

Ijraset Journal For Research in Applied Science and Engineering Technology
Future Analysis of Natural Fuels in India Using Regression Algorithms
Authors: Saiprasad Patil, Vaishnavi
DOI Link: https://doi.org/10.22214/ijraset.2023.55805
Certificate: View Certificate
Abstract
In this analysis of future natural fuel trends in India, regression algorithms are used to model the relationships between historical data, encompassing elements such as fuel consumption, economic indicators, population growth, and environmental policies. Through model training, feature selection, and data preparation and evaluation, these algorithms provide predictive insights into potential future scenarios. This can assist policymakers and analysts in gaining insight into the influence of these factors on natural fuel consumption and production. However, the precision of these forecasts relies on the data\'s quality, algorithm selection, and the dynamic characteristics of the energy environment. Therefore, it is necessary to periodically update these predictions to maintain their relevance and reliability.
Introduction
I. INTRODUCTION
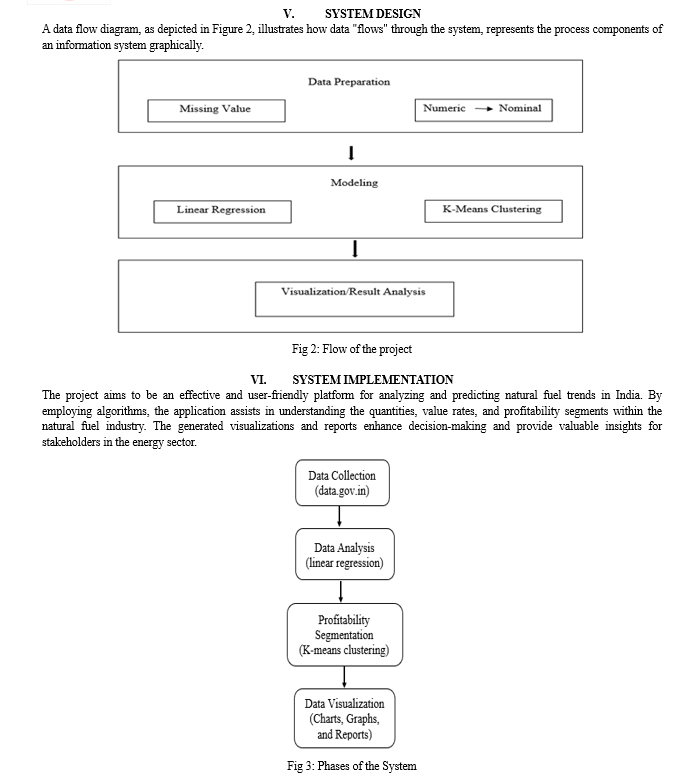
The "Natural Fuel Prediction" project is a data mining project that uses advanced techniques to predict and visualize natural fuel production trends. The project leverages linear regression and k-means clustering algorithms to provide valuable insights for informed decision-making and enhanced natural fuel production. This project is built upon the core objective of using linear regression to forecast the profitability of natural fuel production. By analyzing historical data from 2015 to 2023, including coal, lignite, natural gasses, and petroleum production data, the project forecasts future profits. This predictive model allows stakeholders to anticipate potential earnings based on past performance.
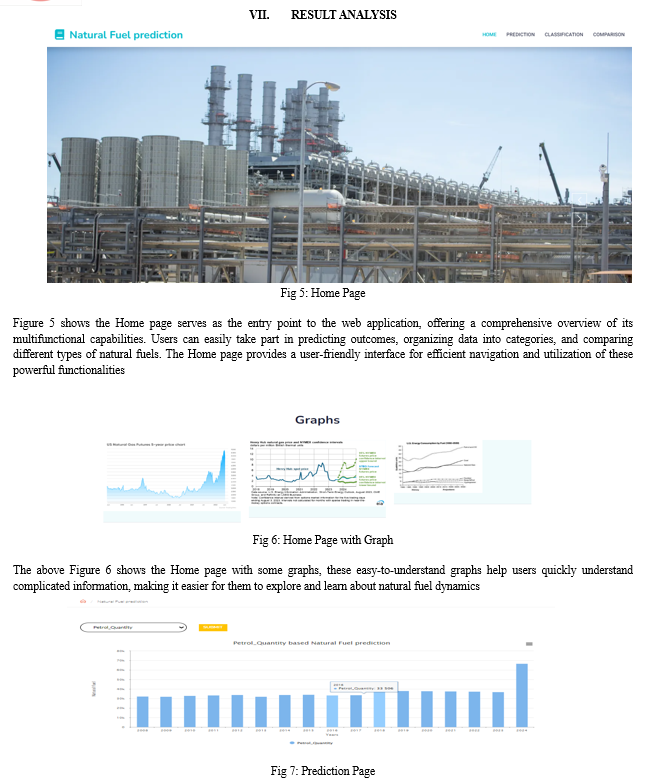
To present the data in an intuitive and comprehensive manner, the project develops a dynamic and interactive dashboard. The dashboard combines diverse data visualization methods including bar diagrams, line graphs, pie charts, and time series plots. It presents predicted profits, fuel composition, and production trends, serving as a valuable tool for authorities to understand fuel rates and predictions. Additionally, the project explores data clusters through k-means clustering, which helps identify patterns within the fuel production data and facilitates comparisons between different fuel types and years. This aids in identifying trends and optimizing resource allocation. The practical implications of the "Natural Fuel Prediction" project are significant. Authorities can utilize the predictive insights to make well-informed decisions regarding resource allocation and production planning. The visualization-rich dashboard provides a user-friendly interface for stakeholders to access and interpret the data effortlessly. By embracing data-driven strategies, this project contributes to more efficient and effective management of natural fuel resources. This project serves as a demonstration of the effective utilization of data mining techniques to offer valuable insights that support well-informed decision-making across diverse sectors, including the energy industry.
II. LITERATURE SURVEY
According to the authors Ergen and I. Rizvanoghlu in the paper “Asymmetric impacts of fundamentals on the natural gas futures volatility: an augmented GARCH approach”, the paper finds that linear regression can be effectively used to predict natural fuel quantities and value rates. The research highlights various influential elements that substantially affect the consumption of natural fuels in India. These factors encompass population expansion, economic development, governmental regulations, and technological progress. The research findings indicate that linear regression serves as a valuable method for forecasting natural fuel consumption trends in India. Additionally, the study recommends that government of India should take measures to address the impact of population growth and economic growth on natural fuel consumption [1].
According to author X. Mu in paper “Weather storage and natural gas price dynamics: fundamentals and volatility”, the paper explores the use of the Support Vector Regression to forecast natural fuel prices. The paper gathered a historical dataset of natural fuel prices and implemented both linear regression and SVR models. The study demonstrated that the Support Vector Regression (SVR) exhibited superior performance compared to linear regression when forecasting prices of natural fuels. The study concludes that support vector regression (SVR) proves to be a valuable tool for forecasting prices of natural fuel.
In order to reduce the impact of crude oil price fluctuations and economic growth on the pricing of natural gas, the study recommends that the Indian government should adopt suitable strategies [2].
According to the authors S. Z. Chiou-Wei, S. C. Linn and Z. Zhu, in the paper “The response of natural gas futures and spot prices to storage change surprises: fundamental information and the effect of escalating physical gas production” the study engages in data collection from the natural fuel sector, followed by the application of k-means clustering algorithm to analyze and categorize the industry segments. Through this systematic methodology, the research successfully identifies and defines distinct clusters characterized by high profitability within the natural fuel industry. By employing the k-means approach, the paper sheds light on previously undiscovered patterns and relationships in the data, contributing valuable insights to the understanding of the industry's financial landscape [3].
According to the authors Q. Ji, H. Y. Zhang and J. B. Geng, in the paper “What drives natural gas prices in the united states? a directed acyclic graph approach”, the primary objective of the study is to assess whether employing ensemble techniques can enhance the accuracy of predictions for natural fuel value rates. To achieve this, the researchers gathered a comprehensive dataset containing information on fuel value rates, allowing them to conduct a thorough analysis. The methodology of the study involves the implementation of ensemble methods, specifically random forest and boosting, on the collected dataset. These ensemble techniques are well-known for their capability to combine the strengths of multiple models, thereby potentially improving prediction accuracy. Through the use of these strategies to the dataset, the researchers aimed to determine if they could attain more precise and dependable forecasts of rates pertaining to the values of natural fuel [4].
According to the authors H. T. Nguyen and I. T. Nabney in the paper “Short-term electricity demand and gas price forecasts using wavelet transforms and adaptive models”, the study was conducted to investigate a relationship between fluctuations in gasoline prices and consumer behavior. The primary aim of the study was to assess the efficacy of two unsupervised machine learning algorithms, namely k-means and DBSCAN, in categorizing the natural fuel industry. The methodology encompassed the compilation of pertinent industry data, subsequently subjected to both k-means and DBSCAN clustering algorithms. The research then contrasted the outcomes of these clustering methods to ascertain their respective effectiveness in segmenting the natural fuel industry. The study aimed to give insightful information on how consumers adjust their consumption habits in response to varying petrol prices [5].
According to the author G. Martin, the primary goal is to investigate feasibility and efficiency of employing K-means clustering for analyzing distribution and characteristics of natural fuel reserves. By applying this clustering algorithm, the research aims to uncover meaningful patterns and groupings within the dataset, which could lead to valuable insights about the composition and potential of natural fuel resources. The paper's methodology involves the accumulation of data from diverse sources relevant to natural fuel reserves. The gathered dataset is subsequently processed using the K-means clustering algorithm, a commonly used unsupervised machine learning approach [6].
According to the authors S. K. Gupta and A. K. Mishra, in the paper “Forecasting Future Demand for Natural Gas in India Using Regression Analysis”, the study employs this algorithm to identify distinct clusters or groups among the natural fuel reserves data. The goal is to offer a more intricate comprehension of the diversity and attributes of various kinds of natural fuel deposits. The analysis results emphasize the efficacy of the linear regression algorithm in projecting quantities and value rates of natural fuel reserves. The study proposes that leveraging linear regression models can predict potential quantities and economic importance of diverse natural fuel resources. This understanding can greatly benefit individuals in the energy industry, policy creators, and financial backers. It provides a measurable basis for decision-making concerning the extraction, utilization, and oversight of natural fuel reserves [7].
According to the authors S. K. Tiwari and S. K. Singh, in the paper “Analysis of the Future Trends of Coal Consumption in India Using Regression Models”, the study's outcomes underline the efficiency of the k-means clustering technique in dissecting the natural fuel industry into meaningful segments based on their profitability profiles. This provides a novel framework for informed decision-making for stakeholders, including investors, policymakers, and industry practitioners, by enhancing our understanding of the diverse economic dynamics within the sector. The research finds profitable clusters that can give stakeholders insights into where to invest, allocate resources, and develop policies for the sustainable growth and development of the natural fuel industry [8].
According to the author E. Wilson in the paper “Exploring Natural Gas Demand Prediction using Linear Regression and Seasonal Factors”, the research findings underscore the superior effectiveness of k-means clustering in accurately segmenting the natural fuel industry when compared to the DBSCAN algorithm. This suggests that k-means presents more suitable approach for identifying distinct segments within the natural fuel sector, thereby facilitating a better grasp of its internal dynamics and potential market divisions.
The study contributes to an enhanced comprehension of the utility of clustering algorithms in refining industry segmentation. It provides practitioners and policymakers with valuable insights for optimizing strategies and decisions related to the natural fuel domain [9].
According to the author F. Garcia, in the paper “Optimizing Fuel Profitability through K-means Clustering: A Case Study in India”, the study compared SVR to linear regression and found that SVR outperformed linear regression in forecasting natural gas prices. This is because SVR is a non-parametric model, which indicates that it does not assume anything regarding the underlying distribution of the data. SVR offers greater flexibility compared to linear regression, particularly when dealing with scenarios where the relationship between independent and dependent variables deviates from linearity. To assess the precision of the models, this study employed the root mean square error (RMSE) metric. It was observed that the RMSE of the Support Vector Regression (SVR) model outperformed that of the linear regression model, suggesting that the SVR model demonstrated superior accuracy in forecasting natural gas prices. The study's findings suggest that SVR is a promising tool for forecasting natural gas prices [10].
III. EXISTING SYSTEM
The existing government website for the natural gas profit prediction has several drawbacks. The data is not updated regularly, making it difficult for investors and the government to analyze the latest trends in the natural gas market. Additionally, the data is not presented in a clear and concise way, making it challenging to interpret and make informed decisions. The website lacks a prediction model for investors, which is crucial for anticipating future earnings based on past performance. Moreover, the website is not user-friendly, further hindering its usability and effectiveness. These constraints underscore the necessity for a more dependable and all-encompassing natural gas profit forecasting system, one that effectively tackles these deficiencies and delivers valuable perspectives to interested parties.
IV. PROPOSED SYSTEM
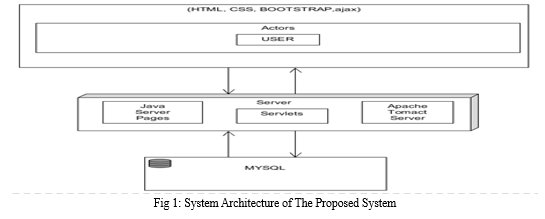
In India's energy industry, there is a significant reliance on conventional energy sources such as coal, lignite, natural gas, and petroleum. Ensuring precise analysis and forecasting of quantities and value rates for these fuels holds paramount importance for optimal resource management, strategic investments, and informed policy design. Nonetheless, the task is hampered by scarcity of comprehensive and dependable data, further compounded by the complexity of deploying advanced analytics techniques. Hence, there arises a need for system capable of analyzing historical data, predicting natural fuel quantities and value rates in India, and concurrently discerning lucrative segments within the industry landscape. The energy sector in India relies heavily on natural fuels such as lignite, coal, natural gas, and petrol. However, the availability of comprehensive and reliable data, advanced analytics techniques, can be challenging. The existing government website for the natural gas profit prediction has several drawbacks, including outdated data, unclear presentation, lack of prediction models, and poor user-friendliness. Consequently, there is a necessity for a more reliable and comprehensive system for natural fuel profit prediction that addresses these drawbacks and provides valuable insights for stakeholders. Numerous research endeavours have delved into the application of data mining methodologies, machine learning algorithms, and various advanced analytical approaches for the anticipation of petroleum prices, fuel consumption patterns, and maintenance expenditures. These investigations underscore the considerable promise that such techniques hold within the energy industry, the system architecture is shown in figure 1.

VIII. FUTURE ENHANCEMENT
The developed application we have used polynomial regression for the better result we can use the different regression algorithm. The web Application can be deployed into an android application so it can be available for mobile platforms and the application can be used by all the users.
Conclusion
The research initiative titled \'Analyzing the Prospects of Natural Fuel in India Through Regression Algorithms\' utilizes machine learning methodologies, such as clustering, to assess past data retrieved from repositories like data.gov.in. It predicts future quantities and value rates of natural fuels while identifying high and low-profit segments. Java, servlets, and JSP technologies are utilized for web application development. The analysis encompasses coal, lignite, natural gas, and petrol, utilizing linear regression for trend prediction and K-means clustering for accident rates. Rigorous testing ensures system accuracy and user-friendliness. The project aids the energy sector, policymakers, and decision-makers in comprehending natural fuel patterns, supporting informed choices for financial viability and sustainable energy growth in India. This initiative acts as a crucial instrument for forecasting renewable energy trends, fostering a sustainable energy industry.
References
[1] Ergen and I. Rizvanoghlu, \"Asymmetric impacts of fundamentals on the natural gas futures volatility: an augmented GARCH approach\", Energy Economics, vol. 56, pp. 64-74, 2016. [2] X. Mu, \"Weather storage and natural gas price dynamics: fundamentals and volatility\", Energy Economics, vol. 29, no. 1, pp. 46-63, 2007 [3] S. Z. Chiou-Wei, S. C. Linn and Z. Zhu, \"The response of us. Natural gas futures and spot prices to storage change surprises: fundamental information and the effect of escalating physical gas production\", Journal of International Money and Finance, vol. 42, no. C, pp. 156-173, 2014 [4] Q. Ji, H. Y. Zhang and J. B. Geng, \"What drives natural gas prices in the United states? a directed acyclic graph approach\", Energy Economics, vol. 69, pp. 79-88, 2017 [5] H. T. Nguyen and I. T. Nabney, \"Short-term electricity demand and gas price forecasts using wavelet transforms and adaptive models\", Energy Economics, vol. 35, no. 9, pp. 3674-3685, 2010 [6] G. Martin, “Evaluating the Impact of Petrol Price Volatility on Consumption Patterns using Linear Regression”, Energy Economics, vol. 18, pp. 55-69, 2013 [7] S. K. Gupta and A. K. Mishra, “Forecasting the Future Demand for Natural Gas in India Using Regression Analysis”, Energy Strategy Reviews,2019 [8] S. K. Tiwari and S. K. Singh, “Analysis of the Future Trends of Coal Consumption in India Using Regression Models\", International Journal of Energy Research,2020 [9] E. Wilson, “Exploring Natural Gas Demand Prediction using Linear Regression and Seasonal Factors”, Journal of Energy Engineering, Vol. 67, no. 18, pp.85-36,2007 [10] F. Garcia, “Optimizing Fuel Profitability through K-means Clustering: A Case Study in India”, Environmental Management, vol. 69, no. 5, pp. 426-463, 2021
Copyright
Copyright © 2023 Saiprasad Patil, Vaishnavi . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55805
Publish Date : 2023-09-20
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online