

Ijraset Journal For Research in Applied Science and Engineering Technology
Gesture Language Translator Using Raspberry Pi
Authors: Supriya Pawar, Apoorva Bamgude, Sayali Kamthe, Arundhati Patil, Prof. Rajesh Barapte
DOI Link: https://doi.org/10.22214/ijraset.2022.42242
Certificate: View Certificate
Abstract
Sign language is a remarkable development that has evolved over time. Unfortunately, there are some disadvantages associated with this language. When conversing with a speech disabled person, not everyone understands how to interpret sign language. Without an interpreter, communication is difficult. We need a product that is both adaptable and robust. We need to transform sign language so that it can be understood by common people and the differently abled can communicate without hurdles.
Introduction
I. INTRODUCTION
There are more than 70 million people who are mute or hard of hearing. These people can communicate via postures, body movements, eyes, eyebrows, and hand gestures thanks to sign languages. People with hearing and/or speech impairments use sign language as their natural mode of communication. Signs are gestures made with one or both hands accompanied by facial expressions with specific meanings. Although deaf, hard-of-hearing, and mute people can easily communicate with each other, integration in educational, social and work environments is a significant barrier for the differently abled. There is a communication barrier between an unimpaired person who is not aware of the sign language system and an impaired person who wishes to communicate. The use of computers to identify and render sign language has progressed significantly in recent years. The way the world works is rapidly changing and improving due to technological?advancements. As programs over the last two decades have progressed, barriers for the differently abled are dissipating. Researchers are working to build gear and software that will help these people interact and learn using image processing, artificial intelligence, and pattern matching approaches. The project's goal is to help people overcome these obstacles by developing a vision-based technology for recognising and translating sign language into text. We want to create a Raspberry Pi application for real-time motion gesture recognition using webcam input in Python. This project combines real-time motion detection and gesture recognition. The user has to perform a specific gesture. The webcam captures and recognizes the gesture(from a set of known gestures) and displays the accurate representation.
II. LITERATURE SURVEY
- “SVBiComm: Sign Voice Bidirectional Communication System based on Machine Learning” Nada Gamal Mohammed; Rania Ahmed Abdel Azeem Abul Seoud, 2018 1st International Conference on Computer Applications & Information Security (ICCAIS). The purpose of this study is to create a desktop human computer interface application that will let persons who are normal, "deaf/dumb," or blind communicate more easily. The SVBiComm system allows blind people to hear a voice stating the word gestured by the "deaf/dumb," while the deaf receive a gesture representing the blind's word. SVBiComm operates in two directions. The first is to convert video to speech. The animated word movements are mapped into text using a language knowledge base. The audio is then created using the Text-to-Speech (TTS) API. Processing from speech to video is the second direction. The voice of the blind person is translated into text using the Speech-to-Text (STT) API. Using a 3D graphical model, the natural language is mapped from the database to "deaf/dumb" in a corresponding sign language form. A total of 113 sentences with 244 signals were used to test the system. In speech recognition, the system correctly identified words from 19 different people with a 90% accuracy rate. For picture recognition, the system correctly identified photographs for 21 different people with an 84 percent accuracy rate. The SVBiComm system provides a variety of low-cost facilities that can be utilised in a variety of applications.
- “Real Time Sign Language Recognition Using a Consumer Depth Camera” Alina Kuznetsova,Laura Leal-Taixe, Bodo Rosenhahn, Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, 2018. Recent improvements in sensing technologies, such as time-of-flight and structured light cameras make hand gesture detection practical.We offer a highly precise approach for recognising static gestures from depth data provided by one of the sensors specified above in this paper. Rotation, translation, and scale invariant characteristics are derived from depth pictures. After that, a multi-layered random forest (MLRF) is trained to categorise the feature vectors, resulting in hand sign recognition.
- “American Sign Language Alphabet Recognition using Convolutional Neural Networks with Multiview Augmentation and Inference Fusion” Wenjin Tao, Ming C Leu Engineering Applications of Artificial Intelligence, 2018. From depth images recorded by Microsoft Kinect, this study offers a method for ASL alphabet identification utilising Convolutional Neural Networks (CNN) with multiview augmentation and inference fusion. Our method adds to the original data by producing extra viewpoints, making the training more successful and reducing the risk of overfitting. Our approach comprehends information from many viewpoints during the inference stage for the final prediction to handle the perplexing circumstances produced by orientational fluctuations and partial occlusions. Our technique outperforms the state-of-the-art on two available benchmark datasets.
- “Vision based sign language recognition”Sadhana Bhimrao Bhagat, Dinesh Rojarkar Journal of Emerging Technologies and Innovative Research (JETIR), 2020. This study suggests an algorithm or approach for an application that will aid in the recognition of Indian Sign Language's various signs. The approach has been designed with a single user in mind. The real-time images will be captured first, and then they will be saved in the directory. By using the SIFT (scale invariance Fourier transform) algorithm, it will be possible to determine which sign has been articulated by the user. The comparison will be done in reverse, and the result will be generated based on matched key points from the input image to the image that has already been saved for a certain letter. In Indian Sign Language, there are twenty-six signs that match to each letter of the alphabet and the proposed algorithm delivers 95% accuracy.
- “Human-Computer Interaction with Hand Gesture Recognition using ResNet and MobileNet” Abeer Alnuaim,Vikas Tripathi, Hussam Tarazi, Comput Intell Neurosci, 2022. A framework was developed that consists of two CNN models, each of which is trained separately on the training data. To attain better outcomes, the final forecasts of the two models were combined.The main contribution of this study is resizing the images to 64 x 64 pixels, converting them from grayscale to three-channel images, and then applying the median filter, which acts as lowpass filtering to smooth the images and reduce noise, as well as making the model more robust to avoid overfitting. The preprocessed image is then sent into ResNet50 and MobileNetV2, two distinct models. The ResNet50 and MobileNetV2 designs were combined. After using several preprocessing approaches and multiple hyperparameters for each model, as well as different data augmentation techniques, we produced results on the test set for the entire data with an accuracy of roughly 97 percent.
III. PROBLEM STATEMENT
To implement Gesture Language Translator using Raspberry Pi. Hand signals and gestures are used by the differently abled to communicate. Unimpaired people find it difficult to understand this language As a result, a system that identifies various signs and gestures and relays information is required. It connects people who are challenged with others who are not.
IV. OBJECTIVE
- The primary purpose of gesture language translator is to create a system that can recognise different human gestures and translate into text. Vision-based hand gesture interfaces require real-time hand detection and gesture recognition to do this.
- Promotes greater sensitivity and awareness of the deaf and hard of hearing communities.
- The outcomes allow signers and non-signers to communicate successfully, effortlessly, and instantly in their respective languages.
- The capacity of this technology to open up discussions between signers and speakers in the marketplace, employment, schools, health care, and civic institutions is what makes it intriguing.
V. COMPONENTS
A. Hardware
- Raspberry Pi 3 Model B+
- Zebion Webcam 20 Mega Pixel
- SD Card 32 GB
- Desktop or Laptop
B. Software
- Python IDLE
- Packages:
a. CV2
b. Numpy
c. Mediapipe
d. Tensorflow
e. Tf.keras
VI. DESCRIPTION
A. Raspberry PI 3 Model B+

- Windows and Android operating systems are supported by this computing device.
- RPi is essentially a low-cost system programming and administration test machine.
- The BCM2837B0 system-on-chip (SoC) features a 1.4 GHz quad-core ARMv8 64bit processor and a powerful VideoCore IV GPU.
- Snappy Ubuntu Core, Raspbian, Fedora, and Arch Linux, as well as Microsoft Windows 10 IoT Core, are among the ARM GNU/Linux distributions that can be run on the Raspberry Pi.
B. ZEBION Webcam 20 MP

This full functionality 20 MP camera can deliver smooth and detailed high-quality video.
Specifications :
- Image Sensor – CMOS
- Interface – USB
- Frame Rate – 30 FPS
VII. BLOCK DIAGRAM
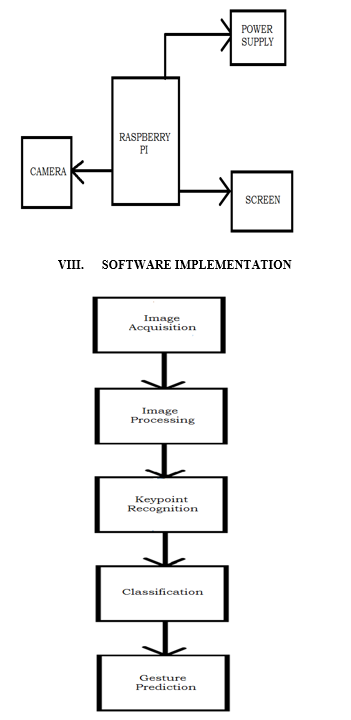
IX. FUTURE SCOPE
A. It removes the need for an interpreter.
B. Application that is both mobile and web-based.
C. Image processing should be enhanced so that the system can communicate in both directions, i.e. transform conventional language to sign language and vice versa.
D. Recognize motion-related indicators.
E. Concentrate on turning the gesture sequence into speech.
F. The system may be improved by allowing for multi-language display and speech conversion.
References
[1] K Amrutha, P Prabu, “ ML Based Sign Language Recognition System”, IEEE, 2021 [2] Kshitij Bantupalli, Ying Xie, “American Sign Language Recognition using Deep Learning and Computer Vision”, IEEE,2018 [3] Md. Moklesur Rahman, Md. Shafiqul Islam, Md. Hafizur Rahman, Roberto Sassi, “A New Benchmark on American Sign Language Recognition using Convolutional Neural Network”, IEEE,2019 [4] G. Anantha Rao; K. Syamala; P. V. V. Kishore; A. S. C. S. Sastry, “Deep Convolutional Neural Networks for Sign Language Recognition ”, IEEE, 2018 [5] Ronnie O. Serfa Juan, August C. Thio-ac, Maria Abigail B, “Static Sign Language Recognition Using Deep Learning”, International Journal of Machine [6] Learning and Computing, Vol. 9, No. 6, December 2019 [7] Sang-Ki Ko, Jae Gi Son, Hyedong Jung, “Sign Language Recognition with Recurrent Neural Network using Human Keypoint Detection”, Proceedings of the 2018 Conference on Research in Adaptive and Convergent Systems, October 2018 [8] Neena Aloysius, M Geetha, “Understanding Vision Based Continuous Sign Language Recognition”, 17 May, 2020
Copyright
Copyright © 2022 Supriya Pawar, Apoorva Bamgude, Sayali Kamthe, Arundhati Patil, Prof. Rajesh Barapte. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET42242
Publish Date : 2022-05-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online