

Ijraset Journal For Research in Applied Science and Engineering Technology
Hand Safety Using Convolution Neural Networks
Authors: Dr. Mahesh V Sonth, K. Sai Manideep, K. Rohith, M. Sai Akash, K. Harichandana Priya
DOI Link: https://doi.org/10.22214/ijraset.2022.47711
Certificate: View Certificate
Abstract
Detecting the hand when it crosses the safety level and in return it also raises an alert in the form of alarm. So that the threat can be identified and proper measures are taken to overcome that. The methodology of the project goes as follows, taking input from camera , Image processing to detect hand, Projecting a line using computer vision, Raising alarm when hand crosses this projected safety line. The real time data is taken from the camera as an input to the Image processing algorithm. Then this input is processed to find the hand in image in it and checks whether the hand is crossing that safety line. If that hand is crossing the safety line we can simply raise alarm. The applications of the project are to the Employees who are working at industry are pushing the material into shredder machine. But somehow while pushing these material into shredder machine the employees are pushing their hands itself in the flow of work and the hands of employees were cut in that cause. So from a certain distance from shredder machine input we project a imaginary line using computer vision, So that if any hand crossing that imaginary line which is for safety we will raise an alarm. In addition, we can also extend the applications, by just replacing hand with the Bike, we can detect the bike, which is crossing the staggered stop line, and we can punish or fine them. As a part of object detection we are using Single short multibox detector.
Introduction
I. INTRODUCTION
Detecting the hand when it crosses the safety level and in return, it raises an alert in the form of alarm. So that the threat can be identified and proper measures are taken to overcome that, Let us say there was a shredder machine into which the employees who are working at industry are pushing the material into it. But somehow while pushing these material into shredder machine the employees are pushing their hands itself in the flow of work and the hands of employees were cut in that cause. So from a certain distance from shredder machine input we project a imaginary line using computer vision, So that if any hand crossing that imaginary line which is for safety we will raise an alarm.
But firstly we need to detect the hand, for sure the problem here is we cannot use any ultrasonic sensor to detect hand , because for ultrasonic sensor the Hand and the material which entering into machine will be same , due to this for every object entering into the machine it will raise an alarm .
To overcome this here we use object detection that only detects the hand, which is crossing the imaginary line, which is for safety and raises alarm. It is also possible to maintain the record of how many hands entered into it so that people can aware when they see the stats and they try to protect themselves to avoid such danger; we can also use this theme of the project to other applications. By just replacing hand with the Bike, and we can detect the bike which is crossing the staggered stop line and we can punish them. Therefore, the project involves computer vision techniques and Object detection .Theme of project is able to solve the industry problems and real time problems.
The theme of the project is to detecting the hand if it is a hand. Therefore, we used convolution neural network model to extract feature maps and passed these feature maps to the detector, which will return the location of hands. If the hands in the image cross the safety line we raise an alert in the form of alarm[3]
II. LITERATURE SURVEY
In India and across the world, in some of the industries employees used to push the trash into shredder machine as shown in figure in introduction and sometimes unknowingly they used to push the hands into it and getting injured. To overcome this kind of problems we are using deep learning technique i.e., object detection technique.
In this object detection technique whenever it detects any hand it will intimate us programmatically and with that result we go further and whenever we get result saying that the deep learning model detected the hand then will raise an alert in the form of alarm. There is no research paper, solving this problem using deep learning. However, there are many use cases in real time solving this problem using Sensors i.e., object detection using sensors.
A. Existing system
In the automation sector, object detection is a key activity. Ultrasonic sensors detect objects by using sound waves. Most ultrasonic sensors to detect objects and estimate distance use the return echo of an emitted sound wave bouncing off a target or background condition. But for this, object detection sensors every object is same. In our case object detection sensor treat both hand and the trash as object. But we don’t need that, we only want to detect the hand and that to if that hand crosses the line we need to raise an alarm. So, the existing system doesn’t work in our problem to solve it. Moreover, we moved to the deep learning.
B. Proposed system
Object detection is a computer technology linked to computer vision and image processing that detects instances of semantic items of a certain class (such as individuals, buildings, or cars) in digital photos and videos. Formalized paraphrase Face detection and pedestrian detection are two well-studied object detection areas. Object detection has a wide range of applications in computer vision, including image retrieval and video surveillance. There are various object detection algorithms are there. But we are choosing SSD. Because SSD works well for real time object detection with best possible accuracy and speed,it is what actually we need .So , we opted for SSD algorithm.
III. PROPOSED SYSTEM
SSD stands for Single Short Multibox Detector, which predicts classes and bounding boxes for the entire image in a single run of the algorithm, rather than picking interesting areas of an image. It's often employed for real-time object detection because it gives up a little accuracy in exchange for a lot of speed[2]. To understand the purpose of the SSD algorithm, we must first define the following concepts:
- Single Shot: This means that the duties of item location and classification are completed in one network pass.
- Multi-box: consists of two boxes: a ground truth box and a forecasted box. Szedegy is the one who brings it up.
- Detector: The network is an object detector that also classifies the objects that are detected.
The SSD method uses a feed-forward convolutional network to generate a fixed-size collection of bounding boxes and scores for the presence of object class instances in those boxes, followed by a non-maximum suppression step to get the final detections ( for bounding boxes with most overlap keep the one with highest score).The early network layers are based on the base network, which is a common architecture for high-quality image categorization (truncated before any classification layers)[6]. The network is then enhanced with auxiliary structure to create detections with the following important characteristics: Convolutional feature layers are added to the end of the truncated base network to create multi-scale feature maps for detection. These layers shrink in size over time, allowing detections to be predicted at several scales. Each feature layer has a different convolutional model for predicting detections. The SSD architecture is divided into 2 parts.
They are:
A. ???????Feature Extraction
Convolution is the deep learning technique that is used to extract the features.
The feature extraction in convolution layers involves many steps. Below is the block diagram of feature extraction. The Fig 1 describes the process of extracting the features from the given image. The steps are
- Convolution layer
- Pooling layer
- ReLU Lyer
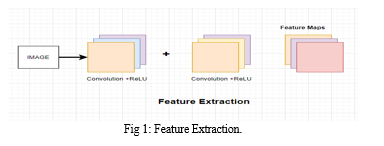
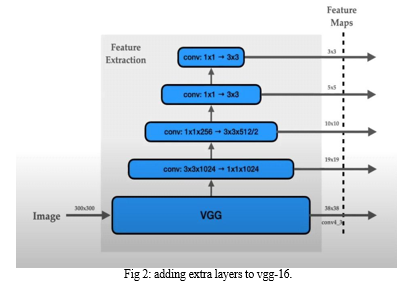
The convolution network that is used for feature extraction is VGG-16 network. The VGG-16 network acts as a base network for the feature extraction. The output of this VGG-16 is a feature map. The Feature maps are now finally with us from VGG-16 and this is not the end, But SSD wants to make detection at various scales. So SSD added more convolution layers to the VGG-16 base network in Fig 2.Now these convolutional layers generate a stack of feature maps of variety of sizes and different channels. Now after having our feature maps, we move forward to detection heads where these detection heads are neural networks that are used to detect the class and boxes of an object[2].
???????B. Detecting Objects (By Applying Convolution Filters)
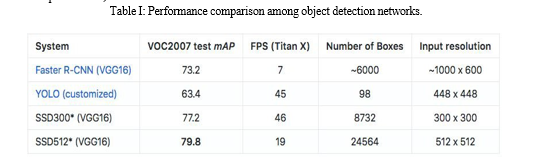
From the feature maps that we get from feature extractor stage, we detecting the objects from every feature map that are at different scales. Before getting into detection of objects we will look into how multibox detection works and then we see how it is implemented on SSD.SSD's bounding box regression technique is based on Szegedy's MultiBox, a method for quickly generating class-agnostic bounding box coordinate recommendations. SSD is designed for object detection in real-time. Faster R-CNN uses a region proposal network to create boundary boxes and utilizes those boxes to classify objects. While it is considered the start-of-the- art in accuracy, the whole process runs at 7 frames per second. Far below what real-time processing needs. SSD speeds up the process by eliminating the need for the region proposal network. SSD implements a number of enhancements, including multi-scale features and default boxes, to make up for the reduction in accuracy. These enhancements allow SSD to match the accuracy of the Faster R- CNN utilising lower resolution images, increasing the speed even further. It achieves real-time processing speed and even outperforms the accuracy of the Faster R-CNN, according to the Table I. (Accuracy is measured as the mean average precision mAP: the precision of the predictions.)
IV. IMPLEMENTATION AND RESULTS
The experiment or project is being developed using the Python programming language.
Now the steps that involved in this process of detecting hand are shown in Fig 3.And the steps are as follows:
- In order to get real time data we use camera of the laptop.
- After accessing camera we continue take a video from camera.
- Now we pass the frame by frame to our deep learning model. So that now our model will be able to process that frame i.e., image.
- Now the model gives the response and the response is:
a. Class
b. Location points of object
5. Now we will show it on the screen
6. With the help of open cv library we will draw some lines with respect to camera
7. And whenever the hand crosses the safety lines we raise an alarm
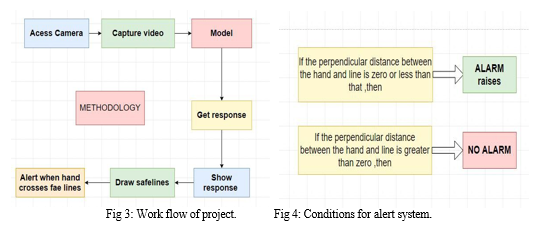
The Fig 4 describes conditions for raising an alarm , the alarm is raised based on the distance between the hand and the safety line. If the distance between them is less than zero i.e., hand crossed the safety line. So alarm will raise in this case. And for the rest cases alarm will not raise.

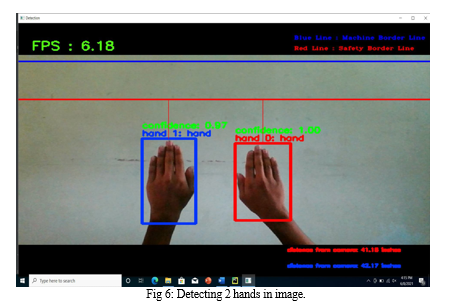
In Fig 5, Fig 6 ,Fig 7 ,Fig 8 whenever the hand is crossing the red line (safety border line) the alarm is raised whether it is single hand or double hand and alarm will not raised when hands are at a certain distance from the red line.
The object detection model that is used SSD(single shot multibox detector) is giving better results in detecting the hand in the image. More over SSD is best for real time applications and working for us good as well. The confidence at which the model is detecting the hand is 95% and sometimes even it will detect at a confidence of 98% as well. So the confidence is good in predicting these hands. More over as of our requirement (i.e., detect only hand so that we can able raise an alarm) our model working in the same direction in detecting only hand rather than any other objects which is shown in Fig 9.Below we will let you show some of the images that show the model detecting only hands itself.

In the Fig 9 though someone is holding the phone in hand it only detecting the hand not phone and you also able to observe that the phone is crossing the redline but alert is not raised because it is not hand, our model detects only hand because we want the hand not to enter into the machine.
Conclusion
The detection of hand and raising an alert whenever someone crosses the safety line is able to solve the real time problems .There are many object detection algorithms are out there but SSD works well for real time applications because as we seen that it is very fast and it is trained with different scales of the image (so that model can detect the images that are far from the camera).Unlike other detection algorithms like RCNN , fast RCNN , faster RCNN where it uses regional proposed networks for detecting a object in image which takes large time. Whereas SSD stands for Single Short Multibox Detector, which predicts classes and bounding boxes for the entire image in a single run of the algorithm, rather than picking interesting areas of an image. It\'s often employed for real- time object detection because it gives up a little accuracy in exchange for a lot of speed. The SSD method uses a feed-forward convolutional network to generate a fixed-size collection of bounding boxes and scores for the presence of object class instances in those boxes, followed by a non-maximum suppression step to get the final detections (for bounding boxes with most overlap keep the one with highest score).
References
[1] Redmon, J., & Farhadi, A. (2017). YOLO9000: better, faster, stronger. arXiv preprint. [2] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (pp. 91-99). [3] Dalal, N., & Triggs, B. (2005, June). Histograms of oriented gradients for human detection. In Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on (Vol. 1, pp. 886-893). IEEE. [4] Lee, K., Choi, J., Jeong, J., & Kwak, N. (2017). Residual features and unified prediction network for single stage detection. arXiv preprint arXiv:1707.05031. [5] Wang, R. J., Li, X., Ao, S., & Ling, C. X. (2018). Pelee: A Real-Time Object Detection System on Mobile Devices. arXiv preprint arXiv:1804.06882. [6] Liu, W., Anguelov, D., Reed, S., Fu, C. Y., & Berg, A. C. (2016, October). Ssd: Single shot multibox detector. In European conference on computer vision (pp. 21-37). Springer, Cham. [7] https://arxiv.org/abs/1412.1441 (website).
Copyright
Copyright © 2022 Dr. Mahesh V Sonth, K. Sai Manideep, K. Rohith, M. Sai Akash, K. Harichandana Priya . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET47711
Publish Date : 2022-11-26
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online