

Ijraset Journal For Research in Applied Science and Engineering Technology
Fruit Verity-Detecting Adulteration in fruits Using Machine Learning.
Authors: K. Bharath, J. Harini, K. Vijay, U. Venkata Krishna, KVL. Sahiti, G. Mahesh, Dr. N. Rama Rao
DOI Link: https://doi.org/10.22214/ijraset.2023.57469
Certificate: View Certificate
Abstract
Detecting fruit adulteration is a critical challenge with traditional methods often falling short due to their time-consuming nature and high costs. Chemical tests, while common, have limitations that hinder their efficiency. Fortunately, a beacon of hope emerges in the realm of machine learning, offering a promising alternative for identifying adulteration in fruits. By leveraging the power of data, machine learning algorithms can be finely tuned to recognize intricate patterns that act as red flags for adulteration. These data sources span from detailed laboratory tests to the nuances revealed through sensory analysis and even extend to the analysis of fruit images. Once a machine learning model undergoes meticulous training on this diverse array of datasets, it transforms into a potent tool for swift and precise adulteration detection. This breakthrough not only strengthens food safety measures but also accelerates the identification of compromised products, ultimately safeguarding public health. Consumers are empowered with a robust defense against the persistent problem of adulteration. The revolutionary nature of this approach brings about a paradigm shift, offering a proactive solution that outpaces traditional methods. Incorporating machine learning into fruit quality control not only addresses the shortcomings of current techniques but also enhances the overall efficiency of the process. The ability to discern subtle signs of adulteration through diverse data inputs marks a significant leap forward in ensuring the integrity of the food supply chain. As technology continues to advance, the integration of machine learning in food safety measures is poised to become a cornerstone in protecting consumers and maintaining the quality and authenticity of our food products.
Introduction
I. INTRODUCTION
Fruits are essential for healthy life. The fruits we take should be pure, nutritious and free from any type of adulteration for proper maintenance of human health. The intake of any fruit substance is intended for the nourishment which is gained from it.
Maintaining a healthy lifestyle hinges on consuming pure, nutritious fruits devoid of any adulteration. The essence of fruit intake lies in the nourishment it provides, emphasizing the need for untainted, wholesome produce. Unfortunately, the nutritional value of fruits can diminish through various stages of production, processing, and distribution, making them susceptible to adulteration—a practice often employed to enhance texture, storage, or appearance.
Fruit adulteration involves altering the nature or quality of fruits by introducing adulterants or removing essential components. These adulterants may include foreign or subpar chemical substances intentionally added to enhance visual appeal or extend storage capabilities. Recent years have witnessed a growing concern for food safety and quality, with a heightened focus on the adulteration of fruits. This intentional contamination or dilution for economic gain poses a significant threat to public health and erodes consumer trust. In response to these challenges, our project, aptly titled "FruitVerity," takes a groundbreaking approach. We harness advanced machine learning techniques to detect and combat fruit adulteration swiftly and accurately. By revolutionizing the identification process, our project seeks to restore confidence in the integrity of fruit consumption. Through the power of machine learning algorithms, FruitVerity aims to provide a proactive solution to the pressing issue of adulteration, ensuring that the fruits we consume contribute positively to our well-being.
II. LITERATURE REVIEW
The Literature Review Section critically examines existing research and methodologies related to the DETECTING ADULTERATION IN FRUITS, providing a comprehensive overview of the current state of knowledge in the field. By synthesizing key findings and identifying gaps in the literature, this section sets the stage for the unique contribution’s of the present study.
The literature on detecting adulteration in fruits through the application of machine learning algorithms, specifically focusing on Convolutional Neural Networks (CNN) and image preprocessing techniques, reflects a burgeoning field driven by the need for efficient and accurate detection methods.
Conventional approaches, predominantly reliant on chemical tests, have proven to be insufficient due to protracted processes and significant cost implications. The exploration of machine learning, and specifically CNN algorithms, signifies a promising alternative that leverages the power of data for discerning intricate patterns indicative of adulteration.
Studies in the literature highlight the adaptability and effectiveness of CNN algorithms in fruit adulteration detection. These algorithms, inspired by the human visual perception process, exhibit a remarkable ability to analyze and identify complex patterns within images. The literature underscores the significance of comprehensive datasets, encompassing various sources such as laboratory tests and sensory analysis, in training CNN models. The utilization of image preprocessing techniques further enhances the capabilities of these algorithms, allowing for the extraction of relevant features and improved model performance.
Image preprocessing techniques, as discussed in the literature, play a pivotal role in optimizing the input data for machine learning models. These techniques encompass processes such as normalization, resizing, and filtering, which collectively contribute to enhancing the quality and relevance of the images used for training and testing. The literature emphasizes the importance of fine-tuning these preprocessing steps to accommodate the specific nuances of fruit images, ensuring that the CNN algorithm receives input data that is conducive to accurate adulteration detection.
The existing body of research demonstrates a consensus on the potential of CNN algorithms and image preprocessing techniques in reshaping the landscape of fruit adulteration detection. The literature not only delves into the technical aspects of these methodologies but also highlights their practical implications, including swift and precise detection capabilities. As this field continues to evolve, the literature underscores the need for ongoing research to refine and optimize machine learning models, ensuring their efficacy in real-world scenarios and contributing to the overarching goal of safeguarding food safety and public health.
III. PROBLEM STATEMENT
Fruits are an essential part of a healthy diet, providing vital nutrients and vitamins. However, the increasing instances of fruit adulteration pose a significant threat to consumer health.
Adulteration can involve the addition of harmful substances, misleading labeling, or the use of unapproved pesticides. Traditional methods of detecting adulteration are often time-consuming and may not be sensitive enough to identify subtle changes in fruit composition.
This project aims to address the pressing issue of fruit adulteration by leveraging the power of machine learning. The goal is to develop an intelligent system capable of accurately and efficiently detecting adulteration in various fruits. The system should be trained to analyze complex datasets containing information about fruit composition, including chemical components, texture, and visual characteristics.
IV. METHODOLOGY
Methodology for Detection of Fruit Adulteration using Machine Learning with CNN and Image Preprocessing:
A. Dataset Collection
Gather a diverse dataset comprising high-resolution images of both pure and adulterated fruits. Include various fruit types and different types of adulteration scenarios.
Ensure the dataset is well-annotated, specifying the type and extent of adulteration in each image.
B. Image Preprocessing
Resize all images to a standardized resolution to ensure uniformity.
Apply techniques such as normalization to standardize pixel values, enhancing the model's ability to learn features effectively.
Implement data augmentation to artificially increase the size of the dataset by applying random transformations like rotations, flips, and zoom.
C. Labeling
Assign appropriate labels to each image indicating whether it is a pure or adulterated sample.
Ensure a balanced distribution of labels to prevent bias in the model.
D. CNN Model Architecture
Design a Convolutional Neural Network (CNN) architecture suitable for image classification. Include convolutional layers for feature extraction and pooling layers for dimensionality reduction.
Experiment with different CNN architectures, considering well-established models like VGG, ResNet, or custom architectures tailored to the specific task.
E. Model Training
Split the dataset into training, validation, and test sets. Typically, an 80-10-10 split is suitable.
Train the CNN model using the training set and validate its performance using the validation set.
Utilize transfer learning if applicable, leveraging pre-trained CNN models on large image datasets to boost performance.
F. Hyperparameter Tuning
Fine-tune hyperparameters such as learning rate, batch size, and dropout rates to optimize the model's performance.
Monitor training and validation loss to prevent overfitting and ensure generalization to new data.
G. Evaluation
Assess the model's performance on the test set, measuring metrics like accuracy, precision, recall, and F1 score.
Conduct a thorough analysis of the confusion matrix to understand the model's strengths and weaknesses in detecting different types of adulteration.
H. Real-time Detection System
Integrate the trained CNN model into a real-time detection system that can process images in various formats.
Implement a user-friendly interface for users to input images, and visualize the model's output indicating the likelihood of adulteration.
I. Testing and Validation
Test the real-time detection system using new, unseen images to validate its robustness in different scenarios.
Gather user feedback and refine the system based on practical insights.
J. Documentation and Deployment
Document the entire methodology, including dataset details, preprocessing steps, model architecture, and training procedures.
Prepare the model for deployment, considering scalability and efficiency in real-world applications.
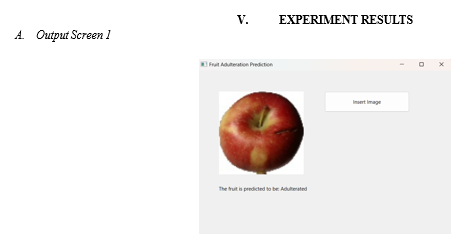
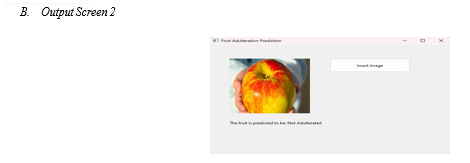
VI. FUTURE WORK
While FruitVerity marks a significant milestone, continuous improvement and exploration of new avenues are crucial for staying at the forefront of food safety technology. Future directions for the project include:
- Expanded Dataset and Adulteration Types: Incorporating a more extensive dataset encompassing a broader range of fruits and potential adulterants to improve the system's ability to generalize different scenarios and variations.
- Collaboration and Industry Adoption: Collaborating with industry stakeholders, regulatory bodies, and research institutions to foster widespread adoption of FruitVerity. Establishing partnerships will facilitate the exchange of knowledge and ensure the project's impact on a global scale.
- Integration of Emerging Technologies: Exploring the integration of emerging technologies, such as blockchain for enhanced traceability, to further strengthen the transparency and accountability of the fruit supply chain.
- Enhanced Privacy Measures: Implementing enhanced privacy measures within the security and privacy module to address growing concerns related to data protection, ensuring the responsible and ethical use of consumer information.
Conclusion
In conclusion, the project for the detection of adulteration in fruits using machine learning, titled \"FruitVerity,\" represents a significant stride towards ensuring the integrity of the global fruit supply chain and promoting consumer confidence in the quality of fruits. The comprehensive and meticulously designed system, comprising various interconnected modules, addresses the complexities associated with the detection of adulteration. Through the utilization of advanced machine learning techniques, the project not only identifies adulterated fruits but also establishes a framework for continuous monitoring and adaptation to evolving adulteration methodsThe FruitVerity project not only contributes to the ongoing efforts in ensuring the integrity of the fruit supply chain but also sets the stage for continued innovation and collaboration in the realm of food safety. Through the application of machine learning and a commitment to adaptability, FruitVerity stands as a beacon of progress in safeguarding consumer health and trust in the quality of fruits worldwide.
References
Here are some references that you can explore for further information [1] Sari, Yuita Arum, R V HariGinardi, RiyanartoSarno. \"Assessment of Color Levels in Fruit Color Chart Using Smartphone Camera with Relative Calibration\". Information Systems International Conference (ISICO), 2013: 631-636. [2] Raid, Richard Neil, and J. C. Comstock. Sugarcane adulterated. University of Florida Cooperative Extension Service, Institute of Food and Agricultural Sciences, EDIS, [3] Camargo, A., and J. S. Smith. \"Image pattern classification for the identification of adulterated causing agents in fruits.\" Computers and Electronics in Agriculture 66.2 (2019): 121-125. [4] Asraf, H. Muhammad, M. T. Nooritawati, and M. S. B. Rizam. \"A Comparative Study in Kernel-Based Support Vector Machine of Oil Palm Leaves Nutrient Adulterated.\" Procedia Engineering 41 (2020): 13531359. [5] Phadikar, Santanu, Jaya Sil, and Asit Kumar Das. \"Rice adulterateds classification using feature selection and rule generation techniques.\" Computers and Electronics in Agriculture 90 (2021): 76-85. [6] Li, Daoliang, Wenzhu Yang, and Sile Wang. \"Classification of foreign fibers in cotton lint using machine vision and multi-class support vector machine.\" Computers and electronics in agriculture 74.2 (2018): 274279. [7] Ginardi, R. V Hari, RiyanartoSarno, and Tri AdhiWijaya. “Sugarcane Fruit Color Classification in Sa*b* Color Element Composition”. 2019 International Conference on Computer, Control, Informatics and It’s Application, pp:175-178. [8] Li-jie, Yu, Li De-sheng, and Zhou Guan-ling. \"Automatic Image Segmentation Base on Human Color Perceptions.\" International Journal of Image, Graphics and Signal Processing (IJIGSP) 1.1 (2019): 25. [9] Shivakumar, G, P.A Vijaya. \"Face Recognition Using Geometric Attributes\". International Journal of Computational Intelligence Research Volume 6, Number 3 (2020), pp. 373–383.
Copyright
Copyright © 2023 K. Bharath, J. Harini, K. Vijay, U. Venkata Krishna, KVL. Sahiti, G. Mahesh, Dr. N. Rama Rao. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET57469
Publish Date : 2023-12-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online