

Ijraset Journal For Research in Applied Science and Engineering Technology
Hand Gesture Recognition
Authors: Bilal Nawaz, Dr. Indradeep Verma, Simran Sharma, Mansi Gupta
DOI Link: https://doi.org/10.22214/ijraset.2022.43491
Certificate: View Certificate
Abstract
Hand gesture recognition system has evolved within the recent few years due to evolving of technology and mostly due to device dependent life. People are now turning towards technology for a far better life with computer and portable devices being an enormous part of it. Not only people but companies too are shifting towards technology for improved performance of their products.
Introduction
I. INTRODUCTION
The essential aim of building hand gesture recognition system is to make a natural interaction between human and computer where the recognized gestures are often used for conveying meaningful information. How to make the hand gestures to be understood and well interpreted by the computer brain considered to be a real challenge.
Hand gestures offer a broad field of usage because they can level up the communication meaning and give a standard mean which can be used to perform a variety of different operations. hand gesture recognition was achieved with wearable detectors attached directly to the hand with gloves.
These detectors detected a physical response according to hand movements or cutlet bending. The data collected were also reused using a computer connected to the glove with line[1]. Now deep learning with computer vision are used to perform gesture recognition as they are less device independent
II. WORKING
To recognize the hand gestures using deep learning a type of neural network called convolutional neural network is used. CNN (Convolutional Neural Network or ConvNet) is a type of feed-forward artificial network where the connectivity pattern between its neurons is inspired by the organization of the animal visual cortex CNN utilizes spatial correlations which exist with the input data. Each concurrent layer of the neural network connects some input neurons. This region is called a local receptive field. The local receptive field focuses on hidden neurons. A convolutional neural network is a feed-forward neural network that is generally used to analyze visual images by processing data with grid-like topology. It’s also known as a ConvNet. A convolutional neural network is used to detect and classify objects in an image. The convolutional network are used to train models on image data set. Supervised, Unsupervised and reinforcement learning are the types of training used to train the model. Since the gesture recognition model is based on supervised leaning and learns from labeled dataset of the target gestures, having a good quality with less noise is very important as the accuracy depends upon the model network and the data used.
A. Collection of Data
Data collection is defined as the procedure of collecting, measuring and assaying accurate insights for exploration using standard validated ways. A experimenter can estimate their thesis on the base of collected data. In utmost cases, data collection is the primary and most important step for exploration, irrespective of the field of exploration. The approach of data collection is different for different fields of study, depending on the required information. During data collection, the experimenters must identify the data types, the sources of data, and what styles are being used. We'll soon see that there are numerous different data collection styles. There's heavy reliance on data collection in exploration, marketable, and government fields. Gesture recognition models are used to recognize gestures and are trained on labeled dataset. The model learns from the images of the gesture and the label on that particular images. The quality and the size of the data directly effects the efficiency of the model in classification of gestures.
The collected data should be relevant to the objective of the model as having unnecessary images would lead to wrong classification of the images presented to the model. The collection of data is followed by splitting the data into training and testing sets. The training set is used to train the model on the images present in that set and the testing set is used to evaluate how good our trained model is in terms of the accuracy in predicting the gesture in the present image. This collection of data could be done by merging different sources to a single directory and using only the relevant ones. The collection of data has to go though different drawbacks like low quality data, irrelevant data, small data size etc. Ways to deal with these drawbacks should be done before starting the process of data collection as it would lead to huge time consumption
B. Building of Model
Although different types of machine learning will have different approaches to training the model, there are introductory way that are utilized by utmost models. Algorithms need large quantities of high quality data to be effectively trained. Numerous of the way deal with the medication of this data, so that the model can be as effective as possible. The whole design needs to be duly planned and managed from the morning, so that a model fits the organisation’s specific conditions. So the original step deals with contextualizing the design within the organization as a whole[2]. When the collection of data are dealt with it is then followed by building of deep learning model. The model uses convulotional neural networks which compromises of convo2D layer, maxpooling layer and dense layer. The convulotional layer and maxpooling layer are used to down sample the image as the size is too big for the model to process. The dense layer is used to predict the category of the input image. There is no fixed numbers of layers used and could be tweaked to improve achieve a greater accuracy.

C. Training and Testing
Training and testing process for the classification of biomedical datasets in machine learning is very important. The researcher should choose carefully the methods that should be used at every step[3]. After the model is constructed, it goes through training and testing phase. In training phase the model is fed with the training dataset during which the model learns the image and their meaning. In testing phase the model is passed through the testing dataset to evaluate the working of the model and to figure out the efficiency of the prediction. When the required efficiency is achieved through tweaking the model parameters such as number of neural nodes or type of optimizer used, it is then put into usage. Training and test are very import phase of machine learning as it tells us about our model like how well it is working, what to recognize and what not to.
III. DRAWBACKS
Neural Network classifier has been applied for gestures classification but it is time consuming as well resource demanding, when the number of training data increase, the time for training and resource required are also increased.To improve the accuracy of the gesture recognition a huge amount of relevant data are need on which the gesture recognition model is trained on, the quality matters too as data with noise will lead to error in completing the objective and obtaining that data is a huge challenge.
The performance of the model also depends upon the distance of the hand and the lightning condition available, increase in distance between the camera and the hand and bad lighting both leads to wrong prediction. The model also face the overfitting and underfitting of data which is dealt by using image augmentation. This model also requires huge amount of resources for better learning and testing time so providing essential resources for basic functioning. Finding and providing relevant resources could be a hindrance in achieving our main objective in time
IV. METHODS
There are certain methods to make gesture recognition models. Some of them are using hardware like sensors to track hand movements and distance for accurate measuring or using camera to capture hand and make model learn to recognize them. The later one more effective one as it is less hardware dependent as it does not need hardware like sensors and circuits to for hand tracking rather it uses computer vision through camera.
Computer vision is a part of artificial intelligence that trains computers to capture and interpret meaningful information from image or video data.
Deep learning is also applied with it to understand the data. Deep learning is a sub-field of machine learning which tries to learn abstraction in data from the architectures present in them[3]. After the model is trained with the data collected, it is then made to recognize the image input through the camera using computer vision.
Comparing the two above mentioned models, each model has its own pros and cons. The model using computer vision is less hardware dependent but more resource dependent as without significant resources it would take a huge amount of time training models which deals with tons of data. For the model with sensor, it is hardware dependent as it needs camera, sensors on top of machine learning algorithms. Choosing the type of model is very important as one should keep the resources available in mind.
V. APPLICATIONS
Gesture Recognition is a computer process that attempt to recognize and interpret hand gestures and its meaning through machine learning algorithm and computer vision. Gesture Recognition is used to read and interpret hand movements as commands. It increases efficiency and reduces time in command conveying as it faster than verbal communication. It also provide real time data as an input to computer which could be processed as desired like making analysis or reviewing customer input. Hand gesture recognition model can to applied to personal use as well as in company use. Companies could use gesture recognition model to take input without physically touch their product or device. Sensor based gesture recognition system uses sensor to to recognize gestures whereas computer vision based gesture recognition system uses just uses a camera and machine learning algorithm .
These gesture recognition systems mainly aims at empowering disabled and elderly people where they can carry out daily activities like conveying simple information or controlling machines in the form of simple hand gestures[4].It could also be used in fluent communication between a deaf person who uses sing language and a person who does not know sign language, thus removing a communication barrier. Following are the field where gesture are most widely used.
- Virtual Reality
- Sign language translation
- Robot remote control
- Music creation
- Clinic and health
- Driver-less cars
- Automated homes
The application of gesture control application is limitless, with technology evolving rapidly it is evident that the field of this application will get bigger and bigger with the time.
VI. PERFORMANCE MEASURE
The main aim of the research is to enhance the the gesture recognition, cloud computing provides with the necessary resources like random access memory(RAM), Graphics processing unit(GPU), central processing unit(CPU). These are used for providing resources in building models and processing data. In classi?cation problems, good accuracy in classi?cation is the primary concern[5]. To test the efficiency we used performance metrics like confusion matrix. It was used by J font a a[6], he used matrix to distinguish the predicted values and real values of model elements in software engineering. Four confusion matrix measures such as True Positive(TP), False Positive(FP), True Negative(TN) and False Negative (FN) were used for the classification of faulty and non-faulty classes of Java[5]. True Positive: It is a case where the model predicted yes and it was true. False Positive: It is a case where the model predicted yes and it was false, they are also know as type 1 error. True Negative: It is a case where the model predicted no and it was true. False Negative: It is a case where the model predicted no and it was false, this is also known as type 2 error.
Conclusion
Based on the experimental results and performance analysis of various test images, the results showed that with relevant data a gesture recognition model could be applied anywhere with high efficiency and could easy the work load people face in their daily life. Gesture recognition has very high potential and with the evolving technology, it will witness a greater height of field applicability in near future. People with disability, companies or even a normal human being could use such type of technology in their day to day life. This technology is not restricted to just any field, it could be applied in the field of technology, medicine and health care and even agriculture. New technology are inventing everyday with better efficiency than the previous one using less resource. With evolving technology it would be easier to implement in devices than before as it would become less hardware dependent and would use less resources.
References
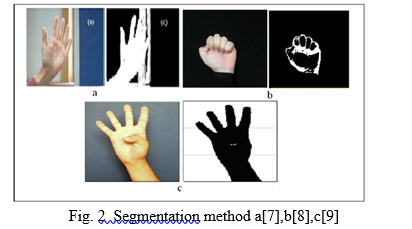
[1] White D, Dunn JD, Schmid AC, Kemp RI. Error rates in users of automatic face recognition software. PLoS One. 2015;10: e0139827. pmid:26465631. [2] Robertson DJ, Noyes E, Dowsett AJ, Jenkins R, Burton AM. Face recognition by metropolitan police super-recognisers. PLoS One. 2016;11. [3] Muhammed Kür?ad Uçar, Majid Nour, Hatem Sindi, Kemal Polat, \"The Effect of Training and Testing Process on Machine Learning in Biomedical Datasets\", Mathematical Problems in Engineering, vol. 2020, Article ID 2836236, 17 pages, 2020. [4] X. Jia, \"Image recognition method based on deep learning,\" 2017 29th Chinese Control And Decision Conference (CCDC), 2017, pp. 4730-4735, doi: 10.1109/CCDC.2017.7979332. [5] S. S. Kakkoth and S. Gharge, \"Real Time Hand Gesture Recognition & its Applications in Assistive Technologies for Disabled,\" 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), 2018, pp. 1-6, doi: 10.1109/ICCUBEA.2018.8697363. [6] Visa, Sofia & Ramsay, Brian & Ralescu, Anca & Knaap, Esther. (2011). Confusion Matrix-based Feature Selection.. CEUR Workshop Proceedings. 710. 120-127. [7] J. Font, L. Arcega, O. Haugen, and C. Cetina, ‘‘Achieving feature location in families of models through the use of search-based software engineer-ing,’’ IEEE Trans. Evol. Comput., vol. 22, no. 3, pp. 363–377, Jun. 2018. [8] Shuying Zhao, Wenjun Tan, Shiguang Wen, and Yuanyuan Liu, (2008). “An Improved Algorithm of Hand Gesture Recognition under Intricate Background”, Springer the First International Conference on Intelligent Robotics and Applications (ICIRA 2008),: Part I. pp. 786–794, 2008.Doi:10.1007/978-3-540-88513-9_85 [9] M. M. Hasan, P. K. Mishra, (2011). “HSV Brightness Factor Matching for Gesture Recognition System”, International Journal of Image Processing (IJIP), Vol. 4(5). [10] E. Stergiopoulou, N. Papamarkos. (2009). “Hand gesture recognition using a neural network shapefitting technique,” Elsevier Engineering Applications of Artificial Intelligence, vol. 22(8), pp. 1141 –1158, doi: 10.1016/j.engappai.2009.03.008 [11] Mokhar M. Hasan, Pramod K. Mishra, (2012). “Robust Gesture Recognition Using Gaussian Distribution for Features Fitting’, International Journal of Machine Learning and Computing, Vol. 2(3).
Copyright
Copyright © 2022 Bilal Nawaz, Dr. Indradeep Verma, Simran Sharma, Mansi Gupta. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET43491
Publish Date : 2022-05-28
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online