

Ijraset Journal For Research in Applied Science and Engineering Technology
Hardware Realization of Low Power and Area Efficient Vedic Mac in DSP Filters
Authors: Ms. D. Ramadevi, K. Pavan Kalyan, B. Anil, P. Sirisha, N. Pallavi, M. Pratyush
DOI Link: https://doi.org/10.22214/ijraset.2022.45208
Certificate: View Certificate
Abstract
VLSI experiences a key position in many of the signal process applications. Multiply and Accumulation methodology is one in all told the chiefly used operation. Power, space and speed ar the metrics accustomed ensure the efficiency of a MAC unit. Surely cases each of these metrics plays a key role. In some cases, speed is simply targeted, so the other parameters do not appear to be rich priority in that case. Through the deep analysis of adders, Carry Select Adder has shown less space and power consumption than totally different adders. The processes that square measure involved in MAC are multiplication, addition and accumulation. The addition of Vedic techniques in a MAC is commonly an additional advantage .So, this project includes development of multiply and accumulate unit pattern frightened writing Sanskrit (UrdhvaTiryakbhyam sutra), accumulation unit involving Carry select adder (CSLA) and its implementation in a 4-tap FIR filter
Introduction
I. INTRODUCTION
Vedic arithmetic may well be a name given to the traditional system of arithmetic that was re discovered kind the Vedas. It offers rationalization of the many mathematical likewise as arithmetic's, geometry, trigonometry and human calcus . It completely was created by Shri Bharathi Krishna (1884-1960), once his eight years of analysis and Vedas. He created 16 main sutras and 16 sub sutras .The beauty of arithmetic is to chop back advanced calculations into straightforward ones .The most of digital signal processing applications, the crucial operations are multiplications and accumulations .The main DSP operates extensively produce use of multiply accumulate (MAC) operation, for high performance digital signal processing systems
II. PRACTICAL DESIGN OF PROJECT
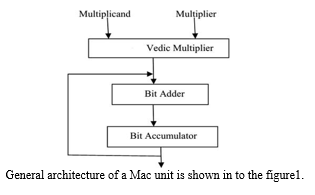
MAC Unit Consists Of
- A Multiplier
- An Accumulator
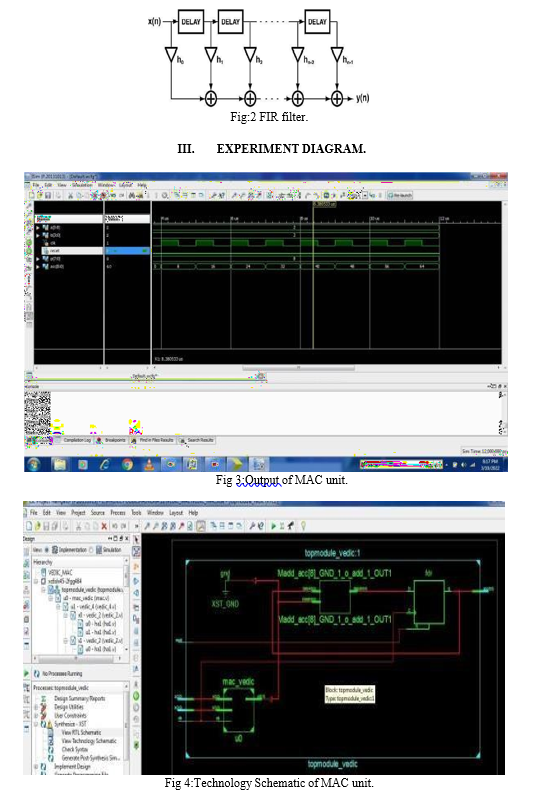
The sum of the previous successive products. The MAC inputs are obtained from the memory location and given to the multiplier block. Here x(n) is the input and the coefficients are h0,h1,h2,h3,….hn-1,hn.It contains n-1 adders and n multipliers .It is the direct form ,that the delays are placed in between the multipliers
The key advantage in victimization the VHDL in systems style is allowing the behaviour of the required system to be delineate (model) and verified (simulated) before synthesis tools translate the design into real hardware (gates and wires). Figure indicates the RTL and technology schematic diagram of the FIR filters. All component of the system is simulated victimization Xilinx ISE 14.7i. Viewing a schematic permits to examine a technology level illustration of HDL optimized for specific device design, that it's going to beassisted tofind the theme problems early in design process
IV. ADVANTAGES FROM ABOVE RESULTS.
- Compact size.
- High Speed Of Operationless Delay.
- Area Efficient.
Conclusion
The projected Vedic mathematics-based MAC unit proves be extremely economical in terms of speed. Thanks to its regular and parallel structure, it will be completed simply on semiconducting material likewise. In FIR filters implementation of Vedic Mac Unit is highly efficient using different adders are Ripple carry adders, Carry selection adder, Han Carlson Adder. When compared to this adder carry select adder have a less time delay. And it was simple rather than other adders.
References
[1] M.E.Paramasivam, Dr.R.S.Sabeenian, An Efficient Bit Reduction Binary Multiplication Algorithm using Vedic Methods, IEEE 2ndInternational Advance Computing Conference 2010. [2] Prabir Saha, Arindam Banerjee, Partha Bhattacharyya, Anup Dandapat, High Speed ASIC Design of Complex Multiplier Using Vedic Mathematics, Proceeding of the 2011 IEEE Students\' Technology Symposium 14- 16 January, 2011, IIT Kharagpur. [3] Swami Sri Bharati Krisna Jagadguru Tirthaji Maharaja, \"Vedic Mathematics or Sixteen Simple Mathematical Formulae from the Veda, Delhi (1965), Motilal Banarsidas, Varanasi, India, 1986. [4] Tiwari, Honey Durga, Ganzorig Gankhuyag, Chan Mo Kim, and YongBeom Cho. \"Multiplier design based on ancient Indian Vedic Mathematics.\" In SoC Design Conference, 2008. ISOCC\'08. International, vol. 2, pp. II- 65. IEEE, 2008. [5] Shamim Akhter, “VHDL Implementation of Fast N X N Multiplier Based on Vedic Mathematics, Jaypee Institute of InformationTechnology University, Noida,201307 UP,India,2007 IEEE. [6] Vaijyanath Kunchigi1, “32 bit MAC design using Vedic Multiplier, JNTU, Hyderabad A.P, INDIA, 2013 International Journal of Scientific and ResearchPublications. [7] Sreelekshmi M. S., “Implementation of MAC by using Modified Vedic Multiplier University of Kerala, INDIA, 2013 International Journal of Advanced Computer Research. [8] Whitney J. Townsend, Earl E. Swartzlander, Jr., and Jacob A. Abraham,“A comparison of Dadda and Wallace multiplier delays”,The University of Texas at Austin, TX 78712. [9] R. Naveen,K.Thanushkodi,C. Saranya,“Reduction of Static Power Dissipation in Wallace Tree Multiplier”, European Journal of Scientific Research, ISSN 1450-216X, Vol.84, No.4 (2012), pp.522-531 [10] Y. Choi, “Parallel Prefix Adder Design,” Proc. 17th IEEE Symposium on Computer Arithmetic, pp 90-98, 27th June 2005. [11] M. Snir, “Depth-size trade-offs for parallel prefix computation,” in Journal of Algorithms 7, pp.185–201, 1986. [12] Richard P. Brent and H. T. Kung, “A Regular Layout for Parallel Adders”, IEEE transactions on Computers, vol.c- 31, pp.260-264,March 1982. 154 [13] Mittal, Anubhuti, Ashutosh Nandi, and Disha Yadav. \"Comparative study of 16-order FIR filter design using different multiplication techniques.\" IET Circuits, Devices & Systems 11.3 (2017): 196- 200.] [14] S. Goel, A. Kumar, and M. A. Bayoumi, “Design of robust, energy efficient full adders for deep-submicrometer design using hybrid-CMOSlogic style,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., vol. 14, no. 12, pp. 1309- 1321, Dec. 2006. [15] M. Zhang, J. Gu, and C.-H. Chang, “A novel hybrid pass logic with static CMOS output drive full-adder cell,” in Proc. Int. Symp. Circuits Syst.,May 2003, pp. 317-320.
Copyright
Copyright © 2022 Ms. D. Ramadevi, K. Pavan Kalyan, B. Anil, P. Sirisha, N. Pallavi, M. Pratyush. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET45208
Publish Date : 2022-07-01
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online