forecasting because they have consumer markets like decision trees.
A tree model is similar to a decision-making tool. The Random Forest Regression class from the sklearn enable library is used to perform the Random Forest Predictive Regression challenge. Parameters and estimators, also called random forest regression, play a decisive role here. A random forest is a meta-estimator that uses a data set function to fit multiple decision trees (depending on the classification).
III. MODELING AND ANALYSIS
Multi-store and multi-product forecasting was implemented to forecast sales volume for each product and each store over a 7-day period using data provided by. The aim of this work was therefore to reduce the amount of waste and increase product availability by improving predictive models.
This paper uses ARIMA and SARIMA (Seasonal ARIMA). This is an open-source machine learning framework. The data comes from Kaggle and contains 1600 unique sales names for orders as Big Mart sales. Use AUC (area under the curve) to calculate efficiency.
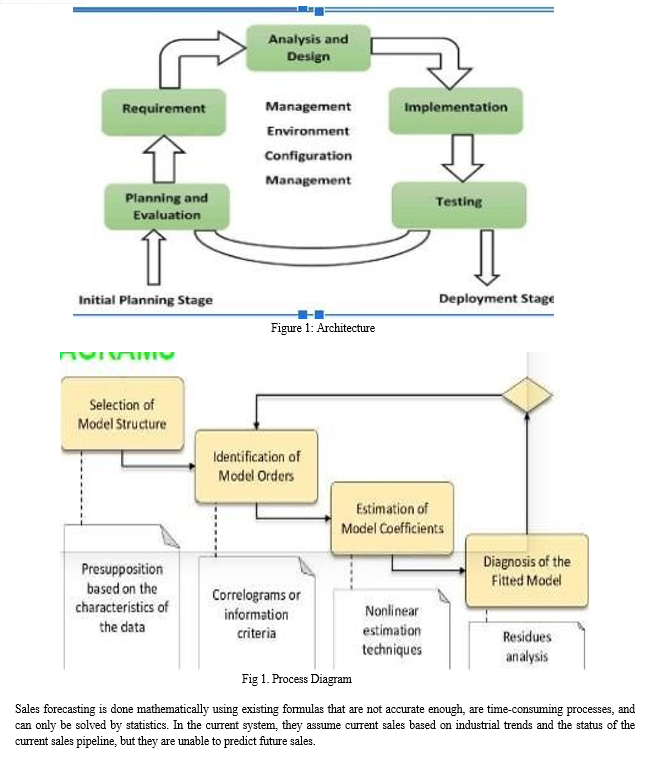
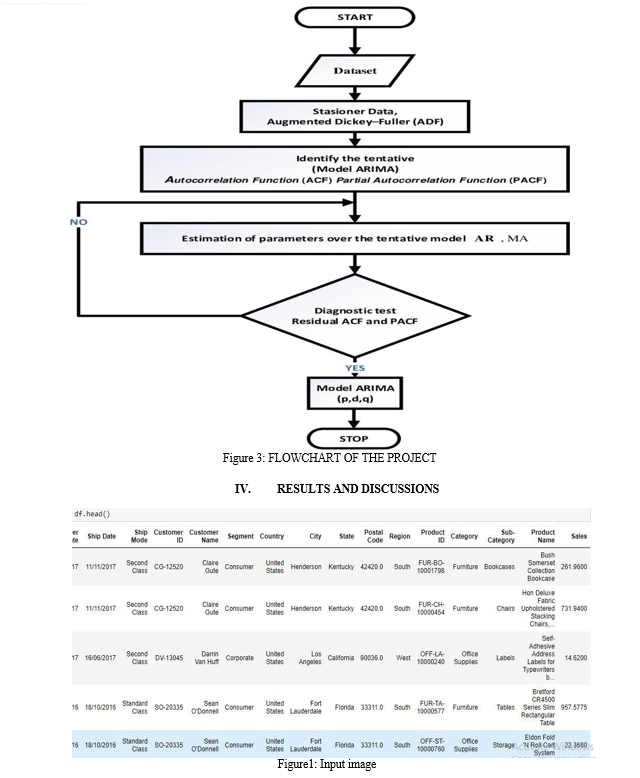
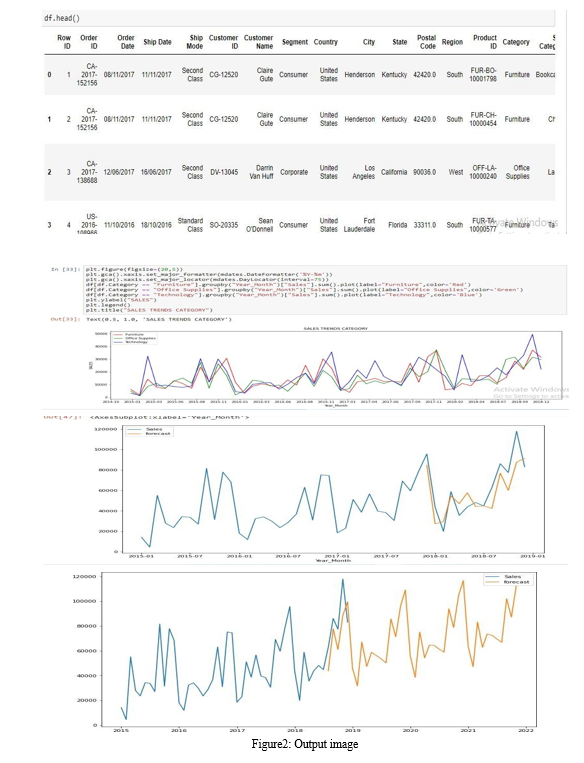
Conclusion
Trades predicting is an important part of the strategic planning process because it allows a company to read how it’ll perform in the future. It enables them not only to plan for new openings, but also to avoid negative trends that appear in the prediction. A charge statement is important because it explains why an association exists and serves as a companion for opinions. Both generalizations are critical to the company’s success and shouldn’t be overlooked during the strategic planning process. This design will help associations enrich their trades operation conditioning, including predicting of profit and shadowing of performance against objects. Deals directors can freely explore their crew’s performance and channel, from high- position crews down to the individual sale position, to quick spot and respond to outliers and concerns. These results in a more predictable and effective deals process at the crew, original, and commercial situations- allowing users to see the whole story that lives within their data. This paper offers gives the logical capabilities that unleash the power of information for Deals Operation. Deals predicting is an important part of the strategic planning process because it allows a company to call how it’ll perform in the future. It enables them not only to plan for new openings, but also to avoid negative trends that appear in the cast. The models we trained and estimated can be used for any dataset.
References
[1] Smola. A, & Vishwanathan,S.V.N.( 2008). Preface to machine literacy. Cambridge University, UK, 32, 34. [2] Saltz,J.S. , & Stanton,J.M.( 2017). A preface to data wisdom. Savant Publications. [3] Shashua,A.( 2009). Preface to machine literacy Class notes 67577. arXiv preprint arXiv0904.3664. [4] MacKay,D.J., & Mac Kay,D.J.( 2003). Information proposition, conclusion and literacy algorithms. Cambridge university press. [5] Daumé III, H. (2012). A course in machine literacy. Publisher, ciml. Word, 5, 69. [6] Quinlan,J.R.( 2014). C4. 5 programs for machine literacy. Elsevier. [7] Cerrada,M., & Aguilar,J.( 2008). Underpinning literacy in system identification. In underpinning literacy. IntechOpen. [8] Welling,M.( 2011). A first hassle with Machine literacy. Irvine, CA. University of California.
Copyright
Copyright © 2023 Samarla Shivani, Sadiq Ahmed, Dr. T. Ramaswamy. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET48556
Publish Date : 2023-01-06
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online